
Key Takeaways
- An AEO prompt functions as a production specification enforcing five contracts—intent classification, evidence sourcing, semantic structure, answer-shape for retrieval, and governance—not a paragraph of writing instructions pasted into a chat window.
- Google's guidance confirms AI features rely on the same foundations as classic search: indexability, semantic HTML, structured data, and non-commodity content, so the prompt must encode those foundations rather than AEO folklore 6, 7.
- Measurement separates eligibility (indexing, schema validity, extractable openings) from extraction (citations in AI Overviews, passage pulls), because low extraction with high eligibility signals an answer-shape failure, not a ranking problem 8.
- Multi-location operators should focus next on wiring one specification into an approval-first workflow with location-specific inputs, so adding markets becomes a configuration change rather than a hiring cycle 1.
The Prompt as System Specification, Not Instruction
An AEO prompt is a specification, not a set of writing instructions. It defines what a draft must contain, how sources must be handled, what structure the output must carry, and which checks it must pass before a human ever reads it. Treated this way, the prompt stops being a clever paragraph pasted into a chat window and starts functioning as the contract between strategy and production.
That distinction matters because Google's own guidance is direct: AI Overviews and generative search features still rely on the same foundations as classic search—indexability, semantic HTML, structured data, internal linking, and people-first quality 6. There is no separate schema for AI features and no shortcut around content quality 6. If AEO is still SEO expressed for AI retrieval, then the prompt has to enforce SEO discipline on every draft, every time, without a senior editor rewriting the output.
That is a systems problem, not a copywriting problem. The prompt needs to encode intent classification, evidence sourcing rules, structural requirements, answer-shape constraints for retrieval, and a governance layer that flags drafts before they enter the approval queue. Each of those is a contract the draft must satisfy.
Marketing leaders running lean teams already understand why this matters. Stanford's 2025 AI Index reports that a growing body of research confirms AI boosts productivity and often narrows skill gaps across knowledge work 5. The productivity gain shows up only when the prompt is the production layer—when the specification is stable enough to run at scale without eroding quality.
Why AEO Is Still SEO—and Why That Changes the Prompt
Google's AI Search guidance is explicit: there is no separate ranking system for AI Overviews, no special schema for generative features, and no llms.txt file that grants preferential treatment. The same signals that make a page eligible for classic search results—indexability, semantic HTML, structured data for rich results, internal linking, and people-first content—are what make it eligible to be cited inside AI answers 6. Search Engine Journal's read of that documentation lands on the same conclusion, adding one operational point that matters for prompt design: chasing long-tail keyword variants produces commodity content, and commodity content is exactly what AI Overviews skip in favor of specific, original, experience-grounded pages 7.
That reframing has direct consequences for how the prompt is written. If AEO tactics circulating in the market—variant chasing, AI-specific schema, llms.txt files, keyword stuffing around question phrases—do not appear in Google's own guidance, they should not appear as instructions inside the prompt. What belongs in the prompt is what Google actually names: crawlable structure, clear semantic hierarchy, standard structured data where a rich result type exists, and content that a subject matter expert would recognize as non-commodity 6, 7.
The practical shift is subtle but consequential. A prompt built on AEO folklore will produce drafts optimized for tactics Google does not use to rank or retrieve. A prompt built on the documented foundations will produce drafts that satisfy both classic ranking systems and the generative layer sitting on top of them. One specification, two surfaces.
This is why the prompt cannot be treated as a marketing artifact. It has to encode the same discipline a technical SEO lead would enforce on a page template—except the enforcement runs on every draft, before human review, at production volume. The next section defines the five contracts that specification has to carry.
