
Key Takeaways
 Increase in guideline adherence with Health Information Technology (HIT)
Increase in guideline adherence with Health Information Technology (HIT)
Increase in guideline adherence with Health Information Technology (HIT)
- Replacing an agency in 2025 means choosing an execution architecture that handles account hygiene, testing, and claims review continuously, not a vendor that delivers a monthly deck.
- Compare packages on waste detection latency, statistically rigorous test cadence, and auditable decision logs with human approval gates on budget, claims, and audience changes.
- Treat compliance as a feature category: pre-publish substantiation review tied to a claims library 1, and tracking configurations that keep PHI out of third-party pixels 2.
- Apply NIST's Govern, Map, Measure, Manage functions 7to interrogate AI bid and copy automation for accountability, drift monitoring, and threshold-triggered rollback behaviors.
- Well-implemented automation produces defensible gains only when tied to defined protocols and instrumented outcomes, mirroring patterns documented in clinical decision support implementations 13.
- For multi-location operators, account-level package pricing decouples cost from site count and centralizes claims libraries and authorization mapping required under HIPAA 3.
- Use a 30-day window to seed known inefficiencies, require pre-declared sample sizes and significance thresholds, and submit ten ad variants to test pre-publish claim blocking.
- Packages, self-serve software, and AI-driven platforms diverge on waste detection, claims review, tracking defaults, and reporting; the contract behaviors matter more than the category label.
What Replacing an Agency Actually Means in 2025
Replacing a PPC agency is no longer a question of fee structure. The retainer math has not changed much in a decade, but the work itself has. Bid strategy decisions now happen inside Google's auction-time models, creative variants get generated faster than a strategist can review them, and tracking implementations sit under regulatory scrutiny that did not exist when the typical agency contract was drafted. The decision a demand gen manager faces is not which vendor to hire. It is which execution architecture takes over the work between reporting cycles.
That reframing matters because most agency value historically sat in three places: account hygiene, testing cadence, and claims review. A package or platform that replaces an agency has to do all three continuously, not in a monthly deck. It has to flag wasted spend on a Tuesday afternoon when no one is logged in, queue a statistically valid test without a human strategist designing it, and stop a non-compliant headline before it serves. Anything less is a reporting tool with a markup.
The criteria that follow treat compliance as a feature category, apply the NIST AI Risk Management Framework 7to AI-driven bid and copy automation, and end with a 30-day evaluation window structured around what the system actually does when no one is watching.
Execution Architecture: The Real Comparison Criterion
Waste Detection Latency and Continuous Audit
Waste detection latency is the time between a budget leak appearing in an account and the system surfacing it for action. Traditional agency cadence puts that latency somewhere between 7 and 30 days, depending on when the strategist next opens the account. A package built to replace that work has to compress the interval to hours, not weeks, and it has to do so without a human running queries.
The specific behaviors worth interrogating:
- how often the system scans search term reports for irrelevant matches,
- whether it monitors quality score drops at the keyword level,
- how it flags placement performance in Performance Max asset groups, and
- what triggers a pause action versus a notification.
A package that emails a weekly report has the same latency as a junior account manager who checks accounts on Mondays. A package that runs hourly anomaly detection against impression share, CPA drift, and conversion rate decay produces a different operational reality.
Continuous audit also means the system catches its own mistakes. Bid adjustments that overcorrected, audience expansions that pulled in unqualified traffic, and budget shifts that starved a performing campaign all need to be visible in the same scan that surfaces external waste.
Test Cadence and Statistical Rigor Without a Babysitter
Most agencies run tests when a strategist has time to design one. The result is a testing program that moves at the speed of human attention, which in practice means two or three meaningful experiments per quarter per account. Packages that replace agency labor need to queue, launch, and read tests without that bottleneck.
The architecture question is whether the system understands sample size. Auto-applied recommendations from ad platforms routinely declare winners on traffic volumes that would not survive a power calculation. A serious package holds tests until the minimum detectable effect is reachable given the account's conversion volume, then reads results against a pre-declared significance threshold rather than a lift percentage that looks impressive in a screenshot.
Test cadence also depends on what gets tested. Ad copy variants, landing page headlines, audience segments, bid strategy types, and conversion action weighting are all testable surfaces. A package that only runs RSA asset rotations is testing one variable while the other four drift. Demand gen managers evaluating packages should ask for the test backlog: how many concurrent experiments the system can hold, how it sequences them to avoid interaction effects, and where it logs the read.
