Key Takeaways: Your AI Training Roadmap
- Data Over Algorithms: 60% of AI project failures stem from poor data quality, not model choice. Prioritize cleaning your dataset first.
- Cost vs. Control: Use Parameter-Efficient Fine-Tuning (PEFT) to cut training costs by 90%, or Retrieval-Augmented Generation (RAG) for real-time accuracy without retraining.
- Human Oversight is Mandatory: Implement "Human-in-the-Loop" workflows to prevent model collapse and ensure brand voice consistency.
Immediate Next Action: Conduct a "Data Foundation Audit" (see Section 1) to determine if your current content assets are ready for AI ingestion.
Building a Strategy for Training AI to Write
Navigating the world of artificial intelligence can feel overwhelming, but the difference between a generic chatbot and a powerful business asset often comes down to one thing: preparation. Training AI to write effectively requires shifting your focus from chasing the newest model to building a solid foundation of data and strategy. Whether you are a small business owner looking to automate emails or an enterprise leader scaling content operations, this guide provides the tools you need to succeed.
Why Data Quality Defines Success When Training AI to Write
The 60% Problem: Data Issues vs. Algorithms
Checklist: Diagnosing Data vs. Algorithm Failures
- Review recent AI writing errors and categorize root causes (e.g., factual error vs. tone mismatch).
- Audit training datasets for missing, biased, or duplicate entries.
- Validate data labeling and annotation accuracy.
- Benchmark model outputs against a clean, manually reviewed data sample.
The dominant challenge in training AI to write is not the sophistication of algorithms, but the integrity of input data. If you feed a model messy information, you will get messy results.
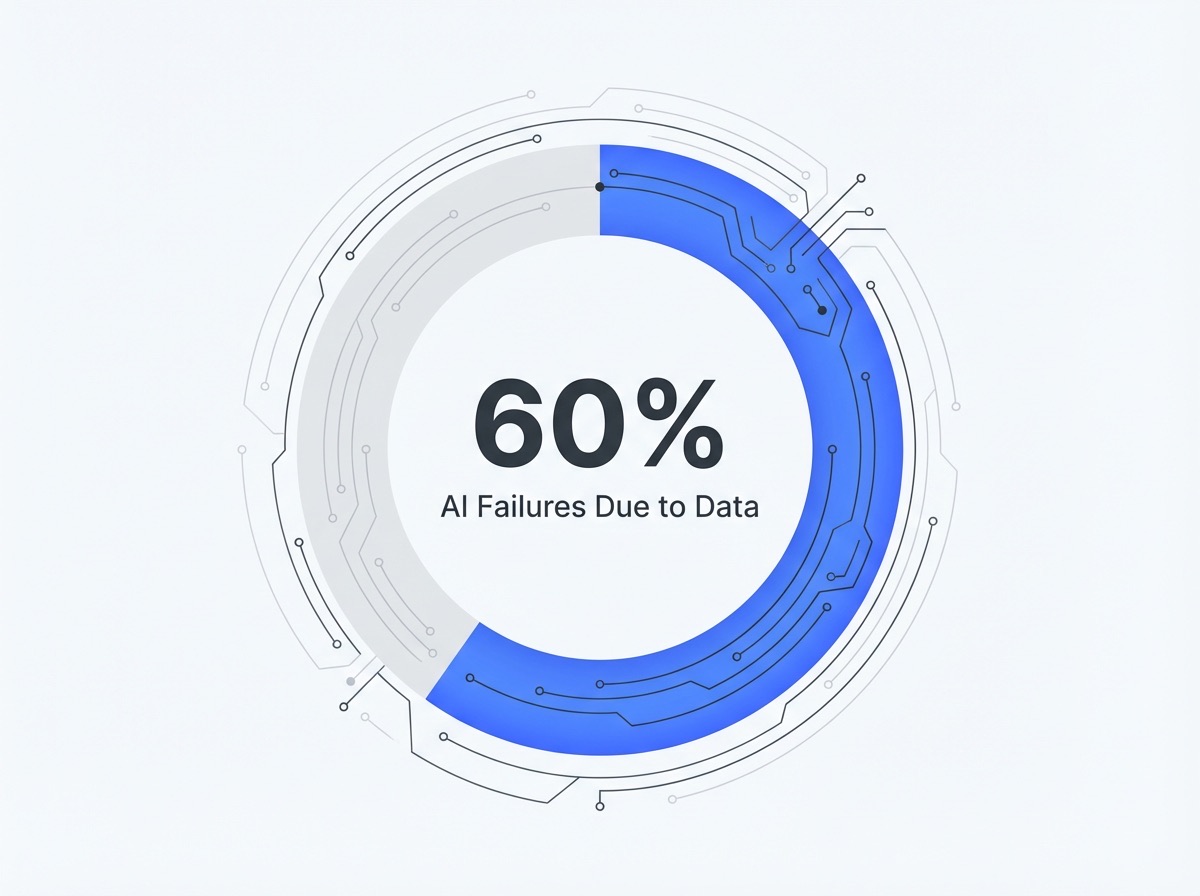 AI Failures Attributed to Poor Data Quality: 60%
AI Failures Attributed to Poor Data Quality: 60%
Research indicates that 60% of AI project failures can be directly traced to data quality issues—such as incomplete, inconsistent, or mislabeled data—rather than algorithmic shortcomings or model architecture choices2.
This statistic underscores a critical reality: for most organizations, substantial gains are realized by improving data pipelines instead of chasing the latest model tweaks. Poor data quality leads to unreliable outputs, hallucinations, and erosion of user trust. For example, if a marketing team relies on flawed product descriptions in its dataset, even state-of-the-art models will propagate those errors at scale.