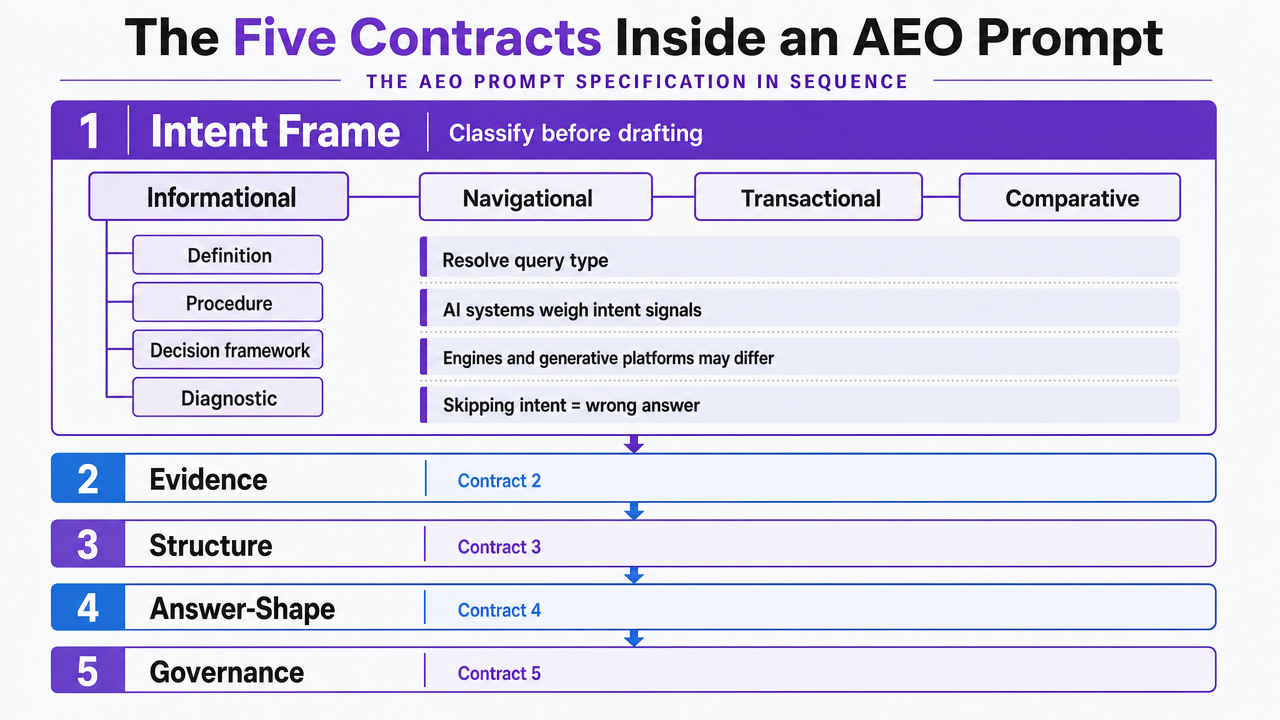
The Five Contracts Inside an AEO Prompt
Intent Frame: Classifying the Query Before Drafting
The first contract the prompt has to enforce is intent classification. Before a draft is written, the prompt must resolve what kind of question the target query represents: informational, navigational, transactional, or comparative—and within informational, whether the reader wants a definition, a procedure, a decision framework, or a diagnostic.
That classification matters more than it did five years ago. AI answer systems interpret queries differently from classic ranking, weighing intent signals to decide which passages to extract and cite. Intent analysis in the AI search era spans traditional keyword-driven engines and generative platforms, and the two do not always read the same query the same way 9. A prompt that skips intent classification produces drafts that answer the wrong question well.
The operational fix is to require the prompt to output an intent statement before the draft body. That statement names the query type, the reader's likely next action, and the format the answer must take—paragraph, list, table, or comparison. Everything downstream inherits that decision. Section structure, evidence density, and citation depth all follow from it.
This is also where commodity content dies quietly. A prompt that classifies intent as "informational-definitional" for a query that is actually "informational-diagnostic" will produce a generic explainer instead of the specific answer the reader—and the AI system—wanted.
Evidence Contract: Source Grounding and Citation Rules
The second contract governs how the draft handles facts. Every claim that carries weight—statistics, benchmarks, regulatory positions, technical specifications—must trace to a named source, and the prompt has to specify which source types are acceptable before drafting begins.
The rule is narrow on purpose. Primary sources, official documentation from platforms and standards bodies, peer-reviewed research, and government publications belong in the acceptable set. Secondary summaries can support context but cannot carry a load-bearing claim. When AI-assisted drafts fail in regulated verticals, the failure almost always traces back to a permissive evidence contract that let a plausible-sounding claim through without a source.
The prompt should require inline citation markers next to each sourced claim and reject drafts that assert numbers without attribution. It should also require scope language in the same sentence as the statistic—what was measured, by whom, and any limits. That last requirement is what separates a citation from a decoration.
Google's guidance reinforces this discipline: AI features prioritize non-commodity content with specificity and originality, not paraphrased summaries of everyone else's summaries 6, 7. A tight evidence contract is what makes originality possible at production volume, because the drafter cannot fall back on generic assertions.
Structure Contract: Semantic HTML, Schema, and Modularity
The third contract controls the shape of the output. Semantic HTML, structured data where a rich result type exists, and modular content blocks are what make a page legible to both crawlers and retrieval systems 6. The prompt has to specify heading hierarchy, list structure, table use, and schema requirements as hard constraints—not stylistic suggestions.
