
Key Takeaways
- Agency portfolios need a visibility stack, not a hero tool, because classifiers, watermarks, and provenance each fail differently under multilingual writers, paraphrase-heavy edits, and legal review 6.
- Classifier detectors belong at pre-publish triage only, since Stanford found 61.22% of non-native English essays misclassified as AI 1and simple prompts bypass them 2.
- Named tools like GPTZero, Originality.ai, Turnitin, Copyleaks, and Sapling work best run in pairs, acting only on intersecting high-confidence flags rather than single noisy scores.
- Interpretable style-feature detection gives reviewers human-readable cues like sentence uniformity or low lexical variety, which survive client conversations better than an opaque probability percentage 3.
- WaterBench and MarkLLM benchmark watermark schemes but confirm they only trace first-party content from instrumented models, not arbitrary third-party text arriving in review queues 6.
- Watermarks face an unavoidable trade-off: aggressive schemes degrade text quality while subtle ones get stripped by ordinary editing, localization, or CMS rewrites 5.
- C2PA Content Credentials carry client-facing defensibility because the signed manifest is verifiable rather than probabilistic, making it the artifact to forward during compliance reviews 7.
- NIST-aligned evaluation keeps the stack honest by requiring written objectives, portfolio-based test sets, logged configurations, and segmented false-positive reporting by writer profile 8.
- Adversarial robustness is now a 2026 evaluation requirement, with NIST's CAISI naming indirect prompt injection in-scope and quarterly retesting against paraphrased content the working bar 9.
- A portfolio decision matrix assigns each layer to its workflow stage: triage, first-party generation, client handoff, and vendor selection, rather than ranking layers against each other.
- Regulated-vertical clients in healthcare or legal need C2PA baselines and quarterly adversarial retests, since medical LLMs failed prompt-injection attacks in 94.4% of primary decision turns 11.
- Governance sits above the four layers, routing conflicting signals through an approval gate with documented reasoning, the posture NIST's GenAI Profile prescribes for deployments at this exposure 10.
Why agency portfolios need a visibility stack, not a single detector
The question "what is the best LLM visibility checking tool" has the wrong shape. No single classifier, watermark, or provenance signal survives the conditions an agency Head of SEO actually faces: dozens of client accounts, multilingual writers, paraphrase-heavy editorial workflows, and legal teams who want a defensible answer before publication. The research record is unambiguous on this. Popular detectors misclassify large shares of non-native English writing as machine-generated 1, simple prompting strategies bypass them 2, and detectors should not be used as the sole means of assessing AI authorship in high-stakes domains 4.
Watermarking does not rescue the problem on its own either. Common design choices leave watermark schemes susceptible to removal and spoofing, with sharp trade-offs between robustness, detectability, and text quality 5. The most credible technical surveys argue for a layered approach that combines statistical signals, metadata, and provenance attestations rather than a hero tool 6.
That is the working premise for the rest of this evaluation. Visibility checking at portfolio scale is a stack of four layers:
- Classifier detection for triage
- Watermark schemes for first-party tracing
- C2PA Content Credentials for client-facing defensibility 7
- NIST-aligned evaluation protocols to test whether any of it holds up under adversarial pressure 8
Each layer fails differently. The agencies running this well decide in advance which layer answers which workflow question, then govern the combination.
Layer one: classifier detectors for triage, not verdicts
Where classifiers break under client-scale traffic
Classifier detectors are the cheapest layer to deploy and the most dangerous to trust as a verdict. The Stanford HAI evaluation of seven popular GPT detectors against 91 TOEFL essays written by non-native English speakers found that detectors misclassified 61.22% of those essays as AI-generated, while the same tools classified essays from U.S.-born eighth-graders with near-perfect accuracy 1. The study was narrow in scope, but the disparity is the part that matters for an agency portfolio. A detector that scores well on clean native-English samples can still produce a false-positive rate above half on writers whose first language is not English.
