
Key Takeaways
- Profound tracks citation share across major answer engines on scheduled prompt panels, giving agencies a single defensible number for monthly reviews once 90 days of baseline data exist.
- AthenaHQ logs prompt-level answer transcripts and flags drift when competitors displace clients or sentiment shifts, enabling proactive content and PR responses to unstable RAG outputs 6.
- Peec AI samples seven engines daily and normalizes citation share for competitor benchmarking, exposing variance like 22% share in Perplexity versus 4% in Gemini for identical prompts.
- Otterly.AI classifies mentions as positive, neutral, negative, or comparative, which matters for reputation-sensitive verticals where being framed as a fallback hurts pipeline more than absence.
- Scrunch AI builds prompt panels from seed keywords and autocomplete data to produce share-of-voice gap charts, making it well-suited for pitch decks and one-hour competitive audits 8.
- Vectoron closes the loop from measurement to execution through an approval-first Command Center, acting on the GEO finding that added citations and statistics lifted source visibility over 40% 5.
Why measurement became the bottleneck in AI search
Classic rank tracking no longer accurately reflects reality, especially with the rise of AI Overviews. Zero-click searches now constitute 58.5% of all U.S. Google queries, and the click-through rate for position-one results on AI-affected queries has dropped from 27% to 11% 2. These figures highlight a significant shift: answers are increasingly resolved within the search engine itself, diminishing the value of traditional "blue links."
For agencies, this creates a growing reporting gap. Traditional dashboards still focus on positions one through three, while pipeline data shows traffic decay. The crucial insights—which queries are absorbed by AI summaries, which brands are cited, and how often a client appears in platforms like ChatGPT, Perplexity, Gemini, or AI Overviews—are missing from existing tools. Current SERP tools were designed for a search environment that is rapidly evolving.
LLM visibility tools address this gap by directly sampling answer engines. They log source citations for prompts and generate metrics such as citation share, brand mention frequency, and share of voice within generated answers. These metrics align with the actual behavior of AI search 7. The fundamental measurement primitive has changed; counting rankings on a declining interface is not equivalent to tracking citations on the platforms replacing it. The following six tools offer distinct approaches to this problem, with the best choice depending on how data integrates into client workflows.
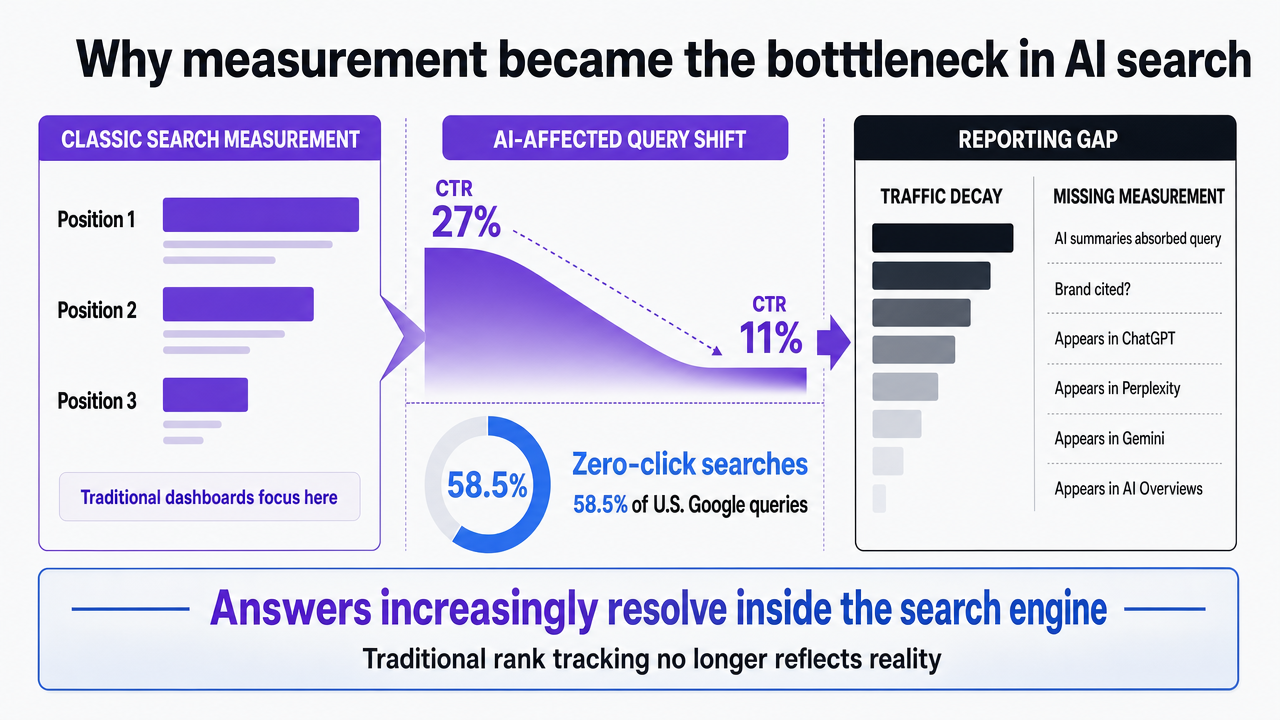 Visualize the dramatic CTR collapse on AI-affected queries cited in this section, reinforcing why traditional rank tracking fails
Visualize the dramatic CTR collapse on AI-affected queries cited in this section, reinforcing why traditional rank tracking fails
