
Key Takeaways
- Require vendors to define incidents in writing against a real taxonomy like CSET's, so detection scope is explicit before contracts and post-incident reviews are predictable 7.
- Map each tool against NIST AI RMF's Govern, Map, Measure, and Manage functions to expose gaps, since most vendors overfit to Measure and neglect Govern for multi-client agencies 4.
- Separate model monitoring from workflow monitoring and insist both live in one reconcilable system of record, because drift dashboards miss bypassed approvals and approval logs miss model decay 1.
- Test the audit trail during trial with a real adverse client scenario, confirming the tool recovers model version, prompt, retrieval context, reviewer identity, timestamps, and edit diffs 9.
- Evaluate pricing against downside exposure such as EU AI Act penalties and client indemnification claims, then negotiate retention, portability, SLAs, and export formats rather than seat counts 8.
The oversight gap is now a procurement problem
Worker access to AI rose 50% in 2025, while only one in five companies reports a mature governance model for autonomous AI agents 3. This gap creates agency liability. Every AI-generated campaign brief, every landing page variant tested by an agent, and every intake call summarized by an LLM operates within workflows that most agencies cannot audit end-to-end.
Agency owners face pressure from two sides. Clients in regulated sectors like healthcare, legal, and financial services demand clear answers on how AI outputs are reviewed before public release. Meanwhile, agencies must scale production without increasing headcount, leading to continuous AI stack growth, often outpacing governance capabilities.
Consequently, vetting an AI monitoring tool is no longer just about features; it's a critical procurement decision. The right tool provides an audit trail that streamlines security reviews, client renewal conversations, and incident post-mortems. The wrong one results in unused dashboards. The following five steps are designed for agency principals already using AI in production who need to implement accountability layers. Each step prioritizes governance function over software capability, addressing key questions like "who approved this," "what changed," and "where is the record."
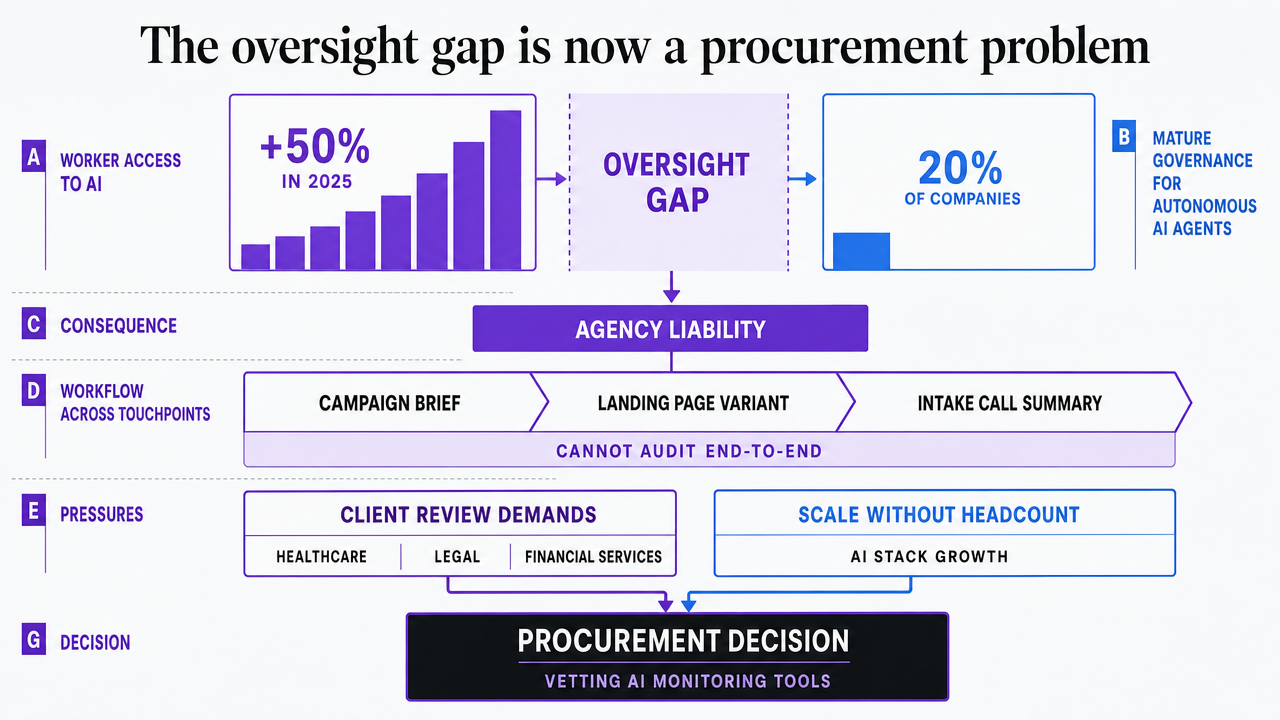 Visualize the governance gap cited in the opening: 50% rise in worker access to AI in 2025 versus only 20% of companies with mature governance for autonomous AI agents, directly supporting the section's core argument
Visualize the governance gap cited in the opening: 50% rise in worker access to AI in 2025 versus only 20% of companies with mature governance for autonomous AI agents, directly supporting the section's core argument
Why 'monitoring' is the wrong word for what agencies actually need
The term "monitoring" suggests passive observation. Agencies, however, require a robust system of record. Simply watching a dashboard fails to satisfy a client's legal team asking for details on a specific model version, its approval, and drift metrics. This demands a comprehensive log, an approval chain, and a searchable history—not just a live chart.
Most tools marketed as "monitoring" were built for machine learning operations teams tracking single production models, focusing on inference latency, prediction distributions, and feature drift. While these signals are important for data science, they don't address agency accountability. An agency managing multiple client accounts with a shared AI stack needs to prove that outputs were governed before shipping and reconstruct events when issues arise.