The peer-reviewed companion study reaches the same conclusion and adds a second failure mode: simple prompting strategies, such as asking the model to write in more literary English, both reduced bias and allowed AI-generated text to slip past the same detectors 2. That cuts in two directions. Agencies cannot rely on classifier output to certify human authorship for a client legal team, and they cannot rely on it to catch AI use by a contractor who has read the same papers.
The University of Chicago analysis of scientific abstracts reached the operational version of this point: detectors are useful as signals but should not be the sole means of assessing AI authorship 4. For a Head of SEO running content across dozens of accounts, that reframes the role of classifier detectors entirely. They are a triage filter, not a compliance instrument. Output should be treated as a priority queue for human review, not as evidence to forward to a client.
Named tools worth running for pre-publish triage
Treated as triage, classifier detectors earn their place in a pre-publish review queue. The candidates an agency editorial lead encounters most often are:
- GPTZero
- Originality.ai
- Turnitin's AI writing indicator
- Copyleaks AI Content Detector
- Sapling's detector
Each produces a probability score and, in some cases, a sentence-level highlight. None of them is a verdict instrument under the evidence cited above, but each can shorten a reviewer's path to the suspect passages in a long draft.
The agency configuration that holds up is running two detectors in parallel and treating only the intersection of high-confidence flags as worth a human read. Single-tool scores are too noisy to act on, particularly for content drafted by non-native writers or heavily paraphrased from briefs 1, 2. The intersection approach reduces the false-positive load on reviewers without pretending the underlying classifiers have become reliable.
Three configuration choices matter at portfolio scale:
- Disable any auto-action on detector output, because the bypass demonstrations in the peer-reviewed work mean a quiet block-on-flag policy will both miss real AI and punish legitimate writers 2.
- Log the model version and threshold used at each scan, because vendor models change without notice and a probability score is only interpretable against a known configuration.
- Never forward raw detector scores to a client as evidence of authorship. The Chicago analysis is explicit that detectors should not stand alone in authorship assessment 4, and a forwarded screenshot is a liability waiting for a non-native writer to appear in a portfolio account.
Interpretable style-feature detection as a reviewer aid
The detectors above return a probability and little else. A Stanford CS224N project on style-feature detection took a different route, building a classifier that labels text as human, AI, or mixed and exposes the stylistic cues driving the decision 3. The authors report that their interpretable model outperformed baseline detectors on classification tasks while producing human-readable explanations of the signals it used.
That matters for editorial review. A reviewer looking at a highlighted passage with a stated reason, such as unusually uniform sentence length or low lexical variety, can make a judgment call in seconds. The same reviewer staring at a 0.87 probability score with no rationale either trusts the number or ignores it. Interpretable signals also survive the conversation with a client brand team better than an opaque percentage, because the reviewer can describe what the tool noticed rather than what the tool concluded.
For an agency stack, style-feature detection sits behind the triage layer as a reviewer aid, not a gate. It does not replace the probability-score tools, but it gives the human in the loop something to act on when a draft lands in the review queue with conflicting signals from the first-pass detectors.
 Percentage of TOEFL essays by non-native speakers misclassified as AI-generated
Percentage of TOEFL essays by non-native speakers misclassified as AI-generated
Percentage of TOEFL essays by non-native speakers misclassified as AI-generated
Layer two: watermark schemes for first-party content tracing
What WaterBench and MarkLLM actually measure
Watermarking sits one layer deeper than classifier detection because it does not try to guess whether arbitrary text came from a model. It asks a narrower question: did this specific text come out of a model the agency or its vendors instrumented? Brookings frames the mechanism plainly, describing how watermark schemes embed statistical signals into model outputs and weigh trade-offs between robustness, detectability, and impact on utility 6. WaterBench and MarkLLM are the two reference points an agency editorial lead is likely to encounter when evaluating vendors that claim watermark support. WaterBench is a benchmarking effort for LLM watermark algorithms; MarkLLM is an open toolkit that implements multiple schemes under a common interface. Both exist to make watermark claims comparable rather than to provide a single verdict.
