
Key Takeaways
- Clearscope enforces optimization discipline through SERP-grounded scoring, lifting editor output per hour without replacing the writing seat, though governance and approval gating remain light.
- MarketMuse strengthens the brief layer with entity coverage and competitive gap analysis, making it the strongest grounding choice for YMYL accounts where source attribution matters most 1.
- Surfer SEO pairs SERP-fit drafting with an audit module that detects decay and routes refreshes into the same workflow, fitting agencies with aging back catalogs.
- Frase compresses brief-to-draft handoff into one workspace for high-volume informational books, but editors must enforce the originality bar the platform will not police 2.
- Writesonic and Jasper deliver draft velocity but score lowest on research grounding, pushing verification cost back to editors and disqualifying them for YMYL client work.
- Vectoron inverts the category by building around the approval gate, with audit trails and live client signals that match the governance-as-value-driver framing 9.
What agency heads are actually buying when they buy an LLM SEO tool
The purchase is rarely a writer. It is a production system. An agency Head of SEO weighing an LLM SEO platform is buying compression of the strategy-to-publish loop across a portfolio of client accounts, where the unit of value is a ranked, refreshed, governed asset rather than a draft.
That framing matters because the category is crowded with tools that optimize the wrong variable. Faster drafting is cheap. Defensible throughput is not. Google's own guidance draws a working line between AI used to research and structure original content and the scaled production of low-value pages that may trigger the scaled content abuse policy 2. Every tool in this market sits somewhere on that line, and the buying decision is really a decision about where the agency's published work will sit.
McKinsey's analysis of generative AI in marketing and sales identifies the function as one of four areas accounting for roughly 75% of the technology's total value potential, but it also cautions that realized gains depend on redesigning workflows rather than dropping models into existing ones 13. The agencies that capture margin from LLM SEO tools are the ones treating them as workflow infrastructure, with research grounding, optimization fidelity, refresh cadence, governance, and per-asset unit economics evaluated together. The rest of this piece scores the leading options against that rubric.
The category reframed: governed throughput, not faster drafts
Why 'fastest writer' is the wrong evaluation axis
Draft speed is the easiest metric to demonstrate in a sales call and the least useful one to evaluate. Every modern LLM can generate a 1,500-word post in under a minute. What separates production systems is what happens before and after that minute: how the brief was assembled, what sources the draft was grounded in, who reviewed it, how it was optimized against live SERP signals, and how the asset is monitored for decay.
McKinsey's analysis of generative AI in marketing and sales is blunt on this point: realized productivity gains depend on redesigning workflows, not on inserting models into existing ones 13. An agency that buys a faster drafter without rebuilding its brief, review, and refresh loops will produce more mediocre content per analyst hour, not more ranked content per client dollar. Throughput without governance is a liability dressed as a feature.
Google's line between AI assistance and scaled content abuse
Google's published guidance is the constraint that defines this market. Generative AI is treated as legitimate when used for research, structuring, and assisting original work, and as a policy violation when used to mass-produce pages without added value 2. The scaled content abuse policy does not turn on whether AI was used. It turns on whether the output is original, useful, and additive to what already exists on the web.
Google's AI search guidance reinforces the same floor: unique, non-commodity content, sound page experience, crawlability, and valid structured data remain the determinants of visibility in AI experiences 3. Any LLM SEO tool an agency adopts must make it easier, not harder, to clear that bar across every client account. The evaluation question is whether the platform's defaults push output toward originality and usefulness, or toward volume that flirts with the abuse line. Tools that cannot answer that question concretely should not advance past the shortlist.
Adoption has crossed the threshold where governance, not access, is the differentiator
The buying question has changed because the adoption curve has changed. Stanford HAI's 2026 AI Index reports that generative AI reached roughly 53% population-level adoption within three years, while organizational adoption climbed to 88% 7. At those rates, access to large language models is no longer a competitive moat for an agency. Every client, every competitor, and every freelancer the agency might hire already has it.
