
Key Takeaways
- Profound delivers enterprise-grade citation share tracking with documented engine versions and prompt panels, making period-over-period movement defensible when a client's CFO scrutinizes methodology.
- Peec AI anchors on mention share across a portfolio view, helping agencies spot decaying accounts before renewal calls, though answer saturation reporting requires supplementing outside the tool.
- Otterly.AI offers prompt-level granularity that suits verticals where a few high-value queries drive pipeline, but it stops at monitoring and leaves the revise-evaluate steps to the agency.
- AthenaHQ measures answer saturation alongside brand-risk overlays like sentiment and misattribution flags, which gives legal and compliance reviewers something concrete to engage with in regulated verticals.
- Vectoron operates as an execution platform rather than a monitor, routing visibility-driven revisions through a human approval step that maps to the analyze-revise-evaluate loop 6, with a $599/mo trial anchor.
Why citation share replaced rank as the agency-side ROI metric
The blue link is no longer the unit of distribution. Answer engines now assemble synthesized responses that cite a handful of sources, and those citations decide whether an agency's client gets named in the answer or paraphrased into invisibility. That single shift is why agency P&Ls are being rebuilt around citation share rather than keyword rank.
Forrester reports that 90% of B2B marketing leaders treat AI visibility as at least an investment-level priority, based on its survey of B2B marketing leaders 2. The scope matters: this is buyer-side B2B marketing, not a cross-industry consumer panel, and it measures stated priority, not realized spend. Even narrowed that way, it tells agency owners what their clients will be asking about in the next renewal conversation.
The reframing is sharper in Forrester's companion analysis, which argues that AI answer engines create a visibility gap traditional traffic reports cannot fill, pushing measurement toward influence and answer inclusion 3. Forrester's answer-engine optimization guide goes further and names the two metrics agencies should be reporting on: citation share and answer saturation 4.
For an agency owner, the operational consequence is direct. Rank-tracking retainers were billed against a measurable artifact, the SERP position. Citation-share retainers must be billed against a measurable artifact too, or margin erodes the moment a client asks what they paid for. The right LLM visibility analysis tool is the one that produces that artifact in a format clients accept in a quarterly business review.
 B2B Marketing Leaders Prioritizing AI Visibility
B2B Marketing Leaders Prioritizing AI Visibility
B2B Marketing Leaders Prioritizing AI Visibility
The three axes that actually separate visibility tools
Measurement rigor: citation share, answer saturation, and reproducibility
Most vendor demos lead with a number. The harder question is whether that number can be reproduced next Tuesday by a different analyst running the same prompts. Measurement rigor is the first axis because every downstream ROI claim depends on it.
Three things separate rigorous tools from dashboard theater. First, citation share and answer saturation must be defined and tracked the way Forrester's answer-engine guide describes them, as the share of AI answers that name the client and the proportion of relevant prompts where the brand appears at all 4. Second, those metrics must be measured across multiple engines, since generative engines have different preferences and rewards for the same content 7. Third, the underlying methodology must be reproducible.
That last point is where most vendors quietly fail. NIST's evaluation workshop summary calls for agreed-upon metrics, disaggregated analysis, and reproducible setups as the foundation of credible AI measurement 9. Public NIST commentary on retrieval-augmented systems goes a step further, recommending that retriever and generator components be evaluated individually and together 10. A visibility tool that cannot explain its prompt panel, refresh cadence, and engine version stack is producing a single-run snapshot, not a measurement system. Agency owners should treat that as a disqualifier when the client asks how the number was derived.
Action layer: observation vs. an analyze-revise-evaluate loop
A dashboard that tells an agency citation share dropped 12 points in the last month is a smoke detector, not a fire extinguisher. The second axis sorts tools by whether they close the loop from signal to executed content change.
The clearest blueprint comes from the content-centric generative search optimization framework, which describes an analyze-revise-evaluate loop driven by specialist agents and a selector agent that picks the best revision before publishing 6. Analyze identifies which passages or pages are underperforming in AI answers. Revise generates targeted content changes — citations added, statistics inserted, structure tightened. Evaluate re-checks the change against the same prompt panel to confirm lift, or rolls it back.
