Key Takeaways
- PPC waste is fundamentally a detection latency problem: the gap between when a query, asset, or audience starts underperforming and when someone intervenes is where budget actually leaks.
- Spend leaks across four layers—query, audience, creative, and measurement—with measurement waste being the most expensive because a misaligned conversion signal corrupts every downstream optimization decision.
- A continuous optimization system requires explicit signal sources, written numeric thresholds, and defined intervention windows, while humans stay in the loop for claim changes, material budget shifts, and compliance-sensitive targeting.
- Beyond five to ten accounts, weekly human cadence breaks down and an AI-platform-assisted model outperforms expanded in-house teams or agency retainers on cost per managed account and optimization cadence.
Waste Is a Detection Latency Problem
Most PPC waste does not begin as a targeting mistake. It begins as a query, placement, or audience that started underperforming on a Tuesday and went unnoticed until the following Monday's audit. Every day in between is paid for at full rate.
That gap between underperformance and intervention is the actual problem. Demand gen teams running $30K to $500K per month in paid search rarely lose budget because they don't know what a negative keyword is. They lose it because the search-term report only gets a serious pass once a week, the placement exclusions list only gets touched when CPL spikes, and asset-level CTR decay is invisible until the campaign's blended numbers turn. Waste compounds inside that window.
Reframing PPC campaign management around detection latency changes what the job actually is. Bid strategy and match-type discipline still matter, but they are inputs to a system whose performance is determined by how fast the system notices something is off and how fast it acts. The relevant questions become: what signals are being watched, at what cadence, against what thresholds, and who or what intervenes when a threshold trips.
This is also why automation has moved from optional to baseline. McKinsey's 2024 survey found 65% of organizations regularly using generative AI in at least one business function, with marketing and sales among the most common deployments 11. The teams pulling ahead are not the ones with better audits. They are the ones whose monitoring layer never sleeps and whose humans spend their hours on decisions the machine cannot make.
The Four Layers Where Spend Leaks
Query Waste: The Search-Term Report Lag
Query waste is the most visible category and the most chronically under-managed. Broad match and phrase match keywords pull in search terms that the original keyword list never anticipated, and a meaningful share of those terms convert poorly or not at all. The waste is not in the existence of those queries. It is in how long they keep spending before someone reads the report.
A monthly audit means an off-intent query can burn budget for up to thirty days. A weekly audit cuts that exposure to seven. Continuous monitoring with rule-based or model-driven flagging compresses it to hours. The math is straightforward: if 12% of spend is going to terms that will eventually be excluded, the only variable is how many days that 12% persists before the exclusion happens. Audit cadence is the lever.
Demand gen teams using machine layers to scan search-term reports daily are not doing anything exotic. They are matching the cadence of the auction itself, which never pauses for a Monday meeting.
The operational question is not whether to monitor continuously. It is which queries trip an automatic exclusion, which queries trip a human review, and which queries trip nothing because they are still being learned.
Audience Waste: Targeting Drift and Match-Type Decay
Audience waste is quieter than query waste because it hides inside aggregate numbers. A campaign's blended CPL can look stable while one audience segment quietly absorbs an outsized share of spend at twice the cost per conversion. The averaging effect masks the leak until a quarterly review forces a segment-level breakout.
The drift usually traces back to one of three sources:
- In-market and affinity segments expand over time as platforms refresh their definitions, often pulling in adjacent intent that was not part of the original targeting thesis.
- Lookalike or similar-audience seeds age, so the audience built on a six-month-old converter list slowly stops resembling current buyers.
- Smart bidding strategies, given loose audience parameters, will reallocate impressions toward segments that hit the conversion goal cheaply on paper but downstream poorly in CRM.
Match-type behavior compounds this. Broad match keywords paired with value-based bidding will follow the algorithm's interpretation of intent, which can drift from the original keyword theme within weeks. The remedy is not to abandon broad match. It is to instrument audience and match-type performance at the segment level, set decay thresholds, and rebuild seed lists on a fixed cadence rather than waiting for blended metrics to deteriorate.
