
Key Takeaways
- Only 16% of brand marketers systematically track AI search performance 1, giving agencies a narrow window to sell Generative Engine Optimization before larger brands build in-house capability.
- A credible tool must answer four questions per prompt: brand presence, ranked recommendation position, model characterization, and cited sources, or agencies will manually stitch workflows across vendors.
- Score vendors on five criteria—measurement depth, execution linkage, governance, vertical fit, and attribution—treating data handling and NIST AI RMF alignment 9as pass/fail rather than weighted.
- Disqualify vendors that guarantee placement, withhold the data processing addendum, hide prompt libraries, or suppress raw answer logs, since each creates FTC substantiation or data-deletion exposure 10, 7.
- For portfolio agencies, consolidation economics matter: measurement, production, and reporting hours multiplied across clients determine whether a multi-vendor stack or integrated platform is defensible.
- Run a 60-day pilot with three gated phases—baseline and governance, execution and remediation, then attribution and defensibility—scoring only on pilot data rather than sales-deck claims.
The Buying Window Agencies are Staring Into
Generative engines have become a primary search channel for buyers researching various services. Agencies serving these verticals must now identify which AI brand visibility optimization tools offer genuine value and longevity.
Agencies that act quickly will gain a significant advantage. A McKinsey analysis revealed that only 16% of brand marketers currently track AI search performance systematically1. This indicates a much smaller percentage is actively optimizing their presence in generative AI answers from platforms like ChatGPT, Perplexity, Gemini, and Copilot. This gap presents a clear commercial opportunity for agencies to offer Generative Engine Optimization (GEO) services before client demand becomes widespread.
This window of opportunity is narrowing due to two key factors. Firstly, larger brands are building in-house teams for this capability, reducing their reliance on agencies once internal measurement systems are established. Secondly, the tooling category is rapidly consolidating, with measurement vendors adding execution features and content platforms integrating AI visibility tracking. This means an agency's tool selection in the near future will significantly influence its delivery model for subsequent renewal cycles.
This article evaluates tool selection based on a scored capability decision, providing a rubric for agency delivery leaders to justify their choices to CEOs or client procurement teams.
 Brands systematically tracking AI search performance
Brands systematically tracking AI search performance
Brands systematically tracking AI search performance
What an AI Brand Visibility Tool Actually Has to Do
An effective AI brand visibility tool must answer four critical operational questions:
- Does the brand appear in generative answers to buyer-intent prompts?
- What is its ranked position within the model's recommendations?
- How does the model characterize the brand?
- Which sources does the model cite to support its answer?
Other features are secondary.
While presence tracking is fundamental, the more challenging aspect is determining recommendation position within a synthesized answer. For example, if ChatGPT lists three options for a parent searching for pediatric orthodontics, the difference between the first and third position can determine whether a consultation is booked. A tool that only reports mentions without ordinal position fails to measure the most impactful variable.
Sentiment analysis and citation attribution are crucial for a complete picture. Generative engines summarize reputation signals, so a brand might be present and ranked but described in a way that hinders conversion. Citation attribution informs SEO leads which owned pages, third-party mentions, review sites, and directory listings the model uses, guiding content or digital PR remediation efforts.
McKinsey defines GEO as a discipline requiring diagnostics, content investment shifts, surface optimization, and dedicated KPIs1. A robust tool must cover this minimum functional footprint. Otherwise, agencies will spend excessive hours manually assembling workflows across multiple vendors and reconciling data. The most valuable tools integrate diagnostics and execution linkage seamlessly, eliminating the need for strategists to translate reports into briefs.
Test AI-Driven Brand Visibility Strategies Now
Evaluate real-time impact on multi-channel brand visibility using live campaigns before committing to a platform.
A Five-Criterion Rubric for Scoring Vendors
Measurement Depth: Presence, Sentiment, Recommendation Position
Measurement depth is a critical differentiator. Many vendor demonstrations falter here. A tool that merely reports brand name frequency in generative AI answers is performing keyword frequency analysis, not comprehensive visibility analysis. The key is whether the platform distinguishes three signals per prompt: brand presence, its ranked position in recommendations, and the model's characterization of the brand.
Baseline diagnostics are paramount. McKinsey's research indicates that even industry leaders can experience GEO performance lagging their SEO performance by 20-50% when comparing visibility in traditional search versus generative engines1. For clients with weaker organic authority, this gap is likely even wider. A tool unable to provide this baseline within the first week of a pilot is not a true measurement platform.