That loop is the operational dividing line. Pure monitoring tools stop at analyze and hand the rest to the agency's production team, which means the margin gain depends on how cheaply the team can produce revisions. Tools that instrument revise and evaluate inside the same workflow compress the cycle and remove the briefing-to-publish lag that erodes retainer profitability. For an agency running 30-plus client briefs a quarter, the difference between observing a problem and shipping a fix in the same system shows up directly in fulfillment cost per account.
Client reporting defensibility: what survives a skeptical QBR
The third axis is the one most agencies underweight until a client's CFO joins the call. A visibility metric is only as good as the agency's ability to defend it under cross-examination from someone who did not buy the narrative.
Defensibility has three components. The report must connect visibility to influence rather than traffic, the framing Forrester argues replaces the old click-based accountability model 3. It must disclose scope: which engines were queried, how many prompts were in the panel, what the refresh window was, and which prompts represented buyer-intent moments versus brand-awareness moments. And it must show period-over-period movement with the methodology held constant, so a citation-share gain is not actually a quiet panel change.
Tools vary widely here. Some export PDF-ready client decks with engine breakouts and prompt categories already labeled. Others expose raw API data and expect the agency to build the reporting layer. Both can work, but the second model only pencils out when an agency has the analyst capacity to maintain reporting templates across a portfolio. The right tool reduces, not expands, the QBR prep hours billable against retainer margin.
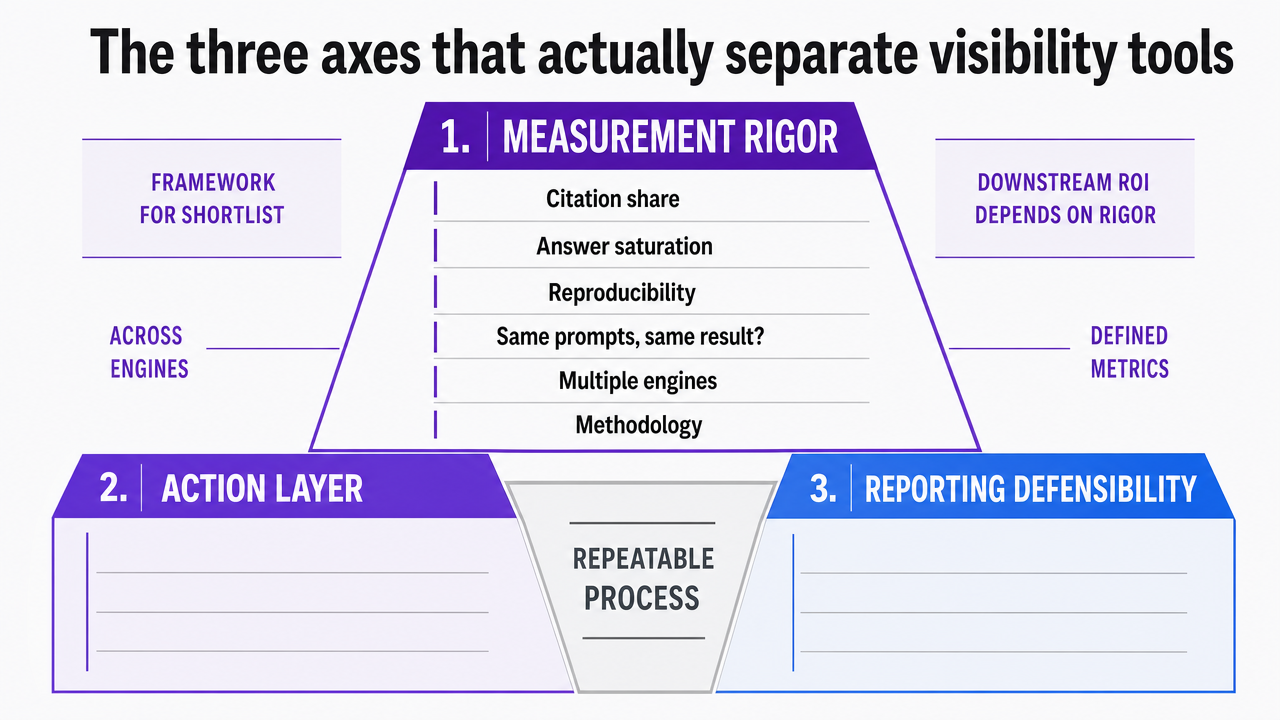 Visualize the three evaluation axes (Measurement Rigor, Action Layer, Reporting Defensibility) as a comparison framework that organizes the rest of the article's tool shortlist
Visualize the three evaluation axes (Measurement Rigor, Action Layer, Reporting Defensibility) as a comparison framework that organizes the rest of the article's tool shortlist
What moves citation share, and why tools must instrument it
Citation share is not won by trying harder on the same content. It is won by editing the page in ways that generative engines reward, then measuring whether the edit changed inclusion in the next query cycle. That is why the action layer inside a visibility tool only earns its keep if it knows what to edit.