Creative Waste: Asset-Level CTR and Fatigue Curves
Responsive search ads obscure where creative is actually losing money. The campaign report shows a healthy combined CTR, but the asset-level breakdown often reveals that two of fifteen headlines are doing most of the work and four are dragging the rotation down. Until those underperformers are paused, the algorithm keeps serving them because it is optimizing within the asset pool it was given.
Fatigue is the second creative leak. CTR for a given asset combination decays over an exposure window as the same impressions hit returning users. The decay is usually gradual, which is exactly why it goes unnoticed: no single week shows a cliff, but month-over-month asset performance bends downward while CPC creeps upward as Quality Score signals soften.
Disciplined creative management treats assets as a portfolio with a refresh schedule, not as a one-time launch. Practical operating rules:
- Review asset-level CTR and conversion attribution weekly.
- Pause assets that fall below a defined performance percentile relative to peers in the same ad group.
- Queue replacements before pausing so the rotation does not collapse to two headlines while new copy is in approval.
Creative testing is not a quarterly campaign. It is a continuous pipeline with intake, review, launch, and retirement stages.
Measurement Waste: Conversion Definitions That Mislead Bidding
Measurement waste is the most expensive layer because it corrupts every other layer. When the conversion event fed to the bidding algorithm does not match the business outcome, the algorithm optimizes faithfully toward the wrong target. Every dollar spent under that signal is structurally misallocated, regardless of how clean the search-term report looks.
The common failure modes are familiar but persistent:
- Form-fills counted as conversions when only a fraction become qualified opportunities.
- Phone calls credited at the click without duration filters, so wrong numbers and 15-second hang-ups count the same as booked consultations.
- Demo requests weighted equally across tiers, so the algorithm chases the cheapest demo regardless of fit.
- Offline conversion data not piped back into the platform, so the model never learns which leads actually closed.
Fixing measurement waste is less about adding tracking and more about subtracting noise. The conversion signal sent to the bidder should be the closest event to revenue that can be measured reliably and at sufficient volume. For most SaaS demand gen programs, that means SQL or pipeline-stage conversions imported from the CRM rather than top-of-funnel form-fills. The bid algorithm will then steer toward the audiences and queries that produce qualified pipeline, and the four-layer waste model starts compounding in the right direction rather than the wrong one.
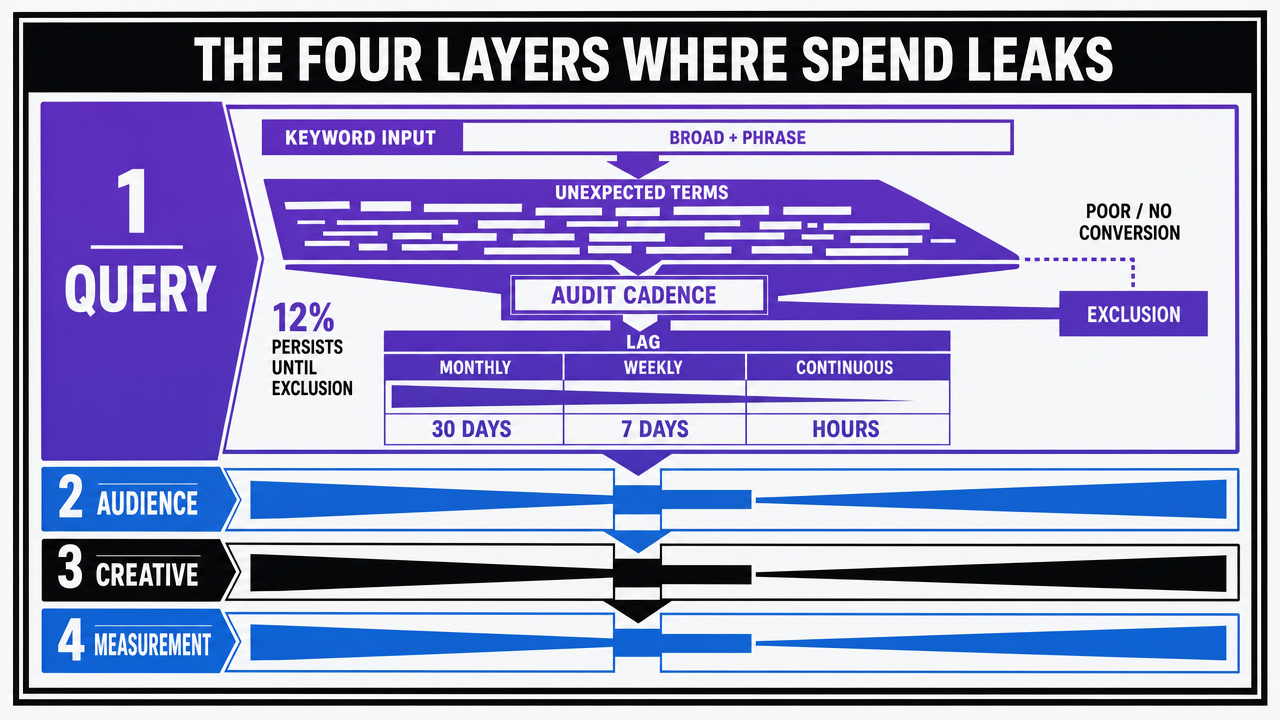 Visualize the four-layer waste framework introduced in this section, since the article explicitly enumerates Query, Audience, Creative, and Measurement layers as a comparison framework