Prompt library construction is another crucial grading point. Prompts must accurately reflect buyer-intent language specific to the vertical, not generic queries. For a personal injury firm, this means prompts mirroring how an injured driver would query a chatbot late at night, across various model versions, geographies, and account states. Inquire about prompt set refresh mechanisms, how non-determinism in model responses is handled, and whether the full answer text or only extracted mentions are logged. Vendors unwilling to show raw response data may be concealing measurement inaccuracies.
Execution Linkage: From Diagnostic to Published Artifact
This criterion distinguishes mere measurement dashboards from platforms that drive actual KPI improvements. Execution linkage refers to the efficiency, measured in human hours and handoffs, between a diagnostic finding and its resolution through a published artifact. A tool that identifies a citation gap on a comparison page and then provides a PDF to the SEO lead creates additional work. Conversely, a tool that routes the finding into a content brief, drafts the revision, holds it for approval, and then publishes it, streamlines the process.
Evaluate this by tracing a single finding through the platform during a demo. If Gemini cites competitor review sites while ignoring the client's owned FAQ page for a specific query, observe the platform's subsequent actions. Strong vendors will demonstrate a queued revision, a schema recommendation, a digital PR target list, and a scheduled recrawl to confirm the change. Weaker vendors will simply generate a ticket.
This is crucial for agency delivery because McKinsey frames GEO as a connected loop of diagnostics, content investment shifts, on-surface optimization, and dedicated KPIs1. A platform that only handles one of these steps forces the agency to manage the others through freelancers, briefing documents, and CMS access. This fragmented approach can lead to significant hidden costs and inefficiencies.
Governance: FTC Exposure, NIST Alignment, Data Handling
For agencies in regulated verticals, governance is a critical filter. Three specific areas of exposure are paramount.
Firstly, data handling. The FTC mandates that AI companies uphold privacy and confidentiality commitments, with enforcement actions including the deletion of models built on unlawfully obtained data7. Any vendor processing client call recordings, form submissions, CRM exports, or first-party audience data must clarify how that data is used for training, who else benefits from that training, and what happens to derivative models upon client offboarding. Request the data processing addendum (DPA) early in the evaluation. Vendors reluctant to provide this are unsuitable for clients in legal, healthcare, or senior living sectors.
Secondly, outcome-claim substantiation. The FTC's Operation AI Comply initiative emphasizes that companies using AI to make deceptive or unsubstantiated performance claims face enforcement10. Vendors promising guaranteed first-position mentions, fixed citation lifts, or specific pipeline outcomes create substantiation liability that agencies will inherit when repackaging these claims for clients.
Thirdly, framework alignment. The NIST AI Risk Management Framework provides voluntary but authoritative guidance on trustworthiness in AI design, development, use, and evaluation9. Buyers should ask vendors to map their governance controls (e.g., model monitoring, bias review, incident response, lifecycle documentation) against the RMF functions. Vendors capable of this mapping have likely undergone enterprise procurement, simplifying legal reviews for the agency. Those who cannot will complicate every client legal review.
Governance should be scored as a pass/fail criterion, not a weighted attribute. A vendor excelling in measurement but failing in data handling is ultimately a failure.
Vertical Fit: Healthcare, Legal, Senior Living, Home Services
Generic GEO tools often fall short for agencies serving high-stakes service categories. The evaluation should determine if the platform's prompt libraries, content templates, and governance defaults align with the regulatory requirements of the target vertical.
For healthcare, behavioral health, and dental clients, the regulatory baseline is defined by patient safety and transparency expectations. FDA guidance on AI in Software as a Medical Device now includes transparency principles and marketing submission recommendations for machine learning-enabled functions, raising the bar for any AI system influencing patient discovery or evaluation of providers3. Peer-reviewed research on healthcare AI ethics underscores the need for representative training data, regular audits, and interpretable models, warning that biased visibility outputs can exacerbate existing care disparities4. A GEO platform optimizing a behavioral health group's presence must be auditable against these expectations, not just click-through rates.
For legal clients, the fit question is different. Bar association advertising rules vary by state, and generative engines frequently synthesize claims about outcomes, specialties, and experience that firms did not author. The tool must not only surface mentions but also identify and flag characterizations that could trigger a grievance.
For senior living and home services, location coverage is a key operational variable. A Dental Service Organization (DSO) with 40 practices or a home services franchisor with 60 territories requires prompt sampling that reflects geographic intent, not just national aggregates. Inquire how many location-modified prompts the vendor runs per client and how they report drift across markets. Platforms that treat multi-location visibility as a rollup rather than a per-location signal are not suitable for portfolio delivery.