The clearest signal comes from the foundational GEO study, which tested specific content modifications against generative engine answers. Adding citations, inserting direct quotations, and embedding statistics each produced relative improvements of about 30 to 40 percent on Position-Adjusted Word Count, and 15 to 30 percent on Subjective Impression, across the prompts and engines tested in the paper 1. The scope is important: this was a controlled academic evaluation, not a longitudinal field study, and the lift was measured on the paper's own metrics. Still, it is the most durable evidence agencies have for what to instrument at the page level.
Two adjacent research threads sharpen the picture. The 2025 comparative analysis of AI search behavior recommends prioritizing earned media, authority signals, and scannable structure as inputs generative engines reach for when assembling answers 5. Separate work on engine preferences shows those signals are not weighted identically across models, which is why a credible tool monitors more than one engine and reports per-engine deltas 7.
The operational read for an agency is narrow. A visibility tool that surfaces citation share without telling the production team which of those levers — sources, quotations, statistics, authority, structure — is underweight on a given page leaves the revision step to guesswork. Instrumenting the lift drivers at the URL level is what turns a monitoring dashboard into a brief the content team can actually execute against.
 Visualize the GEO study's measured lift from content modifications (cite sources, quotation addition, statistics addition), which is directly cited in the surrounding prose with the 30-40% and 15-30% figures
Visualize the GEO study's measured lift from content modifications (cite sources, quotation addition, statistics addition), which is directly cited in the surrounding prose with the 30-40% and 15-30% figures
Test Real-Time LLM Visibility Insights Instantly
Validate LLM-driven content visibility on live campaigns before making a long-term commitment.
The shortlist: five tools scored on the three axes
Profound: enterprise-grade citation share with strong reporting
Profound sits at the top of the measurement-rigor axis. It tracks citation share across multiple answer engines, exposes the underlying prompt panels, and produces engine-by-engine breakouts that hold up in a client deck without heavy analyst rework. For agencies serving enterprise accounts, that disclosed scope is the difference between a defensible number and a screenshot.
The action layer is thinner. Profound surfaces which URLs are losing citation share and flags content gaps, but the revise step lives in the agency's production stack. Teams that already run a tight content workflow can absorb that handoff. Teams running 20-plus retainers will feel the briefing-to-publish lag that Forrester's answer-engine guide identifies as the operational cost of treating visibility as a separate reporting layer 4.
Reporting defensibility is where Profound earns its retainer. Engine versions, refresh windows, and prompt categories are documented, which lets agencies hold methodology constant across quarters and defend period-over-period movement when a CFO asks how the lift was measured.
Peec AI: mention share monitoring built for portfolio tracking
Peec AI is built for the agency owner running a portfolio rather than a single brand. Mention share is its anchor metric, tracked per client and rolled up into a portfolio view that makes it easier to spot which accounts are decaying before a renewal call surfaces the problem.
Measurement rigor is solid on the mention-share side but thinner on answer saturation, the second metric Forrester's guide names as core 4. Agencies that report on saturation will need to supplement with prompt-panel work outside the tool. Multi-engine coverage is present, which matters because generative engines do not weight the same content signals identically 7.
The action layer is observational. Peec AI tells agencies which prompts are losing the client, not which on-page levers — citations, quotations, statistics, authority signals — are underweight. That gap pushes the diagnostic work back onto the strategist. Reporting defensibility is strong at the portfolio level, weaker on per-account methodological disclosure.
Otterly.AI: prompt-level visibility with lighter execution coupling
Otterly.AI leads with prompt-level granularity. Agencies can define the buyer-intent prompts that matter for a client and watch inclusion shift query by query, which is useful when a single high-value prompt drives most of the pipeline conversation in verticals like legal or behavioral health.
