
Key Takeaways
- Baseline each client's GEO performance across ChatGPT, Perplexity, Gemini, and AI Overviews before shortlisting, so vendor demos become acceptance tests against a real query universe.
- Define a three-layer KPI stack covering visibility, content-influence, and CRM outcomes, and reject any metric that cannot connect movement to pipeline in a QBR.
- Audit measurement methodology on citation depth, prompt coverage, semantic alignment, and sentiment, because two tools can report wildly different scores for the same client.
- Segment visibility signals by problem-aware, solution-aware, and branded prompts, and require vendors to show field-level CRM write-back to Salesforce or HubSpot.
- Stress-test portfolio reporting on at least five live accounts across three verticals for 30 days, watching onboarding drag, roll-up views, and reporting flexibility.
- Run net contribution per account per month using fully loaded prompt volumes, because sticker prices at starter tiers rarely survive real portfolio cadence.
- Score finalists on the full loop from signal to briefed rewrite, human approval, publish, and re-measurement, not just the dashboard output.
Why AI search monitoring is a measurement architecture decision
Agency SEO leads are getting the same question from clients this quarter: are we showing up in ChatGPT, and what is it worth? The honest answer is that most existing dashboards cannot say. Traditional rank tracking measures a surface that AI answers are quietly bypassing, and the engagement metrics behind quarterly business reviews were designed for a click-based web that is losing volume to zero-click summaries 4.
That matters because AI search is not a side channel anymore. McKinsey projects generative AI adoption in enterprise SEO and content strategy will rise from 28% in 2024 to 74% by 2028 11. Inside four years, roughly three of every four programs an agency competes against will be running some form of GEO. Tool selection at that point is retroactive; the interesting decision is what gets wired in now.
The framing that fails is the feature checklist. Every vendor demo shows share-of-voice across ChatGPT, Perplexity, Gemini, and Claude. Fewer show how those signals connect to CRM opportunity records, sentiment shifts inside answers, or which pieces of owned content are being cited versus paraphrased away. Forrester's guidance is direct: AI-powered search rewards semantic depth and citation presence, not keyword proxies, and the accountability model has to be rebuilt around that 5, 4.
So the selection question is architectural. Does the tool produce a signal an agency can bind to pipeline, defend in a QBR, and roll up across a client portfolio? Or does it produce another dashboard that no one opens by month three? The seven steps that follow are structured to force that answer before a contract gets signed.
Step 1: Baseline your clients' GEO performance before shortlisting anything
Every vendor conversation gets easier when the agency shows up with a diagnostic already run. Before shortlisting, run a manual baseline across the clients that matter most: their top ten commercial queries, their top five branded queries, and the five queries where a competitor is winning revenue the client should be capturing. Prompt each query in ChatGPT, Perplexity, Gemini, and Google's AI Overviews. Record whether the client is cited, whether the client is mentioned without citation, whether a competitor is cited instead, and what the AI answer actually says about the category.
The scoring exercise usually surfaces the same pattern. Even accounts with strong SEO positions come up thin in AI answers, and the gap is not small. McKinsey's diagnostic of generative engine optimization performance found that even the GEO performance of industry leaders may lag SEO by anywhere from 20 to 50 percent across AI search platforms 11. That gap is the shape of the problem an AI search monitoring tool has to make legible per client, per query set, per platform.
A baseline does three things for the tool selection that follows:
- It sets a defensible starting number a client will remember in month six.
- It exposes which platforms actually matter for that client's buyers, so the agency does not pay for coverage of engines that do not influence pipeline.
- And it produces a query universe the shortlisted tools can be tested against during trials, rather than accepting whatever sample prompts the vendor offers.
Agency leads running 15 or more accounts should build the baseline as a repeatable template, not a one-off audit. Standardize the query taxonomy (branded, category, competitor, problem-aware, solution-aware), the platforms covered, and the scoring rubric. That template becomes the acceptance test every candidate tool has to pass: can it reproduce this diagnostic at scale, refresh it on a defensible cadence, and roll it up across the portfolio without another analyst on payroll?
Skip the baseline and the shortlist becomes a demo popularity contest. Run it, and the conversation with vendors shifts from feature tours to a direct question: show how the platform handles this exact query set, on these platforms, for these three client verticals, and what the reporting output looks like when the account team reviews it.
