
Key Takeaways
- AEO tooling breaks into four functional categories — monitoring mirrors, prompt-research maps, entity graphs, and content production presses — and no single vendor covers all four well, so category selection outranks brand selection.
- Publishing cadence beats schema markup as the decisive AEO variable, because answer engine crawlers revisit pages every few hours and favor recently confirmed, answer-shaped sources over stale but immaculately marked-up ones 9.
- Portfolio economics punish linear costs like per-brand monitoring seats and freelance drafting; consolidating those two lines first is where agencies running 15 to 80 accounts protect margin as scope grows.
- Governance belongs to the agency, not the client — acceptable-use policy, grounding-data rules, and audit cadence must live inside the same production workflow that ships pages, per NIST's Generative AI Profile 6.
Why the citation surface moved before the tooling did
Answer engines started citing brands at scale before most agency stacks were built to influence what those citations say. That gap is the operational problem this article addresses.
The query pool is no longer hypothetical. Pew Research reports that 34% of U.S. adults have ever used ChatGPT, 58% of adults under 30 have used it, and 28% of employed adults now use it for work — a 20-point jump for the workplace figure over two years 3. The survey covers U.S. adults only and measures self-reported use rather than session volume, so it understates rather than overstates the shift for B2B research behavior. Younger and employed cohorts are exactly the segments most agency clients care about for consideration-stage discovery.
What changed is not the ranking algorithm. What changed is where the answer gets assembled. A prospect who once typed a query into Google and scanned ten blue links now reads a synthesized paragraph that names two or three brands and drops the rest. The retrieval layer decides which brands get named, and that decision draws on entity signals, third-party citations, and answer-shaped source content — not just domain authority.
Most agency SEO stacks were assembled for the ten-blue-links model. Rank trackers, backlink monitors, and content briefing tools still work, but they do not measure or shape the new citation surface. The tooling category built for that job — AEO tools — is younger than the behavior it claims to influence. That is why category selection matters more than brand selection right now.
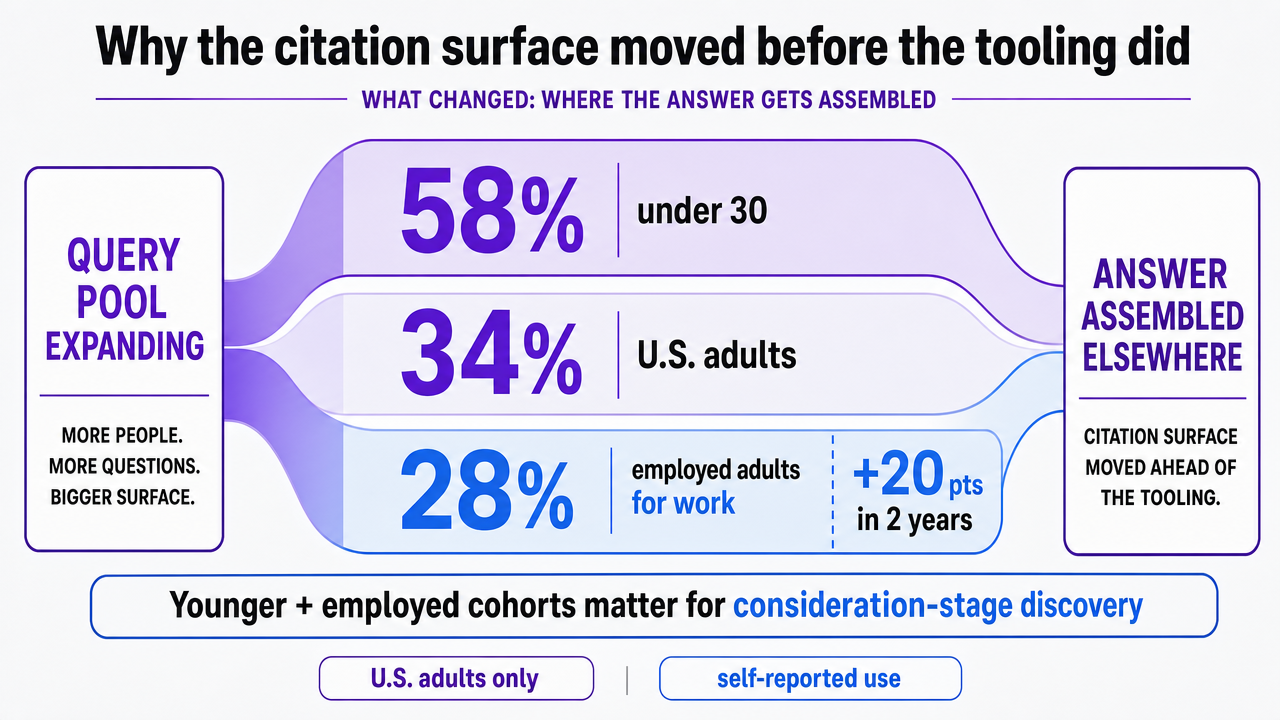 Visualize the three Pew adoption figures cited directly in this section (34% of U.S. adults, 58% of under-30s, 28% of employed adults for work) to reinforce why the query pool is expanding
Visualize the three Pew adoption figures cited directly in this section (34% of U.S. adults, 58% of under-30s, 28% of employed adults for work) to reinforce why the query pool is expanding
What agency SEO leaders are actually buying when they buy an AEO tool