Measurement rigor is respectable on prompt-level tracking, though documentation of refresh cadence and engine version stacks is less complete than enterprise peers. NIST's evaluation workshop summary names reproducible setups as the foundation of credible measurement, so agencies should pin down those details in the sales cycle rather than assume them 9.
Execution coupling is intentionally light. Otterly.AI is a monitoring product, not a workflow platform, and it does not instrument the revise-evaluate steps that compress the cycle from signal to shipped change. Agencies with a fast in-house content pod can run it as a feeder into existing production. Agencies stretched thin will feel the gap as fulfillment cost per account.
AthenaHQ: answer saturation analytics with brand-risk overlays
AthenaHQ approaches the category from the saturation side. It measures the proportion of relevant prompts where the brand appears at all, then layers brand-risk signals on top — sentiment in AI answers, competitor co-mention, and misattribution flags. For high-stakes verticals where an inaccurate AI answer is a legal or clinical liability, that overlay is more than cosmetic.
Measurement rigor is strong on saturation and competitor mapping. Citation-share reporting is present but secondary to the saturation lens, which means agencies pairing AthenaHQ with a citation-led tool get the fuller Forrester-aligned picture 4. Multi-engine coverage holds up.
The action layer is consultative rather than instrumented. AthenaHQ flags risk events and saturation gaps; the revise step lives with the agency. Reporting defensibility is one of the strongest in the shortlist for risk-conscious clients, because the brand-risk overlays give legal and compliance reviewers something concrete to engage with during QBRs.
Vectoron: visibility-aware execution layer at $599/mo trial
Vectoron is the outlier in the shortlist because it is not a pure monitoring tool. It is an execution platform that treats citation share and answer saturation as inputs into a content workflow, then routes proposed revisions through a human approval step before publishing. That maps directly onto the analyze-revise-evaluate loop the content-centric GEO framework describes as the operational shape of credible optimization 6.
Measurement rigor depends on the agency configuring the prompt panel and engines to cover the client's buyer-intent moments; the platform does not impose a fixed methodology. The action layer is the differentiator. Specialist strategists for content, SEO, and backlinks surface ranked recommendations tied to visibility deltas, and approved work executes without a separate briefing cycle.
Reporting defensibility comes from the audit trail: every recommendation includes its reasoning, every change is logged against the visibility metric it was meant to move. Trial pricing is $599/mo after a two-week evaluation, which is the one fixed dollar anchor in this comparison.
ROI math: from citation share to booked revenue
Citation share only matters if it translates into something a client's finance team will sign off on. The math is straightforward once an agency commits to the variables it can actually measure, and refuses to fabricate the ones it cannot.
Four stages connect the dots:
- Citation share on buyer-intent prompts
- Answer inclusion frequency on the engines clients use
- Qualified call or form volume attributable to those AI touchpoints
- Booked revenue per qualified lead
Forrester's case for replacing traffic with visibility as the accountability metric only holds up if the agency can show each handoff between those stages with a defensible number 3. Skip a stage and the model collapses into vibes.
The first conversion is the riskiest. A citation-share lift on a prompt panel of 200 buyer-intent queries means little unless those prompts represent how real prospects ask. Agencies should weight prompts by client-side data — call recordings, chat transcripts, intake forms — and treat unweighted panel gains as a directional signal, not a billable outcome. The Forrester answer-engine guide makes the same point in different words: saturation and citation share need scope to mean anything in a deck 4.
The second conversion is where most ROI claims break. Answer inclusion does not equal click. Zero-click behavior, which Forrester flags as a defining feature of the 2026 operating context, means a meaningful share of value shows up as brand recall, branded search, or direct calls weeks later 12. Agencies serving legal, dental, and behavioral health clients should instrument call tracking with AI-source self-report questions on intake to capture what attribution platforms miss.
The third conversion — qualified lead to booked revenue — is the client's existing math. The agency's job is to feed it cleanly, not reinvent it.
If you manage multi-location portfolios: consolidation economics
The math changes when a single client owns 12 dental practices, 40 law firm offices, or 80 home services territories. At that scale, the cost of running a separate visibility monitoring tool plus a content production stack plus a reporting layer per location stops being a line item and starts being a margin problem. This section is for agency owners running portfolio accounts, not single-brand engagements.
