
Key Takeaways
- Agency efficiency now means margin per approved deliverable across a governed workflow, replacing utilization rate as the metric that actually describes whether production earns.
- Four operating shifts reinforce the new model: hours to unit cost, headcount to workflow scaling, output review to approval gates, and scattered vendors to unified execution loops.
- Speed gains outrun quality gains—40 percent of AI-using workers report faster work while only 29 percent report better quality 6—so senior review capacity must hold as a floor, not compress with drafting time.
- Owners should map deliverables against research-draft-edit versus judgment work, price governance hours into unit cost, and migrate revenue toward the judgment layer clients cannot replicate in a chatbot.
Why the old definition of agency efficiency stopped working
For two decades, agency efficiency was measured in utilization rate. Senior strategists targeted 65 to 75 percent billable hours, junior producers pushed higher, and the whole model priced expertise by the hour markup over blended labor cost. That math assumed a stable ratio between hours spent and deliverables produced. Generative AI broke the ratio.
The task-level evidence is now specific enough to plan around. Among U.S. workers who use AI chatbots at work, 57 percent apply them to research, 52 percent to editing written content, and 47 percent to drafting written content 6—the exact production stages that fill an agency's timesheet. When a junior copywriter's four-hour first draft compresses to a 40-minute prompt-and-revise pass, hours-per-deliverable stops describing effort and starts describing overhead.
Client-side awareness has moved in parallel. Roughly 34 percent of U.S. adults have used ChatGPT, and 28 percent of employed adults say they use it for work 3. Clients who draft their own briefs, subject lines, and outlines in a chatbot before a call arrives with a different question than they asked in 2022. They are no longer buying production capacity. They are buying judgment, coordination, and outcomes they cannot reliably generate themselves.
Utilization rate cannot answer that question. It measures whether people are busy, not whether the workflow produces margin. The rest of this article reframes efficiency around the metric that now matters: cost, quality, and approval velocity per deliverable that actually ships.
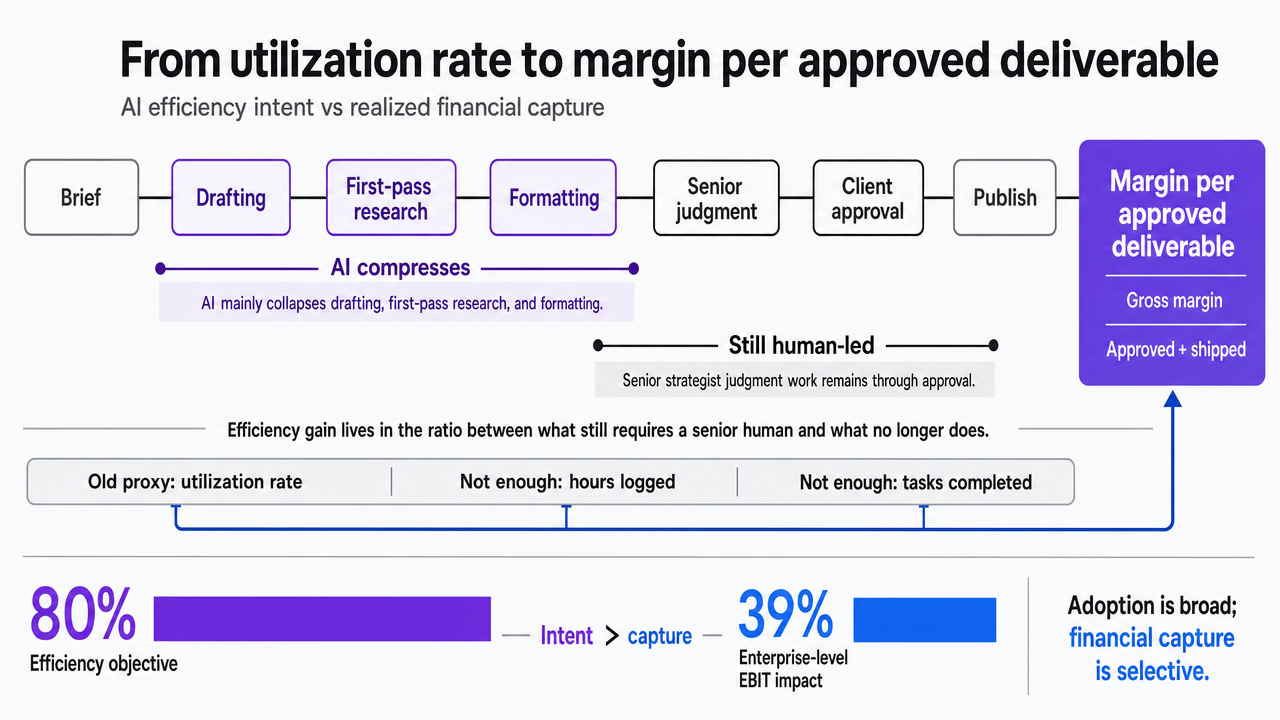
From utilization rate to margin per approved deliverable
Efficiency, redefined for an AI-enabled agency, is the gross margin an agency earns on each deliverable that clears client approval and ships. Not hours logged. Not tasks completed. Margin per approved unit, measured across the full production loop from brief to publish. That reframe matters because AI does not lower the hours a senior strategist spends on judgment work; it collapses the hours spent on drafting, first-pass research, and formatting. The efficiency gain lives in the ratio between what still requires a senior human and what no longer does.