Visualize the four-layer waste framework introduced in this section, since the article explicitly enumerates Query, Audience, Creative, and Measurement layers as a comparison framework
Test PPC optimization efficiency in real time
Experience live campaign analysis and measurable spend reduction during your trial—no delays, no simulation, just actual results.
Designing a Continuous Optimization System
Signal Sources, Thresholds, and Intervention Windows
A continuous optimization system has three moving parts: where the signal comes from, what threshold trips action, and how fast the window closes between trip and intervention. Most demand gen teams have the first part figured out and the other two improvised.
Signal sources for a paid search program are narrower than they look. Search-term reports, asset-level performance, audience segment breakdowns, impression share lost to budget and rank, landing page conversion rate by ad group, and CRM-stage outcomes piped back through offline conversion imports. Six surfaces, monitored at different frequencies. The auction generates data continuously; the question is which surfaces get sampled hourly, which daily, and which weekly.
Thresholds are where most programs leave money on the table. A threshold without a number is a suggestion. Useful thresholds look like: a search term that has accumulated 3x the target CPA without a conversion gets auto-excluded; an asset whose CTR falls below the 25th percentile of its ad group for seven consecutive days gets queued for pause; an audience segment whose blended CPL exceeds the campaign average by 40% over a rolling 14-day window gets flagged for human review. The specific numbers are program-dependent. The discipline of writing them down is not.
Intervention windows separate flagging from acting. A signal that fires on Tuesday and waits for Friday's standup has already wasted three days. The operational design choice is which trips trigger immediate machine action, which trigger same-day human review, and which enter a weekly batch. Each tier should be explicit, documented, and revisited quarterly as the program matures and the thresholds get sharper.
Where Humans Stay in the Loop
Continuous monitoring does not mean removing judgment. It means moving judgment to the decisions that actually need it.
Three categories of decisions belong with a person:
- Anything that changes the brand's claim surface—new ad copy, new landing page headlines, new value propositions—needs human review because substantiation, tone, and competitive positioning are not threshold problems.
- Anything that reallocates budget across campaigns or channels at material scale should have a human approval step, because the bidding algorithm cannot see strategic context like a pricing change, a product launch, or a sales-team capacity constraint.
- Anything that touches sensitive query categories or audience definitions where targeting drift could create compliance exposure needs a reviewer, not just a rule.
