Key Takeaways
- Patient education materials from top medical journals consistently exceed recommended reading levels, exposing a workflow gap that agency selection must directly address through explicit grade-level targets and structured editing 2.
- Treat the partner as a clinical content operating system rather than a writing service, because governance, throughput, and transparency matter more than individual bylines for multi-location operators 10.
- Demand three governance artifacts upfront—substantiation policy, disclosure protocol, and change log—plus a medical review SLA with named credentialed reviewers per service line and source-mapped citations 4.
- Operationalize plain language with named owners, default grade-level targets, comprehension testing, and a documented protocol for pushing back when reviewers reintroduce specialist vocabulary 1.
- Require a written map of AI-assisted versus human-reviewed stages, a citation verification protocol, and an audit trail of human approvals to meet AMA explainability expectations 5, 6.
- Score partners against a weighted rubric where medical review SLA, AI transparency, and account-level scope carry veto weight regardless of total score or writing sample quality.
- Per-location billing structurally caps content velocity through duplicated briefs, fragmented review queues, and multiplying account managers; account-level execution makes the marginal location near-zero cost.
- Scope portal microcopy, intake instructions, and service-line pages under one readability target and reviewer pool, since fragmented voice across digital surfaces suppresses patient engagement 8.
The Readability Gap Most Healthcare Marketing Teams Inherit
Clinical authorship does not produce patient-usable content. An observational analysis of 2,585 patient education materials drawn from high-impact medical journals between 1998 and 2018 found that the majority were written above the reading levels recommended for general patient audiences 2. The materials were produced inside the most rigorous editorial environments in medicine, and they still failed the basic comprehension threshold their own patients needed to act on them.
That finding reframes the medical content writing agency selection conversation. Healthcare marketing leaders at multi-location operators typically inherit two content streams: clinician-authored explanations that legal cleared but patients abandon, and marketing-authored pages that read fluently but cannot survive medical review. Both fail the same test, which is whether a person searching for care at 11 p.m. on a phone can read the page, understand the recommendation, and book.
The readability gap is not a writing-talent problem. It is a workflow problem. Materials produced without explicit reading-level targets, structured plain-language editing, and audience testing tend to drift back toward the vocabulary of the people writing them 1. Plain language benefits even patients with high health literacy, because illness, pain, and time pressure compress the cognitive bandwidth available to process clinical information 3.
For growth teams evaluating partners, this gap becomes the diagnostic. An agency that cannot name its target grade level, describe the editing pass that enforces it, and show before-and-after readability scores on prior work is not solving the problem the published record has been documenting for two decades. The rest of the criteria in this article follow from that single test.
Reframing the Selection Decision: From Writing Quality to Clinical Content Operating System
The category label "medical content writing agency" misdirects the search. It implies that the deliverable is prose and the differentiator is talent. Healthcare marketing leaders running 10 to 200 locations have a different problem: they need a clinical content operating system that produces accurate, plain-language assets across every service line on a predictable cadence, survives medical and legal review without rework loops, and stays auditable when the FTC, state boards, or a plaintiff's counsel asks how a claim was substantiated.
That reframing changes what gets evaluated. Writing samples become table stakes. The decision criteria move to governance, throughput, and transparency. Health literacy research treats clear communication as a mediator between content and outcomes, not a stylistic preference, which means the production process matters more than any single byline 10. Editorial transparency expectations from the AMA Code of Medical Ethics extend the same logic to disclosure, conflict handling, and accurate representation of services 4. And the 2025 AMA policy on explainable AI raises the bar again for any partner using language models in the production line 5.
For multi-location operators, the operating-system frame also exposes a scope problem most agencies still bill around. A partner that produces excellent individual articles but cannot coordinate publishing, medical review, and updates across 40 sites and seven service lines is not solving the throughput half of the equation. The sections that follow score partners against both halves: the governance layer that protects the brand, and the execution layer that moves content into market fast enough to matter.
