
Key Takeaways
- Treat package selection as a diligence problem framed by pricing model, measurement contract, testing cadence, and, for healthcare operators, claim substantiation — not by deliverable lists.
- Each pricing archetype has a native failure mode: percent-of-spend inflates managed budget, flat retainers invite coasting, pure CPA chases wrong buyers, and hybrid pods carry complexity drag.
- Build the measurement contract around incrementality testing with named designs, holdout shares, and decision rules, and shift the KPI stack from MQL volume to opportunity contribution 3, 4.
- Require a numeric testing cadence in writing — two to four live experiments weekly with hypothesis logs and decision rules — so optimization is continuous machine work, not deferred analyst labor.
- McKinsey's 15 to 20 percent MROI band sets the recoverable-spend prize, and redeploying that share into higher-lift tests compounds faster than handing savings back 10.
- Healthcare portfolio operators need claim substantiation embedded in the ad workflow and measurement tied to booked visits, since click-level reporting and post-hoc compliance reviews both leak budget 5, 1.
- Before signing, demand written answers on pricing-model safeguards, the next 90 days of incrementality tests, day-one offline conversion import, and where claim substantiation sits in the workflow.
Why Package Selection Decides Whether Spend Compounds or Leaks
Most PPC service packages are sold as deliverable bundles: account audits, weekly reports, a set number of ad variants, a quarterly business review. That framing hides the variable that actually decides whether a budget compounds or leaks — the operating model behind the package. A demand gen manager running $25K to $250K per month in paid search is not buying ad builds. They are buying a measurement and optimization system, and the package's pricing structure quietly dictates what that system optimizes for.
The economics are not abstract. McKinsey's MROI work estimates that 15 to 20 percent of marketing spend can often be released through better return-on-investment discipline, available for reinvestment or return to the business 10. That figure spans total marketing spend, not paid search alone, but it sets the upper-bound prize: the difference between a package that surfaces waste continuously and one that defends its retainer is measured in points of recoverable budget, not basis points of CTR.
The rest of this guide treats package selection as a diligence problem with four levers — pricing model, measurement contract, testing cadence, and, for healthcare operators, claim substantiation.
The Four Pricing-Model Archetypes and the Waste Each One Creates
Percent-of-Spend: The Incentive to Inflate Managed Budget
The percent-of-spend model — typically 10 to 20 percent of monthly media, illustrative ranges — ties provider revenue directly to the size of the budget under management. The structural problem is that every dollar saved by pausing a wasteful campaign is a dollar of fee the provider loses. A team that ruthlessly trims branded-search overlap, kills duplicate keywords, or shifts budget to organic when paid is non-incremental is cutting its own paycheck.
The waste shows up as managed-budget creep. Match types stay broad. Negative keyword sweeps happen quarterly instead of weekly. Display and Performance Max remain on at full tilt even when geo holdouts would suggest the incremental contribution is thin. The account looks healthy on a managed-spend report because spend is rising and CTR is stable, but the share of that spend that drives net-new pipeline is shrinking.
Demand gen managers running this model should require a contractual scope clause that compensates the provider for spend reductions tied to documented incrementality findings, not just media volume.
Flat Retainer: Predictable Cost, Predictable Coasting
Flat retainers solve the incentive problem of percent-of-spend by decoupling fee from budget size. They create a different one: once the retainer is signed, the marginal cost of doing more work falls entirely on the provider. Hours flow to the loudest client, not the highest-leverage test.
The failure mode is coasting. Hypothesis logs go stale. Quarterly business reviews recycle the same three optimization themes. Responsive search ad assets rotate on autopilot without fresh creative inputs. The account does not visibly decay — it just stops compounding. Six months in, the same campaigns are running with the same negatives list and the same audience signals, and the provider's roadmap slide deck has not changed.
The diligence move is to attach the retainer to a documented work-unit floor: a minimum count of structured experiments per month, a minimum cadence of search query reviews, and a deliverable log reviewed against the SOW. Without that floor, the retainer pays for presence, not progress.
