
Key Takeaways
- Multi-client governance and approval gates protect agencies from unreviewed AI output reaching client sites, logging who proposed, approved, and published each change per account 5.
- AI answer engine visibility tracking across ChatGPT, Perplexity, and Google AI Overviews is essential as LLM systems could handle over 50% of query volume by 2030 7.
- Entity and topical coverage analysis at portfolio scale clusters thousands of URLs, surfaces missing subtopics, and flags intent-content mismatches that strategists cannot catch manually 1.
- Retrieval quality and the context layer determine accuracy, since two tools using the same LLM produce very different analysis depending on what data grounds each recommendation 9.
- Workflow integration matters because analysis ending in a PDF erodes margin; the tool should reduce hand-offs between audit finding and published change 10.
- Margin economics per strategist is the final test: a tool only earns its place if it raises the clients-per-strategist ratio without lowering output quality 6.
Why agency SEO leaders are re-evaluating their analysis stack in 2025
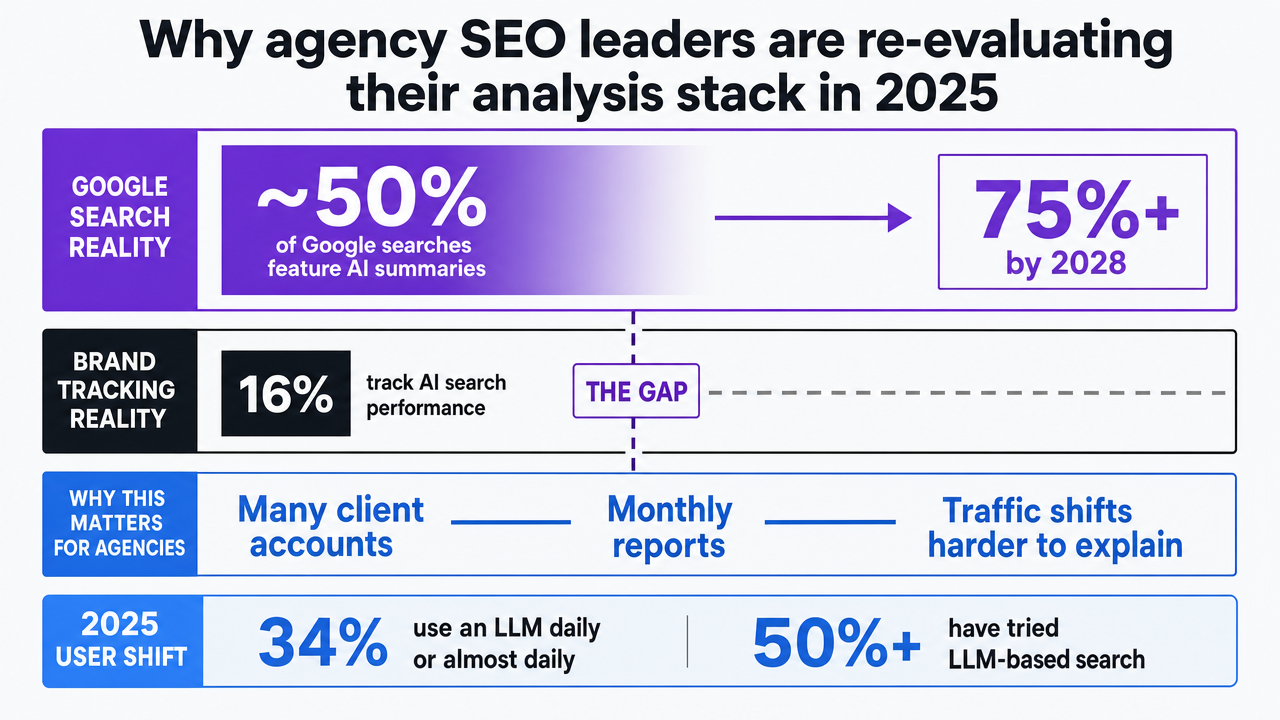
The SEO stack that agencies have relied on for the past decade, built around rank tracking, backlink graphs, and on-page audits, is now insufficient. McKinsey's analysis of brand tracking practices reveals that approximately half of Google searches already feature AI summaries, a figure expected to surpass 75% by 2028. However, only 16% of brands systematically track AI search performance 2. For an agency managing numerous client accounts, this gap is not merely an academic point; it represents a significant delivery challenge, manifesting in monthly reports that no longer adequately explain shifts in qualified traffic.