For an agency, the operational read is that these tools measure detection rate, false-positive rate, and text-quality impact across watermark configurations, not whether any single product is secure for client work. A vendor that says "we watermark our outputs" is making a first-party tracing claim about content their own models generated. That is useful for portfolio audits and contractor verification, where the agency controls the generation pipeline. It is not useful for detecting AI text written by third parties using uninstrumented models, which is most of the content arriving in a typical review queue 6.
Spoofing, paraphrase, and the trade-off no watermark escapes
The CMU analysis of watermark design choices is the cleanest summary of why this layer cannot stand alone. The authors show that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to watermark removal or spoofing 5. Removal means a downstream editor, paraphrasing pass, or translation step strips the statistical signal the watermark relied on. Spoofing means an adversary forges the signal in text the watermarked model never produced, which can drag a human writer into a false flag. Neither failure mode is exotic. Both happen under ordinary editorial workflows, where a draft passes through a human editor, a localization pass, and a CMS rewrite before publication.
The trade-off the CMU work documents is sharper than "some watermarks are better than others." Aggressive watermarks that survive paraphrase tend to degrade text quality enough that brand and SEO teams will reject the output. Subtle watermarks that preserve quality tend not to survive the edits a normal agency process applies before publish 5. Brookings reaches the same conclusion from the policy side, arguing that watermarking should be combined with metadata, signatures, and detection rather than treated as a sufficient signal on its own 6.
For a Head of SEO, this confines watermarking to a specific job: tracing first-party content through pipelines the agency controls end to end. Treat watermark hits as evidence the agency's own instrumented models produced a passage, and treat watermark misses as uninformative. Anything broader is overreach the underlying research does not support.
Test LLM visibility workflows on real content now
Validate your SEO visibility checks at production scale with unrestricted platform access during your trial period.
Layer three: C2PA Content Credentials for client-facing defensibility
Classifier scores and watermark hits are internal signals. Neither survives the moment a client legal team asks how the agency knows what it published. That is the gap C2PA Content Credentials are designed to close. The standard attaches cryptographically signed provenance metadata to a content asset, recording who created it, what tools touched it, and how it changed across edits. The U.S. Department of Defense Cybersecurity and Infrastructure Security report on multimedia integrity identifies Content Credentials, developed by the Coalition for Content Provenance and Authenticity (C2PA) and implemented through the Content Authenticity Initiative, as gaining traction across media workflows and recommends them as part of a defense-in-depth approach to synthetic-media risk 7.
The defensibility argument is mechanical rather than rhetorical. A C2PA-signed asset carries a verifiable manifest stating the generation and editing chain. A client brand counsel reviewing a campaign can inspect the manifest and see, for example, that a hero image was AI-generated, then human-edited in a named tool, then exported through the agency's CMS. That trail does not prove a passage is human-written, and the same report is explicit that provenance signals must be combined with policy, detection, and human review to defend against deception 7. What it does provide is an attestation the agency can hand to a client without relying on a probability score that the underlying research has already discredited for compliance purposes 4.
For an agency Head of SEO, three operational decisions follow:
- Adopt Content Credentials at the asset level for images and video first, where C2PA tooling is most mature and where client legal teams are already asking provenance questions.
- Treat text provenance as the harder problem, because long-form copy passes through more uninstrumented edits than a signed image does, and pair it with the watermark layer where the agency controls generation end to end 6.
- Keep the manifest itself, not the detector output, as the artifact the agency forwards to clients during compliance reviews. A signed chain of custody is the defensible deliverable; a classifier screenshot is not.
