
Key Takeaways
- Profound monitors brand and URL citations across AI Overviews, ChatGPT, and Perplexity, surfacing visibility drops in standups before clients raise them, though it remains read-only.
- Clearscope grades drafts on entity coverage and structural signals, giving senior editors a defensible QA checkpoint that maps to how AI engines weight sources 11.
- MarketMuse maps existing content footprints against topical authority, replacing manual audit work with prioritized recommendations to write, consolidate, or kill pages.
- Otterly.AI tracks share-of-voice inside LLM answers with prompt-based pricing that fits smaller portfolios, but overlaps heavily with Profound on the monitoring job.
- Vectoron spans research through publish with approval-first execution, compressing brief-to-draft time on the junior cohort where the 34% novice productivity lift lands 3.
- Airtable plus Frase orchestrates a multi-tool stack for agencies unwilling to consolidate, but carries 10 to 15 hours weekly of operator maintenance at 25 accounts.
What Google's Own Documentation Says About 'LLM SEO'
Google's own developer documentation is the cleanest place to start, because it deflates most of the vendor pitch decks circulating in agency Slack channels. The Search Central guidance on AI features states plainly that pages eligible for AI Overviews and AI Mode are pages already eligible to appear in standard Search results, and that "there are no additional technical requirements" beyond being indexed and eligible for snippets 1. The same foundational SEO best practices apply.
That single sentence reframes the entire category. "LLM SEO software" is not a parallel discipline with its own ranking algorithm to game. It is a re-bundling of three jobs agencies already do: auditing whether source pages are structured and authoritative enough to be cited, producing content that answers specific queries cleanly, and monitoring which surfaces actually surface the work.
For a Head of SEO running a 25-account portfolio, this matters operationally. It means tool selection is not about chasing a new ranking factor. It is about deciding where in the existing pipeline — research, brief, draft, QA, publish, monitor — a new piece of software earns its seat. Vendors that promise "AI search optimization" as a distinct service line are, by Google's own framing, selling augmentation of the stack already in place. The six picks below are evaluated on that basis.
Why Agency Briefs Started Mentioning AI Search This Year
Three years ago, a client RFP asking about "AI Overviews coverage" or "ChatGPT citation share" would have been an outlier. In 2026, it is a standard line item. The shift is not driven by agencies pitching it — it is driven by the client side, where marketing leads now use generative AI in their own workflows and assume their search vendor should too.