This shift in user behavior is quantifiable. By 2025, 34% of consumers report using a Large Language Model (LLM) daily or almost daily, and over half have experimented with LLM-based search 7. Content discovery is increasingly fragmented across platforms like ChatGPT, Perplexity, Google AI Overviews, and other embedded answer surfaces. Consequently, a strategist relying solely on keyword-focused tools to audit a client portfolio is observing a diminishing portion of the actual query landscape.
Forrester's distinction between point tools and "true SEO platforms"—those designed to coordinate workflow, reporting, and governance across various stakeholders—has become a more pertinent framework for tool selection 10. Agency leaders are no longer just seeking another tracker; they are choosing the analytical layer that will determine the number of clients a single strategist can effectively serve in the coming year.
 Visualize the gap between AI summary prevalence in Google searches and the percentage of brands tracking AI search performance, directly supporting the section's central claim
Visualize the gap between AI summary prevalence in Google searches and the percentage of brands tracking AI search performance, directly supporting the section's central claim
The six criteria that separate an LLM SEO analysis tool from a keyword tracker with an AI badge
Multi-client governance and approval gates
An agency analysis tool that lacks the ability to enforce client-level permissions, maintain audit trails, and manage approval routing becomes a liability for strategists handling more than a few accounts. Edelman's framework for evaluating enterprise LLMs prioritizes governance, explainability, and workflow integration over raw model benchmarks. This is because the defensibility of model output is directly tied to the controls surrounding it 5.
For an SEO head overseeing a 40-client portfolio, the crucial test is whether the platform separates analysis from publishing with a human checkpoint. While LLMs can generate recommendations, identify entity gaps, and flag cannibalization at scale, unreviewed output deployed to a client's site risks factual errors and inconsistencies in brand tone. The ideal tool should log who proposed, approved, and published each change, per client, with role-based access. Without this layer, the agency bears the risk of every automated suggestion that makes its way into production.
AI answer engine visibility tracking
Tracking "position one" on a traditional SERP no longer fully captures where a query is resolved. By 2025, 34% of consumers use an LLM daily or near-daily, and over half have tried LLM-based search. Forecasts indicate that LLM systems could handle over 50% of global query volume by 2030 7. A tool that only reports Google rank for a client's priority terms provides an incomplete view of the discovery landscape.
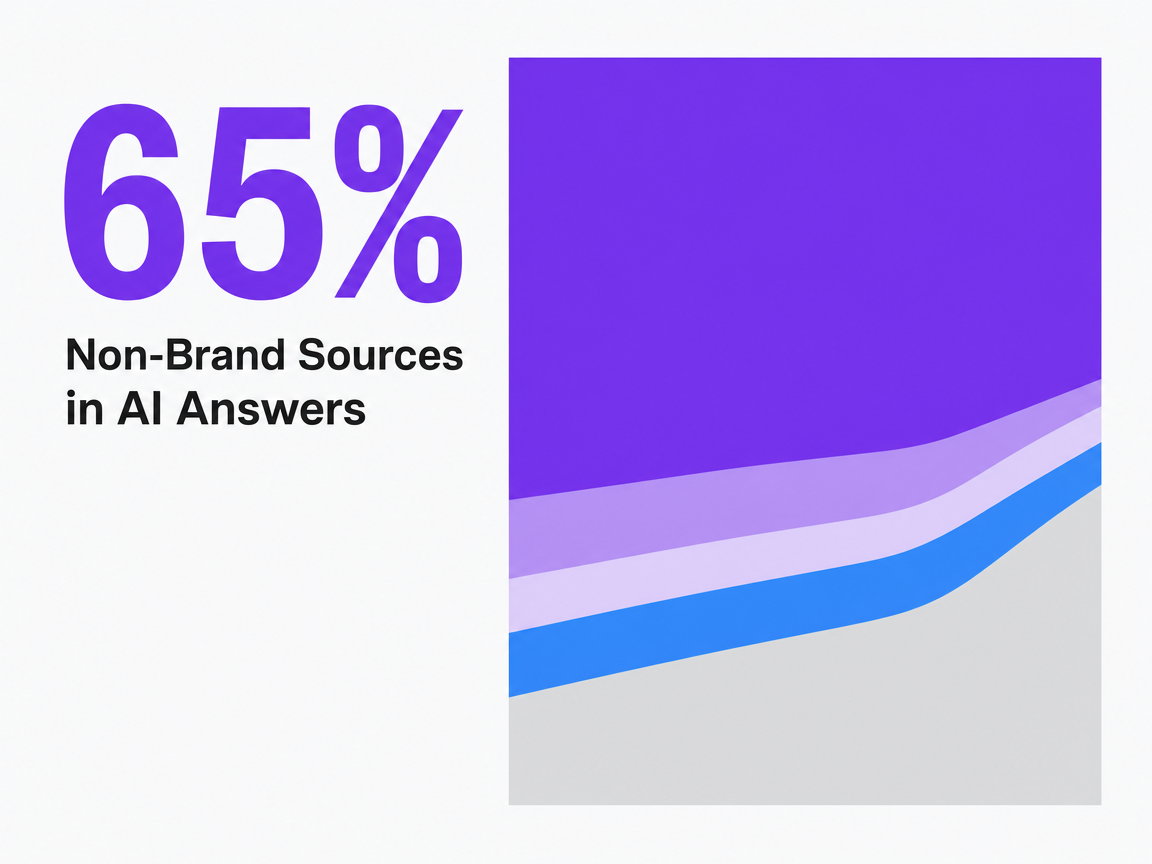