The Governance Layer: Editorial Workflow, Transparency, and Disclosure
Editorial Process Aligned With AMA Transparency Expectations
Governance begins with the documented editorial workflow, not the writer roster. AMA Code of Medical Ethics Opinion 11.2.4 establishes that healthcare communication must accurately represent services, disclose conflicts, and avoid misleading framing in how care is described and financed 4. A medical content writing agency that cannot produce its editorial standards manual on request, with named roles for substantiation, disclosure, and conflict review, is operating outside the expectations that legal and compliance reviewers already apply to clinical communication.
Three process artifacts separate governance-ready partners from generic content vendors:
- A written substantiation policy that ties every clinical claim to a primary source, a guideline, or an internal clinical reviewer's sign-off—not to a search result or a competitor's page.
- A disclosure protocol covering sponsored content, physician contributors, and any service-line claim that touches outcomes, pricing, or comparative effectiveness.
- A change log that records who edited a clinical statement, when, and why, so that a claim can be traced backward when a state board or plaintiff's counsel asks.
Healthcare marketing leaders evaluating partners should request these three artifacts before sample work. Agencies that produce them quickly have already absorbed the cost of governance into their operating model. Agencies that promise to build them after the contract starts will bill that build to the first ninety days of the engagement.
Medical Review SLAs and Citation Discipline
Medical review is the bottleneck that determines content velocity. A partner without a defined service-level agreement for clinical review will move at the speed of whichever clinician answers email that week, which is the failure mode most multi-location operators already know from in-house workflows.
A defensible medical review SLA specifies four things:
- The credentials required for the reviewer assigned to each service line.
- The turnaround window for first review and revision rounds.
- The escalation path when a reviewer disagrees with a draft.
- The documentation captured at sign-off.
Operators running cardiology, behavioral health, and orthopedics under one brand cannot accept a single generalist reviewer for all three—the literature on service-line-specific readability and quality gaps makes that staffing choice visible in the published output 7.
Citation discipline is the second half of review. Every clinical assertion in a finished asset should map to a source the reviewer can open in one click, and the agency should retain that source map for the life of the content. This is not academic formality. When the FTC, a state attorney general, or a malpractice carrier requests the basis for a claim made on a service-line page, the agency that maintained citation hygiene produces an answer in hours. The agency that did not produces a problem.
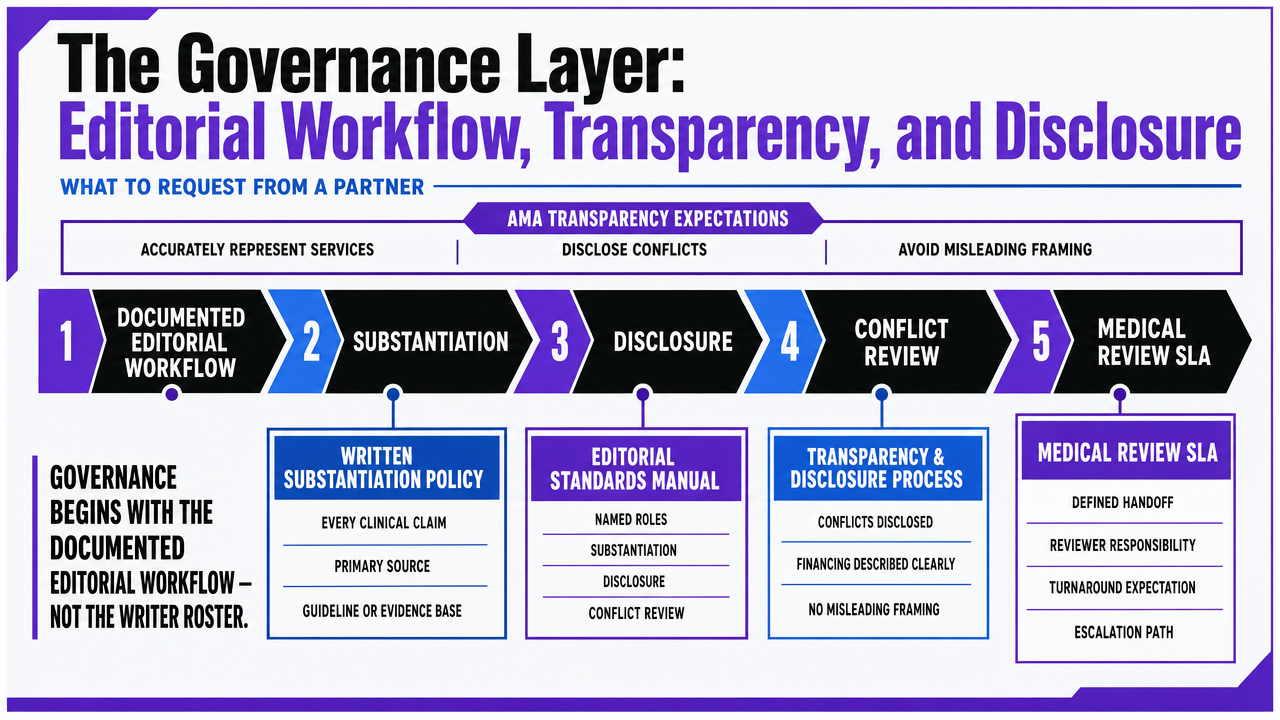 Visualize the three governance artifacts and the medical review SLA components described in the section, giving readers a scannable reference for what to request from a partner
Visualize the three governance artifacts and the medical review SLA components described in the section, giving readers a scannable reference for what to request from a partner
Experience AI-Driven Medical Content Production Now
Test real-world medical content workflows and publish live during your trial—see measurable results before you commit.