Attribution: Connecting AI Mentions to Pipeline
Attribution is often overlooked by vendors but is a primary concern for agency clients. Generative engines rarely provide referral data like Google clicks, necessitating the reconstruction of the connection between a Perplexity recommendation and a booked consultation from adjacent signals.
Score the platform on three attribution mechanisms:
- Direct-to-site instrumentation: does it detect AI-referred sessions via referrer strings, UTM patterns, and known crawler fingerprints, and can it segment them from organic and direct traffic?
- Branded query lift: does it track post-mention increases in branded search volume and direct traffic in the relevant geographies?
- Call and form correlation: does it timestamp visibility changes against qualified call volume and pipeline events from the client's CRM or call intelligence stack?
Vendors should honestly acknowledge that AI attribution is directional, not deterministic; those claiming otherwise are subject to the FTC's deceptive claims guidance10. The best tools instrument correlated signals sufficiently to support a monthly report to a client CMO. A platform demonstrating a correlation between increased presence and pipeline growth within the same reporting window, with exposed geographic and temporal data, will withstand a Quarterly Business Review (QBR). A platform offering only vanity mention counts will not.
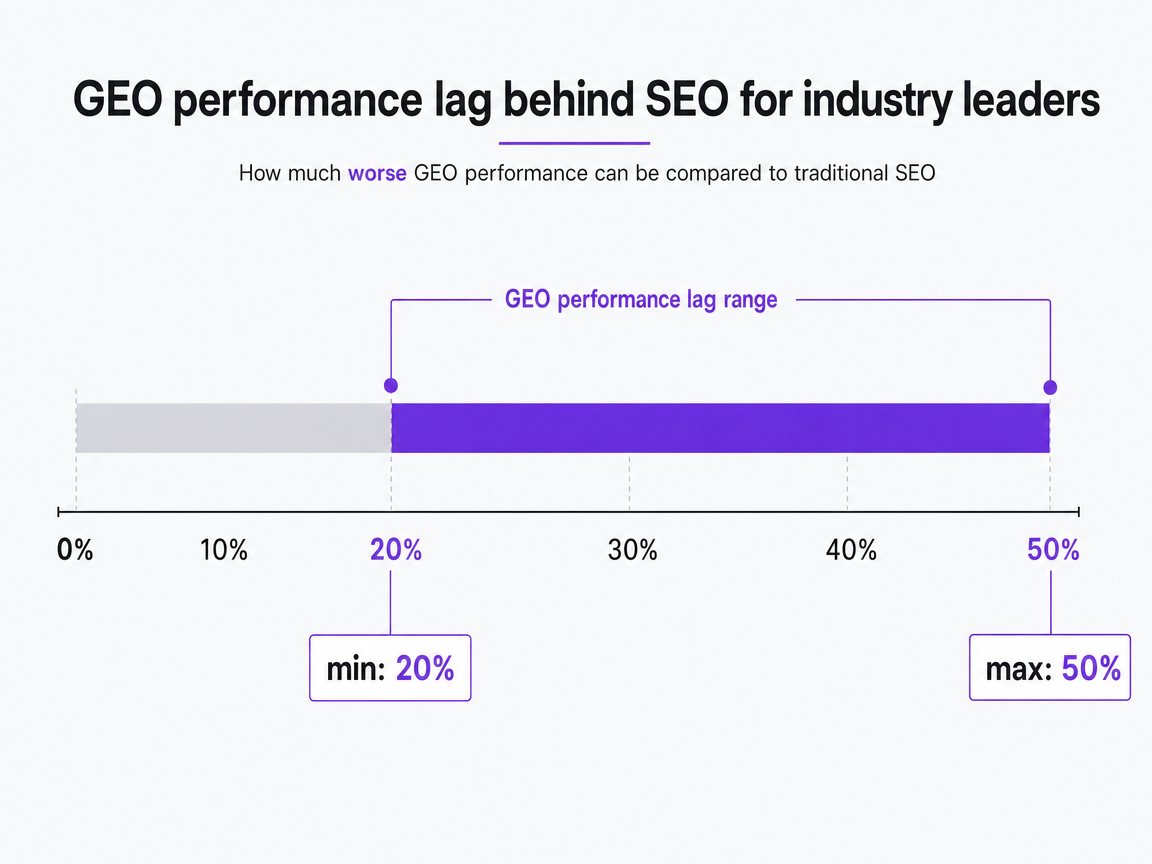 GEO performance lag behind SEO for industry leaders
GEO performance lag behind SEO for industry leaders
From a McKinsey report, this percentage range indicates how much worse Generative Engine Optimization (GEO) performance can be compared to traditional SEO, even for leading companies.