Performance/CPA: Cheap Leads, Wrong Buyers
Pure performance pricing — fee per lead, per qualified lead, or per acquired customer — sounds like the cleanest alignment available. The provider only gets paid when something converts. The hidden cost is that the provider now controls which conversions the system optimizes toward, and the cheapest conversion is rarely the most valuable one.
The waste shows up downstream. Lead volume looks strong against the CPA target, but sales-qualified rates drop, opportunity-to-close timelines lengthen, and pipeline contribution per dollar declines. The provider is rationally bidding into low-intent queries, broad audiences, and lead-magnet offers that convert form-fills but not buyers. For a SaaS demand gen team, this can mean an MQL backlog inflated with free-trial tourists who never reach activation.
Performance pricing only works when the conversion definition includes a sales-stage event — opportunity created, demo attended, or revenue booked — and when offline conversion data flows back into the ad platform fast enough to actually steer bidding.
Hybrid Pod: Base Fee Plus Outcome Variable
The hybrid pod model pairs a base fee covering operational floor — account hygiene, reporting, testing infrastructure — with a variable component tied to a contractually defined outcome: incremental pipeline, qualified opportunity volume, or cost-per-opportunity below a benchmark. The base fee removes the coasting risk of flat retainers; the variable component removes the volume-inflation incentive of percent-of-spend and the wrong-buyer risk of pure CPA.
This is the model most likely to survive the diligence questions in the next sections, because it forces both parties to agree in writing on what the package is actually optimizing. The structural risk is complexity: hybrid contracts require working measurement infrastructure on day one, including offline conversion import and an agreed incrementality test design.
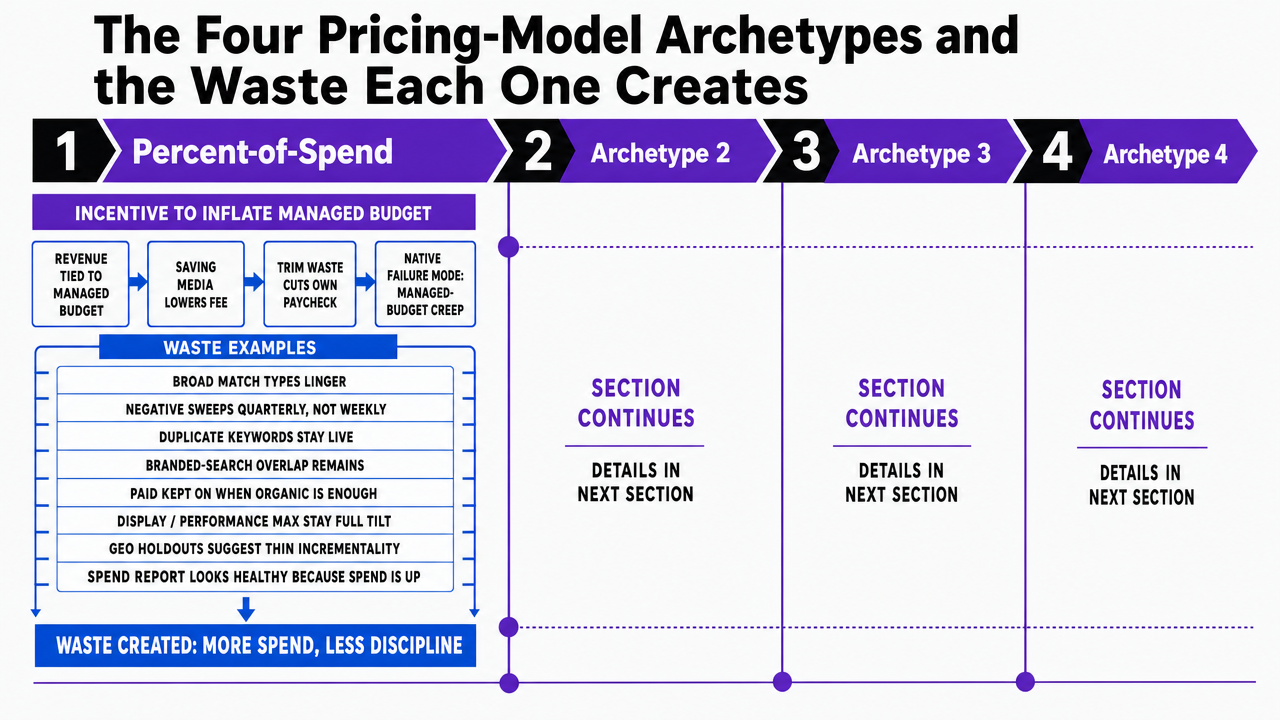 Visualize the four pricing-model archetypes and their native failure modes as a comparison framework directly mapped to the section's structure
Visualize the four pricing-model archetypes and their native failure modes as a comparison framework directly mapped to the section's structure
Test PPC optimization workflows with real campaigns
Validate spend efficiency by running live PPC experiments using your own account data during the trial.