Step 2: Define GEO KPIs that survive client scrutiny
The tool cannot fix a broken measurement plan. Before evaluating any platform's KPI library, the agency has to decide what it will actually put in front of a client, and what it will refuse to report on. Forrester's 2024 finding sets the stakes: 64% of B2B marketing leaders say they do not trust their organization's marketing measurement 10. Loading another dashboard of share-of-voice percentages into that environment adds noise, not credibility.
The gap looks even wider when paired with a second data point. Only 39% of respondents in McKinsey's 2025 global survey attribute any EBIT impact to AI, and most of those say less than 5% of EBIT is AI-attributable 1. Clients reading industry press know both numbers. A GEO KPI set that reports rising "AI visibility scores" without a defensible link to opportunity value walks straight into that skepticism.
A usable KPI stack for AI search monitoring works in three layers:
- Visibility signal (top layer): citation rate on the client's priority query set, prominence position inside the AI answer (cited first, cited among sources, mentioned without link, absent), share of AI answer versus named competitors, and sentiment of the mention.
- Content-influence (middle layer): which owned URLs are being cited, which are being paraphrased without attribution, and how citation patterns shift when specific pages are rewritten or restructured.
- Outcome (bottom layer): AI-referred sessions where the referrer is identifiable, self-reported "how did you hear about us" fields on demo requests, and opportunity records in the CRM tagged with an AI-influenced source.
The test for each metric is simple. If the client's revenue leader asked what a movement in that number meant for pipeline next quarter, could the account team answer without hedging? Metrics that fail that test come out of the client-facing report and stay in the internal diagnostic. Agency leads who enforce that discipline before tool selection walk into vendor demos with a specification: here are the twelve KPIs the platform must produce, here is how each rolls up across a portfolio, and here is the source system each one has to write back to. Vendors that cannot map to that spec drop off the shortlist.
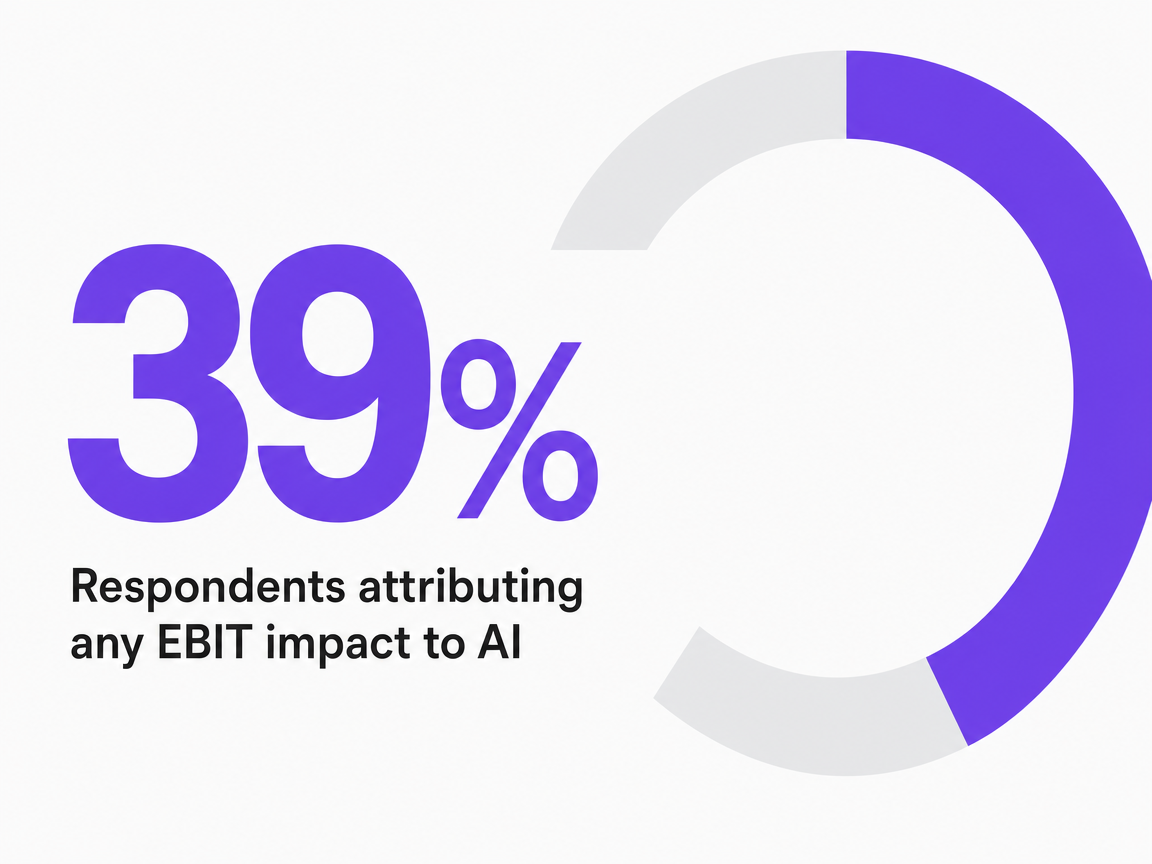 Respondents attributing any EBIT impact to AI
Respondents attributing any EBIT impact to AI
Respondents attributing any EBIT impact to AI
Test AI search monitoring with real data
Validate AI-driven search monitoring ROI on live projects before making a commitment.