The Health Literacy Layer: Plain Language as an Operational Standard
Orthopedics offers the cleanest test case for service-line readability failure. A standardized-scoring evaluation of online patient education materials for orthopedic conditions found that a substantial share scored as suboptimal quality and were written above recommended reading levels, which means patients researching rotator cuff repair, ACL reconstruction, or joint replacement encounter content their own surgeons would not expect a non-clinical reader to absorb 7. The same pattern recurs across service lines a multi-location operator typically runs—cardiology pre-procedure prep, behavioral health intake, dermatology aftercare—where vocabulary drift is harder to catch because the reviewers and the writers share the same expert lexicon.
The CDC's plain language guidance reduces the fix to three operational steps:
- Simplify vocabulary against an explicit grade-level target.
- Organize information so the action the reader needs to take appears before the explanation of why.
- Test materials with members of the intended audience before publication 1.
None of those steps requires advanced tooling. All three require an agency to have built them into the production line as named handoffs with named owners, not as a final-pass sensibility a senior editor applies when there is time.
Three questions separate partners that operationalize plain language from partners that aspire to it:
- What grade level does the agency write to by default, and how is that level verified on every asset before clinical review?
- Who runs comprehension testing with patient-representative readers, and on what cadence—every asset, every service line refresh, or only at brand launch?
- When a clinical reviewer reintroduces specialist vocabulary during medical review, who is authorized to push back, and what is the documented protocol for resolving the disagreement?
Agencies that answer those three questions with named roles, target numbers, and a written workflow have absorbed health literacy into the operating model. Agencies that answer with adjectives have not, and the published readability record predicts what their output will look like at scale 7.
The AI Layer: Explainability, Human Review, and What Belongs to Each
Every medical content writing agency now uses AI somewhere in the production line. The honest question is not whether AI touches the work but where it touches, what it changes, and who can explain the output when a clinician or regulator asks. The 2025 AMA policy on AI in medicine sets that expectation directly: clinical AI tools should be explainable, ship with accessible safety and efficacy data, and produce outputs a human can interpret before acting on them 5. Healthcare marketing leaders should apply the same standard to any partner generating medical content with language models in the pipeline.
The narrative review of AI in medical writing maps the division of labor cleanly. AI performs well on drafting from structured briefs, surfacing candidate sources during literature search, normalizing tone, and catching mechanical errors during editing. It performs poorly—and dangerously—on clinical accuracy, source verification, accountability for claims, and explanation of why a particular recommendation was framed a particular way 6. Those four functions belong to credentialed human reviewers, full stop. An agency that lets AI close the loop on clinical accuracy is not running a medical content operation; it is running a liability generator.