Most AEO purchases start as a defensive move. A client asks why a competitor got named in a ChatGPT answer and the account team needs a dashboard to point at by Friday. That pressure has produced a market where the dominant product feature is visibility, not influence.
A monitoring subscription tells an agency which prompts surface which brands. It does not close the gap between the current citation set and the desired one. Closing that gap requires content published in the right shape, on the right domains, at a cadence answer engine crawlers actually catch. Forrester notes those crawlers revisit pages every few hours and can hit sites with hundreds of requests per second 9. Watching a dashboard does not move that needle.
The more useful way to frame the purchase: agencies are buying one of four things when they add an AEO tool — a mirror (monitoring), a map (prompt research), a graph (entity and authority), or a press (content production). Each solves a different part of the problem, and no single vendor covers all four well. Leaders who treat the category as a single-tool decision end up with overlapping mirrors and no press. The next section breaks the four categories apart so the trade-offs are explicit.
The four functional categories of AEO tooling
Mention monitoring: seeing citations without shaping them
Mention monitoring tools query answer engines on a schedule, log which brands appear in which responses, and produce a share-of-voice dashboard by prompt cluster. That output is useful. It is also the least differentiated part of the stack.
The category exists because clients ask a simple question — am I in the answer or not — and someone on the account team needs a defensible number by the next status call. Monitoring produces that number. It does not produce the mention.
Three operational limits show up quickly at portfolio scale.
- Prompt coverage is a sampling problem: an agency running 40 accounts cannot manually curate the prompt set for each vertical, so most tools ship with generic templates that miss the queries a client's actual buyers use.
- Answer variance is real — the same prompt returns different brand lists across sessions, models, and regions, which forces multi-sample logging to get a stable read.
- Monitoring reports drift toward vanity because they measure presence in a fixed prompt set rather than movement caused by any specific content action.
Agencies that treat monitoring as the whole AEO investment tend to renew the subscription and cut the content budget. That inverts the causal chain. Monitoring belongs in the stack as instrumentation, budgeted like rank tracking — not as the deliverable itself.
Prompt-space research: mapping the questions ChatGPT actually receives
Prompt-space research tools try to reconstruct the query pool: which questions real users are typing, in which phrasings, at which stage of a purchase decision. The category matters because the query surface is widening fast.
