
Key Takeaways
- Profound delivers deep prompt-level citation tracking and versioned prompt libraries, but stops at reporting, leaving briefs, schema fixes, and internal-link work for downstream teams to ship.
- Peec AI parses how a brand is described inside answers and benchmarks competitors at the prompt level, sharpening sentiment and gap analysis without solving the shipping bottleneck.
- The Semrush AI Visibility Toolkit wins on stack consolidation and zero training friction, but lags AI-natives on sentiment nuance and prompt-level competitive-gap analysis.
- BrightEdge and seoClarity bring enterprise-grade AI Overview monitoring and scale, yet quarterly release cadences and enterprise pricing pressure agility on mid-market accounts 1.
- Sight.ai and Riff Analytics specialize in citation forensics, source attribution, and cross-engine divergence, best suited to B2B agencies where citation quality outweighs coverage breadth.
- An approval-first execution layer routes measurement signals into ranked, human-approved briefs and schema patches, closing the reporting-to-shipping gap the other five categories leave open 17.
The measurement-to-execution gap agencies keep hitting
Six-in-ten U.S. adults now say they read AI search engine summaries, and about four-in-ten use chatbots for information searching 11. That has moved AI visibility out of the experimental column and into the same P&L conversation as organic rankings. What has not moved is the agency operating model built to serve it.
Cross-platform benchmarking of enterprise AI SEO tools shows why single-engine tracking is a dead end: ChatGPT concentrates roughly 78% of AI referral traffic, yet only about 25% of the sources cited across ChatGPT, Perplexity, Google AI Overviews, Gemini, Copilot, and Claude overlap 1. A brand can dominate one engine and be invisible in the next, and the delta rarely surfaces in a suite that treats AI Overviews as a bolt-on widget.
The harder problem is not measurement. Profound, Peec AI, Sight.ai, and the AI modules inside Semrush, BrightEdge, and seoClarity all produce credible visibility data 1, 6. The gap is what happens next. A Head of SEO running 40 accounts does not need another dashboard reading citation share; they need those signals routed into content briefs, schema fixes, and internal-link work that ships this sprint, not next quarter. Forrester makes the same point in operator terms, arguing that reporting should shift from traffic and average position toward share of search and answer-engine saturation 17. Tools that measure without closing that loop widen cost-to-serve. The six evaluated below are graded on whether they close it.
The agency-grade scoring rubric behind this shortlist
A tool that reports well is not the same as a tool that scales delivery. The rubric below scores each platform against the five criteria that actually determine cost-to-serve inside an agency running dozens of accounts.
- Multi-engine coverage. The tool must query and normalize responses across ChatGPT, Perplexity, Google AI Overviews, Gemini, Copilot, and Claude, not sample one and infer the rest. Enterprise reviews confirm that the leading platforms already monitor brand presence across all six systems and analyze sentiment, citation accuracy, and competitive positioning 1.
- Citation quality, not just frequency. Mention counts are easy to game and easy to misread. Only one-in-five U.S. adults find AI summaries extremely or very useful, so the citation surrounding a brand mention carries more weight than the raw count 12. The rubric weights how a brand is described, whether the cited passage is accurate, and whether the source URL actually resolves to the client's domain.
- Sentiment and competitive gap. Agencies reporting to CMOs need to show not only where the client appears, but how it is characterized versus named competitors in the same answer.
- Workflow-to-execution handoff. This is where most tools stop and most agencies bleed hours. A signal is only useful if it becomes a brief, a schema patch, or an internal-link edit that ships. Forrester's guidance to shift reporting from traffic and average position toward share of search and answer-engine saturation only pays off when those metrics drive production work 17.
- Multi-tenant agency fit. Per-seat pricing that scales linearly with account count breaks agency margins. The rubric rewards workspace isolation, roll-up reporting, and role-based approval routing.
The five-signal model behind these criteria—mention frequency, citation share, position, sentiment, and competitive gap—maps directly to Forrester's saturation framing and sets the reporting floor every tool below is graded against 17.