The gap between intent and capture is the story of the current cycle. McKinsey's 2025 global survey found that 80 percent of organizations name efficiency as an objective for AI, yet only 39 percent report any enterprise-level EBIT impact from AI deployments 1. Adoption is nearly universal. Financial capture is a minority sport. The delta is where the operating-model question lives for agency owners: layering AI onto a timesheet-priced, hours-billed model produces faster drafts and higher tool costs without moving the margin line.
Margin per approved deliverable forces four measurements onto the same page.
- Production cost, which now includes model tokens and prompt-engineering time alongside labor.
- Senior review cost, which typically rises as a percentage of total effort because judgment work is what remains.
- Rework rate, which determines how many revision rounds a deliverable absorbs before approval.
- Throughput per FTE, which sets the ceiling on how many engagements the current team can carry without hiring.
Track those four together, per deliverable type, and the P&L question becomes concrete rather than philosophical.
Owners who run this math discover that the traditional utilization target quietly inverts. Senior strategists should be less utilized on production and more utilized on approval, positioning, and client judgment. Junior producers should be measured on cycle time and approval rate, not hours booked. The efficiency question stops being how busy the team is and becomes how much margin the workflow generates per unit that clears the gate.
 Visualize the gap between AI efficiency intent and realized enterprise financial impact, directly supporting the section's argument that adoption is nearly universal while financial capture is a minority sport
Visualize the gap between AI efficiency intent and realized enterprise financial impact, directly supporting the section's argument that adoption is nearly universal while financial capture is a minority sport
Where AI actually lands inside an agency workflow
The task-level data is unusually clean for a technology this new. Among U.S. workers who use AI chatbots for work, Pew found that 57 percent apply them to research, 52 percent to editing written content, and 47 percent to drafting written content 6. Those three tasks are not incidental to agency production. They are the production. A content retainer, a paid-media landing page build, a social calendar, a competitive audit—each moves through some sequence of research, drafting, and editing before it reaches senior review.
That distribution predicts which line items on a scope of work compress first and by how much.
- Research pass, which used to consume a junior strategist's morning gathering competitor headlines, keyword clusters, and source links, collapses to a structured prompt with source verification.
- First drafts, historically the most time-hungry stage, move from blank-page effort to prompt-plus-revise.
- Editing—copy polish, brand-voice alignment, formatting for CMS—remains human-led but runs against a cleaner starting draft.
- The senior review stage does not shrink. It often grows, because judgment work is what remains to do.
Two other stages barely move. Client discovery, positioning, and creative concepting still require the strategist who can read a market and a client roster at the same time. Approval routing, revision arbitration, and stakeholder management still require someone who understands why a client's legal team flagged a claim. AI does not compress these because they are not text-generation problems. They are judgment problems dressed in text.
The operational takeaway is specific. An agency owner auditing where AI belongs should map the current workflow against the three Pew task categories and mark which deliverables are 60 to 70 percent research-draft-edit and which are 60 to 70 percent judgment. The first bucket is where unit cost falls quickly. The second is where senior time concentrates and where pricing power lives. Confusing the two—assuming AI compresses concepting the way it compresses drafting—produces disappointed clients and margin that never materializes. The workflow map is the prerequisite. Tool selection comes second.