What remains scarce is the operating discipline to turn that access into ranked, durable assets at portfolio scale. PwC's 2025 Responsible AI work frames responsible AI as a driver of business value rather than a compliance overhead, tying governance directly to ROI, efficiency, and trust 9. For an agency Head of SEO, that translates into a concrete shortlist criterion: the best LLM SEO tool is the one whose governance surface, including approval gates, source attribution, and review trails, is as developed as its generation surface.
The implication for vendor evaluation is straightforward. Demos that emphasize model choice, draft length, and template libraries are answering yesterday's question. Demos that show how a draft becomes an approved, attributed, monitored asset are answering the one that determines margin in a portfolio-scale book.
The five-criterion rubric for evaluating any LLM SEO tool
Research grounding: where the draft's facts actually come from
The first question to ask any vendor is mechanical: when the model writes a claim, what is it citing, and can the editor see the source before approving the line? Tools that pull from live SERP scrapes, structured knowledge bases, or first-party client data produce drafts an editor can defend. Tools that rely on the model's training memory produce drafts an editor has to re-research from scratch, erasing the throughput gain.
NIST's generative AI profile treats source attribution and traceability as core risk controls, not optional features 1. For agency work, that translates into a hard requirement: every factual sentence in a draft should map to a retrievable source the editor can open in one click. Grounding is the difference between assisted writing and supervised guessing.
SERP and AI Mode fidelity: optimizing for both surfaces
Optimization fidelity used to mean term coverage against the top ten results. That floor is now table stakes. Google's AI Mode began rolling out to U.S. users in May 2025, shifting a meaningful share of informational queries from a list of links to a synthesized answer with citations 12. Tools that score drafts only against blue-link competitors are optimizing for a shrinking surface.
Google's own AI search guidance is consistent on what wins in both surfaces: unique, non-commodity content, sound page experience, crawlability, and valid structured data 3. An LLM SEO tool should make those signals easier to ship at the asset level, not harder. The evaluation test is whether the platform surfaces schema gaps, entity coverage, and originality scoring inside the same workflow that produces the draft, or whether those checks live in three other tabs.
Refresh automation: keeping ranked assets ranked
Ranked content decays. The asset that earned position three in March drifts to position eight by November because competitors update, intent shifts, and SERP features rearrange. Agencies that treat publication as the finish line lose ground on their own back catalog while spending budget on new pages.
The relevant capability is automated decay detection paired with a refresh queue an editor can triage. The tool should flag which ranked URLs have lost positions, which queries have new SERP features, and which drafts need updated sources or examples. A platform that produces 200 new posts a quarter but cannot tell an agency which 30 of last year's posts need a 400-word update is solving the easier half of the problem.
Governance controls: approval gates, audit trails, attribution
Governance is where most LLM SEO tools quietly fail an agency-grade evaluation. The relevant features are not marketing checkboxes. They are the approval gate that prevents a draft from publishing without a named reviewer, the audit trail that records who changed what and when, the source attribution that survives export to the CMS, and the role permissions that keep a junior writer from pushing a YMYL post live for a healthcare client.
PwC's 2025 Responsible AI work positions governance as a value driver rather than a compliance tax, tying oversight directly to ROI, efficiency, and trust 9. NIST's AI RMF reinforces the same operating principle: accountability and traceability are the controls that make scaled AI output defensible 11. For an agency Head of SEO, the evaluation question is whether the platform's governance surface is as developed as its generation surface, or whether the controls are bolted on after the fact.
Unit economics: cost and time per published asset
The final criterion is the one most demos avoid. What does a published, approved, optimized asset actually cost on this platform, measured in editor hours plus license fees, divided by the number of assets that ship per month? Seat-based pricing favors agencies that produce a lot per seat. Credit-based pricing favors agencies with uneven output. Per-asset pricing favors no one but the vendor.
The honest comparison requires a baseline. An agency should know, before any demo, how many editor and SEO QA hours a typical client post consumes today. Without that number, every vendor's productivity claim is unfalsifiable. With it, the rubric collapses into a single defensible question: which tool moves the most assets across the approval gate per editor hour, at the quality bar Google's guidance requires 2?
