
Key Takeaways
- Treat AI content curation as a health recommender problem governed by five pillars: trusted sourcing, cohort-based audience modeling, explainability, privacy by design, and multi-dimensional evaluation 9.
- Draw a clear line between work the manager personally approves and what the system executes against existing approvals, keeping the human as the accountable reviewer 2.
- For multi-location operators, location is a variant axis, not a duplication axis — one approval can drive N publishes only when cohort fit and clinical substance hold across markets.
- Sequence the rollout sourcing-first, then explainability and de-identification, then the four-quadrant scorecard covering engagement, outcome proxy, fairness across cohorts, and workflow fit 1.
Curation as a health recommender problem, not a publishing one
Most healthcare marketing teams approach AI content curation as a publishing automation question: how to schedule more assets, across more locations, with fewer manual touches. That framing misses the actual problem. The clinical research community has spent over a decade describing a closely related system — the health recommender system (HRS) — and its design constraints map directly onto what a multi-location marketing program needs.
The scoping literature defines the job plainly. An HRS exists
"to retrieve trusted health information from the internet, to analyze what is suitable for the user profile and to select the best" items for that user 8.
Swap "user" for "prospective patient researching a service line" and the requirement is identical. A cardiology group publishing across 14 locations is not running a content calendar. It is running a recommender that has to match a defensible knowledge base to a segmented audience and justify each selection to a human reviewer.
That reframe carries operational weight. AI content curation in healthcare is decision-support for the marketing manager, not autonomous publishing — a distinction the broader AI-in-healthcare literature treats as load-bearing because of bias, interpretability, and accountability concerns 2. The manager remains the approver of record. The system's job is to surface the right candidate, with the right context, in a form that can be reviewed in minutes rather than hours.
Read this way, curation inherits the same five design pillars that govern credible HRSs: trusted sourcing, audience and context modeling, explainability, privacy by design, and multi-dimensional evaluation 9. Each one is a marketing requirement before it is a clinical one.
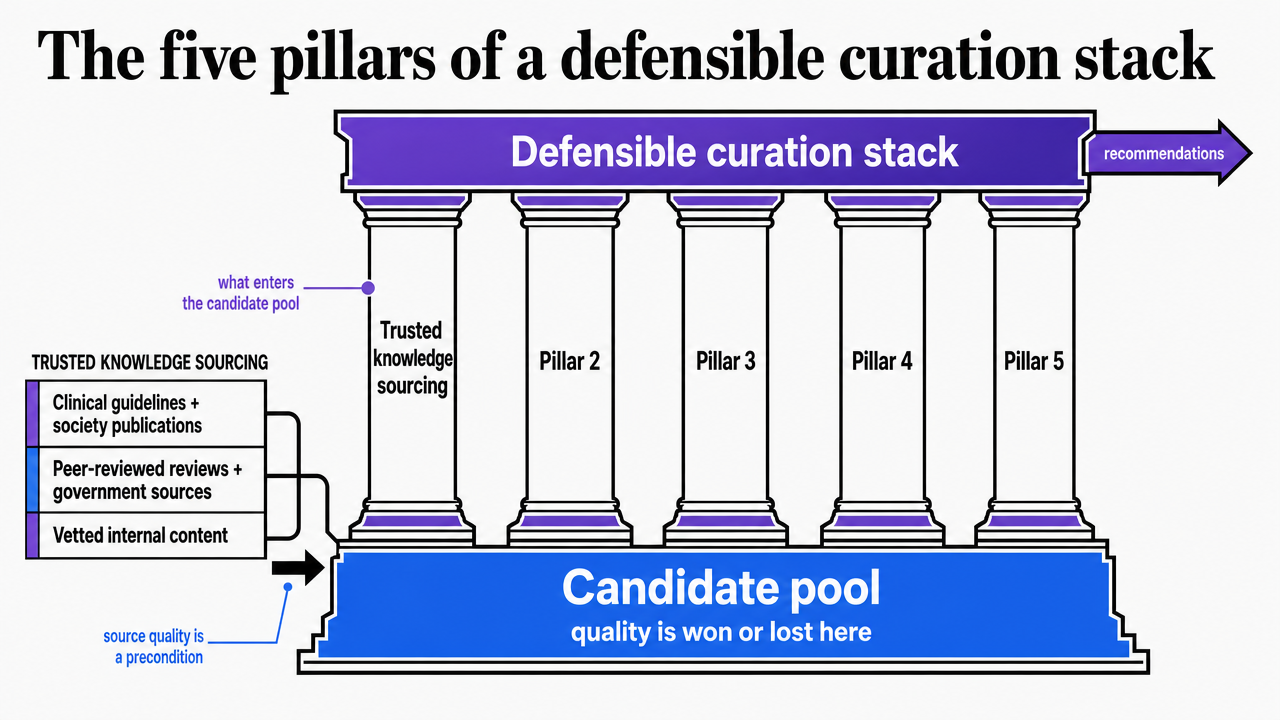
The five pillars of a defensible curation stack
Trusted knowledge sourcing: what enters the candidate pool
The candidate pool is the first place curation quality is won or lost. If the corpus an AI ranks against is a mix of vendor blog posts, scraped competitor pages, and old internal drafts, no amount of personalization downstream will produce defensible recommendations. The HRS literature is explicit on this point: the system's first job is
"to retrieve trusted health information from the internet, to analyze what is suitable for the user profile and to select the best" items for that profile 8.