Regulators are already establishing these standards. The OCC's 2026 model risk guidance emphasizes "conducting ongoing monitoring and outcome analysis" alongside comprehensive model inventories and vendor oversight 1. NIST's AI RMF Manage function further requires "actionable strategies for managing AI risks, monitoring system performance, and mitigating threats" with documented incident response protocols 5. Both describe an operational discipline, not merely a dashboard.
The practical shift for agency principals is to move from shopping for observability to investing in accountability infrastructure. This means reframing capability questions: instead of "does this show drift," ask "does this produce a defensible record when a client, auditor, or insurer asks what happened?" Tools that can't answer this quickly are dashboards; those that can are governance systems.
Evaluate AI monitoring impact in your workflow
Test real-time AI oversight on live campaigns before committing to a full platform rollout.
The 5-step vetting framework
Step 1: Force the vendor to name what an incident is
Before any demonstration, require the vendor to define, in writing, what the tool considers an incident—not just alert categories, but a specific list. If the response is vague, such as "anomalies" or "performance degradation," the conversation should pause.
MIT's AI Incident Tracker, using CSET's AI Harm Taxonomy, categorizes over 1,400 real-world incidents, including content harms, safety issues, bias, and security failures 7. This taxonomy is a valuable starting point. Agencies using LLMs for client campaigns may encounter the following distinct incident classes:
- hallucinated ad copy
- off-brand outputs
- prompt injection
- PII leakage in call summaries
- silent regressions from model updates
Each is a distinct incident class requiring specific detection. No single monitoring product handles all equally well.
The vetting process involves providing the vendor with this taxonomy and asking which categories the tool detects natively, which require custom rules, and which are outside its scope. CSET's research highlights the importance of a hybrid reporting model combining automated detection with human-flagged events, as pure automation often misses context-dependent harms 6. A monitoring tool unable to ingest human-flagged incidents and correlate them with model logs is incomplete.
Two key questions cut through vendor ambiguity: First, what is the tool's default incident schema, and can it be extended without vendor engineering? Second, when a client escalates an output quality complaint, what evidence does the tool provide within the first fifteen minutes of investigation? Vague answers here predict difficult post-incident reviews.
Agencies that skip this step often end up with a product that alerts on latency spikes but misses critical failure modes relevant to their clients. Defining the incident set upfront shifts the sales dynamic, requiring the vendor to prove fit against specific requirements.
Step 2: Map the tool to Govern, Map, Measure, Manage
NIST's AI Risk Management Framework structures AI oversight into four functions: Govern, Map, Measure, and Manage 4. A monitoring tool addressing only one function is a point solution, not a platform. The vetting exercise requires mapping the tool's capabilities across all four functions before commitment.
