
Key Takeaways
- Conductor-class enterprise AEO platforms deliver the deepest engine coverage and prompt segmentation for regulated verticals, but their fixed panel cost only pencils out when the largest accounts individually justify enterprise pricing 9.
- AI Monitor-class specialists occupy the middle layers of the visibility stack, exposing citation share of voice, source URL inclusion, and sentiment at the raw response level with elastic prompt panels across a book 5, 13.
- SE Ranking-class convergence tools bolt AI Overview and conversational assistant monitoring onto existing rank tracker contracts, giving directional coverage for mid-market accounts that cannot fund a separate specialist AEO subscription 17, 18.
- Zapier-class lightweight alerting tools flag competitor movement and negative sentiment on compact prompt panels, working best as triage into deeper specialist platforms rather than as a standalone measurement layer 15.
- Vectoron-class execution layers close the loop between visibility signals and shipped change through an approval-first workflow, removing the analyst-to-writer-to-developer relay that turns two-hour findings into two-week tickets 5, 20.
Why AI Visibility Became Its Own Line Item on the Agency Stack
Rank tracking no longer measures where discovery actually happens. Citation share of voice, source URL inclusion, and sentiment inside ChatGPT, Perplexity, Google AI Overviews, and Gemini now form a distinct measurement layer that traditional SERP tools miss entirely 13. Agency SEO leads who treat this as a bolt-on report inside the existing rank tracker are not measuring the same thing their clients are being asked about in QBRs.
The adoption curve makes the timing question straightforward. Enterprise adoption of AI visibility management tools stood at 18% in 2024 and is projected to reach 65% by 2027, a 54.3% CAGR across the category 18. This indicates a critical window for agencies to integrate AI visibility or risk absorbing costs through unbilled analyst hours.
The category is real because the KPIs are different. AI models reward semantic relevance, structured data, entity authority, and content freshness in ways that rank position does not capture 11, 12. A page can hold position three organically and be absent from every AI Overview and Perplexity citation for the same query set. Separating GEO reporting from traditional SEO reporting, and tracking AI referrers like chat.openai.com, perplexity.ai, and gemini.google.com as their own traffic class, is now standard client-deliverable practice 10.
The five tools that follow are evaluated on portfolio scalability, engine coverage, and execution integration, not feature count.
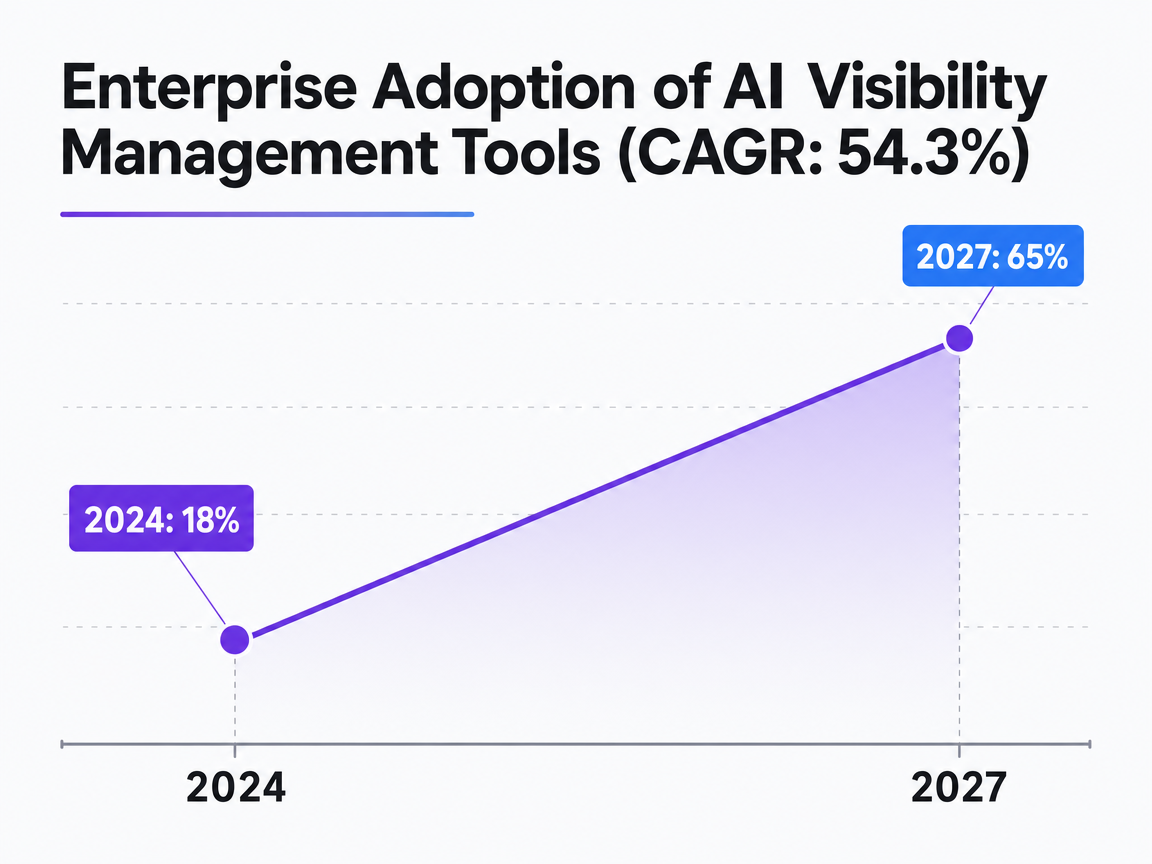 Enterprise Adoption of AI Visibility Management Tools (CAGR: 54.3%)
Enterprise Adoption of AI Visibility Management Tools (CAGR: 54.3%)
Source: Rankability: 22 Best AI Search Rank Tracking & Visibility Tools for 2026
The Portfolio-Scaling Decision Model: Four Criteria That Actually Matter