Three disclosures separate partners that have operationalized AI governance from partners that have not:
- A written statement of which production stages use AI assistance and which require human medical review, available before contract signing.
- A sourcing protocol that prevents AI-suggested citations from entering a finished asset without a human opening and confirming the source.
- An audit trail that records the human reviewer who approved each clinical claim, so the chain of accountability survives staff turnover and regulator inquiry.
Agencies that cannot describe their AI workflow at this level of granularity are asking the operator to absorb the explainability gap. Agencies that can are absorbing it themselves, which is what the AMA policy and the medical writing literature both now expect 5, 6.
See How Leading Healthcare Marketers Streamline Content Operations at Scale
Connect with a specialist to review unified, AI-driven workflows for medical content, SEO, and PPC management across all locations—purpose-built for enterprise healthcare and agency teams.
The Vendor Diligence Rubric: Scoring a Medical Content Partner
A defensible vendor selection survives three audiences: legal, clinical, and finance. The rubric below assigns weighted criteria that healthcare marketing leaders can score on a 1–5 scale during the evaluation cycle, then defend in committee with documented artifacts rather than vendor adjectives.
| Criterion | Weight | What a 5 looks like | What a 1 looks like ||---|---|---|---|| Medical review SLA | 20% | Named credentialed reviewers per service line, written turnaround windows, documented sign-off captured per asset | Single generalist reviewer, ad hoc turnaround, no sign-off record || Readability targets and verification | 15% | Explicit grade-level target, automated scoring on every asset, comprehension testing with patient-representative readers 1| No stated target, readability assessed by editor sensibility || AI transparency and disclosure | 15% | Written map of AI-assisted vs. human-reviewed stages, sourcing protocol, audit trail aligned with AMA explainability expectations 5, 6| AI use undisclosed or described in marketing language only || Citation discipline | 10% | Every clinical claim linked to a primary source, source map retained for content lifetime | Claims sourced to competitor pages or unretrievable searches || Editorial transparency per AMA 11.2.4 | 10% | Substantiation policy, disclosure protocol, change log produced on request 4| Standards described verbally, no artifacts available || Account-level scope | 15% | Single plan covers all locations and service lines, no per-site coordination overhead | Per-location billing, separate contracts, parallel account managers || Service-line depth | 10% | Documented reviewer coverage across the operator's full service mix | Generalist coverage with gaps in specialty lines || Multi-channel coordination | 5% | Content, SEO, and publishing executed against one plan | Content delivered in isolation from distribution surface |
A partner scoring below 3 on medical review SLA, AI transparency, or account-level scope should not advance regardless of total score. Those three criteria carry veto weight because each one, failed at scale, produces a regulatory, clinical, or financial exposure that no editorial quality can offset. The rubric is meant to be circulated before the first sample review, not after, so that writing samples are evaluated as evidence of the operating model rather than as the decision itself.
If You Manage Multiple Locations: Account-Level Execution vs. Per-Location Billing
Why Per-Location Billing Caps Content Velocity
This section narrows to operators running 10 or more locations under one brand, where the billing unit of the agency contract becomes the governing constraint on output. A per-location engagement structurally caps content velocity in three places at once:
- Each site is scoped, briefed, and invoiced as its own engagement, which means every service-line update has to be replicated across separate workstreams rather than authored once and distributed.
- Medical review queues fragment along the same lines, so a cardiology update cleared for Site A waits in a separate review cycle before it can publish at Sites B through R.
- Account managers multiply with the location count, and the coordination tax compounds before any writing happens.
The ceiling is not a budget number; it is a workflow shape. Even when an operator funds more output, per-location contracts force the agency to spend marginal hours on duplication rather than new assets. Service-line gaps appear at the locations with the lowest individual budgets, which are usually the newest acquisitions—the exact sites where organic share of voice needs to move fastest.