The work that does not need a human in the loop is the high-frequency, low-judgment maintenance that consumed most of the demand gen manager's week under the old model: negative keyword additions for clearly off-intent queries, pausing assets that have failed objective performance tests, adjusting bids inside pre-set guardrails. Pushing that work to the monitoring layer is what frees the hours that get spent on attribution, lifecycle, and experimentation strategy—the work that actually compounds.
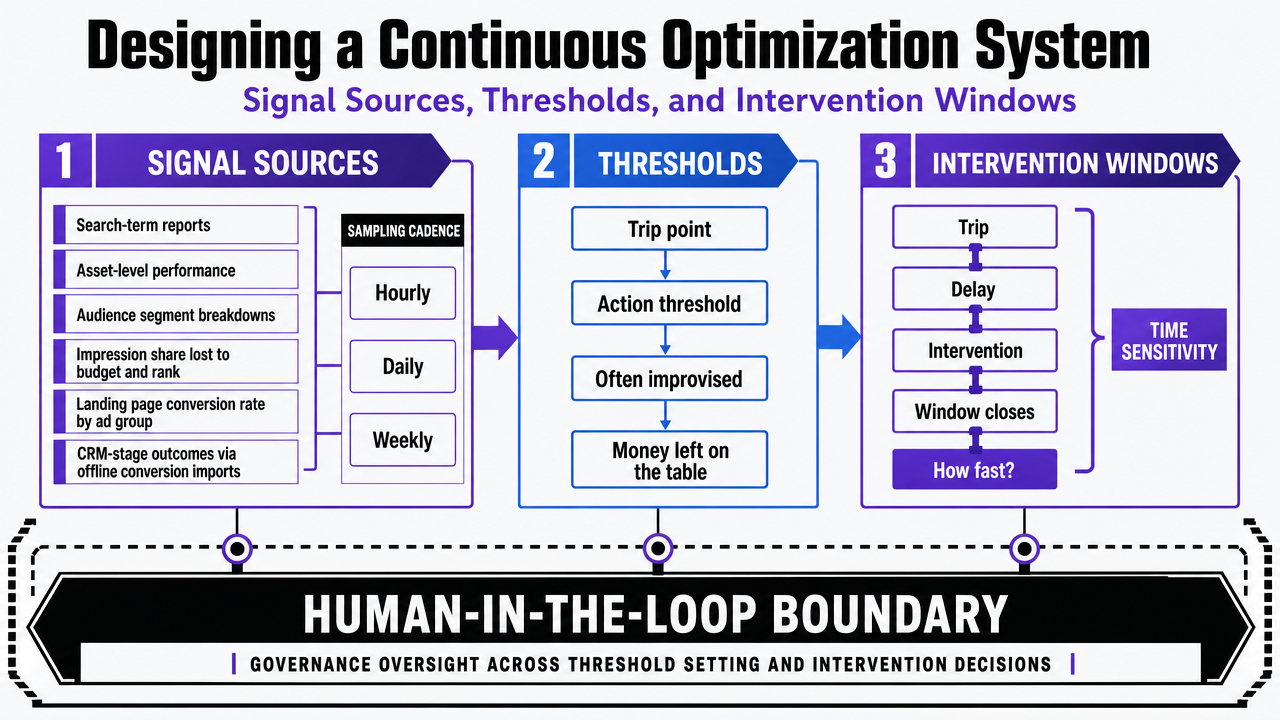 Visualize the three-part operating model (signal sources, thresholds, intervention windows) and the human-in-the-loop boundary that this section defines as a governance/operating framework
Visualize the three-part operating model (signal sources, thresholds, intervention windows) and the human-in-the-loop boundary that this section defines as a governance/operating framework
Eliminate PPC Waste with Autonomous, Data-Driven Campaign Management
See how leading agencies and enterprise brands automate continuous PPC optimization, reduce unproductive spend, and scale campaign efficiency—no manual monitoring or daily intervention required.
Substantiation and Funnel Guardrails in One Place
Compliance gets scattered across PPC articles for a reason: it touches every asset. The more useful move is to collapse the rules that actually govern ad copy, landing pages, and extensions into one map and treat them as guardrails on the optimization system rather than a separate workstream.