Engine Coverage Across ChatGPT, Perplexity, Gemini, and AI Overviews
Engine coverage is the first disqualifier. A platform that only samples ChatGPT is measuring roughly one seat at the table. Agency-viable tools now track citation behavior across ChatGPT, Perplexity, Google AI Overviews, and Gemini as a minimum set, with several also monitoring Google AI Mode as it expands 13, 14.
Coverage is not binary. Each engine exposes different citation mechanics: Perplexity surfaces source URLs prominently, AI Overviews blend summaries with a curated link set, and ChatGPT and Gemini vary citation density by query type and browsing mode. Tools that normalize these differences into a single share-of-voice figure without exposing the underlying per-engine data will produce reports that clients cannot act on 19.
For agency portfolios, the practical test is whether the vendor runs prompts against each engine on a fixed cadence and stores raw responses, not just parsed metrics. That raw layer is what allows an analyst to answer the QBR question of why a client dropped out of Perplexity citations for a specific query cluster while holding steady in AI Overviews.
Citation Share of Voice, Source URL Inclusion, and Sentiment Depth
Three metrics define the measurement layer: citation share of voice, source URL inclusion, and sentiment 13. Each answers a distinct client question, and tools that collapse them into a single composite score obscure the diagnostic value.
Citation share of voice quantifies how often a brand is named across a defined prompt panel, benchmarked against competitors in the same set. Source URL inclusion tracks which specific pages the models are pulling from, which is the signal that closes the loop back to content and technical SEO decisions 15. Sentiment measures the tone in which the brand is described, flagging cases where visibility exists but the framing is unfavorable or off-positioning.
Sentiment depth matters more than it first appears. A dental group with 90% citation share for local implant queries but a persistent negative sentiment tag on one procedure is a different client problem than a low-citation account. Tools that only surface presence, without describing how the model characterizes the brand, force analysts to re-read raw outputs manually. That does not scale past a handful of clients 15, 21.
Multi-Client Reporting and Prompt Panel Economics
Prompt panels are the unit of cost in this category. A panel is the fixed set of queries a tool runs against each engine on a schedule, and pricing scales with panel size, engines monitored, and refresh frequency rather than with seat count 14.
For a twenty-client book, panel economics decide whether AI visibility is a margin-positive line item or a hidden loss. A boutique law firm needs a smaller panel than a multi-market DSO, and a tool that only sells uniform bundles forces the agency to either overpay for small accounts or underserve large ones. Vendors that allow per-client panel sizing and tiered refresh cadence keep the math workable 6, 17.