Auditable Decision Logs and Approval Workflows
The difference between a serious replacement and a black box is whether every automated action leaves a record a human can review. Auditable decision logs answer three questions for any change: what the system did, what data triggered it, and who approved it. Without that trail, the package is making decisions the buyer cannot defend to a CFO, a compliance officer, or a regulator asking why a particular claim ran on a particular landing page.
The responsible pattern for AI-driven decisioning is assistive, not autonomous. A peer-reviewed survey of contemporary clinical AI systems found that most are designed as assistive tools requiring users to confirm or approve AI-provided information or decisions 18. The clinical context is not PPC, but the implementation principle transfers: high-stakes automation in regulated environments holds for human approval at meaningful decision points rather than executing silently.
For PPC packages, that translates to approval gates on budget changes above a threshold, new ad copy touching regulated claims, audience list construction, and conversion action redefinition. Routine bid micro-adjustments can run autonomously. Anything that changes what the public sees or how performance is counted belongs in a queue a human signs off on, with the rationale logged.
Test Automated PPC Management With Real Campaigns
Run live PPC optimizations and measure performance impact before committing to a long-term solution.
Compliance as a Primary Feature Category
Substantiation Review for Ad Copy and Landing Pages
Most package comparisons treat compliance as a checkbox under "professional services." That framing breaks down the moment a healthcare advertiser ships a headline like "clears acne in 14 days" through an automated copy generator. The FTC's Health Products Compliance Guidance is explicit that advertisers must hold "competent and reliable scientific evidence" for health benefit claims, and that evidence requirement applies whether a human strategist or a language model wrote the line 1. A package that produces ad variants without a substantiation gate is producing legal exposure at scale.
The operative question for evaluators is where the review happens. Pre-publish review built into the generation workflow stops a non-substantiated claim before it serves. Post-publish flagging waits until the ad has already run, which means the regulator-relevant document is the served impression, not the internal warning. The FTC's Health Claims resource reinforces that the standard applies to express and implied claims alike, including the kind of softened phrasing automated copy tools tend to produce when prompted for "benefit-led" variants 19.
A serious package maintains a claims library tied to source evidence, blocks generation of claims outside that library, and logs which evidence record supported each approved headline. That log is what a compliance officer reviews. Without it, the package is producing copy faster than anyone can defend it.
Tracking, Pixels, and Audience Lists Inside the Package Stack
The analytics stack a package ships with is often the most consequential compliance decision in the entire contract, and it is rarely surfaced in the sales conversation. OCR's bulletin on online tracking technologies is direct: HIPAA-regulated entities must ensure tracking tools only use and disclose protected health information in ways the rules permit, and sharing PHI with a tracking vendor generally requires patient authorization or a business associate agreement 2. The PDF companion extends the same standard to unauthenticated pages when the URL, query string, or page context could reveal a health condition 17. A package that drops a default Meta pixel on an oncology service page is not a marketing decision. It is a disclosure event.
Public sensitivity compounds the regulatory pressure. Pew's 2023 survey of U.S. adults found that 77% have little or no trust in social media company leaders to protect user privacy 14. The figure measures trust in social platform leadership rather than healthcare advertisers specifically, but it sets the operating environment for any package that relies on platform-native pixels, lookalike modeling, or cross-site retargeting to hit performance targets. Audience strategies that depend on those mechanics are running against a user base that already assumes the worst.
HIPAA's marketing provisions add a further constraint: written authorization is required before PHI is used to build marketing audiences, with limited exceptions 3. Evaluators should ask the vendor to map every audience list the package generates back to its data source and authorization basis. A package that cannot produce that map should not touch a regulated account.
Evaluating AI-Driven Packages Through the NIST Lens
Govern, Map, Measure, Manage Applied to Bid and Copy Automation
The NIST AI Risk Management Framework organizes trustworthiness work into four functions: Govern, Map, Measure, and Manage. The framework is voluntary, but it gives demand gen managers a vocabulary for interrogating a PPC package that uses AI agents to set bids, generate copy, or reallocate budget. NIST positions the framework as a tool to improve trustworthiness in the design, development, use, and evaluation of AI systems 7. That last word matters. Evaluation is the buyer's job.