This approach is ideal for enterprise leaders and technical buyers who want to maximize ROI, as investments in data cleaning and validation consistently outperform equivalent spending on algorithm optimization in AI writing projects2. Prioritize data quality reviews early and often, especially when scaling AI content production. Addressing foundational data issues sets the stage for all subsequent steps in a successful AI writing strategy.
Building Your Training Data Foundation
Assessment: Training Data Foundation Readiness
- Is your corpus primarily human-written, recent, and relevant to your domain?
- Have you removed duplicate, low-quality, or AI-generated content?
- Do you conduct regular bias and representativeness checks?
- Are annotation and labelling guidelines well-documented and enforced?
Establishing a robust training data foundation is a measurable predictor of success when training AI to write. Industry guidance emphasizes sourcing datasets that are not only large but also diverse, up-to-date, and deeply aligned with your content objectives. For example, Encord highlights that high-quality data curation is critical to preventing AI hallucinations and model drift, directly impacting output reliability5.
Resource requirements for building this foundation are significant. Teams typically consist of 2–5 data engineers and subject matter experts working over several weeks to months, depending on dataset scale and domain complexity5. Costs stem primarily from manual data cleaning, annotation, and ongoing validation. This path makes sense for organizations seeking long-term AI writing accuracy and regulatory compliance, especially in specialized or regulated fields.
A structured approach—beginning with data discovery, progressing to quality audits, and culminating in continuous monitoring—ensures the training process remains aligned with business goals over time. Training AI to write with this level of rigor mitigates systemic errors and supports brand-specific requirements.
Choosing Between Fine-Tuning and RAG
Parameter-Efficient Methods Cut Costs 90%
Decision Tool: Parameter-Efficient Fine-Tuning (PEFT) Assessment
- Is your dataset proprietary, but limited in size?
- Are computational resources or cloud budgets tightly constrained?
- Does your use case require rapid iteration or frequent model updates?
- Is regulatory compliance or data privacy a concern?
Parameter-efficient fine-tuning (PEFT) methods, including techniques such as Low-Rank Adaptation (LoRA), allow organizations to customize large language models for specific writing tasks by updating less than 1% of the model’s total parameters1, 7. This approach reduces both infrastructure requirements and energy consumption, with studies showing PEFT can cut training costs by 90% compared to full model fine-tuning10.