What LLM visibility tools actually measure (and how they sample)
At their core, these tools measure brand mentions (any reference to a client or competitor within a generated answer), citations (the source URL credited by the engine), and share of voice (the ratio of a brand's mentions or citations within a defined prompt set). These definitions are widely accepted, framing visibility as how often a brand is referenced, cited, or recommended by AI engines for relevant queries 7, 1.
The primary difference among tools lies in their sampling methods. Answer engines are non-deterministic; the same prompt can yield different sources across multiple runs because retrieval-augmented generation (RAG) fetches new documents at inference time 6. To account for this, credible tools employ a "prompt panel"—a fixed set of queries executed on a schedule across various engines, with results logged over time. Without this structured approach, a single ChatGPT screenshot offers only an anecdote, not a reliable measurement.
Sampling methods vary across three key dimensions: prompt source, engine coverage, and frequency.
- Prompt sources include agency-defined prompts, prompts generated from seed keywords, or those scraped from autocomplete and "people also ask" data.
- Engine coverage: Most reputable tools cover ChatGPT, Perplexity, Gemini, and Google AI Overviews, with Microsoft Copilot and Claude often included.
- Sampling frequency ranges from daily (capturing volatility) to weekly (smoothing noise) or on-demand (for specific audits).
The data volume and associated costs differ significantly between a tool sampling four engines daily with 200 client prompts versus one running 50 prompts weekly on two engines 8, 9.
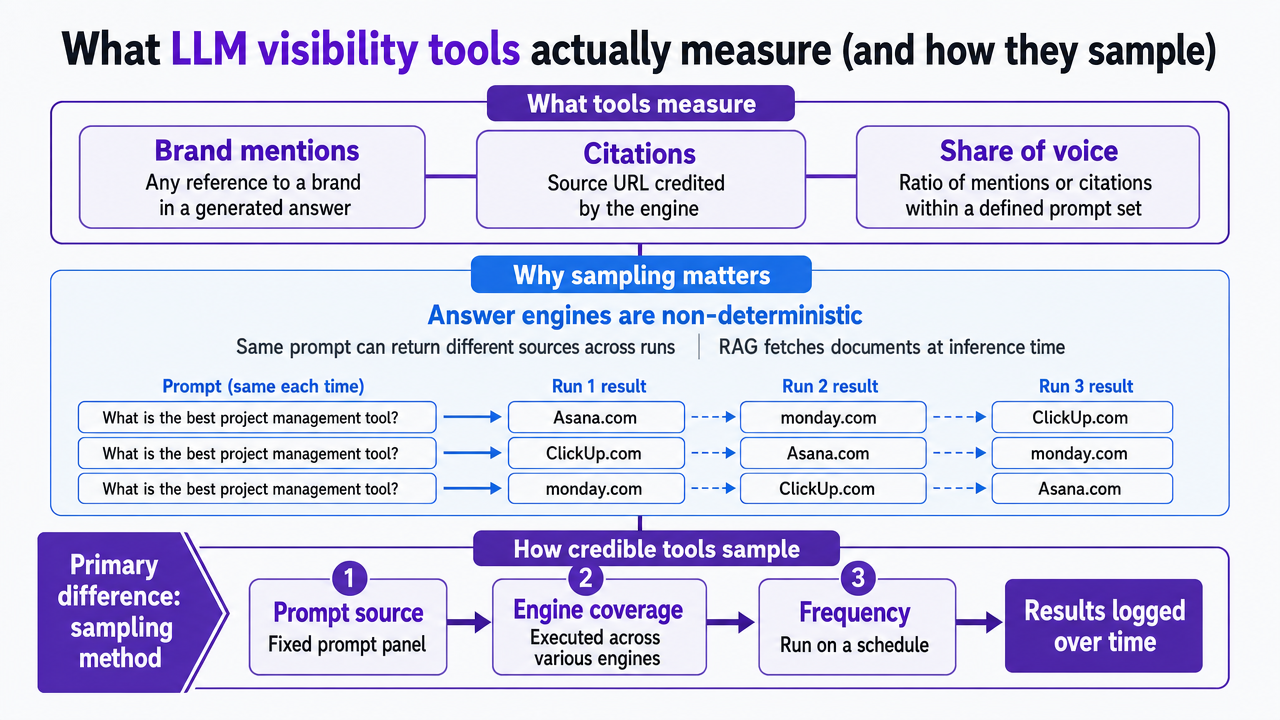 Process infographic mapping the three sampling dimensions (prompt source, engine coverage, frequency) described in the section
Process infographic mapping the three sampling dimensions (prompt source, engine coverage, frequency) described in the section
The six tools worth evaluating
Profound — citation share across answer engines
Profound specializes in citation share, running scheduled prompt panels across ChatGPT, Perplexity, Gemini, Google AI Overviews, and Microsoft Copilot. It logs cited URLs and aggregates this data into a citation share percentage per domain, segmented by engine, topic cluster, and prompt category. This primary metric is particularly valuable for agencies that need to report a single, defensible number to clients.
The tool uses API and headless browser-driven sampling, with daily pulls against agency-defined prompt sets. It relies on ingested prompt lists rather than scraping, meaning agencies must ensure prompt panels accurately reflect the client's demand. When done effectively, this produces a citation share series that correlates with content investment. If implemented poorly, the data remains flat and uninformative.