Essential capabilities include structured monitoring of brand and content visibility across platforms like ChatGPT, Perplexity, Google AI Overviews, and similar answer engines. This involves tracking citation share, source attribution, and prompt coverage for each client's target intents. Agencies also need tools that differentiate between cited mentions and competitive omissions, as the corrective actions required are distinct. McKinsey's analysis found that in some sectors, over 65% of sources cited in AI answers originate from publishers, user-generated content, and affiliate sites, rather than the brand itself, redefining what "winning" a query means 2.
Entity and topical coverage analysis at portfolio scale
Keyword volume alone does not inform a strategist whether a client's site demonstrates the entity relationships and topical depth that AI systems use to establish authority. Google's own generative AI guidance emphasizes that visibility in AI features relies on expert-led, non-commodity content with clear structure and crawlability, not specialized markup 1. The analysis tool's role is to identify areas where content coverage falls short of this standard.
At a portfolio level, this means the tool should cluster thousands of URLs by entity overlap, pinpoint missing subtopics by comparing against competitor and SERP data, and flag pages where intent and content diverge. A strategist auditing multiple client sites cannot perform this manually across various practice areas and locations. The tool must provide ranked, page-level coverage gaps with supporting evidence, allowing strategists to focus on critical judgment calls rather than manual data reconciliation.
Retrieval quality and the context layer behind the analysis
Even if two tools use the same underlying LLM, their analysis quality can differ significantly due to the retrieval layer. This layer determines what content, metadata, SERP data, and competitive information the system incorporates as context before the LLM processes a query. Atlan's enterprise LLM guide explicitly states that
"the retrieval layer is your quality lever,"
and the context layer establishes the accuracy baseline for every model response 9.
For SEO analysis, this prompts specific questions for vendors: Does the platform chunk and embed the client's entire site, or only a sample? Are recommendations grounded in live SERP and AI-answer data, or do they rely on the model's training cutoff? Does the tool expose the sources behind a recommendation for strategist verification? Tools that provide vague answers to these questions are prone to confidently hallucinating across a client portfolio.
Workflow integration and the analysis-to-execution loop
Analysis that culminates in a PDF report does not drive client KPIs. Forrester's platform criteria highlight workflow, reporting, and governance as key differentiators for true SEO platforms, emphasizing the connective tissue that enables multiple stakeholders to act on shared data 10.
For an agency, effective integration means the platform can route a flagged entity gap into a brief, the brief into a draft, the draft into client review, and the approved asset into a tracked publishing event, all without manual data re-entry. Tools that only provide recommendations shift the integration burden back to the strategist, eroding profit margins. The evaluation question is practical: how many hand-offs occur between an audit finding and a published change, and which of these hand-offs does the tool eliminate?