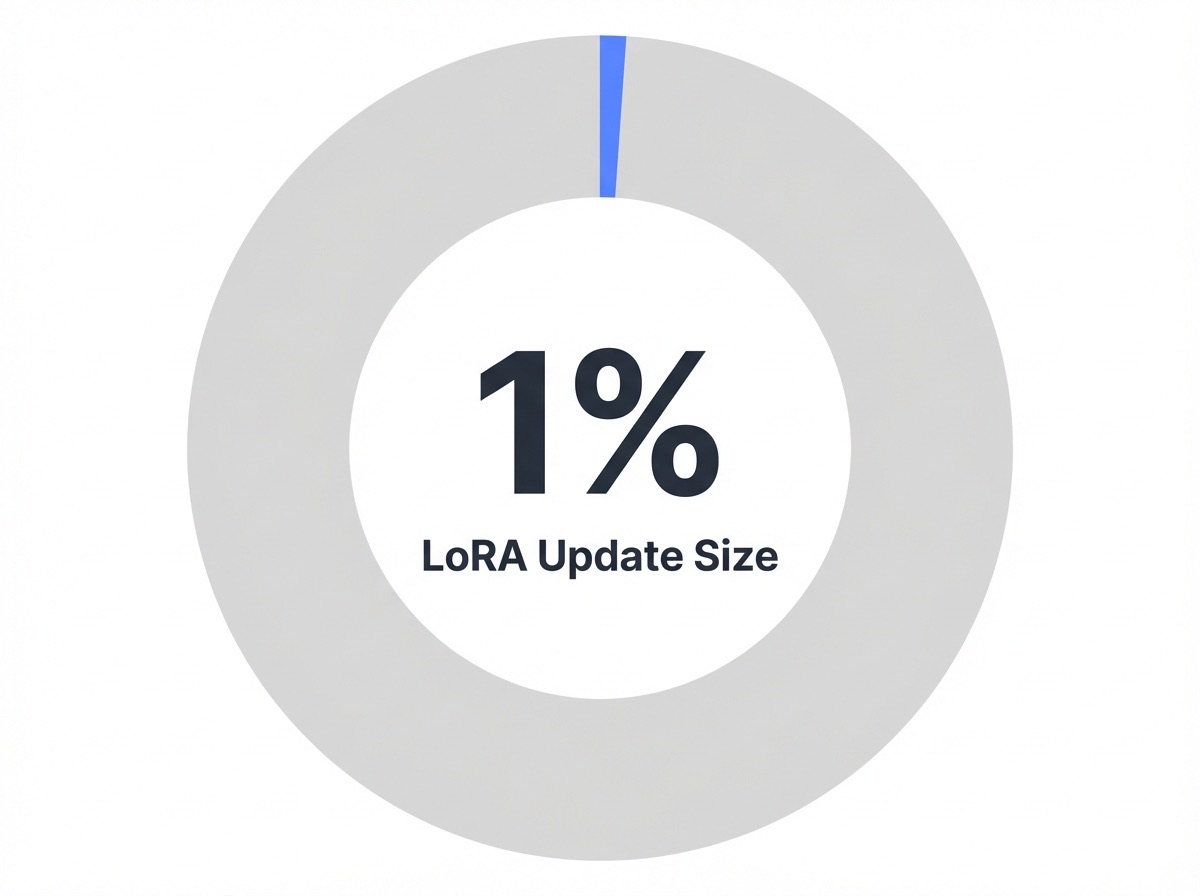 Parameter Update Size in LoRA Fine-Tuning: 1%
Parameter Update Size in LoRA Fine-Tuning: 1%
For teams training AI to write tailored content in finance, healthcare, or legal sectors, this strategy suits scenarios where data security and agility are priorities. PEFT methods typically require a single machine with a high-end GPU or a modest cloud instance, dramatically lowering the entry barrier for small businesses and mid-sized enterprises. Time-to-market shrinks from months to weeks, which is a significant advantage when adapting to regulatory changes or shifting content demands.
When RAG Beats Custom Model Training
Unlock Advanced AI Writing Training Frameworks with Vectoron
Gain access to proven AI content workflows, automated quality checks, and strategic tools for optimizing every stage of AI writing—from research to multi-platform publishing.