Source quality is a precondition, not a filter applied at the end.
For a healthcare marketing program, that translates into three concrete sourcing decisions. The first is a tiered knowledge base: clinical guidelines and society publications at the top, peer-reviewed reviews and government health agency content next, then internally produced service-line assets that have already cleared medical review. Anything else sits in a holding tier and cannot enter the candidate pool without explicit promotion.
The second decision is tagging. Every ingested asset needs structured metadata — service line, condition, intent stage, reading level, locale, last clinical review date — because the recommender ranks on those fields. A dermatology asset tagged only as "skin" is invisible to a curation engine asked to surface Mohs surgery education for a 58-year-old researcher in a specific market.
The third decision is freshness governance. Clinical content decays. A cardiology piece written before a major guideline update should drop in rank automatically until a clinician re-reviews it. Treating the candidate pool as a living inventory, not a static library, is what separates a recommender from a glorified asset manager.
Audience and context modeling without PHI exposure
Personalization in healthcare marketing has to do real work without ever touching identifiable patient data. That constraint is not a limitation of the curation system — it is the design center. The machine learning literature on web-based health personalization frames the goal as delivering content
"predicted to be effective and engaging for patients" by combining structured and unstructured signals across sources 5.
The trick is choosing signals that carry predictive weight while staying outside the PHI perimeter.
A practical audience model for a multi-location operator runs on four signal layers:
- Behavioral signals come from site analytics, search query patterns, and content engagement — page sequences, dwell, scroll depth, asset completion.
- Contextual signals describe the session: device, geography down to the service area, time of day, referral source.
- Editorial signals come from the asset side: condition, service line, intent stage, reading level.
- Cohort signals describe the audience segment in aggregate, not the individual — for example, "users in a 25-mile radius of three dermatology locations researching procedural options."
Sentiment is the layer most marketing teams underuse. Deep learning recommenders in health settings have shown that sentiment derived from user-generated content and feedback can sharpen ranking and surface engagement issues that click data misses 4. A review corpus, an FAQ thread, a post-visit survey — aggregated and de-identified — tells the recommender which framings resonate for which conditions.
The hard rule across all four layers: the system models cohorts and contexts, not named patients. Individual session data is processed transiently and discarded or de-identified before it enters any training set or persistent profile. That keeps the model useful and the audit trail clean — and it forces the engineering team to treat re-identification risk as a first-class design problem rather than a downstream legal review.
Explainability as approval UX
The marketing manager who has to approve fifty recommended assets a week does not need a model card. They need to know, in seconds, why this asset was chosen for this audience and how confident the system is. That is an explainability problem, and the clinical XAI literature has already mapped what users actually want.
The systematic review of explainable AI in clinical decision support found that healthcare professionals consistently prioritize local explanations — specifically,
"explanation of features and their importance for specific outputs, certainty of output results, and explanation based on similar cases" 3.
Those three explanation types translate almost directly into an approval-screen specification for marketing curation.
Feature contribution answers the "why this piece" question. The approval card should show the top signals that drove the recommendation: matched service line, audience cohort, intent stage, freshness score, and the editorial source tier. A reviewer scanning that card can confirm the logic in one read or reject it on a specific factor — "wrong intent stage, this is a top-of-funnel cohort" — rather than a vague gut call.