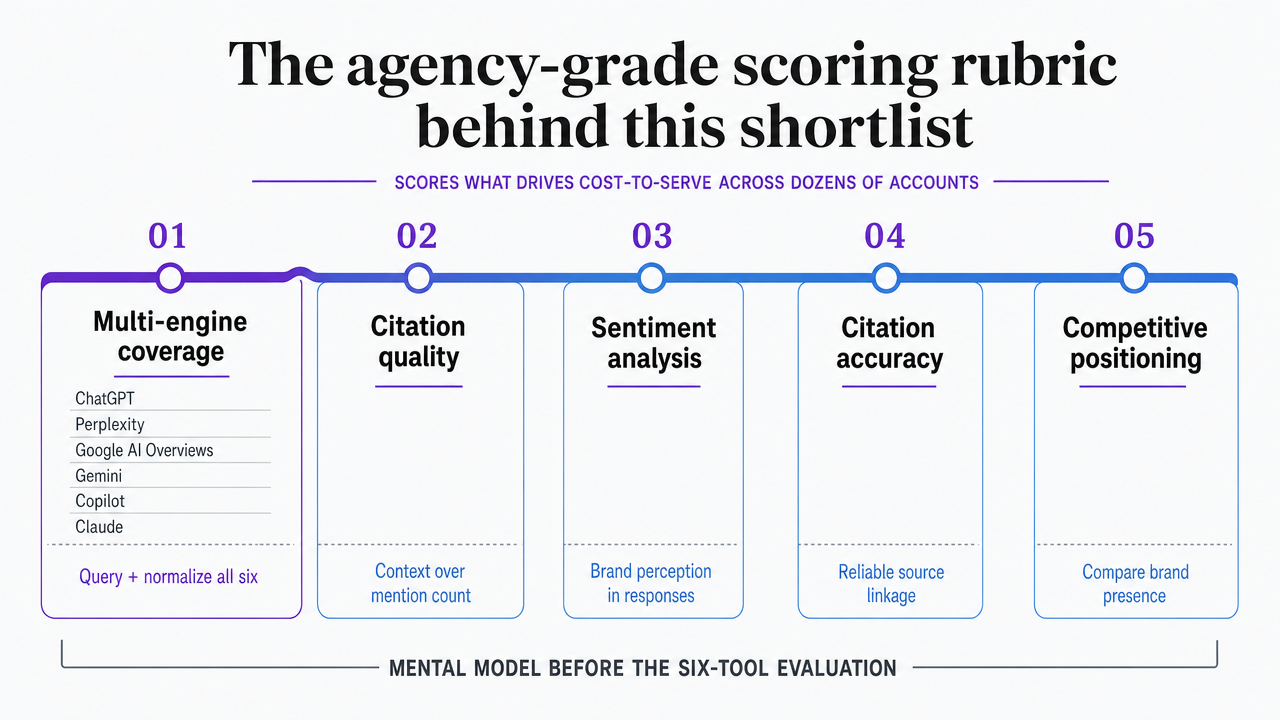 Visualize the five scoring criteria that structure the entire tool evaluation, giving readers a mental model before they encounter the six tools
Visualize the five scoring criteria that structure the entire tool evaluation, giving readers a mental model before they encounter the six tools
Test AI-driven SEO workflows with real campaigns
Publish live SEO-optimized content and measure performance impact over seven days, risk-free.
Six tools, three categories, one honest read
Profound: prompt-level citation tracking for the reporting layer
Profound sits in the pure measurement category alongside Peec AI, and its center of gravity is prompt-level citation tracking. The platform queries generative engines directly, captures how brands are recommended in AI-generated answers, and prioritizes competitor advantages inside those responses 6. For a Head of SEO who needs to show a client where Perplexity is citing a rival's whitepaper instead of theirs, that granularity is the point.