 Visualize the five evaluation criteria as a structured rubric framework that readers can use to score any LLM SEO tool, directly mirroring the section's content
Visualize the five evaluation criteria as a structured rubric framework that readers can use to score any LLM SEO tool, directly mirroring the section's content
Experience AI-Driven SEO Content Production Now
Test real-time SEO content workflows and publish live results during your free trial, no commitment required.
The tools, scored against the rubric
Clearscope: optimization fidelity with editorial discipline
Clearscope earns its place by treating optimization as a constraint on writers rather than a replacement for them. Its grader scores drafts against term coverage, readability, and competitor depth pulled from live SERP data, which gives editors a defensible target rather than a vibe.
On the rubric, Clearscope is strong on SERP fidelity and weaker on autonomous drafting. Research grounding is partial: term recommendations come from ranked competitors, but the writer still supplies the facts. Refresh automation exists through content inventory scoring, though triage remains a manual editor task. Governance is light, with shared workspaces but no formal approval gate. Unit economics favor agencies that already have editors on payroll and need to lift their output per hour rather than replace the writing seat entirely. The line it helps clear is the originality and usefulness floor Google's guidance defines 3.
MarketMuse: research-grounded briefs that survive editor review
MarketMuse leans into the brief layer, which is where most agency rework actually accumulates. Its topic models map entity coverage, related subtopics, and competitive gaps before a word is drafted, producing briefs an editor can hand to a writer without rebuilding from scratch.
Research grounding is the strongest line on the rubric here. The platform surfaces what the top-ranking pages cover, what they omit, and which entities a draft must address to compete. SERP fidelity is solid through its content scoring. Refresh signals exist through inventory analysis, though the editor still owns the queue. Governance is workspace-level, not approval-gated. The unit economics work for agencies whose throughput bottleneck is brief quality rather than draft generation, particularly on YMYL accounts where the source-attribution discipline NIST's framework treats as a core risk control matters most 1.
Surfer SEO: SERP-fit drafting paired with content audit loops
Surfer combines a drafting interface with on-page scoring and a separate audit module for existing URLs. The audit loop is the differentiator. It scans ranked pages for term drift, structure gaps, and internal link opportunities, then routes them into a refresh worklist.
On SERP fidelity, Surfer is competitive with Clearscope. Research grounding leans on competitor analysis rather than first-party sources, which keeps editors in the verification seat. The refresh automation criterion is where Surfer scores best in this comparison: decay detection and rewrite prompts are part of the same workflow that produces new drafts, not a separate tab. Governance remains light, with no formal approval routing. Unit economics favor agencies running heavy refresh cycles on aging client back catalogs, where the cost of letting ranked URLs decay quietly exceeds the cost of the seat itself.
Frase: brief-to-draft compression for high-volume client books
Frase compresses the brief-to-draft handoff into one workspace. It pulls SERP data, generates an outline, and drafts against that outline in the same surface where the editor reviews. For agencies running dozens of mid-funnel posts a month across similar verticals, the workflow consolidation is the value.
SERP fidelity is solid, research grounding is functional but lighter than MarketMuse, and refresh signals are basic. Governance controls are minimal. Where Frase wins on unit economics is throughput per editor on commodity informational content, the segment where Google's distinction between AI-assisted originality and scaled abuse is most easily violated 2. Editors using Frase have to set the originality bar themselves; the platform will not enforce it.
Writesonic and Jasper: draft velocity, weaker on grounding
Writesonic and Jasper sit in the general-purpose AI writer category and are included here because agency heads still encounter them in client tech stacks. Both produce drafts quickly, support brand voice training, and integrate with common publishing tools.
Against the rubric, both score lowest on research grounding. Drafts pull from model memory more than from live, attributable sources, which pushes the verification cost back onto the editor. SERP fidelity exists through add-ons rather than as a native scoring layer. Refresh automation and governance are minimal. Unit economics look attractive on the seat line and worse on the editor-hour line, which is the one that actually determines margin. For an agency book with any YMYL exposure, the grounding gap is the disqualifier.
Vectoron: approval-first execution across channels
Vectoron is built around the approval gate rather than the drafting surface, which is the inversion most of this category needs. Specialist strategists for content, SEO, backlinks, PPC, social, and call intelligence surface ranked recommendations into a Command Center, and nothing publishes until a named human approves it.