Building a Measurement Contract Around Incrementality, Not Lead Volume
What Causal Lift Means Inside a PPC SOW
Forrester defines incrementality testing as the method for determining the true causal impact of marketing activity, distinct from platform-reported conversions that often credit demand the brand would have captured anyway 3. Inside a PPC statement of work, that definition translates into a written test calendar, not a footnote. A package that cannot name the next three incrementality tests on the roadmap is selling reporting, not measurement.
Three test designs cover most paid-search questions. A geo holdout suppresses paid search in matched DMAs or metros for a defined window and compares organic and direct conversions against test markets — it proves whether paid is additive to baseline demand. A ghost-bid test enters the auction at a bid that loses impression share by design, isolating the lift that comes from being served versus eligible. An audience holdout withholds remarketing or in-market segments from a randomized share of users to quantify what the audience layer contributes above broad targeting.
Each design costs foregone clicks during the measurement window. The diligence question is whether the package owner can name the test, the holdout share, the minimum detectable effect, and the decision that follows the readout — before the contract is signed.
Moving the KPI Stack From MQLs to Opportunity Contribution
Most PPC SOWs still anchor on MQL volume and cost-per-lead. Forrester's B2B planning guidance pushes the opposite direction, advising marketing leaders to divest from net-new lead acquisition metrics and shift funds toward efforts that produce opportunity types and the buying groups attached to them 4. For a demand gen manager negotiating a package, that reframe is the difference between a provider optimizing toward form-fills and one optimizing toward sourced opportunities.
The KPI stack inside the measurement contract should read in this order: incremental opportunities created, weighted pipeline contribution, cost per opportunity by segment, and only then leading indicators like qualified-lead rate and CPL. Volume metrics stay in the report as diagnostics, not scorecard lines.
This change has a contractual consequence. If the package's variable fee or performance bonus is still tied to MQL count, the operating system optimizes toward MQL count regardless of what the dashboard headline says. The bonus structure is the real KPI. Rewriting it to pay against opportunity contribution — even partially — is what moves bidding, audience, and creative decisions toward buyers instead of browsers.
Offline Conversion Import and the Pipeline Feedback Loop
An opportunity-weighted KPI stack only works if downstream events flow back into the ad platform. Without offline conversion import wired from the CRM to Google Ads and Microsoft Advertising, Smart Bidding optimizes against the proxy it can see — usually a form submission — and the provider's reporting layer becomes the only place pipeline ever shows up. That gap is where bid algorithms learn the wrong lesson at scale.
The measurement contract should specify three items: the conversion events being imported (opportunity created, SQL accepted, closed-won), the latency target between CRM event and platform upload (24 to 72 hours is the operating range that keeps bidding models fresh), and the value assignment rule, whether static per-stage values or dynamic deal-size weighting.
When the feedback loop runs on schedule, the bidder optimizes toward the conversions that matter and the incrementality tests in 3.1 have a clean dependent variable. When it does not, every other clause in the SOW degrades.
Continuous Testing Cadence as a Hard Package Requirement
Minimum Weekly Test Volume, Hypothesis Logs, and Decision Rules
A package that promises "ongoing optimization" without a numeric cadence is selling sentiment. The contract should specify, in writing, a minimum count of structured experiments running concurrently and a minimum count completing per week. For an account in the $25K to $250K monthly range, a working floor is two to four live tests per week across bid strategy, creative, audience signals, and landing experience, with at least one of those slots reserved for an incrementality design rather than a within-platform A/B.