Pew's 2026 tracking shows U.S. adult ChatGPT use rising from 34% the prior year to 44% currently, with about half of U.S. adults now using AI chatbots and roughly four-in-ten using them for information searching 4. The population is self-reported U.S. adults, so the figure understates session volume and workplace queries, and it does not measure enterprise or logged-in behavior. What it does establish is that the prompt pool is no longer a niche — it is now a general-population research surface that agency clients cannot ignore.
Good prompt-research tools cluster questions by intent stage, extract the entities that appear alongside a brand, and flag phrasings where competitors currently dominate the response. Weaker tools rebrand keyword lists as prompts and add little.
The operational value shows up in briefs. A content brief built from actual prompt clusters names the sub-questions the answer needs to resolve, the entities it needs to reference, and the format the engine tends to synthesize from. Without that input, answer-shaped content is guesswork. With it, the same content team ships pages that map to how retrieval actually assembles answers.
Entity and authority builders: consolidating the graph that LLMs read
Retrieval-augmented models do not read a page the way a ranking crawler reads a page. They read entities and the relationships between them — a brand, its products, the people associated with it, the categories it operates in, and the third-party sources that corroborate all of that.
Entity and authority tools work on the substrate underneath the citation. They audit knowledge-panel coverage, reconcile inconsistent brand descriptions across Wikidata, Wikipedia, industry directories, and structured data on the client's own domain, and identify the third-party publications where a mention would carry retrieval weight. Some also monitor whether the entity graph for a brand is converging or fragmenting over time.
This category is where legacy SEO experience compounds. Agencies that already run structured data audits, digital PR outreach, and citation cleanup for local clients are doing 60% of the work an entity builder tool automates. The tool's job is to make that work legible at portfolio scale — surfacing which of 40 clients has a fractured entity graph this quarter, and which needs a fresh third-party citation before a competitor closes the gap.
McKinsey's survey finding that roughly half of consumers now intentionally seek AI-powered search engines to discover and evaluate brands raises the stakes on entity coherence 8. A brand that describes itself three different ways across sources gives the model three different brands to choose from — and it may choose none.
Answer-shaped content production: the category most stacks under-fund
The first three categories reveal problems. This one solves them. It is also the category where most agency budgets fall short.
Answer-shaped content is not blog content with an FAQ appended. It is source material structured the way retrieval systems synthesize: a direct claim in the first sentence, supporting evidence with named sources, sub-questions resolved as discrete sections, and entities referenced consistently across the page. Forrester's guidance to marketers is to map authoritative content to shopper questions across answer engines and to publish credible FAQs authored by subject-matter experts 9. That is a production spec, not a content-marketing tip.
Production tools in this category range from AI-assisted drafting environments to full execution platforms that combine research inputs, entity constraints, editorial approval, and publishing. The differentiator is whether the tool can hold answer structure across dozens of pages per month per client without a specialist reviewing each draft.
This is where the agency delivery constraint actually bites. Monitoring, prompt research, and entity work all produce backlog items. Production is what clears the backlog. An agency with best-in-class insight tools and a bottlenecked content team will watch competitors get cited while its own recommendations sit in a briefing queue.
Vendors in this category include AI-assisted writing suites, integrated content operations platforms, and approval-first execution systems such as Vectoron, which route drafts through human sign-off before publishing.