Scale Your AI Writing Strategy with Vectoron's Flexible Plans
Compare Vectoron's pricing tiers to find the right solution for advanced AI content training, workflow automation, and multi-site management tailored to your growth objectives.
Experience Data-Driven AI Writing—Try Vectoron’s Professional Tools Free for 7 Days
Unlock advanced AI content creation, seamless social media scheduling, and multi-platform publishing. Start your 7-day free trial of Vectoron’s Professional plan and streamline your entire content workflow.
Decision Guide: Is Retrieval-Augmented Generation (RAG) Right for You?
- Do you need AI-generated content to always reflect the latest internal documents or frequently changing databases?
- Are hallucinations or outdated information major risks for your use case?
- Is your organization required to provide traceable, source-backed responses for compliance or auditing?
- Do you have significant unstructured data (wikis, PDFs, support tickets) that should inform outputs?
Retrieval-Augmented Generation (RAG) combines a language model with a real-time search over external knowledge sources, enabling grounded and up-to-date writing. RAG outperforms custom model training when information rapidly evolves or must be verifiable on demand. For example, RAG systems are now preferred in regulated sectors like healthcare and finance, where accuracy and citation are non-negotiable9.
This approach works best when enterprises must mitigate the risk of AI hallucinations—where models confidently produce plausible but incorrect content. In 2025, industry analysis shows RAG adoption climbing as organizations seek scalable, audit-ready AI writing that draws from proprietary and public datasets9. Unlike traditional fine-tuning, RAG avoids costly retraining cycles. Setup typically requires integration with document stores and search infrastructure, but ongoing maintenance is minimal compared to custom training pipelines.
Prompt Engineering as Strategic Control in Training AI to Write
Strategic Control Assessment: The 5 Dimensions
Before deploying, verify your prompts address these five layers of control:
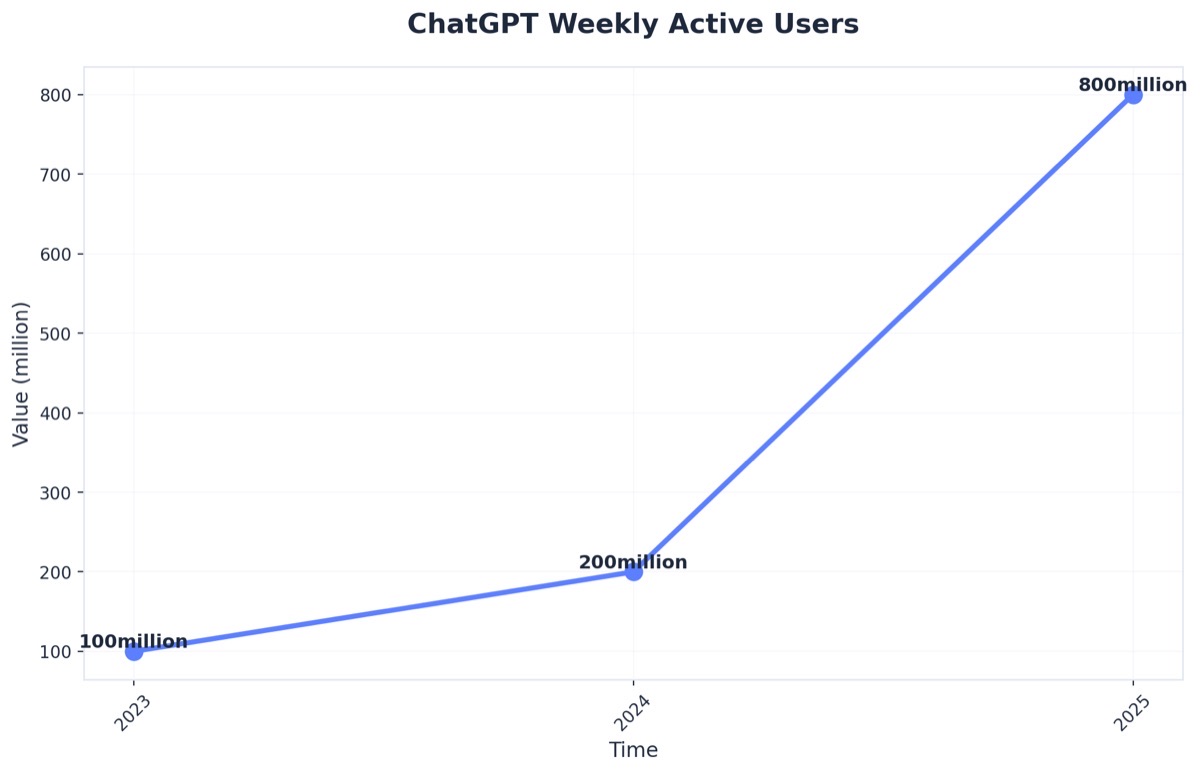
ChatGPT Weekly Active Users (Source: Vention - AI Statistics 2025: Key Trends and Insights)
- Boundary Establishment: What is the AI forbidden from saying?