The Census Bureau's Business Trends and Outlook Survey tracked overall AI usage at U.S. businesses between 17% and 20% from December 2025 through May 2026, with 20% to 23% of firms expecting to be using AI within the next six months 4. That range matters less than the direction: every cohort the Bureau surveyed reported higher expected use than current use. Client-side marketing teams sit inside those firms, and they are the ones writing the briefs that land in agency inboxes on Monday morning.
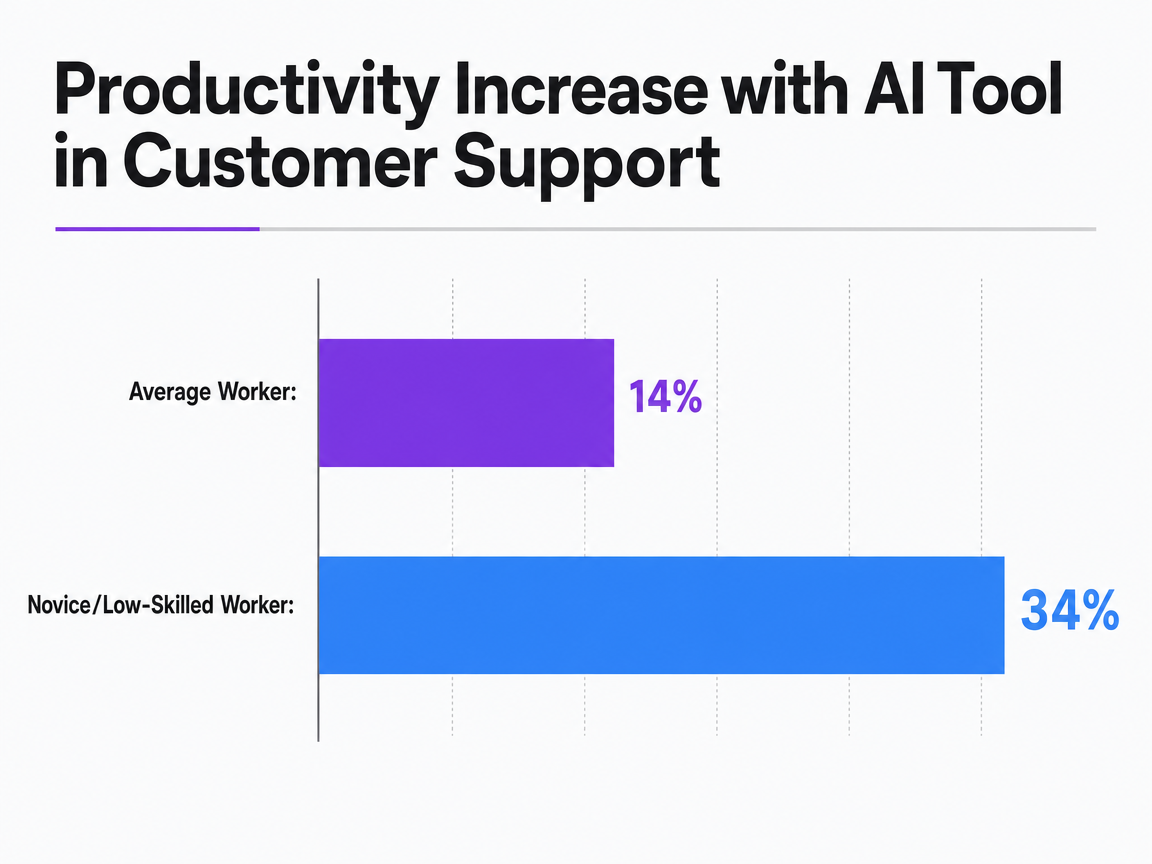
There is a second pressure, less visible but more operationally consequential. The Generative AI at Work field study found AI assistance lifted output 14% on average and 34% for novice and low-skilled workers in a customer support setting 3. The finding is narrow — one company, one job function — but the implication for agency clients is direct. If a client's in-house team is producing twice as much draft content with AI assistance, they expect their SEO partner to keep pace on the distribution side.
The brief no longer reads "rank for these keywords." It reads "show up in the answer." That phrasing is what every tool below is trying, in different ways, to operationalize.
The Four-Criterion Rubric Behind These Picks
Every tool below was scored against the same four questions, because those are the questions that come up in agency operating reviews — not the ones that come up in vendor demos.
- Throughput per SEO. How many client accounts can one senior SEO realistically support with this tool in the stack? A visibility monitor that requires daily manual review fails this test differently than a production tool that compresses brief-to-draft time.
- Defensibility of output. Does the tool produce an audit trail — source citations, change history, structured rationale — that survives a client QA call or a Google quality update? Pages cited by AI surfaces tend to be authoritative and well-structured 11, and the tool should reinforce that property, not paper over its absence.
- Governance and approval fit. Where does human sign-off live? Agencies running regulated verticals (legal, healthcare, behavioral health) cannot ship content that bypasses a named reviewer. Tools that assume full automation are a liability in those accounts.
- Margin impact at 20+ accounts. Does the cost curve bend favorably as the portfolio grows, or does each new client add a proportional seat fee? This is where stack consolidation either pays off or quietly erodes the gross margin line.
No tool scores a perfect four. The point of the rubric is to make the tradeoffs visible before procurement, not after.
Test AI-driven SEO workflows with real outputs
Experience live publishing and workflow automation for actual client SEO projects during your trial—no restrictions, no simulations.