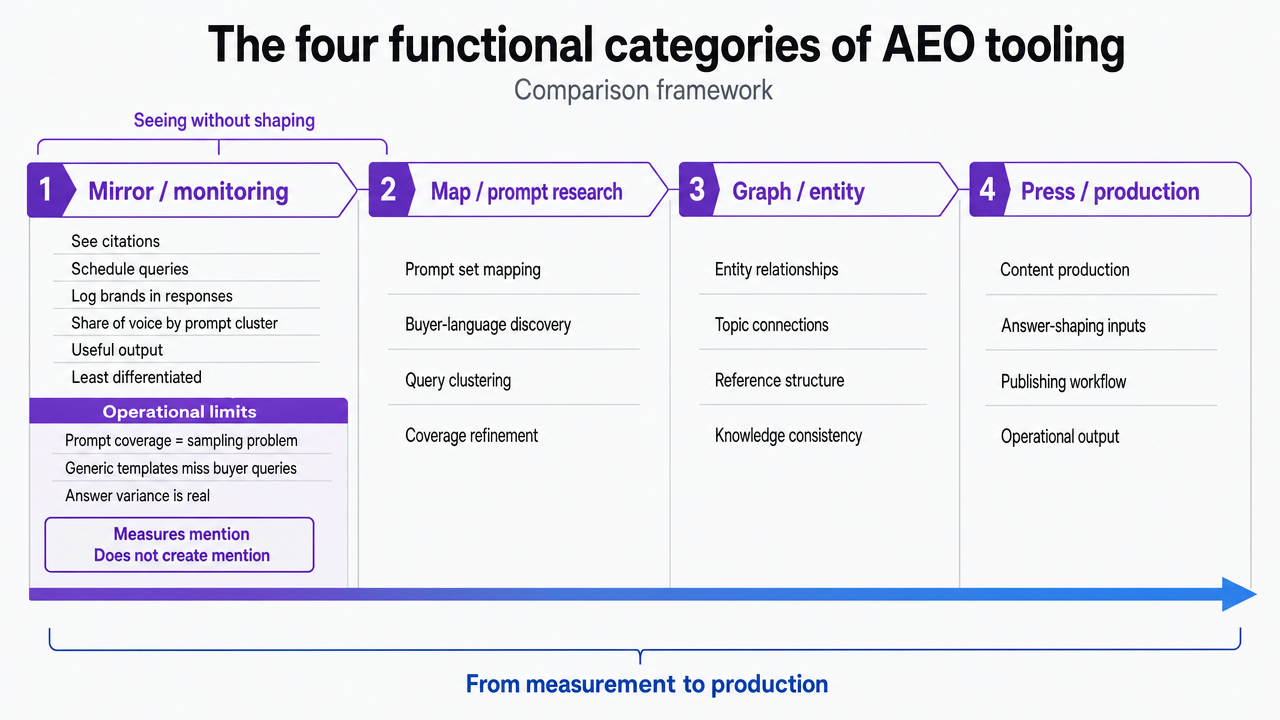 Process infographic mapping the four functional categories introduced in this section (mirror/monitoring, map/prompt research, graph/entity, press/production) as a comparison framework
Process infographic mapping the four functional categories introduced in this section (mirror/monitoring, map/prompt research, graph/entity, press/production) as a comparison framework
Test AEO brand mention strategies in real time
Experiment with live, publishable AEO workflows to validate ChatGPT brand mention outcomes across client portfolios.
Publishing cadence is the real AEO variable
Schema markup gets most of the technical AEO attention. Cadence gets almost none of it. That ordering is backwards.
Forrester's analysis of answer engine crawler behavior found that these crawlers ignore protocols such as robots.txt, revisit the same page every few hours, and can hit websites with hundreds of requests per second 9. Traditional search crawlers wait days between visits to a mid-authority page. Answer engine crawlers do not wait. That difference reshapes what a publishing calendar has to look like to influence what an LLM retrieves.
A page updated once a quarter competes against sources updated weekly. When the retrieval layer assembles an answer, it favors material that is both structurally clean and recently confirmed. An agency that ships one refresh per client per month is publishing at roughly the cadence the crawler expects to see change. An agency that ships one refresh per client per quarter is publishing below the noise floor.
This is where the schema-first framing fails. A perfectly marked-up page that has not been touched in eight months signals staleness to the retrieval layer regardless of its JSON-LD. Fresh, answer-shaped content with adequate structured data outperforms stale, immaculately marked-up content in citation frequency. The correct order of operations is publish, mark up, refresh, republish — not audit, audit, audit.