Output certainty answers the "how confident" question. A recommender that surfaces every candidate at the same visual weight forces the human to do all the triage. Surfacing a calibrated confidence score, or at minimum a high/medium/low band tied to model agreement and audience-fit thresholds, lets the manager batch-approve the high-confidence queue and spend their attention on the marginal cases.
Similar-case explanations answer the "has this worked before" question. For each recommendation, the system should show two or three comparable past placements and their outcomes — engagement, downstream conversion, any flags raised in review. That gives the reviewer a precedent to reason from, which is closer to how editors actually decide.
Built this way, explainability stops being a compliance artifact and becomes the interface itself. The faster a reviewer can confirm or reject with reason, the more curation throughput a single approver can absorb.
Privacy by design: de-identification inside the pipeline
Privacy in an AI curation pipeline is an architectural decision, not a policy line item. HHS guidance under the HIPAA Privacy Rule defines two acceptable paths to de-identification: Expert Determination, in which a qualified statistician certifies that the risk of re-identification is very small, and Safe Harbor, which requires the removal of 18 specified identifier categories 10. Either path has to be wired into the data flow before any signal touches a model.
The Safe Harbor route is the cleaner default for most marketing curation work. The pipeline strips direct identifiers — names, geographic units smaller than the first three digits of a ZIP, dates more precise than year for anyone over 89, contact information, account numbers — at the ingestion boundary. What flows downstream is cohort-level aggregate data: session patterns, content engagement by audience segment, sentiment trends by condition. Expert Determination becomes the path when the operator wants finer-grained signals, such as detailed geographic clusters in a specific market, and is willing to commission the statistical risk assessment to justify it.
Conversational and unstructured signals deserve closer scrutiny. The analysis of AI chatbots and HIPAA compliance notes that the Privacy Rule treats health information as identifiable when
"there is no reasonable basis to believe that the information can be used to identify an individual" — and that re-identification risk in rich, unstructured conversational data is materially higher than in structured records 7.
A curation system that ingests chat transcripts, intake form free text, or post-visit feedback needs a tokenization and redaction step before that data enters any feature store, plus periodic re-identification testing on the de-identified outputs.
Two operational practices keep this defensible over time. First, separate the de-identification function from the recommender function — the team that decides what is safe to model from is not the team optimizing engagement. Second, log every de-identification transformation as part of the asset-level audit trail. When legal asks how a specific recommendation came to exist, the answer should be reproducible from the logs without involving the data science team. That is the difference between a pipeline that survives a privacy audit and one that triggers a rebuild.
Multi-dimensional evaluation beyond clicks
Click-through and open rate measure whether a recommendation got attention. They do not measure whether it was the right recommendation. The HRS research community has been organizing around exactly this gap — the scoping review protocol in BMJ Open is explicitly designed to map how recommender evaluations should account for outcomes beyond engagement, drawing lessons from across the digital health intervention literature 1. Marketing programs should adopt the same structure before vendors define it for them.
A workable evaluation scorecard runs on four quadrants.
- The first is engagement: standard signals — CTR, dwell, scroll, asset completion, downstream conversion — segmented by audience cohort and intent stage. This quadrant tells the team whether the recommender is surfacing content that earns attention.
- The second is outcome proxy. For patient education and self-management content, the proxy might be completion of a multi-asset sequence, return visits to related material, or appointment requests on the relevant service line. The point is to measure whether the content moved the audience closer to the action the program was built to drive, not just whether they clicked.
- The third is fairness across cohorts. A recommender that performs well in aggregate can systematically underperform for specific age bands, language groups, or geographies. Tracking the engagement and outcome metrics separately by cohort surfaces those gaps before they become equity problems. The autonomy literature on health recommenders for older adults is a useful prompt here — over-personalization that narrows options is its own failure mode, not just a missed click 6.
- The fourth is workflow fit: review time per asset, approval rate, rework rate, time from candidate surface to publish. These are the metrics that tell the marketing leader whether the system is actually compressing the work, or just relocating it. A recommender with strong engagement numbers and a ballooning rework rate is failing — the editorial cost is hidden in the reviewer's calendar.
Reported together on a single scorecard, the four quadrants make trade-offs visible. A change that lifts engagement but hurts fairness or workflow fit gets caught in the same review cycle, not three quarters later.