Reporting matters equally. White-label exports, per-client dashboards, and API access to the raw citation and sentiment data are the difference between a tool that produces client reports and one that produces analyst homework.
Execution Integration: The Gap Between Signal and Shipped Change
The fourth criterion is where most stacks quietly leak margin. A visibility platform can flag that a client has lost source URL inclusion for a high-value prompt cluster, and that finding will sit in a dashboard until an analyst briefs a writer, a writer drafts a revision, an editor reviews it, and a developer ships the schema update. Each handoff is a billable hour that the visibility report itself did not fund 5.
Execution integration is the degree to which findings can be routed into production without leaving the governed workflow. Some monitoring tools expose webhooks and API endpoints that feed content and technical SEO systems directly. Others produce PDF reports and stop there 17, 20.
The distinction matters for portfolio math. Monitoring-only platforms add a line item without removing any. Platforms with execution integration, or execution layers that consume monitoring signals through an approval workflow, are the only path to net-positive stack consolidation. Agencies that skip this criterion end up paying twice: once for the signal, again for the labor to act on it.
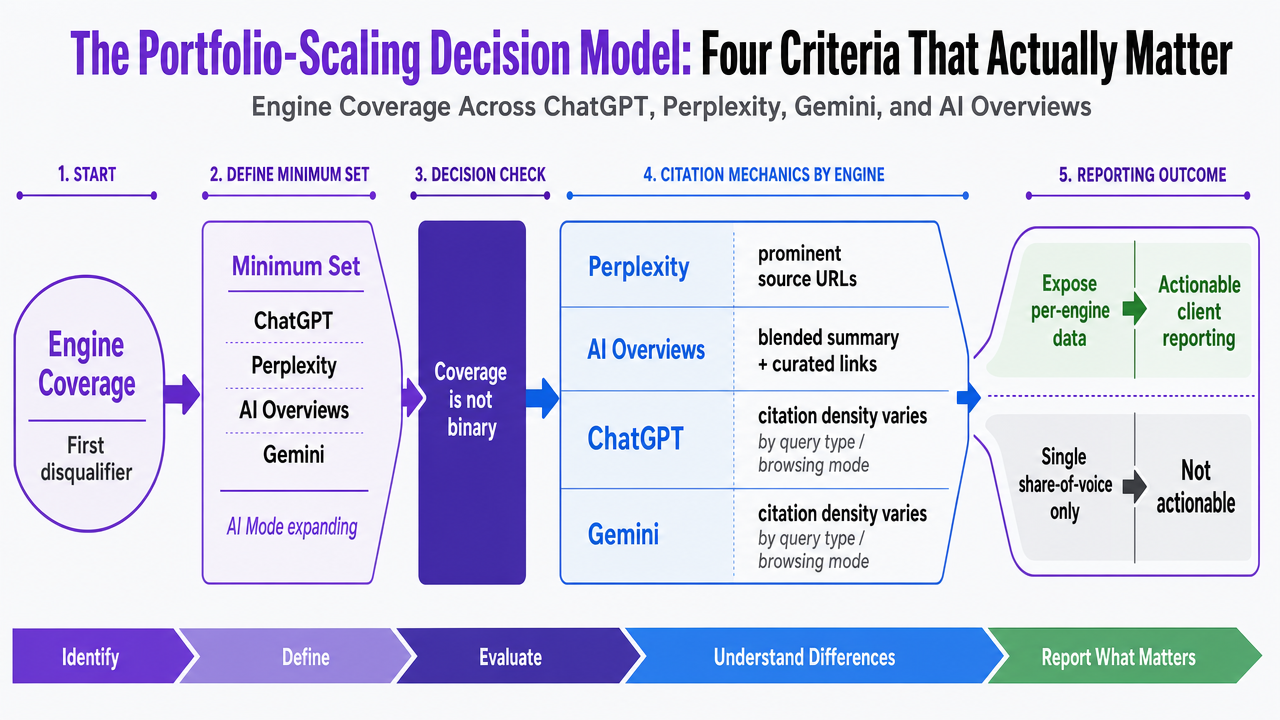 Process infographic visualizing the four decision criteria as a framework for evaluating AI visibility tools
Process infographic visualizing the four decision criteria as a framework for evaluating AI visibility tools
Test AI-powered SEO workflows with real campaigns
Experience hands-on execution and measurable impact with live content publishing during your trial period.