Where Profound earns its place on an agency shortlist is prompt library management. Building and maintaining a prompt library is the operational discipline that makes citation data reproducible across reporting cycles, and it aligns with the AEO practice of generating, organizing, and refining prompts so AI models can cite content consistently 9. Profound treats prompts as first-class assets, which matters when a single account needs 200 tracked queries and a portfolio of 40 accounts needs versioned libraries per vertical.
The honest limitation: Profound reports, it does not ship. A citation gap surfaced on Tuesday still needs a content strategist to write the answer block, a technical lead to add QAPage schema, and an editor to route it for approval. Against the rubric, Profound scores high on multi-engine coverage and citation quality, moderate on sentiment, low on workflow-to-execution handoff, and moderate on multi-tenant fit depending on workspace configuration. Agencies buying Profound are buying reporting depth, not delivery leverage, and the cost-to-serve math has to be run with that boundary in mind.
Peec AI: fastest iteration on sentiment and competitive gap
Peec AI is the newer arrival in the measurement category and has moved fastest on the two signals most agencies underweight: sentiment and competitive gap. Reviews of the current AI visibility landscape group Peec with Profound and the Semrush AI Visibility Toolkit as the three most-cited tools, noting Peec's specialization in tracking where and how brands are recommended across generative search platforms 6.
Two capabilities carry the weight. First, Peec parses how a brand is described inside an answer, not only whether it appears—so an agency can show a client that Gemini is citing them accurately in three prompts and mischaracterizing them in seven. That distinction matters because only one-in-five U.S. adults find AI summaries extremely or very useful, meaning the quality of the surrounding language shapes trust more than raw citation counts 12. Second, Peec's competitor benchmarking runs at the prompt level, so a Head of SEO can rank exactly which named competitors are winning which answer slots.
Rubric read: high on sentiment and competitive gap, high on multi-engine coverage, moderate on citation quality forensics, and low on workflow-to-execution. Peec produces the sharpest picture of representation, but the picture still has to be handed to a content team to act on. Agencies pairing Peec with a downstream execution layer get the strongest reporting-to-delivery pipeline of the measurement-only tools. Agencies using Peec in isolation get better slides and the same shipping bottleneck.
Semrush AI Visibility Toolkit: the incumbent extension play
The Semrush AI Visibility Toolkit represents the suite-with-AI-module category and answers a specific agency question: can the platform already installed on every analyst's desktop absorb AI search work without a second license? Semrush has evolved from pure SEO tracking into what current reviews call a comprehensive AI search monitoring solution, benchmarking brand appearances in AI-generated answers alongside its keyword and backlink data 6.
The advantage is integration friction, or the lack of it. A Head of SEO does not have to train 12 analysts on a new interface, negotiate a new procurement cycle, or reconcile two sources of truth in client reports. Traditional keyword rankings, backlink profiles, and AI citation data sit in one workspace, which matters when reporting to a CMO who wants a single narrative across search surfaces.
The trade-off is depth. Purpose-built tools like Profound and Peec iterate on prompt libraries, sentiment parsing, and citation forensics faster than any suite can, because those are their entire product. Semrush's toolkit is credible for tracking mention frequency and citation share across the major engines, but sentiment nuance and competitive-gap analysis lag the AI-natives.
Rubric read: moderate on multi-engine coverage, moderate on citation quality, lower on sentiment, low on workflow-to-execution beyond content brief exports, and high on multi-tenant fit given existing agency licensing. For agencies whose margin depends on stack consolidation rather than best-in-class per tool, the toolkit is a defensible default. It is not a differentiator.
BrightEdge and seoClarity: enterprise suites with AI Overview monitoring
BrightEdge and seoClarity anchor the enterprise end of the suite-with-AI-module category. Cross-platform benchmarking of enterprise AI SEO tools finds that both currently lead in AI visibility tracking for enterprises, offering monitoring of AI Overview appearances and generative search citations alongside their traditional enterprise SEO stacks 1. For agencies serving Fortune 1000 brands, that pedigree is often a procurement precondition, not a preference.