 Visualize the five governing pillars introduced in this section so readers can anchor the subsections that follow
Visualize the five governing pillars introduced in this section so readers can anchor the subsections that follow
Evaluate AI-driven content curation in real workflows
Test AI content curation performance using your actual marketing channels and approval processes, risk-free.
Approval-gated execution: who decides what, and when
The hardest decision in an AI curation rollout is not which model to use. It is drawing the line between work the manager personally approves and work the system is trusted to execute. Get that line wrong in either direction and the program fails: too much human review and the throughput gains disappear; too little and the marketing manager loses control of a regulated content surface they are ultimately accountable for. The decision-support literature on AI in healthcare is consistent that the human remains the accountable party, with the system acting as an aid to judgment rather than a substitute for it 2.
A workable split runs along three states:
Awaiting review : Everything that touches medical claims, condition language, new service-line launches, or any asset where the recommender's confidence score falls below the high band. The manager sees these as a prioritized queue with the explanation card attached — feature contributions, certainty, and similar-case precedent already rendered so the decision takes minutes, not a meeting 3.
In motion : Everything the system has been authorized to execute against an existing approval: republishing an evergreen patient education asset to a new location, sequencing a previously cleared nurture series, swapping a reading-level variant for a cohort that has already been modeled.
Published : The audit-trail state — what went live, where, when, under whose approval, and against which signals.
Two operating rules keep the line honest. First, any asset touching clinical substance moves to awaiting review on every material edit, not just on first publish. Second, the system never crosses cohorts without a fresh approval — a piece cleared for a post-procedure dermatology audience does not migrate to a pediatric service line because engagement looks promising. The manager's calendar gets compressed; their authority does not.
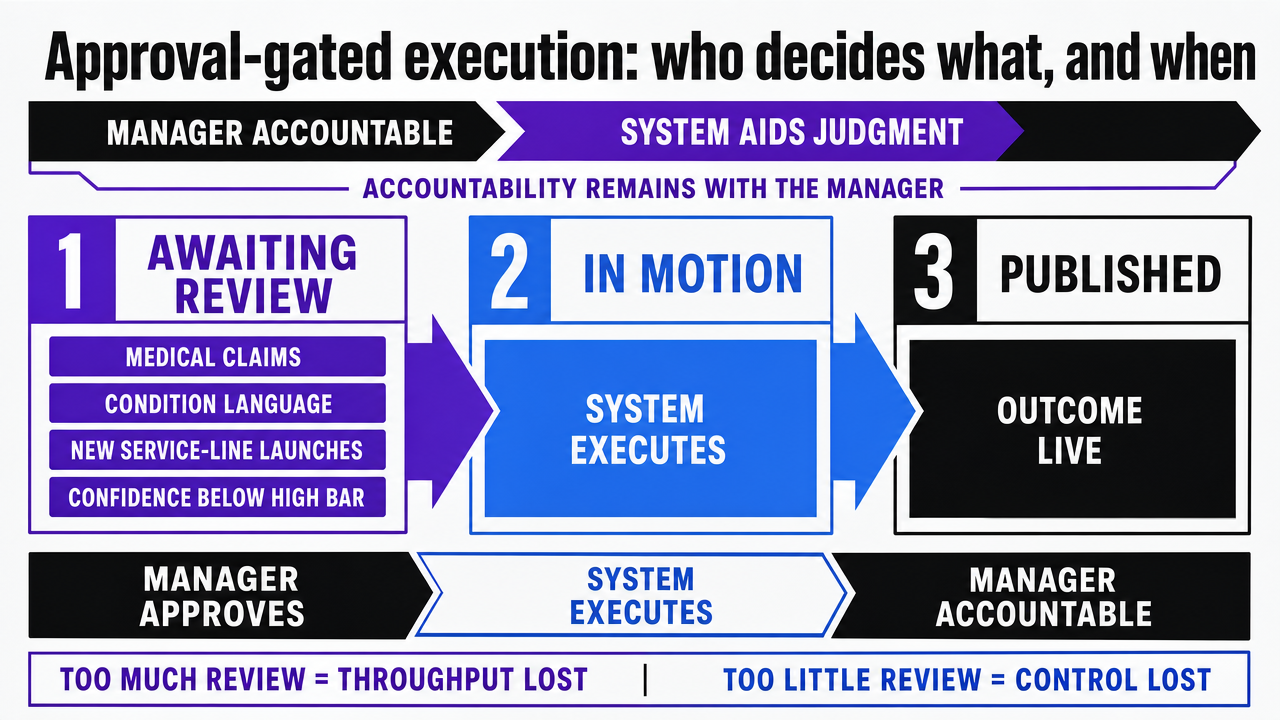 Diagram the three-state approval workflow (Awaiting Review, In Motion, Published) described in the section, including what triggers each state
Diagram the three-state approval workflow (Awaiting Review, In Motion, Published) described in the section, including what triggers each state
If you manage multiple locations: one approval, N publishes
The economics of curation change shape the moment a marketing manager is responsible for more than one location. A single-site program can absorb a per-asset review cycle. A 14-location dermatology group, a 30-clinic urgent care network, or a hospital system with seven service lines cannot — not without either bloating headcount or quietly skipping review. The question stops being "how do we curate faster" and becomes "how do we get one approval to do legitimate work across N publishes."