CMS-side infrastructure decides how far the prompt can go. Platforms evaluated for LLM SEO readiness are graded on structured data support, semantic HTML fidelity, flexible content models, and authoring tools that expose headings and schema to editors 10. If the CMS strips semantic markup or forces a flat content model, the prompt's structural instructions do not survive publishing. The contract has to match what the infrastructure can preserve.
Modularity is the underrated part. Retrieval systems extract passages, not pages. A draft built as one continuous argument gives an AI system nothing clean to pull. A draft built as discrete, self-contained blocks—each with a clear heading, a direct answer in the first sentence, and supporting detail beneath—gives the retrieval layer exactly what it needs. The prompt should enforce that block structure as a requirement, not an aesthetic choice.
Answer-Shape Contract: Writing for Retrieval, Not Just Reading
The fourth contract is where AEO diverges most visibly from classic content writing. Retrieval systems that combine LLMs with search do not read a page linearly; they score passages against a query, extract the strongest match, and surface it as an answer or citation 8. That mechanic changes what a well-written paragraph looks like.
The answer-shape contract specifies that each section opens with a direct, extractable answer in the first one or two sentences—phrased so it can stand alone if lifted out of context. Supporting evidence, nuance, and examples follow beneath. The prompt should reject drafts that bury the answer in the third paragraph or hedge the opening sentence with qualifiers that break extractability.
This is also where the five contracts stack visibly into a single specification. Intent classification decides what question the passage answers. The evidence contract decides which sources back it. The structure contract decides where the passage lives in the page. The answer-shape contract decides how the passage is written. And the governance layer, next, decides whether the draft ships.
Google's guidance is consistent with that stack: eligibility for AI features comes from the same foundations that produce good classic-search pages, expressed with enough specificity that a retrieval system can isolate the answer 6.
Governance Layer: The Enforcement That Makes the Spec Real
The fifth contract is what turns the other four from aspirations into enforcement. Without a governance layer, the prompt is a document. With one, it is a system.
NIST's Generative AI Profile treats content-generating systems as needing operational controls across the trustworthiness lifecycle: evaluation criteria before deployment, checkpoints during generation, human review before release, and monitoring after publication 1. Translated into a content workflow, the governance layer inside the prompt specifies which automated checks a draft must pass—intent statement present, citations resolvable, schema valid, answer-shape verified—and which conditions escalate the draft to human review before it enters the approval queue.
That escalation logic is the operational hinge. A draft that passes every automated check still goes to human sign-off. A draft that fails any check does not consume reviewer attention until the failure is resolved. Reviewers spend their time on judgment calls—positioning, tone, competitive claims—not on catching missing citations a rule could catch.
For regulated verticals, the governance contract is not optional. It is the layer that makes AI-assisted production defensible when a compliance officer asks how the content was produced and what controls existed at each stage.
 Visualize the five sequential contracts (Intent, Evidence, Structure, Answer-Shape, Governance) that the section explicitly defines as the AEO prompt specification
Visualize the five sequential contracts (Intent, Evidence, Structure, Answer-Shape, Governance) that the section explicitly defines as the AEO prompt specification
Test an AEO-driven content workflow in days
Experience measurable improvements by deploying and publishing AEO-optimized content in a live environment within one week.