- Knowledge Encoding: Have you embedded your specific decision frameworks?
- Consistency Enforcement: Will the 100th output match the quality of the 1st?
- Adaptive Agility: Can you change tone without retraining the model?
- Governance Infrastructure: Is there an audit trail for your prompt versions?
Prompt engineering represents far more than technical fine-tuning—it is a fundamental mechanism for organizational control over AI systems. As businesses integrate large language models into their operations, the ability to shape AI behavior through precise prompting becomes a critical strategic asset. This control determines whether these tools amplify human judgment or introduce uncontrolled variability.
1. Boundary Establishment
At the most basic level, well-crafted prompts establish boundaries around AI outputs, defining what constitutes acceptable responses and filtering out irrelevant or potentially harmful content. This guardrail function proves essential in customer-facing applications where brand reputation hangs on every interaction. A financial services firm, for instance, can use prompt constraints to ensure AI assistants never provide specific investment advice without appropriate disclaimers, maintaining regulatory compliance while delivering value.
2. Knowledge Encoding
Beyond simple constraints, strategic prompt engineering enables organizations to encode institutional knowledge and decision-making frameworks directly into AI workflows. When a healthcare organization specifies that diagnostic support tools must consider patient history, current symptoms, and evidence-based treatment protocols in a specific sequence, they are translating clinical best practices into executable AI behavior. A major hospital network implementing this structured approach reported that their AI-assisted triage system reduced average diagnostic pathway time by 23% while maintaining physician oversight at critical decision points.
3. Consistency Enforcement
The consistency advantage cannot be overstated. Traditional human-driven processes suffer from variability based on individual experience, current workload, and subjective interpretation. Prompt engineering creates reproducible decision architectures that apply the same analytical rigor across thousands of interactions. Research from enterprise AI implementations indicates that standardized prompting reduces response variability by 60-80% compared to ad-hoc AI usage, while maintaining quality scores above human-only baselines.
4. Adaptive Agility
Perhaps most strategically significant is how prompt engineering enables rapid adaptation without system retraining. Market conditions shift, regulations evolve, and competitive landscapes transform—often faster than traditional AI models can be updated. Organizations with sophisticated prompt libraries can pivot their AI behavior in hours rather than months. When a multinational retailer needed to adjust its AI customer service responses following new consumer protection regulations, prompt updates accomplished in 48 hours what model retraining would have required 4-6 months to achieve.
5. Governance Infrastructure
The governance implications extend throughout the enterprise. Centralized prompt management creates audit trails showing exactly how AI systems were instructed at any point in time, critical for compliance and quality assurance. Version control for prompts parallels software development practices, allowing organizations to test modifications, roll back problematic changes, and maintain production stability. This structured approach transforms AI deployment from experimental technology into managed infrastructure.
Mitigating Hallucinations and Model Drift
Verification Systems for Factual Accuracy
Verification Checklist: Factuality Safeguards in AI Content
- Is each generated statement cross-checked against authoritative databases or documents?
- Are outputs scanned for unsupported claims using automated fact-checkers?
- Is revision history tracked for all AI-generated drafts?