Each test needs a hypothesis log entry the demand gen manager can read in under a minute: the variable being changed, the prior belief, the predicted direction and size of the effect, the minimum detectable effect the sample can support, the holdout share, and the decision rule that triggers on readout. "Winner gets 100 percent of traffic" is a decision rule. "We will keep monitoring" is not. Forrester's framing of incrementality as the true causal impact of marketing only pays off when the readout actually changes the bid, the budget, or the creative rotation on a defined date 3.
Without that scaffolding, the test queue becomes a reporting artifact.
Where Manual Analyst Bottlenecks Quietly Burn Budget
Most package failures are not strategy failures. They are throughput failures. A single analyst running an account with thousands of search terms, dozens of ad groups, and a Performance Max layer cannot review query reports, refresh negative lists, rotate responsive search ad assets, and read out an incrementality test in the same week. Something gets deferred, and the deferred item is almost always the one that would have surfaced waste.
The bottlenecks repeat across accounts:
- search query reviews running monthly instead of weekly,
- negative keyword sweeps batched into quarterly cleanups,
- RSA asset fatigue going unaddressed because creative refresh requires a brief cycle, and
- incrementality readouts skipped when the analyst is staffing a campaign launch.
Each delay costs spend that the account already booked.
The diligence question is whether the package's operating model treats these tasks as continuous machine work with human approval, or as scheduled analyst labor. The first model scales with budget; the second scales with headcount and visibly slows down at exactly the spend levels where waste compounds fastest.
See How Leading SaaS Teams Optimize PPC Spend—Continuously
Connect with experts to benchmark your PPC efficiency, review real-world optimization workflows, and discover how top enterprise teams identify and eliminate wasted ad spend at scale.
The Economics of Recoverable Spend
The case for treating package selection as a measurement problem rests on a specific number. McKinsey's marketing return-on-investment work estimates that 15 to 20 percent of marketing spend can be released through better MROI discipline, freed for reinvestment in higher-return tactics or returned to the business 10. The figure covers total marketing spend across channels — not paid search in isolation — but it sets the size of the prize that disciplined package selection competes for.
Applied as a redeployment band against a $100,000 monthly PPC budget, the math is straightforward. The lower bound, 15 percent, is $15,000 per month of recoverable spend, or $180,000 across a year. The upper bound, 20 percent, is $20,000 per month, or $240,000 across a year. That recoverable share does not appear in a quarterly business review slide. It surfaces only when search query reviews run weekly, when negative keyword sweeps are continuous, when incrementality readouts retire non-additive campaigns, and when offline conversion data shifts bidding toward opportunities instead of form-fills.
The redeployment question matters more than the cut question. A package that finds $18,000 per month of low-incremental spend and reinvests it into tests, audiences, or geos with higher causal lift compounds faster than one that simply hands the savings back. A package that finds the same $18,000 and lets it pool into broad-match expansion or another Performance Max asset group quietly returns the recoverable share to the waste column it came from.
The diligence implication for the next package signed: the recoverable band is large enough to fund its own measurement infrastructure several times over. Providers that cannot describe how they would surface and redeploy 15 to 20 percent of the account's spend within two quarters are competing on the wrong axis.
If You Manage Multiple Healthcare Locations: A Different Diligence Layer
Claim Substantiation Built Into the Ad Workflow
The audience shifts here. Multi-location healthcare operators — dental groups, urgent care networks, specialty platforms running ten or more sites — carry a diligence layer that SaaS demand gen teams do not. Every ad headline, every landing page proof point, every offer carries an evidentiary burden. The FTC's standing guidance on health claims requires advertisers to support advertising claims with solid proof before the ad runs, not after a complaint surfaces 5. The Precision Patient Outcomes enforcement action in 2022 demonstrated what happens when that proof does not exist: the agency moved to stop marketing claims for a supplement positioned as an effective COVID-19 treatment without scientific support, and the company faced injunctive action and required disclosures 6.
For a portfolio operator, the cost of an unsupported claim is not a single ad disapproval. It is an account-level pattern that compounds: ads flagged across locations, landing pages pulled mid-campaign, and rebuild cycles that strand budget already committed to auction. A package that treats claim review as a periodic legal pass cannot keep up with weekly creative rotation across 15 or 30 sites.