At portfolio scale, cadence becomes an execution question, not a strategy question. An agency running 40 accounts needs a production system that can move 40 to 120 answer-shaped pages per month through research, draft, review, and publish. Legacy briefing cycles measured in weeks per page cannot hit that number without proportional headcount. That is the constraint AEO tooling has to solve, and it is the constraint most monitoring-first stacks quietly ignore.
The citation loop: how a mention actually gets earned
A brand mention in a ChatGPT answer is the last step in a chain that starts weeks or months earlier. Understanding the chain is what separates agencies that can influence citations from agencies that only watch them.
The loop has five stages.
- A research signal — a prompt cluster, a competitor mention, a client-side product update — identifies a question the answer engine is being asked but not resolving in the client's favor.
- Entity and authority work makes sure the brand is described consistently across the sources retrieval systems already trust.
- Answer-shaped content is published on the client's domain and on adjacent surfaces the brand controls or influences.
- Third-party pickup extends the citation footprint: trade press coverage, expert roundups, industry directories, and structured references that corroborate the same claims.
- The LLM retrieval layer assembles an answer and, if the entity and evidence are coherent, names the brand.
Each stage feeds the next. Skip the entity work and the third-party pickup lands against a fractured brand description. Skip the third-party pickup and the answer-shaped content sits on one domain with no external corroboration. Skip the research signal and the whole loop optimizes for questions no one is asking.
McKinsey's finding that half of consumers now intentionally seek AI-powered search engines to evaluate and discover brands raises the cost of a broken loop 8. Pew's separate data point — that only about one-in-ten U.S. adults get news often or sometimes from AI chatbots — bounds the claim in the other direction 5. The loop matters for research and consideration, not for breaking news. Agencies should invest accordingly: prioritize evergreen answer-shaped content and entity coherence over news-cycle chasing.
The operational takeaway is that no single tool runs the loop. Monitoring surfaces stage one, prompt research sharpens it, entity builders handle stage two, production and outreach handle stages three and four, and the retrieval layer decides stage five on its own schedule. The agency's job is to keep every stage moving on the same cadence across every account.
Portfolio economics for agencies running AEO across many accounts
If you manage 15 to 80 client accounts, the math changes
A quick audience marker before this section develops: the economics below are written for agency portfolio operators, not for single-brand marketing teams. The unit of analysis is one client account inside a book of 15 to 80.
At that scale, per-account fixed costs dominate. A monitoring subscription priced for one brand becomes a line item repeated 40 times. A senior strategist reviewing prompt clusters for one vertical becomes the same strategist expected to review 12 verticals. A briefing cycle that runs two weeks per page becomes the reason 30 clients are behind schedule at once.
The compounding works in the other direction too. An entity audit template built once applies across every account in the same vertical. A production workflow that ships one answer-shaped page per week per client is roughly the cadence Forrester's crawler-behavior data suggests answer engines expect to see change 9. Centralized execution turns each new account into a marginal cost rather than a fresh setup. That is where portfolio math either works or breaks.
Consolidated stack versus specialist stack, per account per month
The comparison below uses variable placeholders rather than invented benchmark prices, because published category-wide AEO tool pricing is thin and specialist rates vary by market. The only fixed anchor is the supplied trial price for one consolidated execution platform.
| Cost line, per account per month | Specialist stack (assembled) | Consolidated stack (execution platform) |
|---|---|---|
| Mention monitoring subscription | Per-brand SaaS seat | Included module |
| Prompt-space research | Separate SaaS seat or manual analyst time | Included module |
| Entity and authority work | Specialist hours × loaded rate | Templated workflow, reviewer hours only |
| Answer-shaped content production | Freelance or in-house writer hours × loaded rate | AI-assisted drafting, approval-gated |
| Third-party citation outreach | Digital PR retainer share | Digital PR retainer share (unchanged) |
| Coordination overhead | PM hours × loaded rate, across vendors | Single approval queue |
| Platform anchor | Sum of above, per account | $599/mo trial pricing on the consolidated platform |
Two dynamics matter more than the exact numbers. First, the specialist stack scales linearly: adding an account adds another set of subscriptions and another PM slot. The consolidated stack scales sub-linearly on tooling and templated work, so the marginal account costs less than the average account. Second, the specialist stack pays for insight tools that generate backlog and pays specialists again to clear it. The consolidated stack shortens the distance between the signal a monitoring tool surfaces and the page that answers it.