Red Flags That Disqualify a Vendor Before the Demo Ends
Certain vendor behaviors during the sales cycle are strong enough indicators to terminate the evaluation immediately. Each item below signifies a specific delivery risk for the agency.
Guaranteed placement language. Any vendor promising fixed citation lifts, guaranteed first-position mentions in ChatGPT, or specific ranking outcomes in Perplexity answers is making a substantiation claim explicitly targeted by the FTC's Operation AI Comply enforcement against deceptive AI marketing10. Generative engines are non-deterministic across sessions and model versions. A vendor ignoring this in their pitch will produce reports the agency cannot defend in a client QBR.
Refusal to share the data processing addendum (DPA). If the DPA is only provided after contract signing, or if the vendor cannot explain how client-supplied data is used for training, who else it trains for, and what happens to derivative models upon offboarding, the tool is unsuitable for law firm, dental, behavioral health, or senior living clients. The FTC has mandated the deletion of models and algorithms built on improperly obtained data, and this remedy extends to the agency providing the inputs7.
No raw answer logs. Vendors reporting aggregate brand mention counts without exposing the underlying model responses are concealing measurement errors. Agencies require the full answer text to audit sentiment, verify ranked position, and reconstruct citations. A dashboard without logs cannot support client disputes or monthly attribution reviews.
No governance mapping. Request the vendor's alignment with the NIST AI Risk Management Framework functions covering model monitoring, bias review, and lifecycle documentation9. A vendor unable to provide this mapping has not undergone enterprise procurement, meaning the agency will have to conduct every client legal review from scratch.
Undisclosed prompt libraries. If the sample set driving every report is a black box, the measurement is unverifiable. This is a deal-breaker.
See How Leading Agencies Evaluate AI Brand Visibility Optimization Platforms
Request a tailored walkthrough of advanced AI tools for scaling brand visibility across complex client portfolios—focused on measurable SERP share, workflow efficiency, and transparent approval controls.
If You Manage a Client Portfolio: The Consolidation Economics
This section addresses agencies managing a portfolio of clients, such as law firms, DSOs, home services franchisors, and senior living groups, where a poor tool choice can have multiplied negative effects.
The economics of GEO tooling involve three delivery activities that consume specialist hours per client per month: measurement (running prompt libraries, auditing answers, logging citations), production (briefing, drafting, and revising content to close visibility gaps), and reporting (translating diagnostics into client-facing narratives). A multi-vendor stack—e.g., one platform for measurement, freelancers for production, and a separate BI layer for reporting—forces the team to manage handoffs between disparate data models. A consolidated platform integrates these handoffs into a single workflow.
The relevant variables are transferable across any agency's cost model. The total monthly delivery cost per client is calculated by multiplying hours per client per activity by the blended specialist rate, summed across measurement, production, and reporting. Portfolio cost is this figure multiplied by the client count. The consolidation delta represents the difference between the multi-vendor total and the platform-consolidated total, assuming the same output volume.
| Activity | Multi-vendor stack (hrs/client/mo) | Consolidated platform (hrs/client/mo) |
|---|---|---|
| GEO measurement and audit | H₁ | H₁ × (1 − r₁) |
| Content production tied to findings | H₂ | H₂ × (1 − r₂) |
| Client reporting and QBR prep | H₃ | H₃ × (1 − r₃) |
| Monthly cost per client | (H₁+H₂+H₃) × rate | reduced total × rate |
The reduction factors (r₁, r₂, r₃) must be validated during the pilot, not accepted from vendor presentations. McKinsey's view of GEO as a connected loop of diagnostics, content investment, surface optimization, and dedicated KPIs highlights why consolidation is beneficial: each broken handoff between these steps results in duplicated effort and cost1. Base your decision on real pilot data to determine the consolidation delta.
Running the Pilot: A 60-Day Evaluation You Can Defend
A 60-day pilot is sufficient to verify vendor claims and short enough to avoid prolonged commitment to an ineffective tool. The pilot should be structured in three phases, each with a decision gate.
Days 1 to 14: Baseline and Access. Point the platform at two client accounts—one in a regulated vertical, one outside. Demand a comprehensive baseline diagnostic covering presence, recommendation position, sentiment, and cited sources across ChatGPT, Perplexity, Gemini, and Copilot. The DPA must be signed and the NIST AI RMF governance mapping delivered by day 149. Vendors failing this gate are not viable, regardless of demo quality.
Days 15 to 45: Execution and Remediation. Select three findings per client from the baseline and process them end-to-end through the platform. Examples include a citation gap on a comparison page, a sentiment issue on a location landing page, or a missing entity in the model's brand characterization. Track specialist hours consumed from diagnosis to published revision and confirmed recrawl. Log every handoff. If the team is still emailing Google Docs to freelancers, the promised execution linkage is not being delivered.