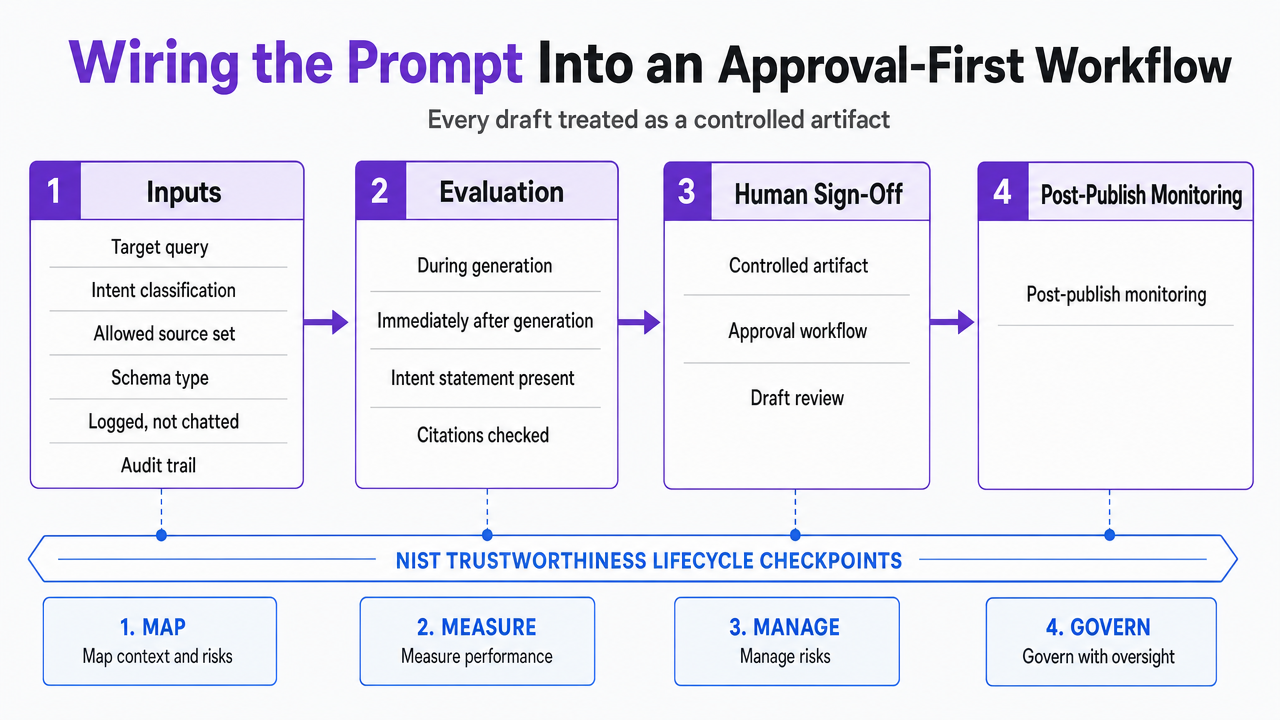
Wiring the Prompt Into an Approval-First Workflow
The prompt only becomes a system when it plugs into an approval workflow that treats every draft as a controlled artifact. That workflow has four stages, and each one maps to a checkpoint NIST's Generative AI Profile identifies for content-generating systems: inputs, evaluation, human sign-off, and post-publish monitoring 1.
Inputs come first. Before the prompt runs, the workflow captures the target query, the intent classification, the source set the drafter is allowed to cite, and the schema type the page will use. Those inputs are logged, not chatted. A workflow that starts with a free-text request and hopes the drafter picks the right sources has already lost the audit trail regulated verticals require.
Evaluation runs during and immediately after generation. Automated checks verify that the intent statement is present, citations resolve to allowed sources, semantic structure passes validation, and each section opens with an extractable answer. Drafts that fail any check bounce back to the drafter—human or AI—with the specific failure named. Reviewers never see them. That is the whole point: reviewer attention is a scarce resource, and the workflow protects it by resolving rule-based failures before escalation.
Human sign-off is where judgment enters. The reviewer looks at positioning, competitive claims, tone, and factual nuance the automated checks cannot assess. Approval-first means nothing publishes until that sign-off happens, and the sign-off is logged against the draft. For legal, behavioral health, dental, and healthcare operators, that log is what makes the process defensible when a compliance officer asks who approved what and when.
Post-publish monitoring closes the loop. The AI RMF frames trustworthiness as a lifecycle, not a launch event—drift, hallucination surfaces, and citation decay all happen after content ships 4. The workflow needs to track which pages get cited in AI answers, which lose eligibility, and which trigger corrections. That signal feeds back into the prompt's evidence and structure contracts, tightening the spec over time.
Without the workflow, the prompt is a document a team occasionally consults. With it, the prompt is the operating layer of a content program that scales without adding reviewers for every additional article.
 Visualize the four workflow stages (Inputs, Evaluation, Human Sign-Off, Post-Publish Monitoring) that map to NIST's trustworthiness lifecycle as described in the section
Visualize the four workflow stages (Inputs, Evaluation, Human Sign-Off, Post-Publish Monitoring) that map to NIST's trustworthiness lifecycle as described in the section
Measuring Whether the System Produces Answers AI Cites
A prompt system is only worth what its output surfaces produce. Measurement has to answer two questions: is the content eligible for AI answer surfaces, and is it being extracted when a relevant query fires. Those are different signals, and teams that conflate them end up optimizing for the wrong one.
Eligibility is the upstream metric. It tracks whether pages are indexed, whether structured data validates, whether semantic markup survives publishing, and whether the answer-shape opens each section extractably. Google's guidance is clear that these foundations decide whether a page can appear in AI features at all 6. Eligibility is a pass/fail check the automated evaluation layer already runs. What matters is trending the fail rate—when it climbs, the prompt or the CMS pipeline is drifting.
Extraction is the downstream metric. It tracks citations in AI Overviews, appearances in ChatGPT and Perplexity responses, and passage-level pulls into answer boxes. LLM-plus-search systems score passages against queries and extract the strongest match, so extraction data reveals which sections of which pages the retrieval layer finds usable 8. Low extraction with high eligibility usually points to answer-shape failure: the page ranks but does not open with a passage clean enough to lift.