Profound is best suited for mid-funnel reporting within an agency stack. After 90 days of baseline data, citation share deltas become a key metric in monthly reviews, indicating whether content investment is increasing AI surface area 7. Its limitation is scope; Profound measures citations but not sentiment or context. A client cited negatively counts the same as one recommended. Combining Profound with a sentiment-aware tool provides a more accurate understanding of citation share.
AthenaHQ — prompt-level monitoring and drift detection
AthenaHQ focuses on granular, prompt-level monitoring. It treats each prompt as a distinct object, logging the full answer text, cited sources, and brand mention position for every run. Agencies configure prompts similarly to keyword tracking, tagging and categorizing them for continuous observation. The platform flags "drift" when an answer changes, such as a new competitor being cited, a client disappearing from recommendations, or a shift in sentiment.
This granular detail is crucial because answer engines produce unstable outputs. RAG systems retrieve fresh documents at inference time, and models compose responses based on what they find 6. A client's position in an answer can change suddenly if a competitor publishes stronger content. AthenaHQ's drift alerts enable agencies to respond proactively with content or PR actions.
Sampling can be configured for high-priority prompts, with most agency deployments running daily across two to four engines. The output is qualitative, including answer transcripts, change differentials, and mention context. This suits clients focused on specific competitive dynamics rather than portfolio-wide trends. However, prompt-level monitoring scales linearly with panel size, making it more expensive for large prompt sets. This cost is justified for accounts where losing a single prompt position has significant financial implications.
Peec AI — multi-engine sampling and competitor benchmarking
Peec AI emphasizes broad coverage, sampling seven answer engines daily and providing a normalized citation share metric. This allows agencies to compare client positions across ChatGPT, Perplexity, Gemini, Copilot, Claude, and AI Overviews. Built-in competitor benchmarking enables agencies to input competitor domains and view share-of-voice deltas per engine and prompt cluster.
Multi-engine coverage is operationally important because citation patterns vary significantly across engines, even for identical prompts. RAG architectures retrieve from different source sets, weighted by distinct signals, influencing the model's composition 6. A client might have a 22% citation share in Perplexity but only 4% in Gemini for the same prompts. Peec AI highlights this variance, informing content investment decisions.
Brands cited in AI answers experience a 35% increase in organic clicks compared to those not cited 2, demonstrating that citation share gains translate into measurable traffic. This data point strengthens Peec AI's competitive benchmarks, providing a credible justification for agencies pitching content programs.