Step 3: Audit what the tool actually measures inside AI answers
Most platforms in this category report a single headline number: share of voice across ChatGPT, Perplexity, Gemini, and Claude. That number is nearly useless on its own. Two tools can produce wildly different scores for the same client on the same day because they are measuring different things underneath the label. Before a shortlist gets to pricing, the agency has to open the hood on measurement methodology.
Four dimensions matter:
- Citation depth: is the client cited as a linked source, named in the answer body without a link, referenced through a paraphrase that traces back to owned content, or absent entirely? Each state has a different implication for the content team, and a tool that collapses them into one metric is hiding the signal.
- Prompt coverage: how many prompt variations per query does the platform run, on what refresh cadence, and does it capture the follow-up turns where competitors often surface? A weekly single-shot pull misses the conversational drift where buyers actually make decisions.
- Semantic alignment: Forrester's guidance is that AI search rewards content that answers buyer questions with credible, context-rich, intent-driven answers and appears in sourcing 5. A tool that scores presence but cannot show why the model chose one source over another leaves the content team guessing.
- Sentiment inside the answer itself: being cited alongside a negative framing of the client's category is not a win.
The practical audit is a live test. Feed each finalist the same 25-prompt query set built in the baseline, and ask for the raw output: the exact answer text the AI returned, the sources it cited with URLs, the paraphrase segments matched to owned URLs, the prominence position, and the sentiment classification with the reasoning behind it. Tools that only expose aggregated scores fail the audit. Tools that expose raw answer text and traceable citation logic pass, because that is the substrate an account team needs to explain movement to a client and to brief the content team on what to change next.
Step 4: Map visibility signals to buyer-journey stages and CRM opportunity records
A citation on Perplexity for a problem-aware query is not the same asset as a citation on ChatGPT for a branded comparison prompt. Treating them as one number is where most AI search monitoring implementations quietly fail. The tool has to segment visibility signals by buyer-journey stage, and the account team has to know which stage each signal maps to before the first report goes out.
Start with the prompt taxonomy the baseline already produced:
- Problem-aware prompts (how do I fix X) sit at the top of the journey and drive category framing.
- Solution-aware prompts (best tools for Y, X vs Y) sit in the middle and shape shortlist inclusion.
- Branded prompts (is client X reliable, does client X integrate with Z) sit at the bottom and influence closed-lost narratives.
Forrester's buyer-journey data is unambiguous on why this segmentation matters: 89% of B2B buyers report using generative AI in at least one step of their purchasing process, and the type of prompt used shifts as the deal progresses 2. A tool that reports one blended visibility score across all three stages hides which part of the funnel is actually leaking.
The CRM tie-in is where most platforms in this category stop short. The signal an agency needs is not just "the client was cited on Perplexity this week"—it is which opportunity records touched an AI-influenced session, which self-reported source fields on demo forms show ChatGPT or Perplexity referrals, and how citation prominence on solution-aware prompts correlates with shortlist inclusion in the following 30 to 60 days. That requires the tool to either write back to Salesforce, HubSpot, or the client's CRM through native connectors, or expose a clean API and event schema the agency's analytics team can wire in. Ask the vendor to walk through the exact field-level mapping during the demo. Vendors who cannot show a Salesforce object model or a webhook payload structure are selling a dashboard, not an attribution layer.
The operational takeaway for the shortlist is a three-column requirement doc:
- Column one: the visibility signal (citation rate, prominence, share of answer, sentiment).
- Column two: the journey stage it maps to (problem-aware, solution-aware, branded).
- Column three: the CRM field or opportunity property it has to influence or annotate.
Any candidate tool that cannot fill all three columns for the client's stack drops out of the evaluation before pricing gets discussed.