Govern : Represents the policy layer. The tool should support role-based access, documented approval workflows, and a model inventory for every AI system used for each client. If the vendor cannot demonstrate how a new model is registered, assigned an owner, and linked to a client account, the Govern function is inadequate.
Map : Is the context layer, defining the model's purpose, output users, and data flows. A monitoring tool contributes by maintaining metadata such as model version, prompt library version, retrieval sources, data classification, and the business process impacted by the output. Without this, drift metrics lack meaning.
Measure : Is where most vendors focus their marketing, covering drift detection, output quality scoring, bias evaluation, latency, and cost tracking. The critical vetting question is whether these metrics are computed against an agency-defined baseline, not a vendor default. Generic quality scores that cannot be tailored to a client's brand voice or compliance vocabulary generate noise.
Manage : Is the response layer. NIST's framework calls for actionable strategies for monitoring system performance, mitigating threats, and executing documented incident response and communication protocols 5. Practically, this means the tool must support incident escalation paths, remediation logging, and exportable after-action documentation for clients or auditors.
This mapping exercise often reveals a pattern: most tools excel in Measure, some extend to Manage, but few adequately address Govern for agencies managing multiple client accounts under diverse contracts. This gap is crucial for the buying decision. A tool scoring well in three out of four functions might still be suitable if the missing function is covered by another existing system, but this gap must be explicitly acknowledged.
Step 3: Separate model monitoring from workflow monitoring
Two distinct products are often conflated under the same label. Model monitoring observes the AI system itself: prompts, tokens, drift metrics, evaluation scores, and cost. Workflow monitoring tracks the human processes: who requested, reviewed, and approved the output, and which version shipped. Agencies require both, and most vendors specialize in one over the other.
This distinction is vital because failure modes differ. Model-layer failures include hallucinations, bias, prompt injection, or quality regressions. Workflow-layer failures involve unreviewed outputs shipping, backdated approvals, or incorrect prompt library usage. A drift dashboard won't detect a strategist bypassing an approval queue.
The OCC's revised model risk guidance directly addresses this dual requirement, calling for continuous monitoring and outcome analysis alongside comprehensive model inventories and vendor oversight 1. Outcome analysis is a workflow concept, assessing whether human processes achieved the intended result, not just if the model produced a plausible one. Agencies adopting bank-grade discipline for regulated clients need both dimensions logged in a single system or reconcilable across integrated systems.
The vetting test is a scenario walk-through. If a client complains about published content, can the tool, in one query, provide the model version, prompt, retrieval context, reviewer identity, approval timestamp, and any prior rejections? If this requires exporting from multiple tools and joining spreadsheets, the workflow layer is insufficient.
Agencies buying only model monitoring gain telemetry on system performance but lack records of human decisions that allowed faulty outputs. Conversely, agencies with only workflow monitoring have clean approval logs but no signal when the underlying model degrades. The buying decision hinges on finding a vendor that covers both or two vendors that integrate seamlessly as a unified system of record.
Step 4: Test the audit trail against a real client scenario
Vendor demonstrations typically showcase ideal scenarios. The vetting process should involve testing an adverse scenario during the trial period.
Use a specific, real-world client situation. For example, a healthcare client's paid social ad contained an off-label claim, generated by an LLM three weeks prior, edited by a strategist, approved by an account lead, and published via a scheduling tool. Attempt to reconstruct this chain within the monitoring platform. Measure the time taken, the number of systems accessed, and the evidence produced.
Four key artifacts should be recoverable:
- the exact model version and prompt used for the initial draft,
- any retrieval context or reference material provided to the model,
- the full approval chain with identities and timestamps, and
- the difference between the AI-generated draft and the published version.
Missing any of these creates an audit trail gap that a client's legal team will identify.
NTIA's accountability report emphasizes transparency, advocating for greater disclosure about AI system models, architecture, training data, performance, limitations, and appropriate use, recommending standardized disclosures like model cards 9. For agencies, this means the tool should generate a client-facing incident report without requiring a data engineer. CSET's hybrid reporting analysis adds that serious incidents may need escalation to external bodies (client compliance, professional associations, regulators), requiring the monitoring tool to support clean export 10. A structured document with model metadata, decision chains, and remediation notes is required, not just a JSON dump.