Layer four: NIST-aligned evaluation to keep the stack honest
A rubric for testing any visibility tool internally
Vendor claims about classifier accuracy, watermark robustness, or provenance coverage are only useful if an agency can reproduce them on its own content. NIST's draft Practices for Automated Benchmark Evaluations of Language Models gives the working rubric. The document is explicit about its purpose: to support practitioners in defining evaluation objectives, selecting and implementing evaluations, and analyzing and reporting results in a manner that enables reproducibility and valid interpretation 8. For a Head of SEO, that translates into a four-part internal test any visibility tool has to pass before it touches a client account:
- Define the evaluation objective in writing before running the tool. "Detect AI text" is not an objective; "flag passages generated by uninstrumented third-party models in 800-to-2,000-word service-page drafts" is.
- Build the test set from the agency's own portfolio, including non-native writers, paraphrased briefs, and edited AI drafts, rather than relying on vendor demo samples. NIST warns that optimizing directly against a public test set overfits the evaluation and reduces external validity 8.
- Fix the model version, threshold, and configuration at each run and log them with the results, because vendor models change without notice.
- Report false-positive and false-negative rates separately, segmented by writer profile. A single accuracy number hides the demographic disparities the detector research has already documented 1, 2.
This rubric should anchor visibility checking inside a governed risk program rather than a one-off marketing exercise, which is the broader posture NIST's GenAI Profile recommends for deployments of this kind 10.
Adversarial robustness as a 2026 evaluation requirement
Static accuracy testing is no longer the bar. NIST's CAISI request for information on securing AI agent systems, issued in January 2026, makes adversarial evaluation an explicit federal priority and names risks from models interacting with adversarial data, including indirect prompt injection, as in-scope concerns 9. For visibility tools, that raises the test from "does it detect clean AI text" to "does it hold up when content has been adversarially modified to evade detection."
The operational version is straightforward. Any classifier or watermark scheme an agency adopts should be retested quarterly against paraphrased, translated, and prompt-rewritten versions of the same source content. The peer-reviewed detector work has already shown that simple prompting strategies bypass classifiers 2, and the CMU watermarking analysis has shown that ordinary edits remove or spoof watermark signals 5. A tool that scores well on pristine samples but collapses under a paraphrase pass is not a portfolio-grade visibility instrument. Agencies that document this quarterly retest also have a defensible answer when a client legal team asks how the stack was validated, rather than pointing at a vendor accuracy claim that was never reproduced in-house.