The operational takeaway: agencies whose per-account margin is being squeezed by AEO scope creep should audit where the linear costs sit — usually monitoring seats and freelance drafting — and consolidate those two lines first.
See How Leading Agencies Automate AEO for Brand Mentions in ChatGPT
Request a walkthrough of AI-powered workflows that monitor, optimize, and report on brand mentions across conversational AI—including ChatGPT—at scale, with full approval controls for agency teams.
Governance the agency owns, not the client
AEO governance sits with the agency because the agency operates the production system. Clients approve outputs; they do not run the drafting environment, the prompt library, or the grounding-data policy that decides what a model can and cannot cite. Treating governance as a client-side legal review misses where the actual risk lives.
NIST's AI Risk Management Framework and its Generative AI Profile give the working vocabulary. The framework is voluntary guidance, not a compliance standard, and it is designed to improve trustworthiness across the design, development, and use of AI systems 1. The GenAI Profile goes further for production workflows: define acceptable uses, raise internal audit cadence, and update policies for generative-AI-specific risks such as fabricated citations, source drift, and grounding-data leakage 6. Both documents assume the operator running the system is the party accountable for its outputs. For AEO work, that operator is the agency.
Three controls carry most of the weight at portfolio scale.
Acceptable-use policy : Names which client verticals allow AI-assisted drafting, which require human-only production, and which prohibit specific claim types outright — a live constraint in regulated categories where a fabricated statistic in a ChatGPT-cited page becomes the client's legal exposure and the agency's retention risk.
Grounding-data policy : Defines which sources the drafting environment is allowed to pull from, which are blocked, and how source attribution is preserved through review.
Audit cadence : Sets how often published pages are re-checked against their source claims, which matters because answer engine crawlers revisit content on a schedule measured in hours rather than months 9.
The operational takeaway: write the acceptable-use and grounding-data policies once, apply them across every account, and log approvals inside the same workflow that ships the content. Governance held outside the production system does not govern the production system.
A framework for evaluating an AEO tool against agency delivery
Tool evaluation at portfolio scale is not a feature-matrix exercise. It is a delivery-fit test. Five questions separate tools that will compound across 40 accounts from tools that will add another line item to the monthly stack.
- Does the tool solve for a category the current stack is missing, or does it duplicate a mirror already in place?
- Does its output land as an executable brief, or as a report that still needs an analyst to translate it?
- Does it hold answer structure across dozens of pages per month per client without a specialist reviewing every draft?
- Does it fit inside a single approval workflow, or does it create a parallel queue that a project manager has to reconcile?
- Does its cost scale sub-linearly with the account count, or does it re-price with every new brand added?
A tool that fails questions two through four generates backlog. A tool that fails question five compresses margin as the portfolio grows. Agencies clearing 40 accounts should score every AEO purchase against those five before renewal, and consolidate whichever line items produce the most linear cost — usually monitoring seats and freelance drafting. The differentiator is not which tool an agency owns. It is whether the stack ships the page the monitoring dashboard said was missing.