Step 5: Test portfolio-scale reporting before you sign anything
A tool that works for one client rarely works for forty. The demo environment shows a single hero account with clean data and a curated query set. Portfolio reality is messier: dozens of clients across different verticals, each with their own query taxonomy, competitor set, CRM stack, and reporting cadence. The evaluation has to stress-test the tool against that reality before a contract gets signed.
Three failure modes show up repeatedly:
- Per-account setup drag. If onboarding a new client takes an analyst four hours of query configuration, competitor tagging, and CRM mapping, the platform does not scale past twenty accounts without new headcount. Ask the vendor for a time-to-first-report benchmark on a fresh account, then have a junior analyst attempt it live during the trial.
- The missing roll-up view. Individual client dashboards are table stakes; what agency leads need is a portfolio pane that shows citation-rate movement across all accounts, flags which clients slipped week-over-week, and surfaces the three accounts most at risk of a QBR conversation. If that view does not exist, the head of SEO is manually stitching screenshots.
- Reporting output that does not match how the agency actually delivers. Some clients want a white-labeled PDF, some want a Looker Studio embed, some want raw data pushed to their BI stack. A tool that only exports its own branded dashboard forces the agency to rebuild reports downstream.
Deloitte's guidance on scaling AI across the enterprise applies directly: governance and measurement have to hold together as volume increases, not degrade 7. For an agency, that translates to a concrete trial requirement. Run the finalist against five live client accounts spanning at least three verticals for a minimum of 30 days, and measure onboarding hours per account, refresh reliability, and the number of manual interventions the account team logs. Any tool that cannot survive that test at five accounts will not survive at fifty.
See How Leading Agencies Use AI Search Monitoring Tools to Improve ROI Tracking
Connect with our team to review real-world benchmarks, workflow automations, and approval processes that let agencies monitor search performance across multiple clients at scale—without increasing manual oversight.
Step 6: Run the unit economics per client account
The tool has to pay for itself per account, not in aggregate. That is the distinction most agency evaluations get wrong. A platform quoted at a single enterprise price is easy to rationalize when spread across the whole book of business; the same platform priced per account, per month, against the analyst hours it actually saves, is a much harder conversation. Agency leads who skip this math end up subsidizing tooling out of margin they cannot recover.
The inputs are straightforward:
- Cost side: monthly platform fee per client account, any per-query or per-prompt overage charges, onboarding cost amortized across the expected client tenure, and the integration cost of wiring the tool into each client's CRM.
- Value side: analyst hours saved per account per month on reporting production, hours saved on manual query pulls across ChatGPT, Perplexity, Gemini, and Google AI Overviews, hours reclaimed from stitching screenshots into QBR decks, and the blended internal rate the agency assigns to those hours.
The number that decides the shortlist is net contribution per account per month. If the platform costs $X per account and returns fewer than $X in reclaimed analyst time plus defensible reporting output, the account is losing money on the tool before any client sees a KPI. McKinsey's 2025 finding that only 39% of respondents attribute any EBIT impact to AI is a useful calibration here: agency leads should not assume the tool automatically pays back through client retention or upsell 1. The payback has to be visible in the operating model first, then any revenue lift is upside.
One caveat matters for tools priced on prompt volume. A client with 200 priority queries refreshed weekly across four AI platforms is 41,600 prompt executions a year before follow-up turns. Ask each vendor for a fully-loaded quote at the query cadence the KPI plan actually requires, not the starter tier volume. Sticker prices at 25 queries per week per account rarely survive contact with a real portfolio.
A break-even worksheet for agency leads managing multiple accounts
The worksheet below uses labeled variables so any agency lead can populate it against a specific vendor quote. Only the Vectoron trial price is supplied as a fixed reference point 8.
| Input | Variable | Notes ||---|---|---|| Accounts under management | A | Client accounts receiving AI search monitoring || Monthly platform cost per account | C | Fully loaded, including prompt overages || Analyst hours saved per account per month | H | Reporting, manual pulls, deck assembly || Blended analyst rate | R | Loaded cost per hour, not billable rate || Monthly cost per account | C | Direct expense || Monthly value reclaimed per account | H × R | Labor cost avoided || Net contribution per account | (H × R) − C | Must be positive to justify || Portfolio net contribution | A × [(H × R) − C] | Roll-up view |
One fixed reference: a Vectoron trial runs $599 per month per account after a two-week trial, useful as an anchor when comparing candidate platforms priced at a similar tier. The break-even test is the same regardless of vendor: if H × R is less than C at the client volumes and query cadence the KPI plan requires, the tool cannot survive the operating model.