The Five-Tool Shortlist: How the Stack Maps to the Decision Model
Conductor-Class Enterprise AEO Platform: Depth Across Every AI Surface
The enterprise AEO tier sits at the top of the shortlist because it is the only class that treats AI answer engines as a first-class surface rather than a module bolted onto a legacy suite. Conductor is positioned as an enterprise AEO platform built to maximize brand visibility across ChatGPT, Perplexity, and Google AIO, with the depth agencies need for regulated verticals and large prompt panels 9.
What agency leads get in exchange for the price tag is engine coverage without normalization tricks, prompt libraries that can be segmented per client and per market, and citation analytics that separate presence from favorability. For a portfolio containing a national law firm, a hospital system, and a multi-brand DSO holding company, that separation is not a luxury. It is the difference between reporting share of voice as one blended number and diagnosing why one brand under a shared parent is being cited approvingly while another shows up alongside competitor comparisons.
The tradeoff is stack weight. Enterprise AEO platforms consolidate monitoring but do not close the execution loop 9. Findings still route into content and technical workflows through analyst hands or through API pipes an agency has to build. For a book that already justifies enterprise pricing on the largest three accounts, that math works. For a twenty-client book with a long tail of mid-market accounts, the fixed cost per prompt panel is where agencies quietly overpay.
AI Monitor-Class Specialist: Prompt Coverage and Citation Tracking at Portfolio Scale
The specialist tier is where most agency portfolios actually land. Bertelsmann Tech recommends that brands monitor how often they appear in AI-generated responses using specialized tools like AI Monitor, framing this as a distinct discipline from rank tracking 5. That framing matches how the class scales: broad prompt libraries, per-engine citation logs, and sentiment scoring exposed at the raw response level so analysts can build client-specific narratives.
The four-layer AI visibility stack clarifies why this class earns a dedicated slot:
- Engine coverage sits at the base
- Citation and sentiment measurement above it
- Prompt and entity panels one layer up
- The execution and approval loop at the top 13
Enterprise AEO platforms occupy the top three layers with heavy tooling; AI Monitor-class specialists concentrate on the middle two, where citation share of voice, source URL inclusion, and sentiment become measurable, exportable metrics 13.
For agency SEO leads, the practical draw is prompt panel elasticity. A specialist tool that lets one analyst run 200 prompts for a home services client and 2,000 for a multi-state healthcare group, on the same contract, keeps portfolio economics defensible. The class does not solve execution, but it produces the raw signal quality that an execution layer downstream can actually consume.
SE Ranking-Class Convergence: When the Rank Tracker Already on Contract Grows an AI Module
The convergence tier is the pragmatic option for agencies that already pay for rank tracking across a client book and want to avoid a net-new vendor contract. SE Ranking has expanded from traditional rank tracking into AI search visibility, monitoring Google AI Overviews, AI modes, and conversational assistants alongside organic SERPs 18. Other enterprise SEO suites have followed the same trajectory, layering AI search monitoring onto existing technical and content modules 17.
The appeal is line-item consolidation. One contract, one seat structure, one reporting surface. For agencies running twelve-month renewals with mid-market clients who will not fund a specialist AEO subscription on top of their existing SEO retainer, the convergence tier is often the only version of AI visibility that clears budget approval.
The limitation is depth. Rank-tracker-native AI modules tend to report presence and basic citation counts across engines, without the sentiment granularity or prompt panel flexibility that specialist tools expose 18. Mixing rank and AI visibility metrics inside the same dashboard also risks stakeholder confusion if the differences are not clearly labeled 18. For a portfolio where three accounts need forensic AI visibility diagnostics and the rest need directional reporting, pairing a convergence tool with a specialist license on the top accounts is the working configuration.
Zapier-Class Competitor and Sentiment Flagging: The Lightweight Alerting Layer
The lightweight tier answers a narrower question: when did something change, and against whom. Zapier's roundup describes this class as tools that track where and how brands appear in AI responses, flag negative sentiment, and spot when competitors start gaining visibility 15. That is an alerting posture, not a full measurement platform, and it belongs in the stack for exactly that reason.