Six Picks, Grouped by the Job They Do in an Agency P&L
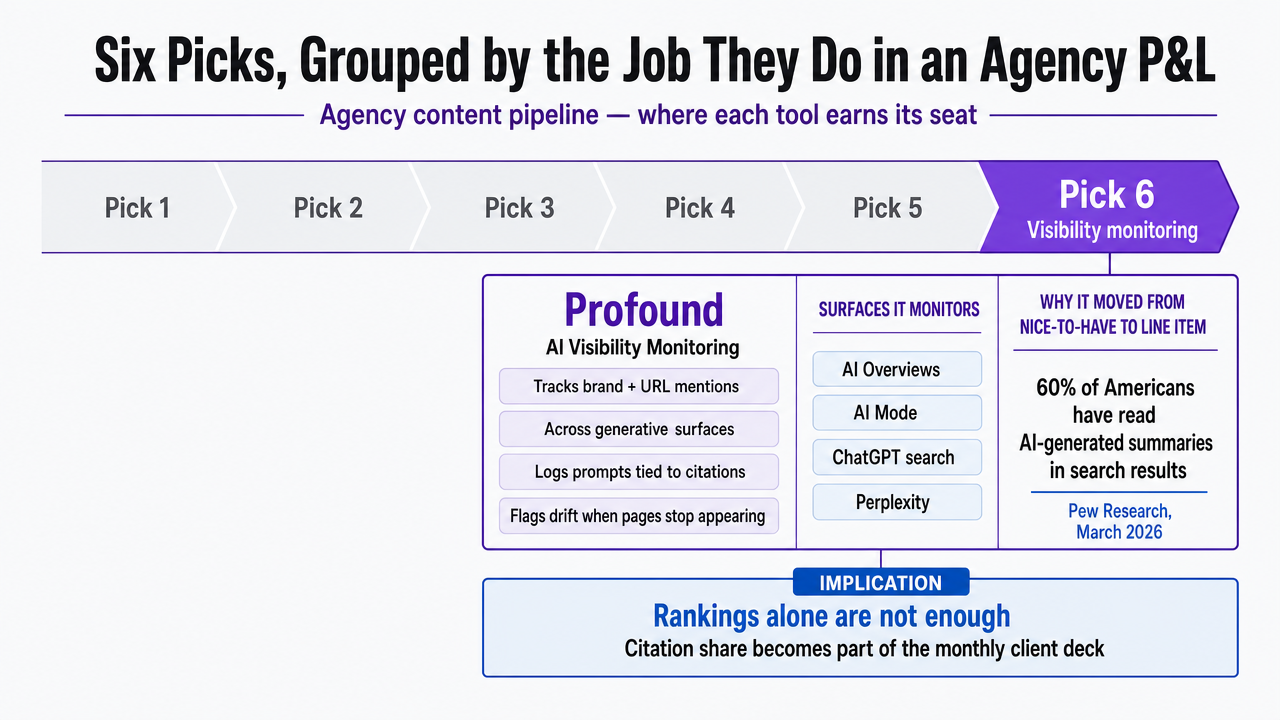
Profound — AI Visibility Monitoring Across Generative Answer Engines
Profound sits in the visibility-monitoring slot, which used to be a nice-to-have and now reads as a standalone line item in most agency tool stacks. The reason is straightforward: Pew Research reporting from March 2026 found that 60% of Americans have read AI-generated summaries appearing in their search results 5. Once a majority of the audience encounters synthesized answers before clicking, an agency cannot report on organic performance using rankings alone. Citation share inside AI Overviews, AI Mode, ChatGPT search, and Perplexity becomes part of the monthly client deck or it doesn't.
Profound tracks brand and URL mentions across those generative surfaces, logs which prompts triggered which citations, and flags drift when a client's pages stop appearing for queries they previously dominated. For a six-person SEO pod managing 25 accounts, that monitoring layer is the difference between hearing about a visibility drop from the client and surfacing it in a Tuesday standup.
The tradeoffs are real. Profound is read-only — it reports on what AI engines do, not on what to ship next. Senior SEOs still have to translate citation gaps into content actions, which means the tool adds a reporting line to the P&L without compressing production time. Pricing scales per tracked brand and prompt volume, so portfolios with many small clients can see seat costs grow faster than coverage. Throughput per SEO improves modestly; defensibility improves substantially because client reporting now includes a measurable AI-surface metric.