Three FTC sources do most of the work. The Health Products Compliance Guidance, issued in December 2022, sets the substantiation standard for any health-related benefit or safety claim, reflecting lessons drawn from more than 200 enforcement cases involving false or misleading health claims 14. It applies broadly across foods, supplements, OTC drugs, devices, and apps, and it generally calls for competent and reliable scientific evidence, often randomized controlled human clinical testing, behind outcome claims that appear in ads or landing pages 9. For PPC programs, the operational consequence is that headline assets making efficacy claims, landing pages featuring before/after results, and dynamic insertion logic that pulls in superlatives all need to map back to evidence the team can produce on request.
The second guardrail covers funnel design. The FTC's dark patterns staff report identifies four common tactic categories that draw enforcement attention: disguising advertisements as organic content, burying key terms or junk fees, using confusing consent flows, and tricking users into sharing data 6. PPC landing pages built for conversion velocity often drift into this territory without intending to: countdown timers that reset on refresh, pre-checked consent boxes, sign-up flows that obscure cancellation terms. Each one is a Quality Score liability and an enforcement risk in the same motion.
The third guardrail is the 2024 final rule banning fake reviews and testimonials, paid testimonials presented as organic, and certain forms of review suppression 16. This rule lands directly on the assets PPC managers tend to treat as low-effort wins: review extensions, star-rating callouts, social proof modules on landing pages, and third-party testimonial widgets. Any review-based claim used in paid creative needs a verifiable source and a documented chain back to a real customer.
The practical synthesis is a three-column map. Ad copy is governed primarily by substantiation: outcome claims tie to evidence on file. Landing pages are governed primarily by dark-pattern rules: consent, disclosure, and cancellation paths stay clear. Extensions and on-page social proof are governed primarily by the fake reviews rule: every star, quote, or endorsement traces to a verifiable source. Routing every new asset through that three-column check before it enters the optimization system keeps the monitoring layer from accelerating spend behind claims the program cannot defend.
If You Manage Multiple Accounts or Locations: Consolidation Economics
When the Math Changes at Account Volume
The article so far has been written for a single demand gen manager running one account in the $30K to $500K range. The economics of detection latency look different the moment that same manager is responsible for eight accounts, or a growth team is supporting twelve regional sites, or an agency is overseeing forty client programs. The audience scope shifts here, and the math shifts with it.
At single-account volume, a strong demand gen manager can plausibly cover the four waste layers themselves with weekly cadence and quarterly deep dives. The bottleneck is bandwidth, not capability. At ten accounts, that same person is reviewing search-term reports across roughly 200 ad groups, comparing asset-level performance across hundreds of responsive search ads, and reconciling conversion definitions against ten separate CRM instances. Weekly cadence becomes biweekly, biweekly becomes monthly, and the detection-latency problem the first half of this article described stops being a process choice. It becomes a math problem.
The consolidation question is not whether to add headcount or hire an agency. It is which combination of human attention and machine monitoring produces the lowest blended cost per managed account at the optimization cadence the auction actually requires. That framing reorders the usual build-versus-buy debate, because it puts cadence on equal footing with cost.
Three Management Models, Compared
Three operating models cover the majority of multi-account programs. Each has a defensible case, and each has a different failure mode at scale.
- The first is an expanded in-house team: a demand gen manager plus one or two analysts splitting account coverage. The cost basis is fully loaded salary, the cadence tops out at weekly for the most important accounts and monthly for the long tail, and the bandwidth absorbed by humans is high because every search-term review, asset rotation, and bid adjustment runs through a person. The model breaks when account count exceeds the team's weekly review capacity and the long-tail accounts quietly accumulate query and creative waste between audits.
- The second is a traditional agency retainer with per-account or per-location fees. The cost basis is a monthly retainer that scales with account count, the cadence is typically weekly with monthly reporting, and the bandwidth absorbed by humans shifts from the in-house team to the agency's account managers. The model breaks on coordination drag: handoffs between strategist, analyst, and client introduce latency that often exceeds the auction's tolerance for waste accumulation.