Margin economics per strategist
The final criterion directly impacts an agency's profitability. A tool's value is determined by its ability to improve the client-to-strategist ratio without compromising output quality. Menlo Ventures reports a significant increase in enterprise AI revenue, from $1.7 billion in 2023 to approximately $37 billion by 2025, with marketing workflows rapidly adopting this spend 6. This investment is driven by the tangible leverage AI offers, but only when the tool reduces labor rather than merely adding another dashboard.
For an agency head, the test is whether a strategist can credibly manage more accounts at the same quality level after adopting the tool. This can be measured by metrics such as pages audited per week, AI answer queries tracked per client, and approved recommendations shipped per cycle. If these numbers do not improve, the tool simply represents additional overhead.
 Non-Brand Sources in AI Answers
Non-Brand Sources in AI Answers
Non-Brand Sources in AI Answers
What to disqualify before you shortlist
Three categories of tools should be eliminated during the initial agency evaluation:
- First, pure keyword research platforms, even those with an "AI summary" tab, are inadequate because they focus on a SERP model that is becoming obsolete, rather than the evolving answer surfaces where clients now compete 7.
- Second, content generation tools lacking a retrieval-grounded analysis layer should be cut. Atlan's enterprise LLM guide clearly states that the context layer dictates the accuracy floor for model recommendations, and a generator without governed retrieval will confidently hallucinate across a large client base 9.
- The third category includes any platform that lacks a human approval checkpoint between recommendation and publishing. Edelman's enterprise evaluation framework considers governance and explainability as primary, not optional, criteria, as unreviewed automated changes can lead to client loss 5.
A practical disqualification heuristic: if a vendor cannot demonstrate, on a single screen, who proposed a change, who approved it, which client it was deployed to, and the data that supported the recommendation, the tool falls into the "point-solution" category that Forrester explicitly distinguishes from true SEO platforms 10. Such tools should be removed from consideration before a demo.
Test AI-driven SEO analysis workflows risk-free
Run live client SEO analyses and publish insights using the full platform during your free trial.
The shortlist: six LLM SEO analysis tools ranked against the agency rubric
Vectoron — unified semantic audit, GEO tracking, and approval-gated execution
Vectoron is designed around the complete loop described in the rubric: signal intake, LLM analysis, ranked recommendations, human approval, executed work, and measured impact—all client-scoped. It features a Command Center where proposed changes from six specialist strategists (Content, SEO, PPC, Backlinks, Social, Call Intelligence) are routed for sign-off before deployment. This directly addresses Edelman's emphasis on governance and explainability as primary evaluation criteria 5.
For an agency head, Vectoron's key capabilities are grouped into three areas. Its semantic auditing processes a client's entire content corpus, not just sampled URLs, identifying entity gaps, intent drift, and cannibalization with supporting evidence. GEO tracking provides standard reporting across ChatGPT, Perplexity, and Google AI Overviews, aligning with Forrester's measurement standards for true SEO platforms 10. Execution is governed, meaning approved recommendations move to drafting and publishing within the same system, preventing audit findings from being stalled in PDFs.
A consideration for agencies is that Vectoron's integration approach is opinionated. Agencies committed to a fully self-assembled stack of best-of-breed point tools may find this design prescriptive.
Ahrefs with AI Overviews tracking — strongest backlink and SERP intelligence with bolted-on AI visibility
Ahrefs remains a benchmark for backlink analysis, SERP history, and keyword intelligence. Its AI Overviews tracking has evolved into a valuable signal for clients whose priority queries trigger Google's generative results. For agencies whose client retention relies on link acquisition and competitive SERP analysis, Ahrefs' data depth is unparalleled.
However, Ahrefs falls short against the rubric in a few areas. Its AI answer engine coverage is primarily focused on Google's surfaces, with less granular visibility into ChatGPT and Perplexity citation share. This gap is significant as LLM systems are projected to account for a majority of query share by 2030 7. Multi-client governance and approval workflows are not native features; agencies typically integrate these through separate project management tools, which reintroduces the manual hand-offs that the rubric aims to eliminate 10.
Semrush Enterprise — broad platform breadth, uneven AI answer depth
Semrush Enterprise offers extensive coverage, encompassing technical audits, content scoring, competitive intelligence, local SEO, and PPC research within a single platform. For agencies requiring a unified solution for diverse client use cases, its breadth provides significant procurement value. The platform's content tools also include AI-assisted analysis layers capable of handling entity coverage at scale.