Clearscope — Source-Quality and Entity Auditing for Cite-Worthy Content
Clearscope earns its place by doing one thing well: scoring whether a draft reads like a page an AI engine would actually cite. The product surfaces missing entities, related terms, and structural gaps against the top-ranking pages for a query, which maps directly onto the property Google's AI features draw from — standard search eligibility and quality signals 1. Pages that AI surfaces tend to lean on authoritative, well-structured sources 11, and Clearscope's content grading is a practical way to enforce that pattern across a writer pod.
For an agency running content-heavy verticals — legal, healthcare, SaaS — the auditing layer matters more than the keyword layer. A personal-injury page that scores well on Clearscope is one a senior editor can defend in a client QA call, because the entity coverage is visible in the report. That audit trail is the defensibility criterion in concrete form.
Clearscope's limits show up at scale. The tool grades drafts; it does not produce them, brief them, or route them through approval. A 25-account portfolio still needs writers, editors, and project managers wrapped around the grader. Per-seat pricing is the standard model, so margin impact is flat rather than declining as the portfolio grows. Throughput per SEO improves at the QA stage but not upstream. Agencies that already run a strong brief-and-write process get the most leverage; agencies hoping a grader will fix a weak writer bench will be disappointed.
MarketMuse — Structured Production and Topical Authority Mapping
MarketMuse approaches the same problem from a planning angle. Instead of grading a single draft, it maps a client's existing content footprint against a topic and identifies the cluster gaps that would have to close before a domain reads as authoritative on that topic. For agencies inheriting messy client sites — 400 thin blog posts, no internal architecture, partial coverage across three verticals — that mapping replaces a week of manual audit work.
The topical-authority framing aligns with how AI search systems weight sources. Guidance from academic content teams reinforces that AI-generated answers tend to pull from authoritative, well-structured sources with clear internal linking and topical depth 11. MarketMuse's content inventories and cluster recommendations operationalize that property: the output is a prioritized list of pages to write, consolidate, or kill, ranked by projected authority impact.
The tool's weak point is execution. MarketMuse tells a senior SEO what should exist; it does not produce the drafts, manage the writer assignments, or track which briefs landed in QA last Friday. Pricing tiers gate the most useful features — competitive content inventories, personalized difficulty scoring — behind higher commitment levels, which can be hard to justify for agencies whose client mix is heavy on smaller accounts. Throughput per SEO improves at the planning stage. Defensibility improves because content decisions carry visible rationale. Margin impact depends entirely on whether the agency has the production capacity to act on the recommendations the tool surfaces.
Otterly.AI — Citation Tracking and Brand Mention Surveillance in LLM Answers
Otterly.AI overlaps with Profound in category but optimizes for a narrower question: when an LLM answers a prompt about a client's industry, does the client's brand get named, linked, or ignored? The tool runs scheduled prompts across ChatGPT, Perplexity, Google AI Overviews, and similar surfaces, then logs every brand mention and source URL in the response. Output is a longitudinal record of share-of-voice inside generative answers.
That data set has two operational uses in an agency. The first is competitive: when a client asks why a rival keeps appearing in AI answers for category-defining queries, Otterly.AI provides the prompts and the citation chain showing which of the rival's pages are being pulled. The second is defensive — flagging when a client's own mention rate decays after a Google quality update or a content consolidation push.
The overlap with Profound is the obvious tradeoff. Agencies running both tools pay twice for variations on the same monitoring job, and most procurement reviews will only fund one. Otterly.AI's pricing tends to fit smaller portfolios better because tracking is prompt-based rather than brand-based. The tool is again read-only, so it improves reporting and account-health visibility without changing what the production pod actually ships. Throughput per SEO is roughly neutral. Defensibility improves at the client-reporting layer.
Vectoron — Approval-First End-to-End Execution for Client Portfolios
Vectoron occupies a different square on the rubric than the four tools above. The previous picks improve one stage of the agency pipeline — audit, plan, or monitor — without touching production. Vectoron sits across the whole pipeline: specialist AI strategists handle research, briefing, drafting, internal linking, and publishing recommendations, and every output is routed through a Command Center where a named human approves before anything ships. For an agency Head of SEO, that combination is what separates an execution platform from a feature.