 Show how the three most common AI chatbot tasks (research, editing, drafting) map onto specific agency workflow stages, reinforcing the section's argument that these stages compress fastest while judgment stages do not
Show how the three most common AI chatbot tasks (research, editing, drafting) map onto specific agency workflow stages, reinforcing the section's argument that these stages compress fastest while judgment stages do not
Experience measurable agency efficiency in seven days
Test real-time AI-driven campaign execution and validate operational impact before making a commitment.
The four shifts that redefine efficiency
Redefinition requires more than a new metric. It requires four operating changes that reinforce each other. Owners who make one shift in isolation—new pricing without new workflow, new tools without new review gates—typically see cost rise before margin does. The four moves below describe what changes underneath the P&L when an agency stops layering AI onto legacy processes and starts running the workflow the technology actually rewards.
Hours to unit cost
Pricing by the hour assumes hours are the input that varies with effort. That assumption held when a 2,000-word article required a predictable range of drafting time. It stops holding when the drafting stage compresses to a fraction of its former duration while the research, editing, and senior-review stages redistribute unpredictably 6. Hourly billing now under-prices judgment and over-prices production, and clients who use AI themselves know it.
Unit cost inverts the frame. An agency measuring the fully loaded cost of a shipped deliverable—labor, model tokens, tool subscriptions allocated per unit, and rework absorbed before approval—can price against the outcome rather than the input. That number is stable enough to quote, specific enough to defend, and comparable across engagements. It also exposes which deliverable types actually earn margin and which quietly subsidize the rest, a diagnosis the timesheet obscures.
Headcount scaling to workflow scaling
The traditional growth formula added seats. A new retainer meant a new junior producer, another slot on the account team, another line on the org chart. Capacity scaled linearly with payroll, and margin compressed each time senior salaries drifted upward faster than blended rates.
Workflow scaling changes the input. Adding a retainer means adding a run of an existing production loop—the same brief template, the same prompt library, the same QA checklist, the same approval routing—rather than a person to execute it. The constraint moves from hiring pipeline to workflow throughput, which an owner can measure, tune, and improve without renegotiating salary bands. McKinsey's 2025 survey found only 23 percent of organizations are scaling agentic AI in at least one function while 39 percent are still experimenting 1. The gap between those two states is largely a workflow-design gap, not a technology gap. Agencies that codify their production loops cross it. Agencies that treat AI as a personal productivity tool for individual staff do not.
Output review to approval gates
Output review is what senior staff did at the end of a production cycle: read the finished draft, mark it up, send it back. The stage was expensive because it caught problems late, absorbed rework hours, and slowed client turnaround. It also assumed the draft was scarce enough to be worth polishing.
Approval gates move the judgment earlier and formalize it. A gate is a checkpoint where a specific human decision must clear before the workflow proceeds—brief approval before drafting, claim substantiation before publication, brand-voice check before client delivery. AI produces the material between gates; humans decide at each gate. The design matters because NIST's AI Risk Management Framework treats trustworthy deployment as a function of documented human oversight, not model quality alone 9. Gates make oversight legible: who approved what, when, against what standard. That documentation is what protects the agency when a client, a regulator, or a plaintiff asks the question later.
Vendor stacks to unified execution loops
Most agencies accumulated their AI stack the way they accumulated their martech stack: one tool per problem, purchased by different teams, integrated through spreadsheets and Slack. A copywriting assistant here, a research tool there, an image generator, a scheduler, a reporting layer. Each subscription adds cost. Each handoff between tools adds friction. And the promised time savings dissipate in context-switching, prompt duplication, and reconciliation work that no line item captures.
A unified execution loop collapses the stack around a single governed workflow: strategy input, production, review, approval, publish, measurement, all connected. The value is not the individual tool. It is the elimination of the handoffs between them. NIST commentary on enterprise AI risk management emphasizes that dynamic governance and monitoring across proliferating use cases is a primary control problem 11. Consolidation is the control. It also makes the unit-cost math from the first shift possible, because scattered tools produce scattered numbers.
Unit economics: three operating models on the same engagement
The clearest way to see how AI changes agency margin is to run the same engagement through three operating models and compare the numbers. Take a 20-deliverable monthly retainer—a mix of long-form articles, landing pages, and social assets. Hold scope constant. Vary only the production model. The columns that matter are production hours, senior review hours, tool cost, gross margin per deliverable, and throughput ceiling per FTE.