- Are domain experts consulted for high-impact or regulated topics?
Verification systems serve as the backbone for factual accuracy when training AI to write. Modern approaches integrate automated fact-checking algorithms that systematically compare AI outputs against trusted sources, flagging inconsistencies for human review. Industry best practices recommend combining these tools with source attribution mechanisms—such as citation requirements for medical or legal content—to further reduce hallucinations, where models generate plausible-sounding but false information9.
For most organizations, deploying effective verification involves both technology and process investments. Automated fact-checking platforms typically require integration with internal knowledge bases and cost several thousand dollars annually, while maintaining a team of reviewers or subject matter experts can add significant labor hours. This approach works best when accuracy and regulatory compliance are mission-critical, such as in healthcare, finance, or scientific publishing.
Preventing Collapse with Human Data Loops
Human-in-the-Loop (HITL) Checklist: Sustaining Model Integrity
- Is a diverse team reviewing a statistically significant sample of AI outputs each cycle?
- Are feedback mechanisms in place for users to flag and correct errors?
- Are retraining cycles scheduled based on the rate of detected issues or model drift?
- Is a mix of human and synthetic data tracked to prevent overreliance on AI-generated content?
Integrating human data loops is essential for preventing model collapse—a phenomenon where repeated training on synthetic or AI-generated data leads to generic, inaccurate, or less useful outputs over time4. Unlike automated verification alone, HITL approaches embed expert feedback directly into the lifecycle of training AI to write, ensuring models adapt to real-world standards and evolving requirements.
This strategy suits organizations prioritizing sustained accuracy and brand differentiation, especially as AI-generated content becomes more prevalent. HITL processes typically require dedicated reviewers or subject matter experts, with resource needs scaling according to content volume and regulatory demands. While time investment ranges from a few hours per week for small businesses to full-time roles in enterprise settings, the long-term benefit is the preservation of model quality and originality.
Frequently Asked Questions
Conclusion
Prompt engineering represents a fundamental shift in how organizations interact with AI systems. Rather than accepting generic outputs, businesses now possess the tools to shape AI responses according to their specific needs, brand voice, and strategic objectives. This level of control transforms AI from a novelty into a reliable business asset.
The five control dimensions explored in this article—establishing clear boundaries, encoding institutional knowledge, ensuring consistency, enabling controlled adaptation, and implementing governance frameworks—provide organizations with a systematic approach to AI deployment. Companies that develop capabilities across these dimensions gain measurable competitive advantages: reduced error rates, accelerated onboarding, predictable outputs, and alignment with evolving business requirements.
Success in strategic AI control requires continuous experimentation and refinement. As AI models evolve and business requirements change, prompt strategies must adapt accordingly. Teams that treat prompt engineering as an ongoing discipline rather than a one-time learning exercise position themselves to capitalize on emerging AI capabilities while maintaining the guardrails necessary for enterprise deployment.
Strategic control over AI systems increasingly differentiates market leaders from followers. Organizations that master these control mechanisms do not just improve operational efficiency—they create sustainable advantages through proprietary approaches to AI interaction that competitors cannot easily replicate. The ROI appears in reduced revision cycles, faster time-to-value, and AI outputs that consistently advance rather than undermine business objectives.
References
- 1.Machine Learning Mastery - The Roadmap for Mastering Language Models in 2025.
- 2.Datagaps - Best Practices for Data Quality in AI.
- 3.VisioneerIT - Enterprise AI Implementation: Your Complete Guide.
- 4.Sebastian Raschka - The State Of LLMs 2025: Progress, Problems, and Predictions.
- 5.Encord - Data Collection: Guide to High-Quality Data for AI Training.
- 6.C3 AI - Best Practices in Developing an Enterprise AI Roadmap.
- 7.ArXiv - The Ultimate Guide to Fine-Tuning LLMs.
- 8.AWS - What is Prompt Engineering?.
- 9.AWS - What is RAG? - Retrieval-Augmented Generation AI Explained.
- 10.SuperAnnotate - Fine-tuning large language models (LLMs) in 2025.