What these suites do well is scale and integration into enterprise reporting standards. BrightEdge's Data Cube and seoClarity's research-grade keyword universe map cleanly onto AI Overview monitoring, so a Head of SEO managing a global brand can track how AI answers cite their client across regions and topic clusters. That maps to Forrester's guidance to structure topic clusters and measure answer saturation as the core AI visibility discipline 15.
What they do less well is agility. Enterprise suites move on quarterly release cycles, which puts them behind AI-native tools on prompt-level features and sentiment forensics. They also carry enterprise pricing, which pressures the cost-to-serve math on mid-market accounts where the same visibility questions have to be answered on a leaner budget.
Rubric read: high on multi-engine coverage and multi-tenant fit for enterprise agencies, moderate on citation quality and sentiment relative to AI-natives, and low-to-moderate on workflow-to-execution—both platforms export briefs and recommendations, but the shipping still happens in a separate content ops stack. Agencies running a bifurcated book of enterprise plus mid-market accounts often pair these suites with an AI-native tool rather than choosing between them.
Sight.ai and Riff Analytics: AI-native specialists for citation forensics
Sight.ai and Riff Analytics sit at the specialist end of the AI-native measurement category, described in current enterprise reviews as platforms that specialize exclusively in AI search monitoring 1. Their pitch is depth over breadth: rather than adding AI visibility to a broader SEO suite, they treat citation forensics as the entire product surface.
The practical value shows up in three places:
- Source attribution—both tools trace which URL on a client's domain is actually being pulled into an AI answer, so a Head of SEO can tell whether a citation is coming from the intended pillar page or a stray FAQ.
- Cross-engine divergence analysis, which matters given how differently ChatGPT, Perplexity, Gemini, and Copilot cite the same query.
- Granular tracking of how brand mentions shift week-over-week as models retrain.
The catch is scope. These are reporting scalpels, not delivery platforms. An agency running Sight.ai or Riff is buying diagnostic clarity for accounts where citation quality is the strategic priority—typically B2B clients whose buyers are actively reading AI answers before requesting a demo.
Rubric read: high on citation quality forensics, high on multi-engine coverage, moderate on sentiment, low on workflow-to-execution, and moderate on multi-tenant fit depending on workspace design. Agencies with a small number of high-value B2B accounts get more from these specialists than agencies managing high-volume local SEO books, where broader suites remain the more efficient choice.
Approval-first execution layer: closing the loop from signal to shipped work
The three categories above—AI-native measurement tools, suite-with-AI-module platforms, and enterprise specialists—all stop at the same place. They produce signals. They do not ship work. For an agency running 40 accounts, the measurement-to-execution gap is where cost-to-serve inflates fastest, because every insight has to be re-briefed, re-approved, and re-routed through a content ops process that was built for a pre-AI reporting model.
The execution-layer category answers a different question: once Profound flags a citation gap on Perplexity, or Peec surfaces a sentiment shift on Gemini, what shortens the path from that signal to a shipped brief, a schema patch, or an internal-link edit? Forrester's guidance to shift measurement from traffic and average position toward share of search and answer-engine saturation only compounds returns when those metrics drive production, not just reporting 17. Otherwise the signal degrades before it becomes work.
An approval-first execution layer routes AI visibility signals into ranked recommendations, ties each recommendation to the specific content or technical action that would close the gap, and requires human sign-off before anything ships. That preserves the strategic judgment a Head of SEO already exercises while removing the briefing, coordination, and QA overhead that scales linearly with account count. Vectoron is the execution layer built on that model, positioned to sit downstream of whichever measurement stack an agency already runs.
Rubric read: coverage depends on the upstream measurement tools it ingests, high on workflow-to-execution by design, high on multi-tenant fit, and low on standalone visibility reporting—it is not a Profound replacement. The category exists to solve the shipping problem the other five tools leave open.
Stack consolidation math for a 40-account book
If you manage 15 or more client accounts, the AI visibility question stops being about tool selection and becomes a stack architecture problem. The cost-to-serve math changes shape at portfolio scale, because most inputs multiply by analyst count and account count at the same time.