Peec AI functions best as a portfolio-wide measurement layer, generating executive charts that show engine growth for client accounts. Its limitation is depth; the normalized score can obscure per-answer context, meaning agencies needing to understand why a citation moved may still require a prompt-level tool.
Otterly.AI — sentiment and brand-context tracking
Otterly.AI addresses a crucial question beyond mere citation share: what is the engine actually saying when a client is mentioned? The platform analyzes generated answers for sentiment, surrounding context, and recommendation language, classifying mentions as positive, neutral, negative, or comparative. This distinction is vital for agencies managing reputation-sensitive clients in sectors like law, healthcare, or financial services.
Sampling occurs across ChatGPT, Perplexity, Gemini, and Copilot, with prompt panels weighted towards branded and comparison queries where sentiment fluctuations are most pronounced. The platform also tracks competitor framing within the same answers, revealing instances where a client is positioned as an alternative rather than a primary recommendation. These nuances are often lost in aggregated citation share metrics.
Methodologically, trustworthiness research on RAG systems suggests that visibility metrics require a multi-dimensional assessment—including factuality, robustness, and fairness—beyond just frequency 10. Otterly.AI's sentiment layer moves in this direction, but agencies should interpret sentiment classifications as directional rather than absolute, especially for complex answers where models may hedge.
Otterly.AI is suitable for reputation-focused accounts and any client where the framing of an answer impacts pipeline as much as its presence. It may be excessive for transactional verticals where citation count directly correlates with conversion, but it is essential where answer framing influences client trust.
Scrunch AI — competitor benchmarking and share-of-voice
Scrunch AI focuses on comparative analysis. It takes a client domain, an agency-defined competitor set, and a prompt panel, then runs scheduled samples to generate share-of-voice metrics. This includes the percentage of mentions and citations across the panel belonging to each competitor, segmented by engine and topic. The output is designed for pitch decks and quarterly reviews, featuring stacked bar charts, trend lines, and gap-to-leader callouts.
A key differentiator for Scrunch is its prompt construction layer. The platform generates prompt panels from a seed keyword list, expanding them with autocomplete data and category-level queries derived from the client's commercial intent 8. This ensures the panel reflects the client's actual demand, rather than a generic template. The integrity of share-of-voice data depends on the relevance of the underlying prompts; a panel biased towards queries a client already dominates will produce misleadingly positive data.
Sampling occurs daily across four to six engines, with results normalized into a single share-of-voice score per competitor. Scrunch is ideal for pitch and audit work, allowing agencies to quickly generate a baseline AI visibility report against competitors. For ongoing reporting, it overlaps with Peec AI's multi-engine coverage. Agencies often use Scrunch for competitive narratives and Peec AI for trend tracking, but running both on the same accounts can lead to duplication.
Vectoron — closing the loop from measurement to content execution
While other tools measure visibility gaps, Vectoron focuses on the execution required to close them. This includes research, drafting, structural changes, and citation-focused formatting, all managed through an approval-first Command Center with specialist AI strategists for content, SEO, and backlinks. Visibility data serves as a signal, leading to ranked content recommendations that require human sign-off before publication.
The integration of measurement and execution is supported by research, such as the GEO study, which found that adding citations, quotations, and statistics to source documents increased source visibility in generative engines by over 40% for queries tested on Perplexity 5. This highlights a structural finding about how answer engines retrieve information. Visibility tools identify the gap, and a platform like Vectoron acts on this finding at scale by restructuring content, adding sourced statistics, and rebuilding question-answer blocks to improve citation share.
For agencies, Vectoron complements the measurement stack rather than replacing it. It can be paired with tools like Profound or Peec AI for visibility insights, while Vectoron handles the execution with approval gates to maintain editorial control. This combination of measurement and approval-first execution transforms citation share from a passively observed metric into a actively managed one.
Test LLM search visibility tracking at scale
Monitor and analyze your clients’ AI search presence with full platform access—no restrictions during your trial.
Methodology caveat: citation counts are not trustworthiness
A citation share dashboard treats every mention as equally valuable. While it shows whether an engine cited a client and how the score moves, it doesn't indicate if the citation appeared in a factually accurate answer, if the brand was framed correctly, or if the context held up under adversarial prompting. Trustworthiness research on RAG systems emphasizes that a comprehensive evaluation must consider multiple dimensions—factuality, robustness, fairness, and transparency—not just citation frequency 10.