The primary weakness lies in its AI answer visibility depth. Citation tracking across ChatGPT and Perplexity is less granular compared to specialized GEO tools. Furthermore, the retrieval layer supporting its AI features is often opaque, necessitating that strategists verify recommendations against live SERPs. This friction point is what Atlan's enterprise guide identifies as the "accuracy-floor problem" when the context layer is not transparent 9.
Profound — purpose-built AI answer visibility, narrower auditing surface
Profound directly addresses the measurement gap identified by McKinsey: that only 16% of brands systematically track AI search performance 2. Its core offering is citation share tracking across ChatGPT, Perplexity, Google AI Overviews, and Copilot, providing prompt-level visibility and competitive answer benchmarking that traditional keyword platforms cannot match.
However, Profound is not a comprehensive audit platform. Functions like entity coverage analysis across a client's site, technical crawling, and content production must be handled by other tools in the stack. Profound is well-suited for agencies that already possess a robust traditional SEO toolset and need to augment it with specialized GEO measurement. It is not designed to be a standalone solution for agencies seeking consolidation.
Conductor — enterprise SEO platform with content intelligence layers
Conductor has long been established as an enterprise SEO platform, excelling in workflow management, stakeholder reporting, and governance features that Forrester uses to distinguish true platforms from point tools 10. Its content intelligence modules effectively handle entity and topical analysis at the scale required by agencies managing large client sites. Integrations with publishing and analytics stacks also reduce the number of hand-offs between audit and execution.
The primary gap in Conductor's offering, according to the rubric, is its AI answer engine coverage. While GEO tracking is improving, it still lags behind purpose-built tools in prompt-level citation share. Additionally, the platform's pricing structure is more favorable for larger client commitments, which may be a consideration for agencies with a mid-market or smaller client base.
Clearscope and MarketMuse — semantic content scoring, limited governance for multi-client delivery
Clearscope and MarketMuse remain valuable for strategists seeking to create defensible content briefs based on semantic and entity analysis. Both tools score content drafts against topical corpora, identify missing subtopics, and streamline the editorial review process for individual pieces. For individual writers or small content teams, their analysis quality is reliable.
However, at an agency portfolio scale, these tools fall short on governance and workflow criteria. Neither provides the multi-client approval routing required by the rubric, nor do they offer AI answer engine visibility as a primary feature. Their recommendations typically conclude at the brief stage, rather than integrating with a tracked publishing event, thereby shifting integration work back to the strategist and compressing margins 10.
If you manage multi-location and franchise portfolios: delivery economics per strategist
While the above rubric applies broadly to any agency, the economics change significantly for those managing multi-location and franchise portfolios. This includes dental groups with 60 offices, home services brands with 30 regional sites, or senior living operators with location-specific compliance needs. At this scale, each client effectively becomes its own portfolio. A strategist who can effectively manage six single-site clients may struggle with just two multi-location accounts using a traditional toolset.
The measurement gap is a critical bottleneck. McKinsey's analysis indicates that only 16% of brands systematically track AI search performance, despite AI summaries already appearing in roughly half of Google searches and projected to exceed 75% by 2028 2. For a strategist managing a franchise account with 40 locations, this gap is compounded: each location has its own intent set, competitive answer surface, and citation share to monitor. Manual tracking simply does not scale beyond a couple of clients.
The table below models the delivery economics using transparent variables. It can serve as a planning framework against your agency's labor cost per strategist.
| Variable | Traditional point-tool stack | Unified LLM-powered platform |
|---|---|---|
| Multi-location clients per strategist | 2–3 | 6–10 |
| Location pages audited per week | 40–80 | 400–800 |
| AI answer queries tracked per client | Sampled, top-10 terms | Full intent set, all locations |
| Approval-cycle throughput (recommendations shipped per week) | 15–25 | 80–150 |
| Manual hand-offs between audit and publish | 5–7 | 1–2 |
This throughput difference is not a theoretical assumption. It results from automating tasks that do not require a strategist's judgment—such as corpus chunking, entity gap detection, citation share monitoring across answer engines, and brief generation—and channeling the remaining work through a single approval interface. This allows strategists to reallocate their time from spreadsheet reconciliation to making critical decisions that clients truly value: editorial choices, competitive positioning, and overarching account strategy.