A typical fragmented agency stack running AI search work today carries four line items: an enterprise SEO suite (BrightEdge, seoClarity, or Semrush) priced per seat, a dedicated AI visibility tool (Profound, Peec AI, Sight.ai, or Riff) priced per tracked domain or workspace, a content operations layer for briefs and QA, and a separate reporting layer stitching all three into client-ready decks. The consolidated alternative collapses reporting and execution into the workspace where signals originate.
The variables that actually move margin:
| Cost driver | Fragmented stack | Consolidated stack |
|---|---|---|
| Software licensing | (SEO suite per-seat × analysts) + (AI visibility per-domain × accounts) + reporting tool | (SEO suite per-seat × analysts) + (execution layer with ingested signals) |
| Reporting hours/month/account | Reconciliation across 2–3 dashboards | Single roll-up, signals pre-tied to recommendations |
| Brief-to-ship cycle time | Re-briefing from dashboard exports | Signals routed as ranked, pre-scoped work |
| QA overhead | Per-account manual review | Approval workflow with audit trail |
The productivity signal that reframes this economics conversation comes from Forrester: answer engines help 28% of B2B buyers spend less time researching 16. That compression pushes agency reporting cycles in the same direction. If buyers are moving faster, the cadence of signal-to-shipped-work has to move faster too, or citation gaps stay open across a full reporting quarter. Plug your actual per-seat cost and analyst count into the top row and the consolidation break-even usually lands well below a 40-account book.
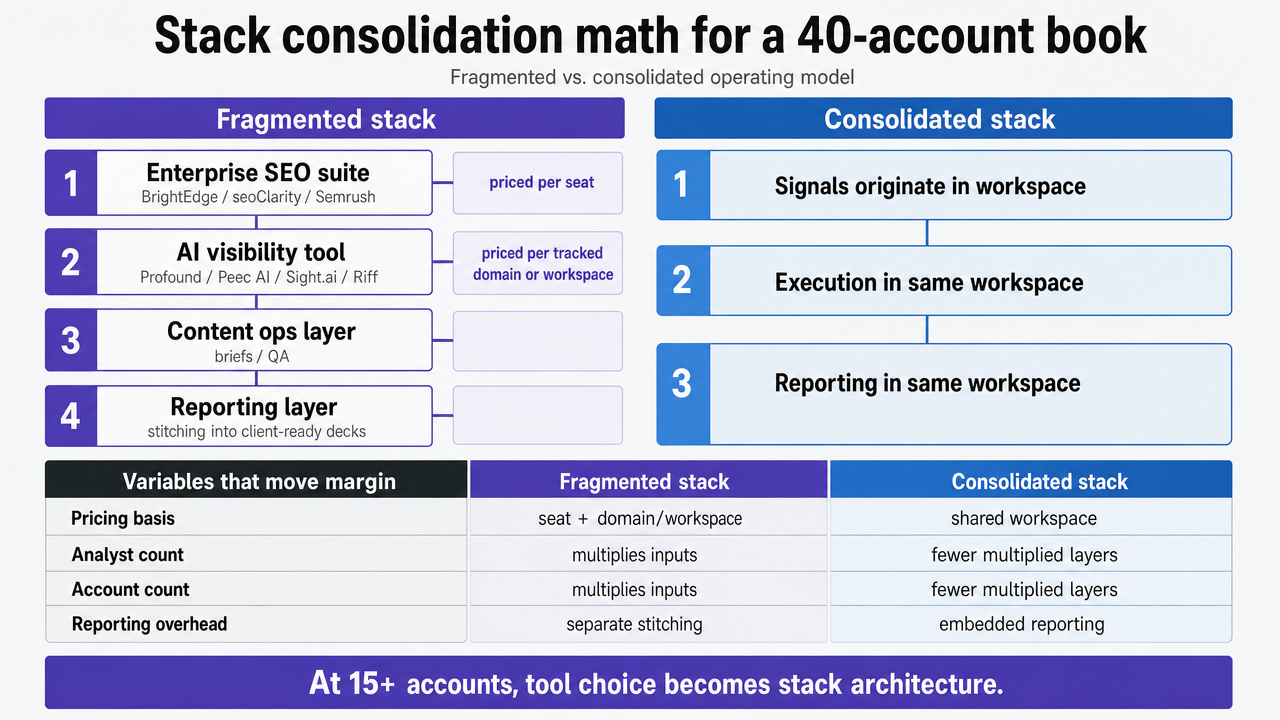 Render the fragmented-vs-consolidated stack comparison table from the article as a clear side-by-side process infographic, directly supporting the section's operating-model argument
Render the fragmented-vs-consolidated stack comparison table from the article as a clear side-by-side process infographic, directly supporting the section's operating-model argument
See How Leading Agencies Deploy AI for Search Optimization at Scale
Connect with a strategist to benchmark your current SEO workflow against AI-powered models that cut delivery time and increase content output without adding headcount.