The math is straightforward enough to write on a whiteboard. If review takes R minutes per asset, the program produces A assets per location per month, and the operator runs L locations, the per-location model demands R × A × L minutes of manager time every month. The account-level model collapses that to R × A minutes when the asset, audience cohort, and clinical substance are shared across locations — with the system handling the N publishes against the single approval. The variables that move the answer are not pricing assumptions; they are review time, asset volume, location count, and how often cohorts genuinely diverge between markets.
The design constraint is that one approval cannot legitimately cover N publishes unless the recommender treats location as a variant axis, not a duplication axis. A patient education asset on minimally invasive cardiology cleared for a suburban Midwest market should publish to twelve sister locations with localized provider names, scheduling links, and service-area language — and not migrate to a market where the service line is not offered or where the audience cohort modeling shows a materially different intent mix. The decision-support framing holds: the manager approves the clinical substance and the cohort fit once, and the system executes the variant publishes with the audit trail attached 2.
Two failure modes deserve attention:
- Silent cohort drift — a recommender that treats all locations as one market because aggregate engagement looks healthy, while a specific geography or age band quietly underperforms. The fairness quadrant of the evaluation scorecard catches that, but only if cohort-level metrics are reported per location, not just per account.
- Approval inflation, where every minor localization triggers a fresh review and the consolidation gain disappears. The fix is a pre-agreed variant policy: which fields the system is authorized to swap (provider, location, scheduling link, reading-level variant for a previously modeled cohort) and which trigger a return to awaiting review (clinical claims, new conditions, untested cohorts).
Run cleanly, the account-level model turns location count from a tax on the manager's calendar into leverage on the same approval.
See How Enterprise Teams Streamline AI Content Curation at Scale
Request a walkthrough of AI-driven content approval workflows designed for multi-location healthcare and agency teams—ensuring full visibility, compliance, and measurable throughput across all service lines.
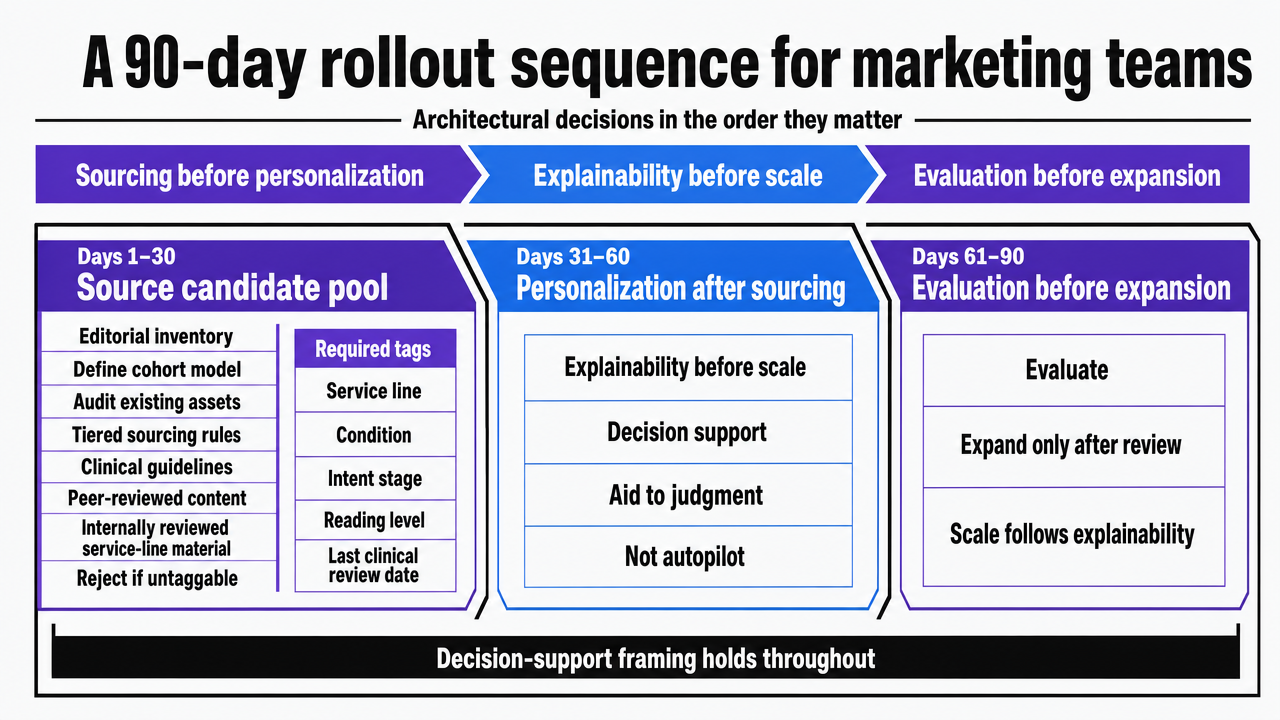
A 90-day rollout sequence for marketing teams
A curation system that takes a year to stand up loses to the publishing calendar it was meant to replace. A 90-day sequence works because it forces the team to make the architectural decisions in the order they actually matter: sourcing before personalization, explainability before scale, evaluation before expansion. The decision-support framing holds throughout — the manager is configuring an aid to judgment, not handing over the keys 2.