Govern : Asks who owns the risk when an AI system mis-bids a campaign or ships a non-substantiated headline. A package without named accountability, escalation paths, and a documented model change policy fails this function on day one.
Map : Asks whether the vendor has identified the contexts the system operates in, including the regulatory environment of healthcare ad copy and the data sensitivities of audience construction. A vendor that cannot describe its system's intended use boundaries is selling generic automation into a regulated context.
Measure : Asks what gets monitored and how often. For bid automation, that means tracking CPA drift, impression share volatility, and the rate at which the system's recommendations are overridden by human reviewers. For copy generation, it means logging which claims were generated, which were blocked, and which were modified before publication.
Manage : Asks what the system does when a measured risk crosses a threshold. Auto-pause, escalation, rollback, and quarantine are the operative behaviors, not dashboard alerts that someone may read on Monday.
Bias, Drift, and Real-World Evaluation
AI bid and audience systems learn from the conversions they are fed, which means they amplify whatever skew exists in the input data. NIST's bias publication identifies recommendation, pattern recognition, and automated decision-making as primary risk surfaces 8. A PPC package that optimizes against a conversion definition mixing high-value patient inquiries with form-fill spam will steadily drift toward the cheaper, lower-quality signal. The drift is invisible in headline CPA numbers and obvious in the sales team's complaints six weeks later.
Evaluation has to happen in conditions that resemble production. NIST's ARIA program is built on the premise that AI risks should be tested in simulated real-world settings rather than assumed away from vendor benchmarks 9. The buyer's version of that principle is running the package against a holdout campaign, a deliberately noisy conversion stream, and a service line with thin volume before granting it the full account. Vendor case studies showing lift on mature accounts do not predict behavior on a cold launch or a long-tail service.
Public attitudes shape the operating ceiling. Pew's 2026 findings note that Americans are more likely to see AI as positive than negative for medical care over the next twenty years, while many remain concerned about its broader impact 15. Buyer trust in AI-driven analysis is growing, but the audience the ads are pointed at is not uniformly enthusiastic. Packages that lean hard on AI-generated patient-facing copy without disclosure or review are running ahead of where the audience actually is.
See How Leading Brands Streamline PPC Management Without Agency Overhead
Request a walkthrough of data-driven PPC management packages designed to eliminate wasted spend, automate optimization, and deliver measurable efficiency for multi-account teams.
What 'Well-Implemented Automation' Actually Produces
The case for replacing agency labor with packaged automation rests on a claim that deserves direct examination: that monitored, well-implemented automation outperforms manual cadence. The strongest evidence sits outside marketing. A peer-reviewed review of health information technology in clinical settings documented 30% higher guideline adherence, a 54% reduction in medication errors, and a 36% reduction in adverse drug reactions across specific implementations 13. Those figures measure patient-safety outcomes from clinical decision support systems, not PPC accounts. They do not predict CPA improvements or quality score deltas.
What they do show is the shape of the gain. The deltas appeared where the automation was tied to a defined protocol, instrumented for measurement, and embedded in a workflow that surfaced exceptions for human review. The same review noted that other implementations produced limited or no improvement, which is the operative caveat. Automation does not generalize. It performs where the inputs are clean, the success criteria are explicit, and the system gets corrected when it drifts.
Translated to PPC execution architecture, the lesson is procedural rather than numeric. Packages that define what counts as waste, what counts as a valid test read, and what counts as a compliant claim, then measure their own behavior against those definitions, are the ones that produce defensible gains. Packages that automate activity without instrumenting outcomes produce faster motion in the same direction. Evaluators should ask the vendor what the system measures about itself, not just what it measures about the account.