The productivity case is grounded, not promotional. An NBER field study of generative AI in customer support found access to the tool lifted issues resolved per hour by 14% on average, with the effect rising to 34% for novice and low-skilled workers 3. The study is narrow — one company, one job function — but the skill-level split is the part that maps onto an agency P&L. The 34% lift for less-experienced workers is where unit economics actually move, because junior SEOs and associate writers represent most of the production hours in a typical pod. Compressing brief-to-draft time on that cohort is where consolidated execution earns its keep.
Vectoron's tradeoffs need to be named. The platform is opinionated about workflow: agencies with deeply customized briefing templates or non-standard QA stages will have to adapt. Approval-first execution slows pure throughput compared to a fully autonomous pipeline, which is the intended design but worth flagging for shops chasing volume above governance. Pricing starts at a $599/month rate after a two-week trial, so the entry point is accessible, but full portfolio rollout requires the kind of operating-model change that takes a quarter to settle.
Airtable + Frase Stack — Workflow Orchestration Across Existing Tools
Some agencies will not consolidate, full stop. The senior team has built a working stack — a brief template in Notion, drafts in Google Docs, a content grader, an SEO dashboard — and rebuilding around a single platform is more disruption than the margin gain justifies. For those shops, the orchestration layer is what makes the stack scale.
Airtable plus Frase is the most defensible version of that approach. Airtable handles the database side — clients, content calendars, brief status, writer assignments, approval gates — with views customized per account manager. Frase covers the LLM-assisted brief and outline layer, pulling SERP data and competitor structure into a working document that writers can build from. The combination is not a single product; it is the connective tissue that keeps Clearscope, MarketMuse, Profound, and a writer marketplace from drifting into separate spreadsheets.
The tradeoff is maintenance debt. The orchestration layer is only as reliable as the operations lead maintaining the Airtable schemas and Frase templates. Turnover in that role is where these stacks degrade. Pricing is modest per seat, but the hidden cost is operator time — typically 10 to 15 hours a week at a portfolio of 25 accounts. Throughput per SEO is high when the stack is healthy. Defensibility depends on whether each underlying tool produces its own audit trail. Margin impact is favorable until the operations lead leaves.
 Visualize the six tool picks mapped to the stage of the agency content pipeline where each one earns its seat, directly supporting the section's framing of tools by job-to-be-done
Visualize the six tool picks mapped to the stage of the agency content pipeline where each one earns its seat, directly supporting the section's framing of tools by job-to-be-done
If You Manage 20+ Client Portfolios: Stack Sprawl vs. Unified Execution
For agency leads managing 20+ client portfolios, the math on tool selection changes shape. At 5 to 10 accounts, a multi-tool stack is a manageable orchestration problem. At 25 or 50 accounts, every seat fee, every manual handoff between tools, and every operations hour spent maintaining glue code shows up in the gross margin line.
The typical sprawl pattern is familiar: one visibility monitor, one content grader, one topical-authority planner, one project management database, one writer marketplace or freelancer bench, plus the LLM-assisted brief layer. Each is justifiable in isolation. Aggregated across 25 accounts, the seat fees stack and the operations lead spends a third of the week keeping schemas in sync rather than producing client-facing work.
The table below uses only reader-supplied variables and the single published price point available in the supplied research. Everything else is left as a variable so the procurement conversation reflects actual portfolio shape, not invented benchmarks.
| Cost component | Multi-tool stack | Unified execution platform ||---|---|---|| Visibility monitoring | Per-brand or per-prompt seat fees × N clients | Included in platform || Content grading / planning | Per-seat fees × E editors | Included in platform || Project management / DB | Per-seat fees × U users | Included in platform || Writer cost | Avg writer rate × A articles/client/month × N clients | Avg writer rate × A articles/client/month × N clients (or reduced via assisted drafting) || Operations maintenance | ~10–15 hrs/week operator time | Reduced; workflow is opinionated, not custom || Published entry price | Variable per vendor | $599/month after a two-week trial (Vectoron) |
The productivity case for consolidation is not speculative. The NBER customer-support field study found AI assistance raised issues resolved per hour by 14% on average, with a 34% lift for novice and low-skilled workers 3. In an agency pod, that skill-level split lands on the associate writers and junior SEOs who carry most of the production hours. Consolidation pays off when the platform actually compresses brief-to-draft time on that cohort. It does not pay off when the unified tool is simply a more expensive replacement for the grader.