NIST's AI RMF frames trustworthiness as continuous—drift, source decay, and factual erosion happen after publish 4. The measurement layer feeds those signals back into the prompt's evidence and structure contracts. Pages losing citations get diagnosed, not just refreshed. That feedback loop is what separates a system from a publishing calendar.
See How AI-Driven AEO Prompts Streamline Enterprise Content Production
Request a walkthrough of an integrated content system leveraging AEO prompts to reduce manual workflows, ensure message consistency, and accelerate multi-channel campaign execution at scale.
If You Manage Multiple Locations: The Operator Economics
The reader shifts here. Single-brand VPs can stop at the previous section. This one is written for operators running content across ten, twenty, or fifty locations—DSOs, MSOs, multi-market law firms, franchise systems, senior living portfolios. The math changes when the same prompt has to produce location-specific answers at portfolio scale, and the governance stakes change with it.
One prompt, many markets. That is the operational reality. A portfolio operator producing 40 AEO-optimized articles per month across 10 locations is running 480 drafts a year through the same specification, with local variations that have to preserve the intent, evidence, structure, answer-shape, and governance contracts without introducing drift between markets. The spec has to hold across every location, or the portfolio ends up with inconsistent authority signals and uneven eligibility for AI answer surfaces.
Stanford's 2025 AI Index reports that a growing body of research confirms AI boosts productivity and often narrows skill gaps across knowledge work 5. For portfolio operators, that gain only materializes when the prompt is the production layer—when adding a location does not require adding a writer, a reviewer, or a vendor coordinator.
The three cost structures for producing that 480-article annual volume look like this:
| Model | Cost Structure | Scaling Behavior |
|---|---|---|
| Agency retainer | $X per article × 480 articles, plus account management overhead | Linear: cost climbs with volume; briefing cycles compound across markets |
| In-house team | FTE fully-loaded cost × writers + editors + SEO specialist | Step function: each headcount addition absorbs 60–80 articles before the next hire |
| AI-governed production (Vectoron) | Platform fee (Vectoron trial: $599/mo) + reviewer time on approvals only | Flat: volume rises without proportional headcount or vendor additions |
The agency and in-house rows use variables on purpose. Agency per-article rates and FTE loads vary by market and vertical, and inventing figures would misrepresent the comparison. What matters structurally is where the cost curve bends. Agencies charge per unit produced. In-house teams charge per unit of capacity, whether utilized or not. An AI-governed production model charges for the specification and workflow, and the marginal cost of the 481st article approaches the cost of one reviewer's approval time.
That is the argument for headcount-neutral scaling. It is not that AI is cheaper per word. It is that the prompt-as-production-layer collapses briefing, drafting, and QA into a single governed loop, so adding a market is a configuration change rather than a hiring cycle.
What Breaks First When the Prompt Is Treated as a Template
Teams that copy an AEO prompt out of a newsletter and paste it into a workflow watch the same failures show up in the same order. Citations go first. Without an evidence contract that names allowed source types and requires resolvable markers, drafts fill the citation slots with plausible-sounding attributions that either point at low-authority pages or point nowhere at all. The draft looks sourced. It is not.
Structure breaks next. A template prompt tells the model to use headings and lists, but it does not specify heading hierarchy, schema type, or the modular block pattern retrieval systems extract from 6. Publishing strips whatever markup the model produced anyway, so the output ranks like a 2019 blog post and gets skipped by AI answer surfaces that need clean passages to lift 8.
Then intent drifts. The same prompt runs against a diagnostic query and a definitional query and produces the same shape of answer for both, because the template never required the drafter to classify the query first 9.
Governance is what breaks last and worst. A template has no automated checks, so every failure above lands on the reviewer's desk. Approval queues back up, reviewers start rubber-stamping, and the audit trail regulated verticals depend on stops existing.
Frequently Asked Questions
References
- 1.Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile.
- 2.AI RMF - AIRC - NIST AI Resource Center.
- 3.Biden-Harris Administration Announces New NIST Public Working Group on AI.
- 4.AI Risk Management Framework | NIST.
- 5.Artificial Intelligence Index Report 2025.
- 6.Optimizing your website for generative AI features on Google Search.
- 7.Google's New AI Search Guide Calls AEO And GEO 'Still SEO'.
- 8.When Search Engine Services meet Large Language Models.
- 9.How to Determine Search Intent in the AI Search Optimization Era.
- 10.Best CMS for LLM SEO: 7 AI-ready platforms for 2026.