For an agency head managing multi-location clients, the operational implication is clear: if an evaluated tool does not improve the clients-per-strategist ratio without compromising quality, it does not justify its place on the P&L.
See How LLM-Powered SEO Analysis Scales Multi-Client Delivery
Request a walkthrough of AI-driven workflows that automate technical audits, competitive analysis, and content optimization—enabling agencies to deliver consistent, high-quality SEO at scale with full approval control.
Building the modern measurement stack around the tool you pick
Tool selection is a visible decision, but the more challenging underlying choice is what an agency reports to clients each month. A practitioner guide to enterprise SEO analytics for 2026 suggests that measurement must expand beyond rank and sessions to include AI referrals, citations within AI answers, and the "zero-click influence" that drives pipeline without direct clicks 8. An LLM analysis tool that surfaces these signals into an outdated reporting template will not realize its full potential.
The shift in reporting is evident when comparing traditional and AI-era stacks. The legacy stack typically focuses on keyword rank, organic sessions, conversions from organic, and backlink growth. The AI-era stack augments this with citation share across answer engines, prompt-level visibility for client intent sets, assisted-discovery influence on branded search and direct traffic, and entity authority signals tied to specific topics. Both sets of metrics remain important; Google's generative AI guidance explicitly states that core SEO fundamentals are still the foundation for visibility in AI features, so rank and crawl health remain crucial 1. The difference is that these traditional metrics are no longer sufficient on their own.
| Reporting layer | Traditional stack | AI-era stack |
|---|---|---|
| Visibility | Keyword rank, SERP features | Rank + citation share in ChatGPT, Perplexity, AI Overviews |
| Traffic | Organic sessions, CTR | Sessions + AI referral traffic, zero-click influence |
| Authority | Backlinks, domain metrics | Backlinks + entity coverage, source attribution in AI answers |
| Outcome | Conversions from organic | Conversions + assisted discovery via answer engines |
The operational takeaway for an agency head is to update the client reporting template before the renewal cycle, and then select the tool that can effectively populate it. Choosing in the reverse order will force strategists to manually re-enter answer-engine data into dashboards designed for an outdated SERP model 8.
How to run a 30-day evaluation across your client portfolio
Vendor demonstrations often provide an incomplete picture, showcasing a tool's capabilities on clean datasets rather than its real-world impact on a strategist's weekly workflow across live client accounts. A 30-day pilot, conducted with three representative clients—one single-site, one multi-location, and one content-heavy—will yield more accurate insights than any demo.
- Week one focuses on instrumentation. Connect each pilot client's full content corpus, Google Search Console, analytics, and competitive set. Establish a baseline by tracking metrics such as pages audited per week per strategist, AI answer queries currently tracked, hand-offs between audit and publishing, and reporting cycle time.
- Week two involves running semantic audits and GEO tracking across all three accounts concurrently, with the strategist manually verifying the quality of a sample of recommendations.
- Week three pushes approved recommendations through the platform's end-to-end execution path, measuring how many are published without manual re-keying.
- Week four compares the collected data against the baseline and the rubric's criteria: governance, AI answer coverage, retrieval transparency, workflow integration, and the clients-per-strategist ratio 10.
The success criterion is not feature parity, but whether the tool improves throughput numbers without compromising the editorial standards that secured client renewals. Agencies conducting this evaluation with Vectoron and other shortlisted alternatives will be able to make a defensible selection by the end of the cycle.
Enterprise LLM Market CAGR
Frequently Asked Questions
References
- 1.Optimizing your website for generative AI features on Google Search.
- 2.Winning in the age of AI search.
- 3.Enterprise LLM Market Trend, Size | CAGR of 29.2%.
- 4.A Comprehensive Overview of Large Language Models.
- 5.Enterprise AI in Focus: Evaluating Large Language Models for Marketing and Communications.
- 6.2025: The State of Generative AI in the Enterprise.
- 7.When Will AI Search Beat Google? 2025–2030 Forecast.
- 8.Enterprise SEO Analytics: A Complete Guide for 2026.
- 9.Large Language Models: An Enterprise Guide to LLMs in 2026.
- 10.Every Company Needs An SEO Platform.