The honest read: sprawl wins for boutique shops with a strong operations lead and a stable account mix. Consolidation wins at 20+ accounts when the operations lead is the bottleneck and approval governance is the constraint.
 Productivity Increase with AI Tool in Customer Support
Productivity Increase with AI Tool in Customer Support
An NBER field study showed that giving customer support agents access to a generative AI assistant increased issues resolved per hour by 14% on average, with the impact rising to 34% for novice and low-skilled workers.
See How Leading Agencies Operationalize LLM SEO at Scale
Connect with our team for a walkthrough of AI-powered SEO workflows that reduce manual overhead, accelerate delivery, and maintain enterprise-grade oversight across all client accounts.
Where Each Tool Plugs Into a Standard Agency Content Pipeline
A useful way to evaluate the six picks is to map them onto the pipeline an agency already runs: research → brief → draft → QA → publish → monitor. Each tool earns its seat at a specific stage, and the overlaps are where procurement gets expensive.
- Research and planning. MarketMuse sits earliest, surfacing cluster gaps and topical-authority deficits before a brief gets written. Frase overlaps here on the SERP-structure side, pulling competitor outlines into a working document.
- Brief and draft. Frase carries into the brief stage. Vectoron spans this stage through publish, with specialist strategists handling briefing, drafting, and internal linking inside one approval workflow.
- QA. Clearscope grades drafts against entity coverage and structural signals — the property that maps onto how AI engines weight sources 11. Senior editors use the score as a defensible checkpoint before approval.
- Publish. Airtable handles the routing layer for agencies running a multi-tool stack; Vectoron handles it natively for agencies that consolidated.
- Monitor. Profound and Otterly.AI both live here, tracking citation share across AI Overviews, AI Mode, ChatGPT, and Perplexity. Running both is the most common source of stack redundancy.
Honest Tradeoffs Before You Sign a Contract
No tool on this list is a clean win. Profound and Otterly.AI improve reporting without changing production, which means citation share moves into the client deck but the writer pod still ships the same volume on the same timeline. Clearscope and MarketMuse sharpen the QA and planning stages but assume the agency already has a functioning writer bench underneath them. Vectoron consolidates execution but requires the operating-model change to do it. Airtable and Frase preserve flexibility at the cost of operator hours that compound with portfolio size.
The sharper question for a Head of SEO is which constraint actually binds the agency right now. If client reporting is the weakest link, monitoring earns the seat. If brief-to-draft time is the bottleneck on a 25-account portfolio, a grader will not fix it. If the operations lead is one resignation away from being a single point of failure, the orchestration stack is already too fragile.
Google's own guidance is the discipline check before any contract gets signed: AI features run on standard search eligibility and quality signals 1. Tools that reinforce that property are investments. Tools that promise a parallel ranking lever are not.
 U.S. adults (18-64) who used generative AI by late 2024
U.S. adults (18-64) who used generative AI by late 2024
U.S. adults (18-64) who used generative AI by late 2024
Frequently Asked Questions
References
- 1.AI Features and Your Website | Google Search Central | Documentation | Google for Developers.
- 2.The Rapid Adoption of Generative AI - NBER.
- 3.Generative AI at Work - NBER.
- 4.AI Use at U.S. Businesses - Census Bureau.
- 5.Key findings about how Americans view artificial intelligence.
- 6.Workplace Adoption of Generative AI - NBER.
- 7.America’s AI Action Plan - The White House.
- 8.Global AI Adoption in 2025 – AI Economy Institute - Microsoft.
- 9.IAB/PwC Internet Advertising Revenue Report: Full Year 2025.
- 10.State of Data 2025: The Next Evolution of AI for Media Campaigns.
- 11.State of SEO in the AI Era - CSU Social Media Blog.
- 12.Is your website's content ready for AI search?.
- 13.Firm Data on AI - NBER Working Paper Series.