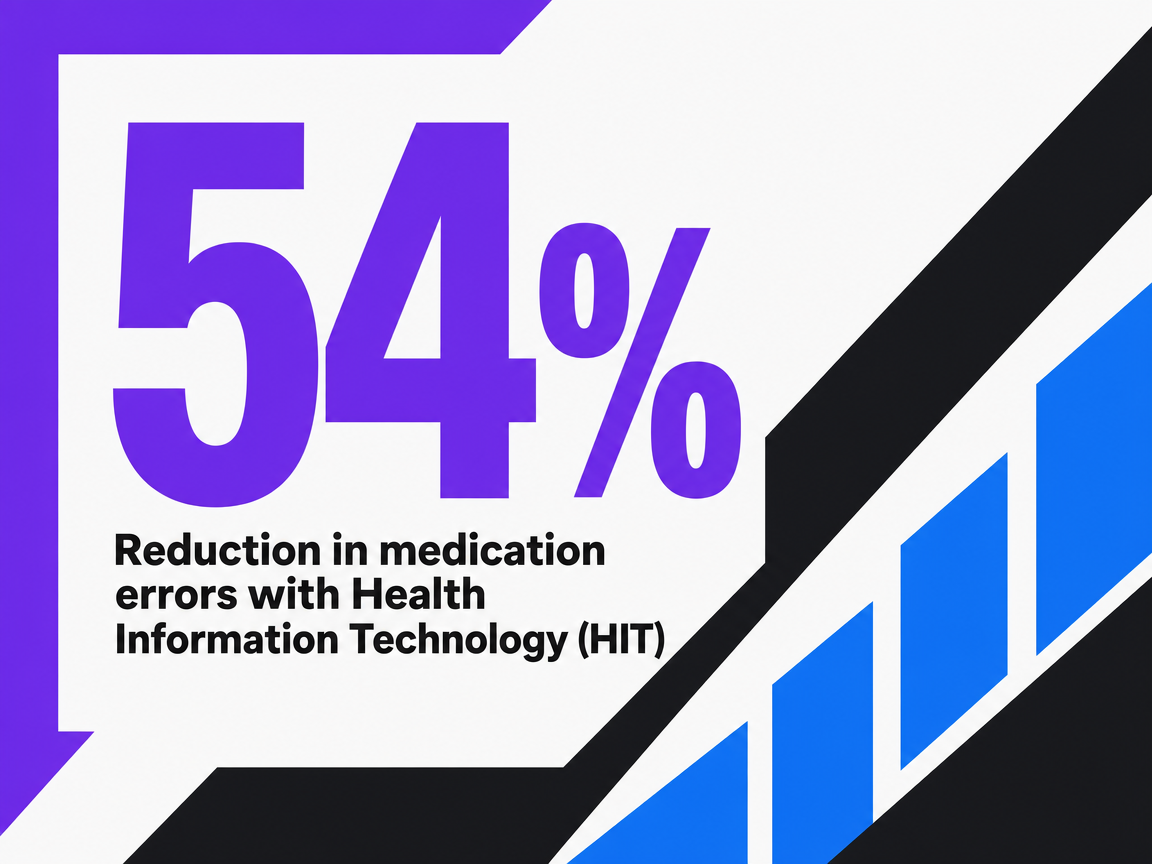 Reduction in medication errors with Health Information Technology (HIT)
Reduction in medication errors with Health Information Technology (HIT)
Reduction in medication errors with Health Information Technology (HIT)
Consolidation Economics for Multi-Location Operators
The economics shift once the buyer is a multi-location healthcare operator running paid acquisition across ten dental practices, twenty urgent care sites, or a regional specialty group with shared service lines. At that scale, the agency conversation is rarely about a single retainer. It is about per-location billing, duplicated account managers, and the coordination tax of pushing one creative update through eight separate engagement teams. A package that operates at the account level rather than the location level changes the cost surface, not just the cost number.
The variables that matter are:
L : the number of locations
R : the average per-location agency retainer
S : the average monthly ad spend per location
P : any percentage-of-spend management fee
The three replacement approaches resolve to different formulas:
| Approach | Monthly Cost Formula | Coordination Overhead | Compliance Review |
|---|---|---|---|
| Traditional agency retainer, billed per location | L × (R + P × S) | Scales with L; one account manager per cluster | Manual, varies by strategist assigned |
| In-house PPC hire plus tooling | Loaded salary + tool stack, fixed regardless of L | Bottlenecked at one operator across all sites | Depends on internal claims process |
| Account-level AI-driven package covering all locations | Platform fee independent of L (account-level pricing starts at $599/mo trial tier) | One plan, one approval queue, one claims library | Built into generation and pre-publish gates |
The retainer column is the one that compounds. At ten locations, the agency formula multiplies ten times. The in-house hire flattens the slope but introduces a single point of failure and still requires a tooling stack underneath. An account-level package decouples cost from location count entirely, which is the operative shift for operators whose growth plan involves adding sites rather than holding the current footprint.