Agency use case: a boutique law firm client with a defined competitive set of four peer firms in one metro. A full enterprise AEO deployment is overkill; a specialist AI monitor is closer to the right shape but still heavy for the account size. A lightweight alerting tool that runs a compact prompt panel weekly and pings the account lead when a competitor gains citation share or when sentiment turns adversarial is what actually gets used 15.
The class also functions as a triage layer for larger portfolios. Alerts from a lightweight tool can trigger deeper investigation inside a specialist platform, keeping analyst time focused on accounts where something has actually moved. Used alone, the class underreports; used as a top-of-funnel signal into the rest of the stack, it prevents the twenty-tab manual review that eats junior analyst hours.
Vectoron-Class Execution Layer: Closing the Loop From Signal to Approved Change
The fifth slot is the one most 2026 listicles miss. Monitoring tells the agency what shifted in AI answer engines. It does not draft the revised page, update the schema, ship the change, or track whether the citation and sentiment metrics moved in response. That work is where agency margin leaks, and it is what an execution layer is built to consume.
The class sits at the top of the four-layer stack: an approval-first workflow that ingests visibility signals from the monitoring tiers and routes prioritized, reasoned recommendations into content and technical production, with human sign-off before anything ships. AI models reward semantic relevance, structured data, entity authority, and content freshness 11, 12. An execution layer operationalizes those levers as ranked work items tied to the specific prompts, engines, and citation losses that surfaced upstream.
For a Head of SEO managing delivery across a client book, the economics change in one direction. Monitoring adds a line item. Execution consolidation removes the analyst-to-writer-to-editor-to-developer relay that turns a two-hour finding into a two-week ticket. Vectoron is one instance of this class, described here generically as an AI marketing execution platform with specialist strategists and an approval-first workflow that connects monitoring signal to shipped change without adding headcount 5, 20. Agencies that treat the execution layer as optional keep paying twice, once for the dashboard, again for the labor to act on it.
What These Tools Do Not Do
The gap between what AI visibility platforms measure and what actually moves the metrics they measure is the honest limitation of the category. Even the best-instrumented monitoring stack will not draft the FAQ block that closes a source URL inclusion gap in Perplexity, will not update the Organization schema that fixes an entity resolution problem in AI Overviews, and will not republish the outdated pricing page that ChatGPT keeps citing with stale figures.
Three shipped-change functions sit outside every monitoring tool reviewed here:
- Content revision at the specificity AI models reward: semantic relevance, structured content with clear intent alignment, and factual accuracy at the paragraph level 11.
- Technical implementation of the schema, structured data, and machine-readable formatting that determines whether models can parse a page correctly 12.
- Freshness maintenance, since models favor frequently updated pages, and dashboards do not update pages 12.
Proprietary AEO scores compound the problem. Different vendors calculate citation frequency differently, which makes cross-tool benchmarking unreliable and can obscure whether shipped changes actually improved the underlying signal 21. The practical response is to treat monitoring as diagnostic input, not as the work itself, and to budget the execution layer as a separate line rather than assuming the dashboard delivers it.
See How Leading Agencies Automate Search Visibility at Scale
Connect with our team to review AI-powered workflows that centralize search visibility management, streamline approvals, and maintain quality across multiple client accounts—without increasing headcount.
If You Manage Multi-Location Portfolios: Where the Stack Consolidates or Bloats
The Multi-Location Prompt Panel Problem
For agency leads managing multi-location service portfolios, prompt panel math changes shape. A single-location law firm needs one panel of branded and unbranded queries. A 40-location DSO needs a panel that expresses each market's competitive set, each service line's local variations, and each location's citation footprint across ChatGPT, Perplexity, Google AI Overviews, and Gemini. Panels multiply, not by client count, but by market count inside each client.
The category spend confirms where this is heading. Annual investment in AI-powered SEO and visibility software by DSOs and multi-location health groups is projected to grow from $0.45B in 2024 to $2.1B in 2028, a 46.8% CAGR 16. That capital is not funding uniform monitoring bundles. It is funding vendors that can size prompt panels per market and expose per-location citation and sentiment data without collapsing everything into a single parent-brand score.