Where governance fits: approval workflows and AI output error rates
Acting on AI visibility signals without a governance layer creates a specific failure mode: an analyst sees a citation gap on Perplexity, drafts an answer block, and ships it before anyone checks whether the underlying AI response was accurate to begin with. Given that only one-in-five U.S. adults find AI summaries extremely or very useful 12, the raw signals feeding an agency's optimization queue carry meaningful error rates and cannot be treated as ground truth.
NIST's AI Risk Management Framework is the reference point agencies should be borrowing from, not building around. Its purpose is to improve the ability to incorporate trustworthiness into the design, development, use, and evaluation of AI systems 13, and the Generative AI Profile released with Commerce guidance centers on 12 risks and just over 200 actions developers can take to manage them 14. Translated into agency operations, three controls matter:
- A human approval gate before any AI-surfaced recommendation ships.
- An audit trail linking each shipped change to the specific signal that triggered it.
- A cross-check step that verifies the AI response cited a real client URL rather than a hallucinated one.
Tools that embed those controls at the workflow layer scale governance without adding QA headcount. Tools that leave governance to a separate spreadsheet push the risk back onto the Head of SEO.
How to pilot the stack in 30 days without disrupting delivery
A stack change across a live book of accounts fails when it tries to swap tools everywhere at once. The pilot pattern that holds delivery margin steady is narrower: pick three accounts, one measurement tool, and one execution loop, and run them in parallel with the existing reporting cadence for a single month.
- Week 1: baseline. Select three accounts that span the portfolio—one enterprise, one mid-market B2B, one high-volume local or DTC. Run the current stack as-is and capture the five signals against Forrester's saturation framing: mention frequency, citation share, position, sentiment, and competitive gap 17. This becomes the control.
- Week 2: add one measurement layer. Bolt a single AI-native tool (Profound, Peec AI, Sight.ai, or Riff) onto the three pilot accounts. Do not replace the incumbent suite yet. The question is whether the new tool surfaces citation gaps the current stack misses, not whether it wins on features.
- Week 3: route signals into ranked work. Take the top five gaps per account and push them through the execution workflow—content brief, schema patch, or internal-link edit—with human approval on every shipped change. Track hours from signal to ship.
- Week 4: measure the delta. Compare citation share movement and reporting hours reclaimed against the baseline. If the pilot compresses brief-to-ship cycle time and lifts citation share on at least two of the three accounts, expand to the next cohort. If it does not, the bottleneck is upstream of tooling.