Step 7: Close the loop from signal to published change
A monitoring tool that stops at reporting is a diagnostic, not a system. The signal has value only if the account team can act on it inside the same operating cadence the client already pays for. That is where most GEO programs stall: the dashboard flags a citation gap on solution-aware prompts, and then a briefing document sits in a queue for three weeks while a writer gets assigned, a legal reviewer weighs in, and a publishing slot opens up.
The seventh step tests whether the tool integrates with production, not just measurement. Three connections matter:
- The monitoring output has to route into a content backlog with the specific gap named at the URL level: which page is being paraphrased without attribution, which competing source is being cited instead, what semantic angle the AI answer prefers. Forrester's guidance on intent-driven content is that structural, contextual alignment is what AI search rewards, and the brief has to carry that specificity or the rewrite misses 6.
- The workflow has to preserve human approval before anything ships. Deloitte's scaling guidance points to governance holding as volume increases, and for agency work that means a named reviewer signs off on every change before publish, with the reasoning captured against the opportunity record 7.
- The tool has to close the measurement loop after the change goes live: re-run the affected query set on a defined cadence, log the citation shift, and write the delta back to the KPI stack the account team already reports on.
Agency leads should score finalists on that full loop, not just the dashboard. A candidate that surfaces a citation gap but cannot generate a briefed rewrite, route it through approval, publish the change, and re-measure the outcome is asking the account team to rebuild the connective tissue by hand across every client. That is the quiet cost that erases the margin calculated in the prior step. Platforms like Vectoron that pair monitoring with an approval-first execution layer are worth testing against pure-dashboard tools on exactly this criterion: how many hours of manual handoff disappear between the signal firing and the published change getting re-measured.
A candidate list, evaluated against the seven steps
The category is crowded and consolidating fast. Rather than rank platforms, the more useful exercise is scoring the current field against the seven-step framework: baseline capability, KPI depth, measurement methodology, journey mapping, portfolio reporting, unit economics, and closed-loop execution.
Profound, Peec AI, and Otterly.AI sit closest to the pure-monitoring end. They report citation presence, share of AI answer, and prompt-level tracking across ChatGPT, Perplexity, Gemini, and Google AI Overviews. Strong on steps one through three. Thinner on CRM write-back and portfolio roll-ups when account counts push past twenty. Athena and Scrunch AI extend into sentiment classification and competitor benchmarking with better semantic traceability, which matters for the step-three audit but still leaves the production handoff manual.
Ahrefs Brand Radar and Semrush AI Toolkit bolt AI visibility onto existing SEO stacks. The advantage is portfolio-level familiarity for agency teams already standardized on those platforms; the constraint is that CRM attribution remains the agency's problem to solve downstream. HubSpot's AI Search Grader offers a free entry point for baseline diagnostics but stops well short of a portfolio-grade system.
Vectoron sits in a different column. It pairs monitoring signals with an approval-first execution layer, so a citation gap on solution-aware prompts routes directly into a briefed rewrite, through a named reviewer, into publish, and back into the KPI stack for re-measurement. That closes step seven in one workflow rather than three vendors 7. For agency leads scoring against the full framework, the honest read is that no single platform passes every step cleanly yet. The selection question is which gaps the agency can absorb internally, and which ones would quietly erase the margin math from the prior step.
 B2B buyers using generative AI in their purchasing process
B2B buyers using generative AI in their purchasing process
B2B buyers using generative AI in their purchasing process
 B2B buyers who say genAI helps create better business outcomes
B2B buyers who say genAI helps create better business outcomes
B2B buyers who say genAI helps create better business outcomes
Frequently Asked Questions
References
- 1.The State of AI: Global Survey 2025.
- 2.The Future Of B2B Buying Will Come Slowly And Then All At Once.
- 3.AI Will Shape the Future of Marketing.
- 4.AI Search Will Crack The Foundation Of B2B Marketing's Accountability Model.
- 5.Impact And Opportunity For AI-Powered Search In B2B Marketing.
- 6.Shifting Search Behaviors Demand Smarter Content Strategies.
- 7.The State of AI in the Enterprise.
- 8.Gen AI's ROI.
- 9.The state of AI in 2023: Generative AI's breakout year.
- 10.B2B Marketing Leaders Don't Trust Their Measurement.
- 11.Winning in the age of AI search.