Days 46 to 60: Attribution and Defensibility. Review the reporting the vendor would present to a client CMO in a QBR. Assess whether it correlates visibility changes with branded search lift, direct traffic, and qualified call volume in the relevant geographies. Cross-reference any performance language against FTC substantiation expectations for AI outcome claims10. A report that cannot withstand client legal review is unusable for the agency.
At day 60, score the vendor using the five criteria from the rubric, relying solely on pilot data. Vendor claims from sales decks should not be considered.
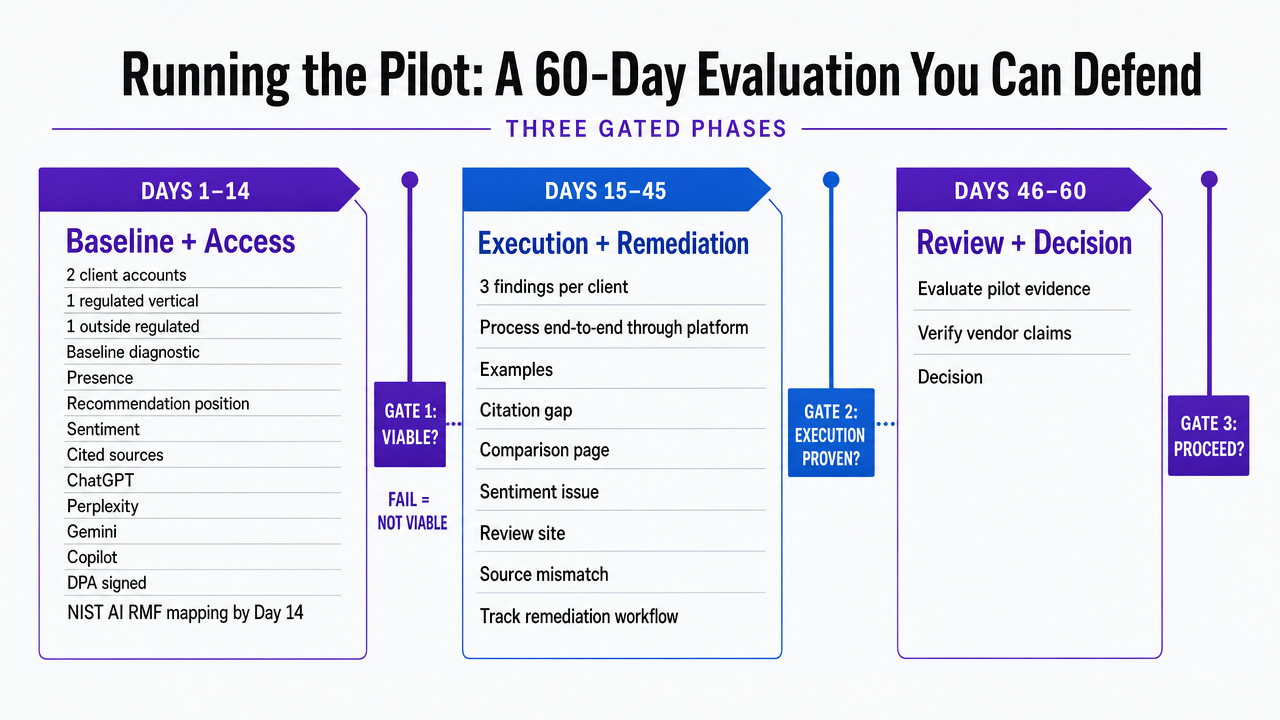 Process infographic mapping the three gated phases of the 60-day pilot described in the section, reinforcing the timeline and decision gates
Process infographic mapping the three gated phases of the 60-day pilot described in the section, reinforcing the timeline and decision gates
Frequently Asked Questions
References
- 1.Winning in the age of AI search.
- 2.Six Steps to Responsible AI in the Federal Government.
- 3.Artificial Intelligence in Software as a Medical Device.
- 4.Ethical and legal considerations in healthcare AI.
- 5.The Role of Artificial Intelligence in Personalizing Social Media Marketing Strategies and Its Impact on Customer Experience.
- 6.In creating an ad, using AI for scenes – but not people – may retain consumer trust.
- 7.AI Companies: Uphold Your Privacy and Confidentiality Commitments.
- 8.AI-Driven Personalized Pricing May Not Help Consumers.
- 9.AI Risk Management Framework.
- 10.FTC Announces Crackdown on Deceptive AI Claims and Schemes.