HIPAA's authorization requirements for marketing audiences apply identically across every location 3, which means the compliance work does not scale linearly with sites either. Centralizing it in one claims library and one tracking configuration removes the per-location interpretation drift that agency rosters tend to produce.
Test Autonomous PPC Optimization—No Agency Required
Experience AI-driven PPC management that continuously identifies wasted spend, runs optimization experiments, and delivers actionable reporting—purpose-built for teams managing complex, multi-account campaigns at scale.
A 30-Day Evaluation Window for Demand Gen Managers
Operational Tests to Run Before Signing
A 30-day window is enough to learn whether a package behaves the way its demo suggests. The tests that matter measure the system's behavior between reporting cycles, not the polish of its onboarding deck.
- The first test is waste detection latency. Seed three known inefficiencies into a sandbox campaign or a low-stakes account: an irrelevant broad-match term burning impressions, a placement in Performance Max that converts at a fraction of the account average, and a budget allocation skewed toward a campaign with declining quality scores. Record how many hours pass before the system surfaces each one and what action it recommends. A package that misses any of the three inside 72 hours is running on agency cadence with a software wrapper.
- The second test is test cadence and read discipline. Ask the vendor to queue two experiments inside week one and document the minimum detectable effect, sample size assumption, and significance threshold for each. A package that cannot articulate those numbers before launch will not produce defensible reads after.
- The third test is claims review. Submit ten ad variants spanning compliant, borderline, and clearly non-substantiated language for any service line that touches health benefits. A serious system blocks the non-compliant lines pre-publish and logs the evidence record that supported each approved one, consistent with FTC substantiation expectations 1. Anything less is producing copy faster than legal can review it.
Disqualifying Signals and Switching Costs
Some findings during evaluation should end the conversation. A package that cannot produce an audit log of automated changes, name the evidence source behind a generated health claim, or describe how its tracking configuration aligns with OCR's bulletin on PHI disclosure 2is not a replacement candidate. Neither is a vendor that resists running the seeded-waste test on the grounds that "the system needs time to learn." Learning is not an exemption from instrumentation.
Switching costs deserve the same scrutiny as feature lists. The portable assets are:
- the conversion action definitions,
- audience lists with documented authorization basis 3,
- the claims library and its evidence records, and
- the decision log itself.
Vendors that hold any of those inside a proprietary format are converting a software contract into a hostage situation at renewal.
The operative question at day 30 is not whether the package performed. It is whether the package produced enough auditable behavior for a demand gen manager to defend the renewal to a CFO and a compliance officer in the same meeting.
Where Packages, Software, and AI-Driven Platforms Diverge
The market labels three different things as "PPC management packages," and the labels obscure how differently they execute. Tiered service packages from traditional agencies repackage human labor into bronze/silver/gold pricing, which addresses fee transparency but leaves the underlying cadence intact. Self-serve software gives in-house teams better dashboards, alerting, and bid-rule builders, but the system still waits for an operator to act. AI-driven platforms add a third behavior: the system proposes, drafts, or executes work between human reviews, with the decision log carrying the regulatory weight.
The divergence shows up in four places:
- Waste detection runs on a strategist's calendar in the first model, on a query the operator writes in the second, and on continuous anomaly scans in the third.
- Claims review depends on which strategist drew the assignment, on the team's internal checklist, or on a pre-publish substantiation gate tied to a claims library 1.
- Tracking configuration carries the agency's defaults, the in-house team's interpretation of OCR guidance 2, or a system-level policy applied uniformly across accounts.
- Reporting reflects what the strategist chose to highlight, what the dashboard surfaces, or what the decision log recorded.
Named options span the same spectrum: agency tiered retainers, self-serve tools like Optmyzr or Adalysis, and AI-driven platforms including Vectoron. The category label matters less than which behaviors the contract actually delivers.