The operational trap is buying a flat-rate visibility platform designed for single-brand enterprises and applying it to a portfolio where one client alone spans 30 markets. Panel elasticity, per-market reporting, and tiered refresh cadence are the three configuration levers that decide whether the tool scales with the book or forces uniform overpayment.
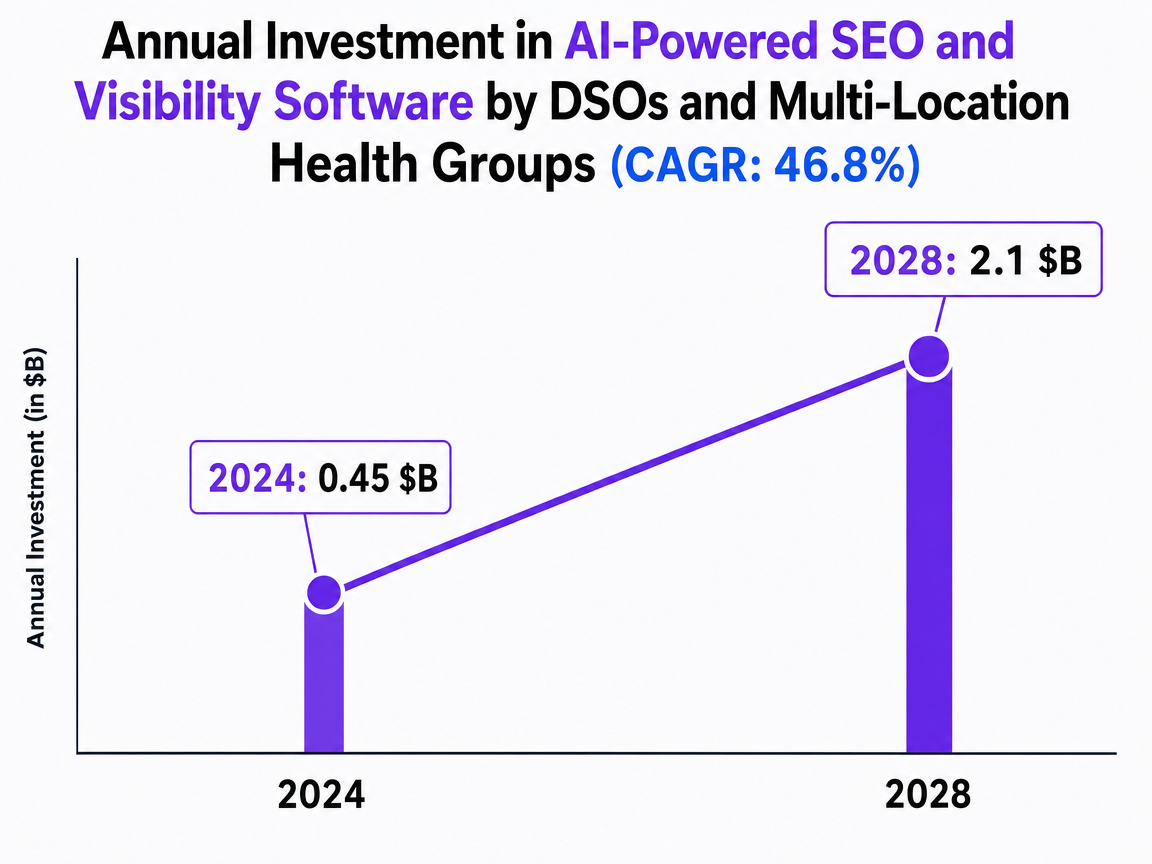 Annual Investment in AI-Powered SEO and Visibility Software by DSOs and Multi-Location Health Groups (CAGR: 46.8%)
Annual Investment in AI-Powered SEO and Visibility Software by DSOs and Multi-Location Health Groups (CAGR: 46.8%)
Source: Yotpo: Best AI SEO Tools 2026: Master Generative Search
Line-Item Comparison: Where AI Visibility Adds a Row and Where Execution Removes Two
The stack question for a multi-location portfolio is not whether AI visibility earns a line item. It does. The question is which adjacent line items compress once monitoring signal routes into a governed execution workflow rather than into analyst tickets.