On the rubric, the strongest line is governance. Approval routing, audit trails, and the strategic reasoning attached to each recommendation map directly onto the controls PwC frames as value drivers rather than compliance overhead 9. Research grounding pulls from live client signals, including qualified calls and pipeline data, rather than only SERP scrapes. SERP and AI Mode fidelity, refresh cadence, and unit economics are evaluated in the same workflow as production. For an agency Head of SEO running a multi-client book where every approval has to be defensible, the platform answers the rubric's hardest question first.
The consolidation economics of governed LLM production
The honest way to model the savings is to start with a baseline of editor hours, not vendor claims. A typical mid-funnel client post moving through a specialist-led pipeline consumes briefer hours, writer hours, editor hours, and SEO QA hours. Call that total H. Per-asset cost is H multiplied by blended hourly rate, plus a share of license and overhead. None of those variables require invented dollars to compare two production models honestly.
The St. Louis Fed's analysis offers the directional input. Workers using generative AI reported saving 5.4% of work hours in the previous week, which implies roughly a 1.1% increase in aggregate productivity once non-users are factored in 5. Both figures are self-reported and population-level, not benchmarks for an agency content pipeline. Applied as a directional multiplier rather than a guarantee, 5.4% off a 30-hour-per-week editor's load is closer to 1.6 hours recovered, not a headcount reduction.
The consolidation gain compounds when the same governed workflow runs across a portfolio. An editor who saves 1.6 hours per week on one account saves a defensible multiple of that across ten. The math only holds, however, if the platform clears Google's originality and usefulness floor on every asset 2. A tool that doubles editor throughput while pushing output toward the scaled abuse line converts hours saved into reputational risk, not margin.
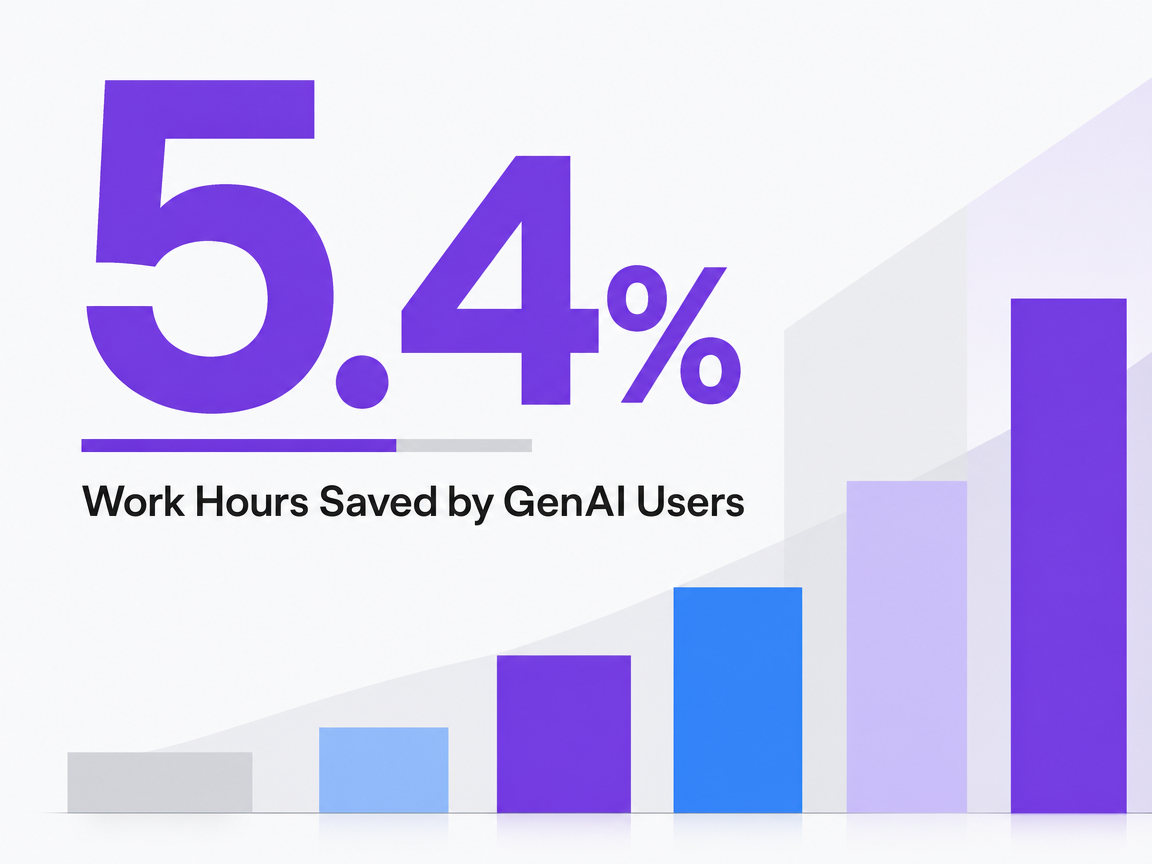 Work Hours Saved by GenAI Users
Work Hours Saved by GenAI Users
Work Hours Saved by GenAI Users
If you manage multiple client locations or franchise portfolios
The economics change when the unit of work is not one client site but a network of 40, 200, or 2,000 location pages sharing a parent brand. Multi-location agency books, franchise marketing leads, and DSO or MSO content teams operate on a template-plus-localization model, where a single approved structure has to flex across markets without flattening into duplicate content.
That is the workflow LLM SEO tools were built for, and the adoption data confirms how widespread the pattern has become. The AMA's January 2025 survey of marketers found nearly 90% had used generative AI at work, 71% used it weekly or more, and nearly 20% used it daily 4. Template-plus-localization is no longer an experimental tactic on the edge of the agency. It is the median way mid-funnel location content gets produced.