The comparison has to weight review alongside production for a reason grounded in the data. Among workers using AI chatbots at work, 40 percent report the tools help them do things more quickly, while only 29 percent say the tools improve the quality of their work 6. Speed gains outrun quality gains, which means review hours cannot be modeled as a fixed percentage of production hours the way they were under a labor-first model. Faster drafts with unchanged quality shift more burden onto the approval stage, not less.
| Model | Production hours | Senior review hours | Tool cost per unit | Gross margin per deliverable | Throughput ceiling per FTE |
|---|---|---|---|---|---|
| Traditional labor-first | H | 0.15H | Low | (Price − H × blended rate − tool cost) / Price | 20 / H units per month |
| AI-augmented legacy workflow | 0.5H | 0.25H to 0.35H | Moderate | Often flat or lower vs. baseline once tool cost and rework absorbed | 25 to 30 / H units per month |
| AI-native unified workflow | 0.3H to 0.4H | 0.20H to 0.25H | Consolidated | Meaningfully higher than baseline when approval gates hold | 40+ / H units per month |
Owners populate H with their own current production hours per deliverable type and their own blended senior rate. The framework surfaces the pattern most agencies discover the hard way: the augmented-legacy row is where margin stalls, because the workflow still routes rework through the same output-review stage that never got redesigned.
See How AI-Driven Workflows Are Redefining Agency Efficiency Benchmarks
Connect with our team to learn how leading agencies are using automated, approval-first execution to cut production time by up to 70% while maintaining full creative oversight.
If you operate a multi-location or portfolio agency
The scope shifts here. Owners running a single P&L can stop reading; the next few paragraphs address operators with either multi-location clients (dental groups, home services franchises, senior living portfolios) or agency portfolios where several sub-brands or acquired shops share back-office production.
The math changes because the same workflow now amortizes across more units. A codified production loop built for one 20-deliverable retainer runs the same way for 15 locations with local variants layered on top. The variable cost per location is prompt configuration and local approval routing, not a duplicated production team. That is where the 23 percent scaling versus 39 percent experimenting split in the McKinsey survey 1 separates portfolio operators from single-shop peers: portfolios that codify win twice, once on unit cost and once on cross-location consistency.
Two operational cautions apply. First, approval gates must sit at the location level, not just the brand level, because a claim substantiated for one market can fail in another. Second, throughput ceilings measured per FTE should be recalculated per workflow, since a portfolio agency's constraint is loop capacity, not seat count.
Retention risk when speed gains outpace quality gains
Faster is not the same as better, and clients notice the difference by the third invoice. Pew's chatbot survey found that 40 percent of workers using AI at work say the tools help them do things more quickly, while only 29 percent say the tools improve the quality of their work 6. That eleven-point gap is the retention risk in miniature. An agency that shortens turnaround from ten days to four but ships copy that reads generically, misses brand voice, or hallucinates a statistic loses the account faster than one that moved slowly and got it right.
The failure mode is predictable. Production compresses. Senior review stays flat or gets squeezed because the pipeline now moves more units through the same reviewer. Small drift accumulates: a claim that was almost accurate, a headline that was almost on-brand, a data point that was almost sourced. Clients rarely churn over one bad deliverable. They churn when the pattern becomes visible across a quarter of work and the agency looks less like a partner and more like a faster version of what the client could do internally.
The operational fix is to hold review capacity as a floor, not a variable. If drafting time falls by half, senior review hours per deliverable should hold or rise, and the throughput ceiling should expand through workflow gains rather than by thinning the approval stage. Agencies that treat quality as the constraint keep the retainer. Agencies that treat speed as the product train clients to renegotiate price against the new baseline.
Client-side AI literacy is repricing what agencies sell
The buyer on the other side of the table now uses the same tools the agency does. Pew reports that 34 percent of U.S. adults have ever used ChatGPT and 28 percent of employed adults use it for work 3, with 21 percent of U.S. workers saying at least some of their job now runs through AI, up from 16 percent a year earlier 4. That population includes marketing directors, brand managers, and in-house content leads who used to buy first drafts and now generate their own before the kickoff call.
The pricing implication is direct. Deliverables that a client can approximate in a chatbot—short-form social copy, competitor summaries, generic blog outlines—lose defensible price. Deliverables that require judgment the client cannot replicate—positioning against a shifting category, media mix decisions tied to CAC targets, substantiated claims for a regulated vertical—hold or gain price. The agency's revenue mix has to migrate toward the second category, and the workflow has to make that migration visible in the scope of work.