The diligence question for the operator is whether substantiation lives inside the ad production workflow — claim, evidence source, landing page proof, ad copy, reviewer signoff — or sits in a separate compliance queue that only catches violations after they ship.
Measuring Value at the Booked Visit, Not the Click
Click-level reporting flatters healthcare PPC packages. Patient inquiry volume and booked visits tell the truer story. Peer-reviewed guidance on healthcare advertising recommends that operators monitor telephone, email, and in-person inquiries and systematically ask patients how they heard about the service to assess advertising impact 1. That instrumentation is the dependent variable for any incrementality test the SOW promises to run.
The implication for package design is concrete. The measurement contract should specify call tracking with conversation-level disposition, form-to-CRM handoff with appointment status writeback, and a reconciliation step that maps booked visits to the campaigns, ad groups, and geos that produced them. A digital marketing plan tied to converting online interest into appointments only pays off when the appointment event makes it back to the bidder 2.
Without that loop, Smart Bidding optimizes toward whichever conversion the pixel can see — typically a form-fill or a click-to-call event — and per-location budget drifts toward locations that produce noise rather than visits.
Portfolio Economics Across 5, 15, and 30 Locations
Portfolio scale changes which pricing model preserves per-location discipline. The table below holds monthly ad spend per location constant at an illustrative $8,000 and walks the three primary package models across 5, 15, and 30 locations. The recoverable-spend line applies McKinsey's 15 to 20 percent MROI band as the redeployment opportunity disciplined package selection competes for, noting that the figure spans total marketing spend rather than PPC alone 10.
| Portfolio size | Monthly ad spend | Percent-of-spend fee (15%, illustrative) | Flat retainer (illustrative) | Hybrid base + variable (illustrative) | Recoverable band at 15–20% |
|---|---|---|---|---|---|
| 5 locations | $40,000 | $6,000 | $8,000–$12,000 | $5,000 base + variable | $6,000–$8,000 |
| 15 locations | $120,000 | $18,000 | $15,000–$22,000 | $10,000 base + variable | $18,000–$24,000 |
| 30 locations | $240,000 | $36,000 | $22,000–$32,000 | $15,000 base + variable | $36,000–$48,000 |
All fee cells are illustrative and meant to expose model behavior, not benchmark provider rates. The pattern that matters: percent-of-spend fees scale linearly with portfolio size while the analytical work — query reviews, negative sweeps, incrementality readouts per location — scales sub-linearly, which rewards providers for adding sites rather than redeploying recoverable spend. Hybrid models with a defined base and a variable tied to booked visits or cost-per-opportunity hold per-location budget discipline the longest at 15 and 30 locations, because the variable component only pays out when the recoverable band actually surfaces.