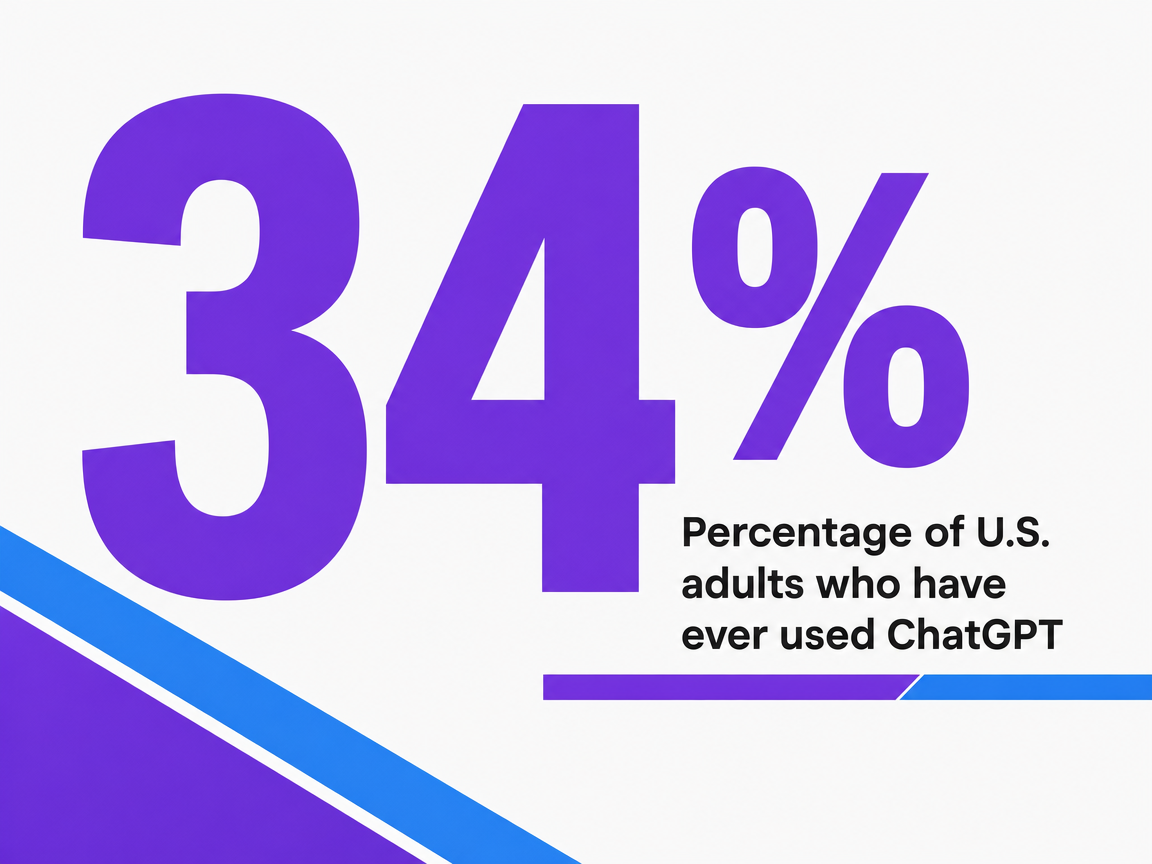 Percentage of U.S. adults who have ever used ChatGPT
Percentage of U.S. adults who have ever used ChatGPT
Percentage of U.S. adults who have ever used ChatGPT
Frequently Asked Questions
References
- 1.AI Risk Management Framework | NIST.
- 2.Artificial Intelligence Risk Management Framework (AI RMF 1.0).
- 3.ChatGPT use among Americans roughly doubled since 2023.
- 4.Americans and AI 2026: Chatbots, Smart Devices and Views on Impact.
- 5.Relatively few Americans are getting news from AI chatbots like ....
- 6.NIST.AI.600-1.GenAI-Profile.ipd.pdf.
- 7.Teens, Social Media and AI Chatbots 2025.
- 8.Winning in the age of AI search: The new front door to the internet.
- 9.The Marketer's Guide To Answer Engine Optimization.
- 10.Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile.
- 11.Responsible AI | The 2025 AI Index Report.