Worker sentiment adds a second layer. Pew found 52 percent of U.S. workers are worried about AI's future workplace impact against 36 percent who feel hopeful 5. Client-side stakeholders carry that ambivalence into the buying decision: they want AI-driven cost gains but need reassurance that oversight, judgment, and accountability remain human. Agencies that sell the judgment layer explicitly—and price it—retain the room the production layer used to occupy.
Redefine Agency Efficiency: Eliminate Production Bottlenecks with AI Coordination
Gain hands-on access to an AI-driven approval workflow that streamlines multi-channel marketing execution, reduces production overhead by up to 60%, and maintains full control and visibility across your client delivery process.
Governance, substantiation, and the workflow tax nobody budgets for
Every AI-generated deliverable that reaches a client is an advertising claim waiting to be tested. The FTC's core guidance is unchanged by the technology: claims must be truthful, not deceptive, and supported by solid proof 7. Operation AI Comply added the enforcement posture, with the FTC signaling action against companies using AI to accelerate deceptive or unfair conduct 8. Neither standard cares whether a human or a model produced the copy. Substantiation sits with the agency that shipped it.
That reality creates a workflow tax most owners do not price into their unit economics. Every AI-assisted deliverable now carries a substantiation cost—source verification, claim documentation, disclosure review, brand-voice audit—that a labor-first workflow absorbed implicitly in senior review. NIST's AI Risk Management Framework treats this as documented human oversight across design, use, and evaluation, not a one-time check 9. The bias publication adds a second layer: transparency, dataset review, and human-in-the-loop mitigation are what keep flawed outputs from reaching clients as finished work 10. Public commentary on enterprise AI governance identifies six standing risk areas, including regulatory compliance and technology security, that need active monitoring rather than periodic audit 11. Client data protection tightens the loop further: dynamic governance and control systems are what keep AI-assisted workflows from becoming a security incident waiting to be named 12.
Priced correctly, that tax is a defensible line item—governance hours, substantiation logs, approval-gate documentation—inside the margin-per-deliverable calculation. Priced incorrectly, it is what turns an apparent efficiency gain into a legal and reputational liability the first time a claim is challenged. Owners should measure governance overhead per deliverable type and load it into unit cost before quoting the retainer, not after the first client dispute.
What an AI-native agency actually looks like on Monday morning
The office looks quieter. Not because staff left, but because the production stand-up is shorter. Junior producers open the week reviewing prompt libraries and briefs already loaded into the workflow, not chasing assignments across three project tools. Senior strategists sit with client dashboards, deciding which recommendations clear the approval gate this week and which need another substantiation pass before they ship.
The metrics on the wall changed. Utilization is gone. In its place: margin per approved deliverable by client, rework rate by deliverable type, and governance hours logged against each retainer. Sales and marketing represent roughly 28 percent of the total potential economic value from generative AI across job functions 2, and an AI-native agency is built to convert that potential into P&L rather than into faster drafts that never move the margin line.
The client conversation also shifts. Kickoff calls open with positioning and outcome targets, not deliverable counts. Weekly reporting shows what was recommended, what was approved, what shipped, and what moved the KPI—the same governed loop Vectoron was built to run. That is what agency efficiency now means: a workflow where humans decide and AI executes, measured one approved unit at a time.
 Organizations setting efficiency as an AI objective
Organizations setting efficiency as an AI objective
Organizations setting efficiency as an AI objective
Frequently Asked Questions
References
- 1.The State of AI: Global Survey 2025 - McKinsey.
- 2.AI in the workplace: A report for 2025 - McKinsey.
- 3.ChatGPT use among Americans roughly doubled since 2023 - Pew Research Center.
- 4.About 1 in 5 U.S. workers now use AI in their job, up since last year - Pew Research Center.
- 5.On Future AI Use in Workplace, US Workers More Worried Than Hopeful - Pew Research Center.
- 6.3. Workers' experience with AI chatbots in their jobs - Pew Research Center.
- 7.Advertising and Marketing - Federal Trade Commission.
- 8.FTC Announces Crackdown on Deceptive AI Claims and Schemes.
- 9.AI Risk Management Framework - NIST.
- 10.Towards a Standard for Identifying and Managing Bias in Artificial Intelligence.
- 11.RFI Comments - NIST AI Executive Order 14110.
- 12.Feedback on the NIST Cybersecurity Framework 2.0 Initial Public Draft.