Agencies conducting this test during a trial often find their preferred vendor cannot complete the scenario within a business day. This indicates either the product is not ready, or the agency's workflow needs redesigning around the product's actual capabilities before contracts are signed.
Step 5: Price the downside, not the subscription
Monitoring tools are typically priced by seat, model, or inference volume. While these figures are relevant for finance, the vetting decision should be based on the potential downside the tool prevents.
The EU AI Act illustrates the maximum downside for agencies with European exposure. Deloitte's analysis indicates that infringements related to prohibited AI systems can incur fines up to EUR 35 million or 7% of global annual turnover 8. While most agencies won't face the highest penalties, this structure signals how regulators value AI failures. High-risk category obligations—documentation, human oversight, transparency, logging—represent the compliance surface a monitoring tool must support.
Domestic exposure, though less publicized, is equally significant. A client indemnification claim from an off-label medical ad, a state attorney general inquiry into deceptive AI-generated testimonials, or a class action due to biased lead scoring in a lending campaign may not generate headlines but can damage client relationships and increase insurance premiums. The monitoring tool's value lies not in preventing every incident, but in producing a record that limits liability and expedites investigations when incidents occur.
The pricing question for vendors should be inverted: not "what does the tool cost," but "what does the tool document that would otherwise require manual reconstruction during a client dispute or regulatory inquiry?" If the answer is minimal, the subscription is expensive at any price. If it provides comprehensive records—model versions, approval chains, incident logs, remediation records, and exportable reports—the subscription cost is a fraction of the first incident it helps navigate.
Agencies that price monitoring against potential downside also negotiate differently. Contract terms regarding log retention, data portability, incident response SLAs, and export formats become key leverage points, rather than just seat count.
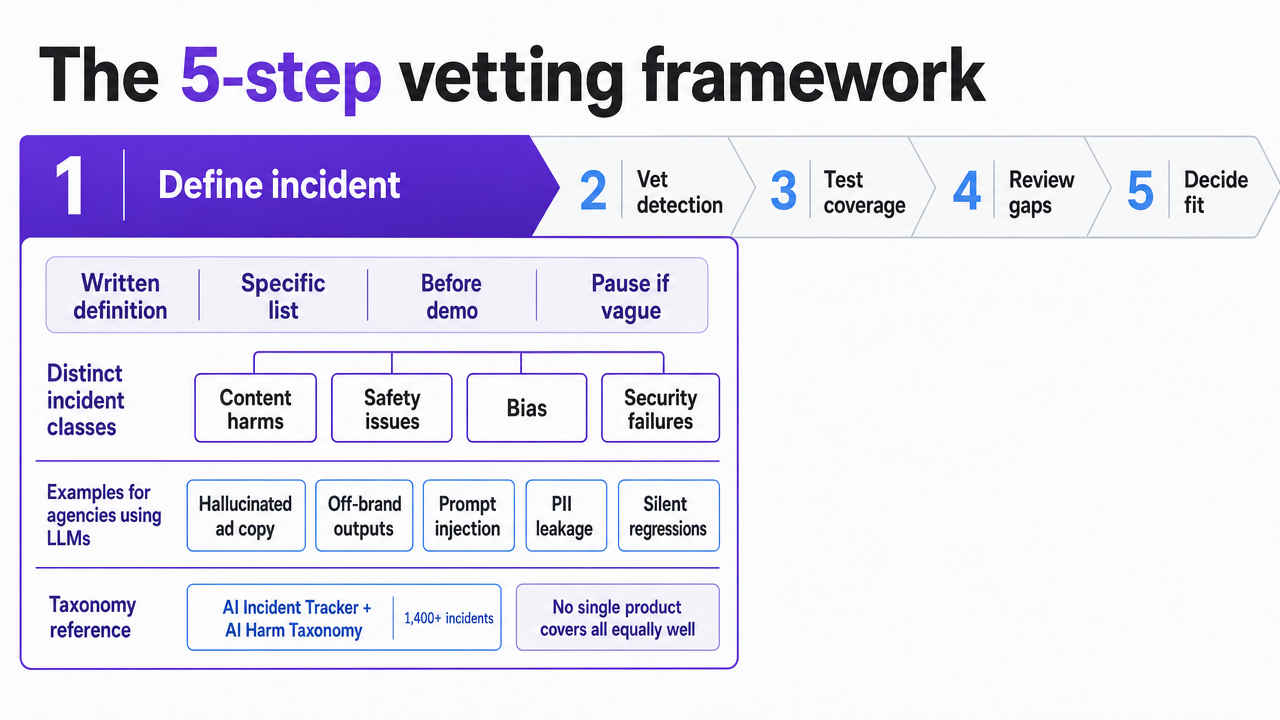 Process infographic visualizing the five-step vetting workflow that structures the entire section, giving readers a scannable overview of the framework
Process infographic visualizing the five-step vetting workflow that structures the entire section, giving readers a scannable overview of the framework
The vendor interrogation checklist
These five steps condense into a practical checklist for vendors to answer in writing before contract signing. This short version can be provided to procurement leads or client security reviewers.