The rubric still applies, but two criteria carry more weight. Research grounding has to extend to local signals, not just SERP scrapes: service area boundaries, market-specific intent variants, and first-party data from each location's call and booking flows. Governance has to scale to per-market approval, so a regional manager can sign off on their own pages without bottlenecking at the central editor. Tools that treat 200 location pages as 200 independent drafts will burn the editor hours the template was supposed to save.
See How Leading Agencies Scale SEO With LLM-Driven Automation—No Additional Headcount
Request a walkthrough of enterprise-grade, AI-orchestrated SEO workflows that deliver consistent, measurable results across all client portfolios while maintaining full oversight and approval control.
What human editors still own in the loop
Even the best LLM SEO tool offloads production, not judgment. Three decisions stay with the editor, and each one is where ranked, defensible work is actually made or lost.
- The first is source verification. NIST's generative AI profile treats traceability as a core risk control, which in practice means an editor opens the cited page and confirms the claim before it ships 1.
- The second is originality calibration. Google's guidance is explicit that AI-assisted research and structuring is acceptable, while volume without added value is not, and only a human can decide whether a draft clears that bar against what already ranks 2.
- The third is strategic framing: the angle, the audience assumption, the internal link logic, and the call the draft is supposed to support.
A platform that pretends to own these decisions is selling risk. A platform that exposes them in a clean approval surface is selling time.
How to run a 60-day evaluation across two client accounts
A vendor demo proves the platform can produce a draft. A 60-day pilot proves whether it moves assets across the approval gate at the agency's quality bar. The shortest defensible test runs two client accounts in parallel: one informational mid-funnel book where draft velocity matters, and one YMYL or local-services account where source attribution and governance matter more.
Set the baseline first. Count editor and SEO QA hours per published asset in the prior 60 days, log positions on a fixed query set, and capture the share of drafts that required substantive rework. Days 1 through 30 run the tool on net-new production. Days 31 through 60 run it on refresh cycles against ranked URLs that have slipped. The decision criteria are concrete: hours per approved asset, share of drafts clearing originality and usefulness review on first pass 2, and position recovery on the refresh cohort. A tool that wins on velocity but loses on first-pass approval is shifting cost from drafting to editing, not removing it.