The table below maps a mid-size agency stack against the four criteria established earlier. Dollar figures are named as variables where the supplied research does not fix them; the only anchored price point is Vectoron's post-trial rate 5, 16, 17.
| Stack Line Item | Monitoring-Only Configuration | Monitoring + Execution Layer Configuration |
|---|---|---|
| Rank tracker (existing contract) | Retained at current seat cost | Retained; AI module deprecated where specialist tool covers it |
| Specialist AI visibility monitor | Added: prompt panel size × engines × refresh cadence | Added at same variable cost; feeds signal into execution layer via API |
| Content production capacity | Analyst briefs + writer + editor per finding | Consolidated into approval-first workflow with strategist-generated drafts 5 |
| Technical/schema execution | Developer ticket queue, weeks of latency | Routed as ranked work items with reasoned recommendations, human sign-off before ship 20 |
| Reporting/QA | Manual export, per-client dashboards assembled by analyst | White-label reporting layered on unified signal + shipped-change log |
| Anchor pricing reference | Sum of five separate vendor contracts | Execution layer at $599/mo post-trial replaces analyst-to-developer relay costs |
The pattern is consistent across portfolio sizes. Monitoring-only stacks add one row and leave the analyst labor untouched. Execution consolidation removes two to three rows of coordination cost by compressing the brief-to-ship cycle into one governed loop. Agency leads who benchmark stack decisions on total delivered change per client, rather than on tool subscription totals, find the second configuration is the only one that keeps portfolio margin positive as prompt panels grow with the DSO and multi-market investment curve 16.
Sequencing the Stack: What to Buy First, What to Deprecate
Sequencing beats shopping. Agencies that buy all four monitoring tiers before deciding what execution work the signals will feed end up with overlapping dashboards and no compression in analyst hours.
The working order:
- Start with a specialist AI monitor as the measurement backbone, sized to the largest three accounts on the book. Citation share of voice, source URL inclusion, and sentiment across ChatGPT, Perplexity, Gemini, and Google AI Overviews become the reporting layer clients see 13.
- Add the execution layer that consumes those signals through an approval-first workflow, so findings route into ranked content and schema work rather than into analyst tickets 5, 20.
- Retain the existing rank tracker but deprecate any AI module inside it that duplicates the specialist tool's engine coverage 18.
- Add lightweight alerting only for accounts too small to justify a full prompt panel, using it as triage into the specialist platform 15.
- Enterprise AEO platforms enter the stack last, and only when three or more accounts individually justify the fixed cost 9.
Vectoron occupies the execution slot in this sequence. Everything else is diagnostic.
Frequently Asked Questions
References
- 1.8 SGE SEO Tips for Google's Search Generative Experience.
- 2.Google's Search Generative Experience (SGE) Rollout, Impact and Strategic Recommendations.
- 3.Complete Guide to Google's Search Generative Experience (SGE).
- 4.How Google's Search-Generative Experience Will Affect SEO.
- 5.SEO and SEM Actionable Strategies for Generative AI Search in 2025.
- 6.10 Best AI Visibility Tools for 2026 (Ranked and Reviewed).
- 7.9 Best AI Visibility Tools Compared for 2026.
- 8.13 Best AI Visibility Tracking Tool In 2026.
- 9.The 10 Best AI Visibility Tools for 2026.
- 10.Generative search optimization in 2025: What the data says and what smart brands are doing about it.
- 11.Beyond SEO: The Complete Guide to Generative Engine Optimization (GEO) and AI Search Visibility in 2025.
- 12.AI Search is Changing SEO: Generative Engine Optimization in 2025.
- 13.AI Search Visibility in 2026: The Complete Guide.
- 14.Best AI Visibility Tools: Complete Guide for SEO Professionals.
- 15.The 8 best AI visibility tools in 2026.
- 16.Best AI SEO Tools 2026: Master Generative Search.
- 17.The 12 Best Enterprise SEO Tools for Scaling Visibility in 2026.
- 18.22 Best AI Search Rank Tracking & Visibility Tools for 2026.
- 19.How do you rank in AI? Top AI Visibility Tools Overview.
- 20.Top AI SEO Tools for Content Optimization in 2026.
- 21.9 AI Visibility Optimization Platforms Ranked by AEO Score (2026).