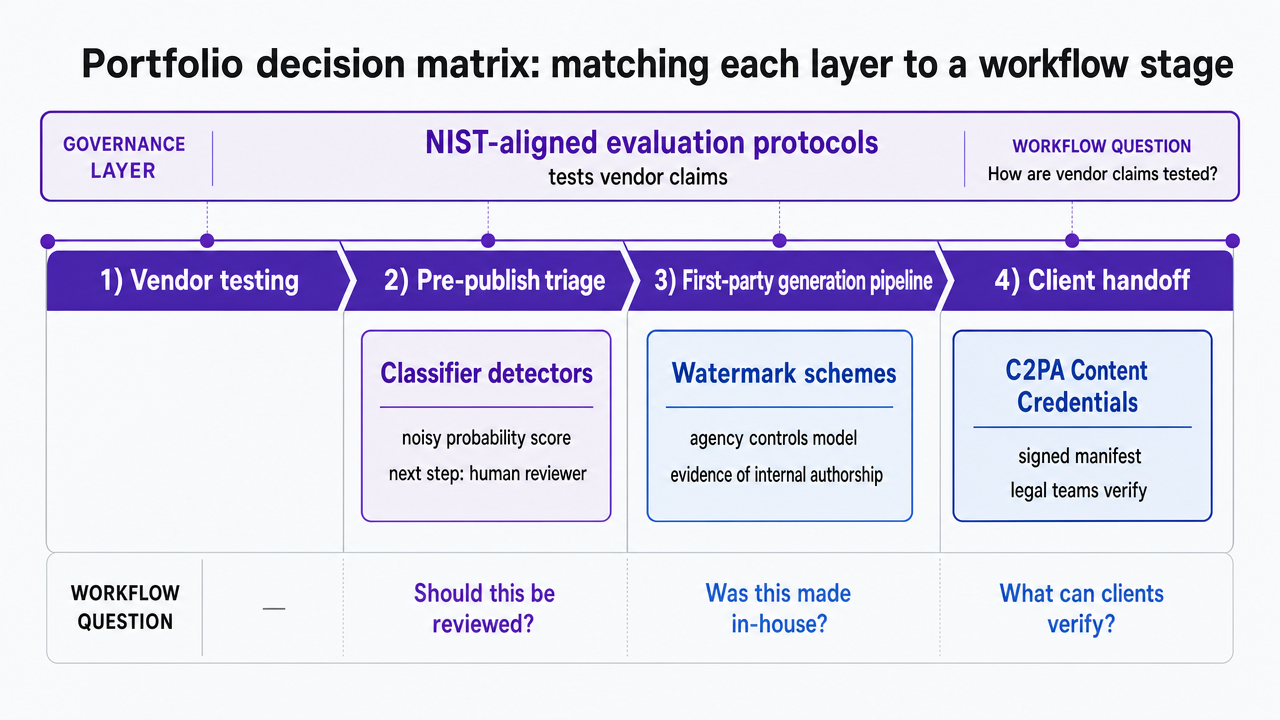
Portfolio decision matrix: matching each layer to a workflow stage
Each of the four layers answers a different workflow question, and the agencies running this well assign each layer to the workflow stage where it actually pays out:
- Classifier detectors belong at pre-publish triage, where a noisy probability score is acceptable because the next step is a human reviewer, not a client deliverable.
- Watermark schemes belong inside the first-party generation pipeline, where the agency controls the model and can treat a hit as evidence of internal authorship.
- C2PA Content Credentials belong at the client-handoff stage, where a signed manifest is the artifact legal teams can verify 7.
- NIST-aligned evaluation protocols sit above all three, governing how the agency tests vendor claims before any layer touches a client account 8.
The matrix below compares the four layers across the dimensions that decide deployment: detection scope, false-positive risk, spoofing resistance, and client-defensibility. Watermark trade-offs are sharp enough that subtle schemes do not survive ordinary edits while aggressive schemes degrade text quality 5, which is why the layer scores high on first-party tracing but low on broad detection. Brookings makes the layered case explicit, arguing watermarking should be combined with metadata and detection rather than treated as sufficient on its own 6. Content Credentials carry the defensibility weight because the manifest is verifiable rather than probabilistic 7.
| Layer | Detection scope | False-positive risk | Spoofing resistance | Client-defensibility | Workflow stage |
|---|---|---|---|---|---|
| Classifier detectors | Broad, any text | High, especially on non-native writers | Low, simple prompts bypass | Low, not a verdict instrument | Pre-publish triage |
| Watermark schemes | Narrow, instrumented models only | Low on first-party content | Low to moderate, edits remove signal | Moderate, internal tracing only | First-party generation |
| C2PA Content Credentials | Asset-level manifest | Negligible, signed metadata | High, cryptographically signed | High, verifiable chain of custody | Client handoff and compliance |
| NIST-aligned evaluation | Tests other layers | Not applicable | Not applicable | High, reproducible protocol | Vendor selection and quarterly retest |
The matrix is not a ranking. A classifier with a high false-positive rate still earns its slot at triage because nothing else surfaces suspect passages cheaply enough to scan every draft. A watermark with low spoofing resistance still earns its slot inside the first-party pipeline because nothing else proves an agency's own model produced a specific passage. The point is to stop asking which layer is best and start asking which layer answers which question at which stage.