Structural Cost Behavior: A Comparison Operators Can Defend
The defensible comparison for legal and finance committees is structural, not dollar-denominated. The table below uses indexed units rather than invented prices, with three variables the operator supplies:
L : number of locations
S : number of service lines
A : articles per service line per quarter
| Dimension | Per-Location Billing | Account-Level Execution ||---|---|---|| Scope unit | One site, one contract | All L locations under one plan || Coordination overhead | Scales linearly with L (account managers, briefs, invoices) | Fixed at the account level regardless of L || Medical review handling | Parallel queues per site, duplicate reviewer sign-off | One reviewer pool per service line, signed off once and distributed 4|| Content velocity ceiling | Capped by slowest per-site workflow; output ≈ A × S per location, with duplication tax | Output ≈ A × S at the account level, distributed across all L sites || Scaling behavior as locations are added | Cost and coordination grow with L; new sites inherit gaps | Marginal cost of adding a location is near-zero for shared assets || Service-line depth | Fragmented; smallest sites get generalist coverage | Reviewer depth pooled across all sites in the service line 7|
The operator implication is direct. A growth program that adds five locations a year under per-location billing absorbs five additional coordination loads and five additional review queues, even when the clinical content the new sites need is substantively identical to content the brand has already published. Account-level execution treats the brand as the unit of work, so the marginal location inherits the existing asset library, reviewer pool, and readability standard on day one. That is the difference between a content program that scales with the footprint and one that taxes every expansion decision.
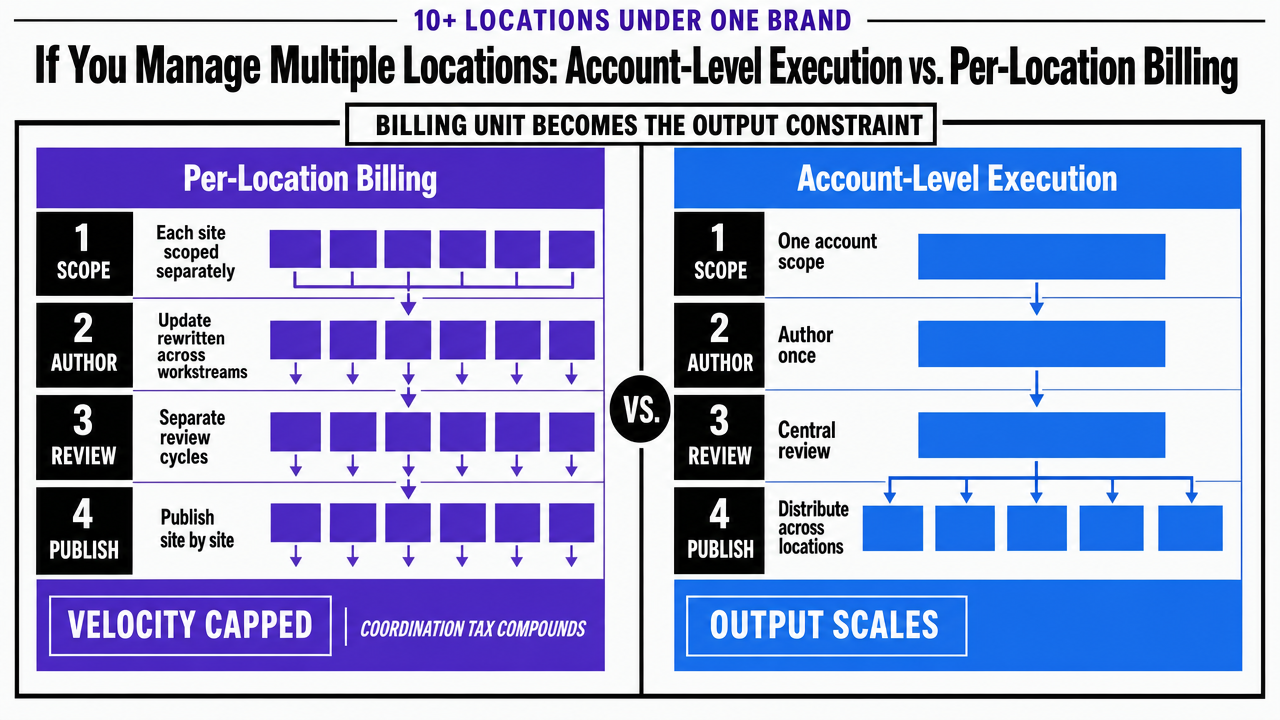 Render the comparison table from the section as a side-by-side operating-model infographic so multi-location operators can defend the structural argument visually
Render the comparison table from the section as a side-by-side operating-model infographic so multi-location operators can defend the structural argument visually
Digital Surfaces: Portal, Site, and Service-Line Content as a Single System
Patient portals, service-line pages, and condition explainers are usually authored by different teams under different briefs, which is why they read like different brands to the same patient inside a single login session. A scoping review of health literacy, digital health literacy, and patient portals found that limited literacy on either axis is associated with lower use and engagement with digital health tools, meaning fragmented voice and inconsistent reading levels across surfaces directly suppress the behavior the operator is paying to produce 8. The same pattern appears in the broader literature on online health information seeking, where patients with limited health literacy struggle to appraise quality across the pages they land on 9.