- The third is an AI-platform-assisted in-house team, where a smaller human team sets thresholds and approves material changes while a monitoring layer handles continuous detection across all accounts. The cost basis is platform subscription plus reduced headcount, with Vectoron priced at $599 per month after the two-week trial as one concrete anchor; retainer figures and salary loads are reader-supplied inputs that vary by market. Cadence is continuous rather than weekly. Bandwidth absorbed by humans drops to the decisions that actually require judgment.
McKinsey's healthcare-specific survey found that roughly half of surveyed leaders report their organizations have already implemented generative AI, with more than 80% deploying use cases to end users, and notes the emergence of agentic patterns where systems autonomously execute workflow actions 12. That adoption curve is what makes the third model operationally viable now in a way it was not three years ago. The monitoring layer is no longer experimental infrastructure; it is the same category of tooling already running in adjacent functions inside the same organizations.
PPC as One Node in a Coordinated Access Strategy
For multi-location healthcare operators specifically, the PPC program is not a standalone budget line. Forrester frames the digital front door as an orchestrated set of touchpoints—search, self-triage, virtual care, scheduling—designed to create coherent access and defend against new entrants 1. A click from a paid search ad that lands on a page where the next available appointment is three weeks out has not generated a conversion. It has generated a wasted impression with a downstream operations problem attached.
That coordination requirement is what makes the consolidation question more than a cost exercise for operators. A continuous monitoring layer that watches PPC in isolation will optimize toward whichever locations convert cheapest, which may be the locations with the most capacity, or may be the locations with the loosest qualification. Coordinating bid signals with appointment availability, service-line capacity, and competing channels is the work that distinguishes a managed program from an automated one. The platform handles the monitoring; the operator's growth team handles the coordination.
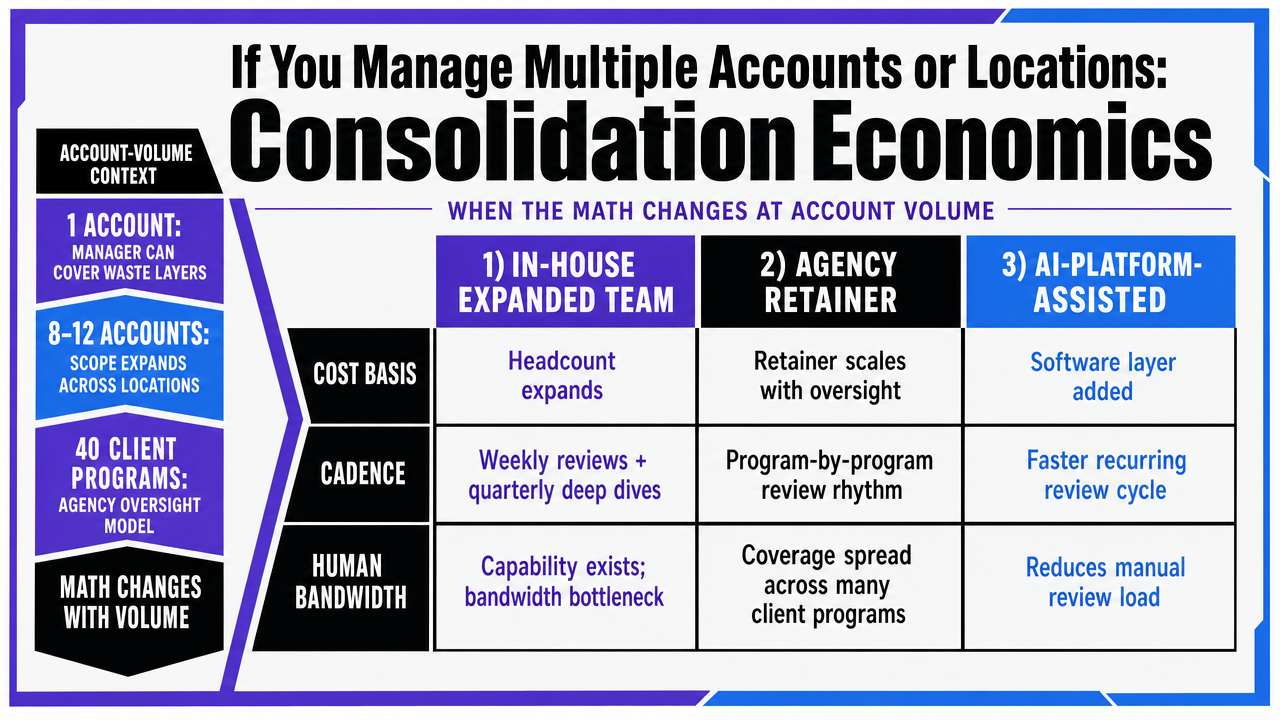 Visualize the three management models comparison (in-house expanded team, agency retainer, AI-platform-assisted) across the dimensions the article uses: cost basis, cadence, and human bandwidth
Visualize the three management models comparison (in-house expanded team, agency retainer, AI-platform-assisted) across the dimensions the article uses: cost basis, cadence, and human bandwidth
Eliminate PPC Waste with Autonomous, Data-Driven Optimization
Gain instant access to AI-powered PPC campaign management that continuously identifies underperforming spend and executes optimization tests—without daily manual analysis or added headcount.