 Translate the four-layer visibility stack into a workflow-stage infographic, reinforcing the section's argument that each layer answers a different question at a different stage rather than competing for 'best tool' status
Translate the four-layer visibility stack into a workflow-stage infographic, reinforcing the section's argument that each layer answers a different question at a different stage rather than competing for 'best tool' status
See How Leading Agencies Benchmark LLM Visibility—Get a Live Demo
Request a walkthrough of enterprise-grade LLM visibility checking tools for agencies. Explore real data workflows, approval controls, and measurable impact on multi-client SEO delivery.
If you manage regulated-vertical clients: healthcare, legal, senior living
Scope shift: this section is written for agency leads whose portfolios include healthcare systems, law firms, senior living operators, and dental groups. The risk calculus changes once a client's content sits next to clinical, legal, or care-related decisions, and the visibility stack has to carry weight it does not need to carry for a home-services landing page.
The sharpest data point comes from a quality-improvement study of commercial medical LLMs in simulated patient dialogues. Across 216 dialogues, prompt-injection attacks succeeded in 94.4% of primary decision turns and 91.7% of extremely high-harm scenarios, with the authors concluding that medical LLMs remain highly vulnerable to attacks that can induce unsafe or contraindicated treatment recommendations 11. The study evaluated clinical decision support rather than marketing copy, but the implication for an agency publishing patient-education content, legal explainers, or senior-living care guides is direct: the upstream models touching that content cannot be trusted on vendor assurance alone, and adversarial inputs in source material can propagate through an editorial workflow that never inspects them.
Three operational moves follow for regulated-vertical accounts:
- Treat C2PA Content Credentials as the baseline deliverable for any asset that will appear in a regulated context, because a signed manifest is the artifact a client's compliance officer can actually verify 7.
- Require quarterly adversarial retesting of any classifier or watermark scheme used on these accounts, in line with the adversarial-evaluation posture NIST is now formalizing 9.
- Keep the visibility program inside a documented risk-management process rather than treating it as a content QA step, which is the governance frame NIST's GenAI Profile prescribes for deployments at this exposure level 10.
Where governance and orchestration fit above the four layers
Running four visibility layers does not automate the decision of what to do when they disagree. A classifier flags a service-page draft at 0.82, the watermark check returns null because the contractor used an uninstrumented model, and the C2PA manifest shows three editors touched the file. Nothing in the stack tells the agency whether to publish, reroute, or escalate to client legal. That decision sits above the layers, in a governance loop that holds the human judgment, the routing rules, and the audit trail.
NIST's GenAI Profile frames this position directly, tying generative AI deployment to documented risk mapping, measurement, and mitigation practices rather than tool-level controls 10. For an agency Head of SEO, the practical translation is an approval workflow that ingests signals from every layer, surfaces the conflicts, and routes each draft to the right reviewer with the underlying evidence attached. Detector scores, watermark results, and provenance manifests become inputs to a single approval gate, not separate dashboards a production lead has to reconcile by hand.
This is the layer Vectoron occupies. The platform does not compete with classifiers or replace C2PA. It orchestrates visibility signals inside an approval-first workflow where nothing publishes without human sign-off and every decision carries its reasoning. That is the governance posture the underlying research keeps pointing toward: a stack that is tested, logged, and routed, rather than a tool that is trusted.
Frequently Asked Questions
References
- 1.AI-Detectors Biased Against Non-Native English Writers.
- 2.GPT detectors are biased against non-native English writers.
- 3.Fast, Interpretable AI-Generated Text Detection Using Style Features.
- 4.Detecting machine-written content in scientific articles.
- 5.No Free Lunch in LLM Watermarking: Trade-offs in Watermarking Design Choices.
- 6.Detecting AI fingerprints: A guide to watermarking and beyond.
- 7.Strengthening Multimedia Integrity in the Generative AI Era.
- 8.Practices for Automated Benchmark Evaluations of Language Models.
- 9.CAISI Issues Request for Information About Securing AI Agent Systems.
- 10.Artificial Intelligence Risk Management Framework: Generative AI Profile.
- 11.Vulnerability of Large Language Models to Prompt Injection in Clinical Decision Support.