The agency selection question follows from those findings. A medical content writing partner working only at the marketing-site layer cannot fix portal copy that contradicts the service-line page two clicks earlier. Healthcare marketing leaders should require partners to scope portal microcopy, intake instructions, and post-visit explainers into the same editorial standard as acquisition pages, with one readability target, one substantiation policy, and one reviewer pool covering the full patient path. That is the difference between a content vendor and a system that treats every digital surface as one asset class.
Streamline Medical Content Delivery Across Every Location—From One Unified Platform
Gain instant access to an AI-driven content engine built for healthcare networks—coordinate strategy, automate approvals, and publish clinically accurate content at scale, all managed centrally for every site and service line.
Red Flags That Surface in the First 30 Days
The first month of any medical content engagement exposes whether the operating model described in the pitch deck actually exists. Four signals predict the rest of the relationship:
- Draft turnaround that slips on the first three assets, with the agency citing reviewer availability rather than producing the named-credentialed-reviewer-per-service-line roster promised during selection.
- Citations that point to competitor pages, WebMD, or unretrievable searches instead of primary sources, indicating the substantiation policy was a document rather than a workflow 4.
- Finished assets that score above the stated grade-level target with no record of who measured readability or when, which means the plain-language standard exists in the proposal but not the production line 1.
- AI use that surfaces through stylistic tells the agency cannot explain when asked—an explainability failure the 2025 AMA policy explicitly flags as unacceptable in clinical communication 5.
Any one of these in the first thirty days warrants a documented escalation; two warrants exit planning before the quarterly invoice lands.
Where Brand Selection Lands
Selection lands on three artifacts a partner can produce before the contract is signed:
- A documented editorial standard with named reviewer roles.
- An AI workflow map distinguishing assisted stages from human-reviewed stages 5.
- An account-level scope statement that prices the brand rather than the location.
Partners that hand those over in week one have already built the operating system. Partners that promise to build them later will bill the build to the engagement. For multi-location operators evaluating account-level execution models, Vectoron is one option in that category, alongside any partner that meets the same governance and throughput tests this article has scored against.
Frequently Asked Questions
References
- 1.Plain Language Materials & Resources | Health Literacy.
- 2.Readability of Patient Education Materials From High-Impact Medical Journals.
- 3.Plain language communication as a priority competency for medical professionals.
- 4.Transparency in Health Care - AMA Code of Medical Ethics Opinion 11.2.4.
- 5.AMA adopts new policy aimed at ensuring transparency in AI tools.
- 6.The landscape of artificial intelligence in medical writing: a narrative review.
- 7.Quality and readability of online patient education materials for orthopedic conditions.
- 8.Health literacy, digital health literacy, and patient portals: A scoping review.
- 9.Online health information seeking and health literacy: a systematic review.
- 10.Health literacy and its importance for effective communication.