- On incident definition: What is the tool's default incident schema, which categories from CSET's AI Harm Taxonomy does it detect natively 7, and can the schema be extended without vendor engineering? How are human-flagged incidents correlated with model logs?
- On framework coverage: Which of NIST AI RMF's four functions—Govern, Map, Measure, Manage—does the tool support, and where are the gaps 4? Specifically, how is a new model registered, assigned an owner, and tied to a client account under Govern, and what incident response and communication protocols are supported under Manage 5?
- On the model-versus-workflow split: Does the tool log both the model call and the human approval chain in the same system of record, aligning with OCC's continuous monitoring and outcome analysis expectations 1? If two systems are involved, how are they joined at query time?
- On the audit trail: Given a specific published output, can the tool produce the model version, prompt and retrieval context, reviewer identity, approval timestamps, and the human edit diff in a single client-facing report, aligned with NTIA's disclosure standards 9? Can serious incidents be exported to an external body in a structured format 10?
- On downside pricing: What log retention, data portability, incident response SLAs, and export formats are contractually guaranteed?
Written answers to these questions form the basis for the decision, superseding the demo.
See How Leading Agencies Standardize AI Monitoring Tool Selection
Request a walkthrough of proven evaluation frameworks and approval workflows tailored to agencies managing multi-channel AI tools at scale.
What approval-first architecture looks like in practice
Approval-first architecture reverses the typical AI stack assumption. Instead of AI systems executing and monitoring problems post-fact, every recommendation is routed to a human decision point before impacting a client asset. Monitoring becomes a ledger recording what was proposed, approved, rejected, and shipped, in that sequence.
This manifests as a unified command surface where strategist recommendations for content, paid media, SEO, and outreach are queued, along with their reasoning, the model version used, and relevant client context. Sign-off is mandatory before execution. Rejections are logged with the same importance as approvals, as a pattern of rejections can be an early drift signal. Platforms like Vectoron are designed around this pattern, prioritizing the approval workflow as the primary interface, not an afterthought for compliance.
The vetting implication is clear. A monitoring tool assuming AI executes first and is audited later will yield clean dashboards but messy investigations. A tool built on the premise that nothing ships without an approval record produces the essential artifact for all five vetting steps: a defensible chain from prompt to publication, understandable by clients, auditors, or regulators without translation.
 Companies with mature governance for autonomous AI agents
Companies with mature governance for autonomous AI agents
Companies with mature governance for autonomous AI agents
Frequently Asked Questions
References
- 1.Model Risk Management: Revised Guidance.
- 2.The state of AI in 2025: Agents, innovation, and transformation.
- 3.The State of AI in the Enterprise - 2026 AI report | Deloitte US.
- 4.AI Risk Management Framework.
- 5.Manage - AIRC - NIST AI Resource Center.
- 6.AI Incidents: Key Components for a Mandatory Reporting Regime.
- 7.AI Incident Tracker - MIT AI Risk Repository.
- 8.Unpacking the EU AI Act: The Future of AI Governance.
- 9.AI Accountability Policy Report.
- 10.An Argument for Hybrid AI Incident Reporting.