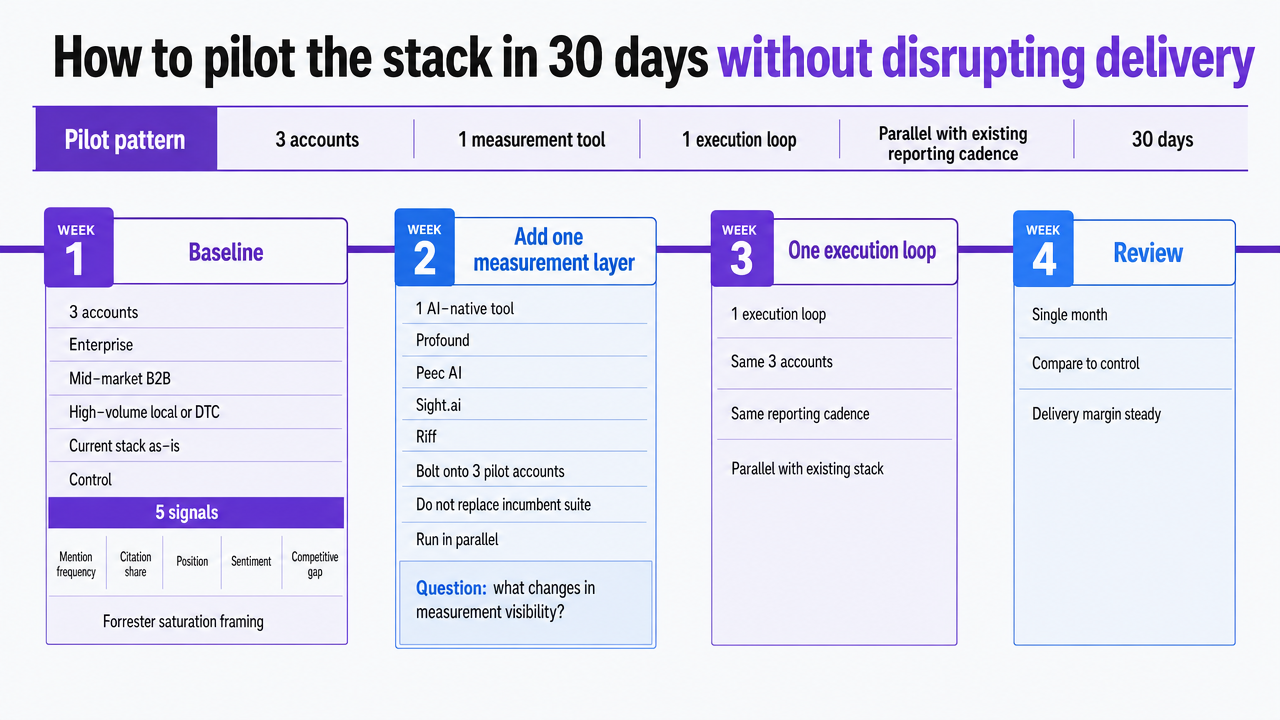 Visualize the four-week pilot sequence as a linear process infographic that mirrors the article's step-by-step operational plan
Visualize the four-week pilot sequence as a linear process infographic that mirrors the article's step-by-step operational plan
Frequently Asked Questions
References
- 1.Best Enterprise AI SEO Platforms for 2026.
- 2.AI SEO: Answer Engine Optimization and LLM Discovery.
- 3.AI SEO Services for AI Search Visibility.
- 4.Answer Engine Optimization (AEO): Guide for B2B Marketing Content.
- 5.AI Answer Engine Optimization: A GEO Strategy for B2B Brand Discovery.
- 6.The 3 BEST AI Search Visibility Tools for 2026.
- 7.Best AI Search Visibility Tools for Businesses in 2026.
- 8.Enterprise SEO: The Complete Strategy Guide for 2026.
- 9.B2B Marketers Need to Know AEO - Answer Engine Optimization.
- 10.B2B Answer Engine Optimization Services (AEO).
- 11.Americans and AI 2026: Chatbots, Smart Devices and Views on Impact.
- 12.Americans have mixed feelings about AI summaries in search results.
- 13.AI Risk Management Framework | NIST.
- 14.Department of Commerce Announces New Guidance, Tools 270 Days Following President Biden's Executive Order on AI.
- 15.Win Visibility In AI Search With Answer Engine Optimization - Forrester.
- 16.The Marketer's Guide To Answer Engine Optimization.
- 17.How To Master Answer Engine Optimization.
- 18.Impact And Opportunity For AI-Powered Search In B2B Marketing.