- Days 1–30: source the candidate pool and define the cohort model. The first month is editorial inventory work, not engineering. Audit every existing asset against the tiered sourcing rules — clinical guidelines, peer-reviewed content, internally reviewed service-line material — and reject what cannot be tagged with service line, condition, intent stage, reading level, and last clinical review date. In parallel, define the audience cohorts the recommender will rank against: behavioral, contextual, editorial, and aggregate sentiment layers, none of which require identifiable patient data 5. The output of month one is a tagged candidate pool and a written cohort model, both signed off by the marketing manager and medical reviewer.
- Days 31–60: wire the approval card and the de-identification boundary. Month two builds the interface the manager will actually live in. Each recommendation surfaces with feature contributions, a confidence band, and two or three similar-case precedents — the three explanation types the clinical XAI literature identifies as load-bearing for healthcare reviewers 3. At the same time, the data pipeline gets its de-identification step before any signal reaches the recommender, with the transformation logged at the asset level. Run the system in shadow mode: it recommends, the manager reviews, nothing publishes.
- Days 61–90: turn on the scorecard and authorize the in-motion lane. Month three is where consolidation gains start to show. Stand up the four-quadrant scorecard — engagement, outcome proxy, fairness across cohorts, workflow fit — and report it weekly 1. Once the high-confidence band has cleared a full review cycle without rework spikes, authorize the in-motion lane for previously approved cohorts and variant publishes. By day 90, the program has a defensible candidate pool, an approval interface the manager can absorb, a privacy boundary the audit will accept, and a measurement artifact that catches trade-offs in the same cycle they occur.
 Visualize the three 30-day phases of the rollout plan so readers can see the sequencing rationale at a glance
Visualize the three 30-day phases of the rollout plan so readers can see the sequencing rationale at a glance
Frequently Asked Questions
References
- 1.Evaluation of health recommender systems: a scoping review protocol.
- 2.Artificial Intelligence and Decision-Making in Healthcare.
- 3.Explainable AI in Clinical Decision Support Systems: A Systematic Review.
- 4.Health Recommendation System using Deep Learning-based Sentiment Analysis.
- 5.Harnessing Machine Learning to Personalize Web-Based Health Content.
- 6.Rethinking Health Recommender Systems for Active Aging.
- 7.AI Chatbots and Challenges of HIPAA Compliance for AI Developers in Health Care.
- 8.Health Recommender Systems Development, Usage, and Evaluation (Scoping Review).
- 9.Development and Evaluation of Health Recommender Systems: Scoping Review.
- 10.Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the HIPAA Privacy Rule.