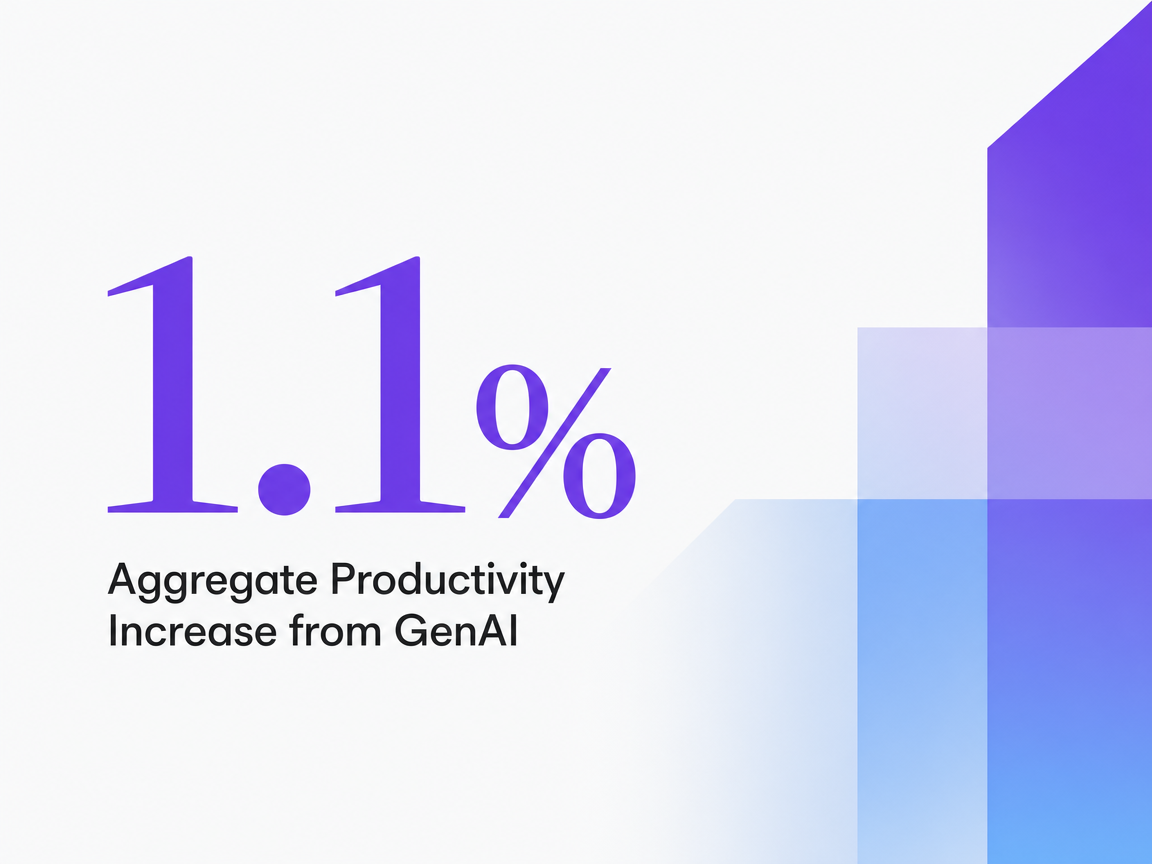 Aggregate Productivity Increase from GenAI
Aggregate Productivity Increase from GenAI
Aggregate Productivity Increase from GenAI
Frequently Asked Questions
References
- 1.Artificial Intelligence Risk Management Framework.
- 2.Google Search's guidance on using generative AI content on your website.
- 3.Top ways to ensure your content performs well in Google's AI experiences on Search.
- 4.Generative AI Takes Off with Marketers.
- 5.The Impact of Generative AI on Work Productivity.
- 6.The 2025 AI Index Report.
- 7.Artificial Intelligence Index Report.
- 8.The Projected Impact of Generative AI on Future Productivity Growth.
- 9.PwC's 2025 Responsible AI survey: From policy to practice.
- 10.AI Governance Profession Report 2025.
- 11.AI Risk Management Framework | NIST.
- 12.AI in Search: Going beyond information to intelligence.
- 13.Marketing and sales soar with generative AI.
- 14.The economic potential of generative AI: The next productivity frontier.
- 15.Key Insights From The Forrester Experience Optimization Solutions Wave, Q4 2024.