Multi-location work introduces three economics nobody talks about in vendor demos:
- Prompt panels multiply: a 200-prompt panel per location across 40 locations is 8,000 prompts to refresh, and per-prompt pricing models punish that volume.
- The revise step compounds: a citation-share gap flagged on 12 locations means 12 briefs, 12 production cycles, and 12 QA passes unless the workflow is consolidated.
- Reporting must roll up to the parent and drill down to the location, which is where most monitoring tools quietly fall over.
Forrester's 2026 framing names scaling content creation with AI as one of the operating themes agencies should be solving for, alongside zero-click search and content impact evaluation 12. The portfolio case is where that scaling pressure is most acute.
| Variable | Plug-in value |
|---|---|
| Locations in portfolio | L |
| Monthly content units per location | U |
| Citation-share lift target (percentage points) | C |
| Qualified calls attributable to AI answers per location | Q |
| Tool + execution cost per location per month | $T (Vectoron trial anchor: $599/mo) |
Run the numbers with the client's actual L, U, Q, and the math reveals whether a consolidated workflow beats a stack of point tools at the portfolio level.
See How AI-Powered LLM Visibility Analysis Delivers Tangible ROI for Agencies
Request a live walkthrough of AI-driven visibility analytics purpose-built for agencies managing multi-channel campaigns. Evaluate performance, track ROI, and compare tool capabilities with real data from enterprise-scale use cases.
Vetting vendors against emerging evaluation standards
Vendor benchmarks are not yet trustworthy as the sole basis for tool selection. NIST's 2026 GenAI Text Challenge evaluation plan, which tests Generator, Prompter, and Discriminator tracks, makes plain that standardized GenAI measurement is still being built in public 11. Agencies signing annual contracts on the strength of a vendor's internal benchmark are buying methodology that has no external peer.
Three diligence questions cut through the marketing:
- Does the vendor evaluate retriever and generator components separately, the way NIST's public commentary on retrieval-augmented systems recommends, or does it report one composite score that hides where errors originate 10?
- Are the metrics disaggregated by engine, prompt category, and refresh window, per the reproducibility standards NIST's measurement workshop outlines 9?
- Can the vendor produce the same number on the same prompt panel six weeks later, with version stamps on the engines queried?
Tools that pass those three checks survive a client's internal AI governance review. Tools that cannot will fail it the first time a regulated client — a hospital system, a law firm's general counsel, a DSO's compliance lead — asks how the citation-share figure was produced. Add those questions to the vendor RFP before the pilot, not after.
How to choose, in one operator-level decision
The shortlist collapses into one question: does the agency need a sharper measurement layer, or a shorter cycle from signal to shipped revision? That is the operator-level decision, and it sorts the five tools cleanly.
Agencies with strong in-house production and enterprise reporting demands should lean toward the measurement-first tools — Profound for citation share, AthenaHQ for saturation and brand risk, Peec AI for portfolio mention tracking, Otterly.AI for prompt-level granularity. Pair one of these with the existing content workflow and bill the analyst hours separately.
Agencies where fulfillment cost per account is the binding constraint should weight the action layer instead. An execution platform that instruments the analyze-revise-evaluate loop inside one approval workflow 6 compresses the briefing-to-publish lag that quietly eats retainer margin. Vectoron fits that case, with its $599/mo trial as the entry point. Pick the axis where margin is leaking, and the tool choice follows.
Frequently Asked Questions
References
- 1.GEO: Generative Engine Optimization.
- 2.AI Search Will Crack The Foundation Of B2B Marketing's ....
- 3.Stop Replacing Traffic. Start Replacing Visibility..
- 4.Win Visibility In AI Search With Answer Engine Optimization.
- 5.Generative Engine Optimization: How to Dominate AI Search.
- 6.Driving Generative Search Engine Optimization with Content-Centric ....
- 7.What Generative Search Engines Like and How to Optimize Web ....
- 8.Trustworthy AI: Managing the Risks of Artificial Intelligence.
- 9.Artificial Intelligence Measurement and Evaluation Workshop Summary Report.
- 10.RFI for NIST AI Executive: ref Order-88 FR 88368.
- 11.2026 NIST GenAI Text Challenge Evaluation Plan.
- 12.Build Your AI Visibility Strategy At B2B Summit.