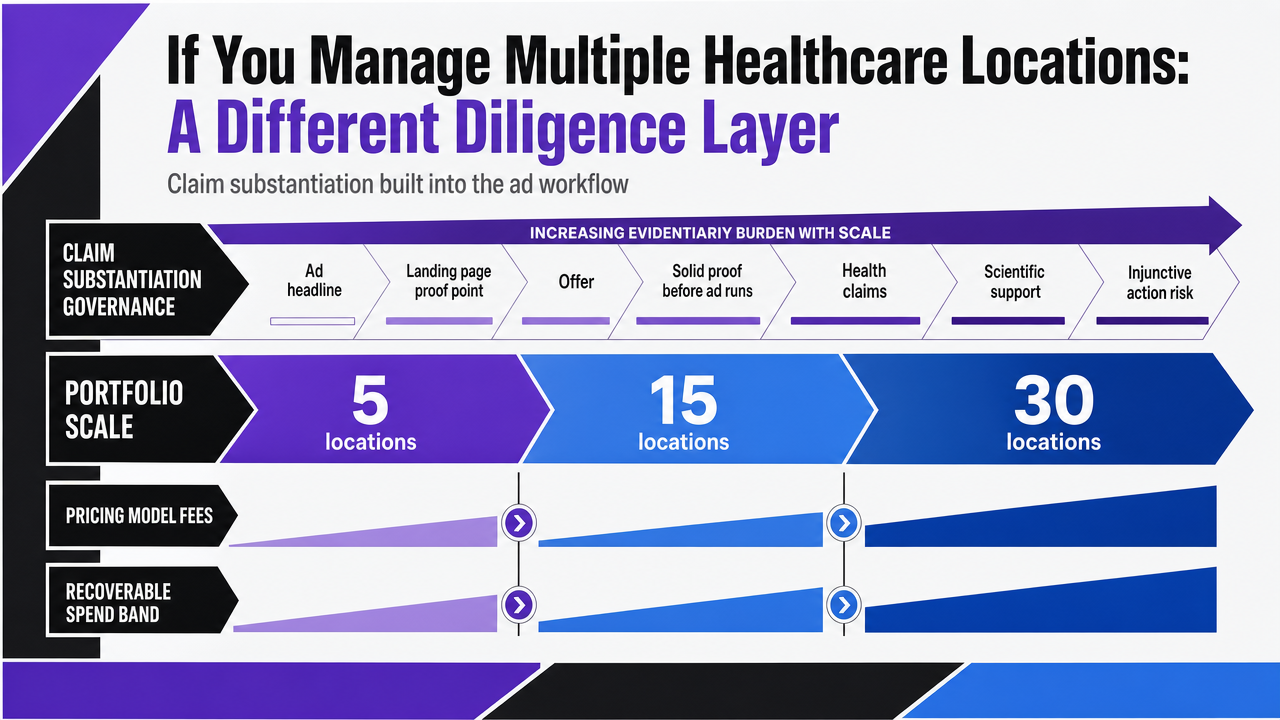 Render the section's portfolio economics table as a clean comparison infographic showing how pricing model fees and the recoverable spend band scale across 5, 15, and 30 healthcare locations
Render the section's portfolio economics table as a clean comparison infographic showing how pricing model fees and the recoverable spend band scale across 5, 15, and 30 healthcare locations
Reduce Wasted PPC Spend with Autonomous Optimization Insights
Access continuous PPC performance analysis, automated wasted spend detection, and actionable optimization tests—purpose-built for agencies and SaaS brands managing multi-channel acquisition at scale.
A Diligence Sequence for the Next Package You Sign
The package worth signing answers four questions in writing before the master services agreement is countersigned.
- Pricing model and failure-mode safeguard. Which pricing model is on the table, and what is the documented mechanism that prevents its native failure mode — managed-budget creep under percent-of-spend, coasting under flat retainer, wrong-buyer optimization under pure CPA, complexity drag under hybrid pod? A clause that compensates the provider for documented spend reductions, or a variable tied to opportunity contribution rather than form-fills, is the answer the SOW should already contain.
- The next 90 days of incrementality testing, named by design — geo holdout, ghost bid, audience holdout — with holdout share, minimum detectable effect, and the decision rule that fires on readout 3.
- Offline conversion import live on day one, with CRM events writing back inside a 24-to-72-hour window, or is the bidder still optimizing toward a proxy?
- For portfolio healthcare operators: does claim substantiation sit inside the ad workflow, or in a separate queue that catches violations after they ship 5?
A provider that can answer those four in concrete language is selling a measurement system. A provider that cannot is selling deliverables, and the recoverable share of the budget will stay recoverable. AI-managed PPC operations exist specifically to keep that diligence sequence running every week instead of every quarter — which is the cadence at which wasted spend actually compounds.
Frequently Asked Questions
References
- 1.Advertising in health and medicine: using mass media to communicate with patients.
- 2.Digital Marketing for Private Practice: How to Attract New Patients.
- 3.Incrementality Testing Boosts Marketing ROI.
- 4.Planning Guide 2023: B2B Marketing Executives.
- 5.Health Claims | Federal Trade Commission.
- 6.FTC Acts to Stop Deceptive COVID-19 Advertising Claims by California's Precision Patient Outcomes, Inc..
- 7.Current Trends in the Use of Social Media by Plastic Surgeons.
- 8.Digital marketing in attracting new patients: cross-sectional study in a vascular surgery office.
- 9.Evolving perspectives in dental marketing: A study of Jordanian dentists.
- 10.Marketing Return on Investment - McKinsey.