Compounding Efficiency Over the Next Four Quarters
The teams that pull ahead on PPC efficiency over the next year are not the ones running better quarterly audits. They are the ones who treat detection latency as the primary design constraint and build the monitoring layer to match it.
The work compounds in a specific sequence:
- Quarter one is instrumentation: getting CRM-stage conversions into the bidder, writing down thresholds for query, audience, creative, and measurement layers, and routing the three FTC guardrails through a single asset-review checkpoint.
- Quarter two is cadence: moving the high-frequency, low-judgment work off the demand gen manager's calendar and onto the monitoring layer, so search-term reports, asset-level CTR, and segment drift get reviewed continuously rather than weekly.
- Quarter three is reallocation: the hours freed from maintenance get spent on attribution refinement, lifecycle integration, and structured creative testing, which are the inputs the monitoring layer cannot generate on its own.
- Quarter four is portfolio behavior: thresholds get sharper as the program accumulates outcome data, and the gap between flagged signal and executed change narrows toward the auction's own clock.
Programs that complete that arc share one trait. They stop measuring PPC management by how much was spent and start measuring it by how fast a wasted dollar gets identified and stopped. That metric is the one that compounds. For demand gen teams evaluating where their monitoring layer comes from, platforms built for this operating model—Vectoron among them—offer a starting point that does not require rebuilding the surveillance infrastructure from scratch.
Frequently Asked Questions
References
- 1.Optimize Your Digital Front Door Strategy In Healthcare To Fend Off New Competitors.
- 2.Digital Marketing for Private Practice: How to Attract New Patients.
- 3.An Overview of Social Media Use in the Field of Public Health Nutrition.
- 4.Advertising and Marketing | Federal Trade Commission.
- 5.Online Advertising and Marketing | Federal Trade Commission.
- 6.Bringing Dark Patterns to Light.
- 7.Social Advertising Effectiveness in Driving Action: A Study of Advertising Appeals in a Public Health Campaign.
- 8.Effectiveness of Social Media Marketing in Healthcare.
- 9.Health Products Compliance Guidance.
- 10.The Bad Ad Program.
- 11.The state of AI in early 2024.
- 12.Generative AI in healthcare: Adoption matures as agentic AI emerges.
- 13.Patients as Consumers: Reflections on the FDA's New Rule for Direct-to-Consumer Prescription Drug Advertising.
- 14.FTC Announces New Business Guidance for Marketers and Sellers of Health Products.
- 15.The rise of artificial intelligence in healthcare applications.
- 16.Federal Trade Commission Announces Final Rule Banning Fake Reviews and Testimonials.