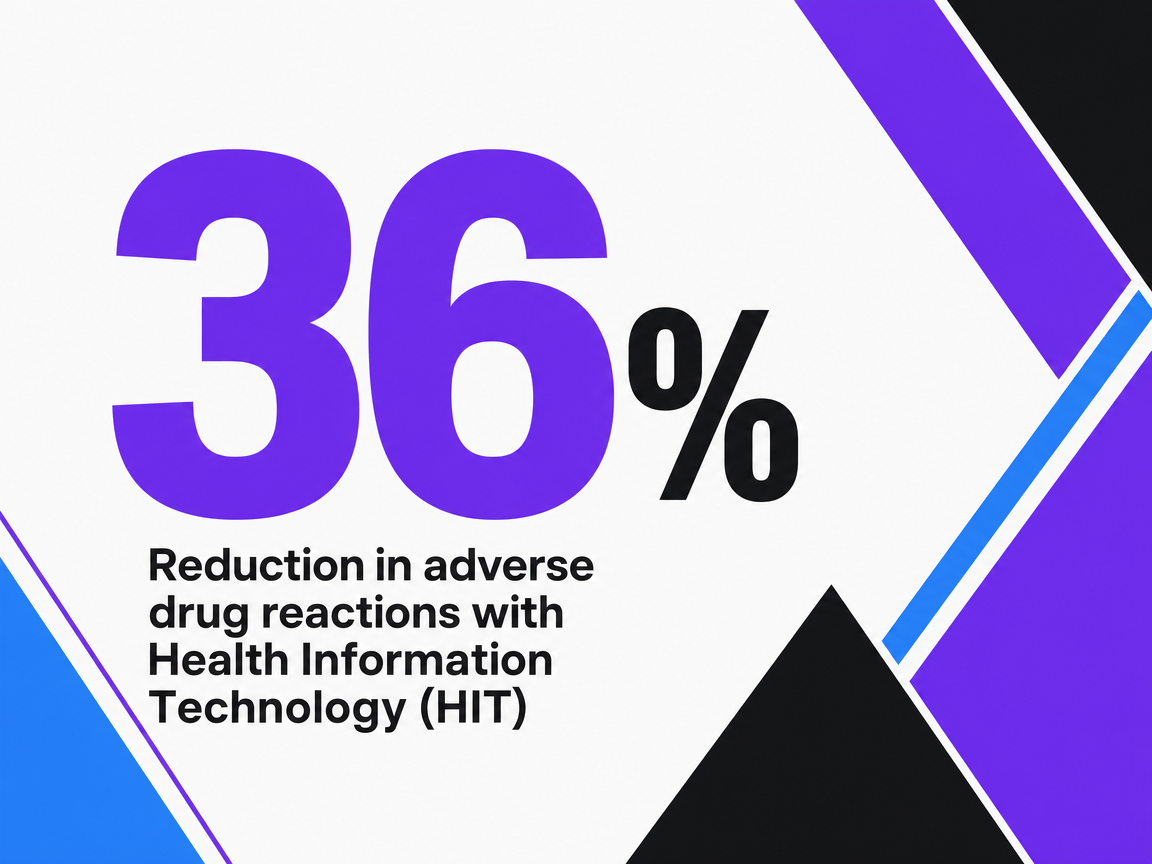 Reduction in adverse drug reactions with Health Information Technology (HIT)
Reduction in adverse drug reactions with Health Information Technology (HIT)
Reduction in adverse drug reactions with Health Information Technology (HIT)
Frequently Asked Questions
References
- 1.Health Products Compliance Guidance.
- 2.Use of Online Tracking Technologies by HIPAA Covered Entities and Business Associates.
- 3.Marketing | HHS.gov.
- 4.Summary of the HIPAA Privacy Rule.
- 5.The Bad Ad Program.
- 6.Communications From Firms to Health Care Providers Regarding Scientific Information on Unapproved Uses of Approved/Cleared Medical Products.
- 7.AI Risk Management Framework.
- 8.Towards a Standard for Identifying and Managing Bias in Artificial Intelligence.
- 9.The Assessing Risks and Impacts of AI (ARIA) Program Evaluation Companion Document.
- 10.Health Policy and Privacy Challenges Associated With Digital Technology.
- 11.Health advertising on Facebook: Privacy and policy considerations.
- 12.Privacy protections to encourage use of health-relevant digital data.
- 13.The impact of health information technology on patient safety.
- 14.How Americans View Data Privacy.
- 15.Key findings about how Americans view artificial intelligence.
- 16.Mobile Health App Interactive Tool.
- 17.Use of Online Tracking Technologies by HIPAA Covered Entities and Business Associates (PDF).
- 18.Automation in Contemporary Clinical Information Systems: a Survey.
- 19.Health Claims.