For agencies, this means a client could show strong citation share while being cited in answers that misrepresent their services, attribute a competitor's case study to them, or recommend them as a fallback. These issues are not reflected in frequency metrics but can manifest weeks later as misqualified inquiries in sales reports.
The best practice is to combine citation share with at least one qualitative layer, such as sentiment classification, answer transcripts, or human review of high-value prompts. Tools that only provide counts are useful for trend tracking but insufficient for greenlighting content investments or signing off on quarterly client reports. Always pair the quantitative data with context to avoid misleading conclusions.
Where each tool fits in an agency stack
The six tools discussed are not interchangeable, and deploying all of them on every account can erode margins without improving insights. The key is to determine which tool serves pitch and audit work, which supports ongoing reporting, and which feeds production. Each of these functions benefits from different sampling methods and output formats.
For pitch and audit, Scrunch AI is highly effective. It generates a baseline competitor analysis against named rivals using autocomplete-expanded prompts, providing a gap chart that can anchor a proposal. Profound can also fill this role if the prospect already has an established AI presence and the focus is on share movement rather than initial gaps. Both tools offer a defensible one-hour audit deliverable.
For ongoing portfolio reporting, Peec AI and Profound offer distinct benefits. Peec AI's multi-engine normalization helps identify routing decisions—which engine is growing for which client—while Profound provides in-depth citation share data per engine for monthly trend tracking. Running both tools simultaneously often leads to duplication; choose one as the primary reporting layer and only add the other if a client portfolio clearly divides between brand-led and demand-led work.
For production feedback, AthenaHQ and Otterly.AI inform editorial decisions. AthenaHQ's drift alerts notify content teams when a competitor displaces a client in a tracked answer. Otterly.AI's sentiment classifications highlight when a citation is detrimental, indicating a need for structural content changes rather than just more publication. Vectoron integrates these signals as inputs for ranked content recommendations, with approval gates ensuring agencies maintain editorial control 5.
See Exactly Where Your Brand Ranks in AI-Generated Search Results
Request a live walkthrough of enterprise-grade LLM visibility tracking—compare your AI search presence against competitors, surface missed opportunities, and get actionable data on emerging SERP features across multiple clients.
Stack economics: if you manage a client portfolio
This section is aimed at portfolio operators managing ten to fifty client accounts, where measurement tooling must scale efficiently without consuming retainer margins. Single-account agencies may find much of this less relevant.
LLM visibility tools are priced based on three variables that compound across a client book:
- Per-domain billing scales linearly with portfolio size, penalizing agencies that include the tool as a standard offering for every retainer.
- Per-prompt billing rewards disciplined panel construction and discourages tracking everything.
- Per-engine sampling increases API and compute costs with each additional engine.
A portfolio of 30 clients, each running 200 prompts across five engines daily, generates approximately 30,000 sampled responses per day before any analysis. Pricing tiers reflect this volume, even if not explicitly stated in the UI.
To maintain margin discipline, align tool selection with retainer tiers. Reserve prompt-level monitoring for accounts where the cost of a displaced citation outweighs the subscription difference. For other accounts, default to a single roll-up tool and add depth only when justified by the account's specific needs 8.
Defending the budget line: what to tell leadership
When presenting to managing partners or CEOs, the focus should be on the agency's ability to credibly report on share of voice as the discovery surface shifts to AI. McKinsey estimates that AI-powered search could influence roughly $750 billion in revenue by 2028. They also note that even category leaders' AI search performance can lag their SEO performance by 20% to 50%—a significant gap that goes undetected without specialized diagnostics 11. This is the message leadership needs to hear: the agency must either measure this gap or absorb it as silent client churn.
Frame tool expenditure as a cost for reporting integrity, not a new channel. Without visibility data, quarterly business reviews describe a search landscape that appears to shrink on dashboards but not in client pipelines. With the right tools, agencies can attribute traffic decay to engine-level citation gaps and strategically direct content investments. This transformation—from unexplained decline to a tracked, addressable metric—justifies the budget line item across a client portfolio.
 Zero-click searches as a percentage of all U.S. Google queries
Zero-click searches as a percentage of all U.S. Google queries
Zero-click searches as a percentage of all U.S. Google queries
Frequently Asked Questions
References
- 1.Guide to LLM Tracking and AI Search Visibility for SEO Agencies.
- 2.Enterprise SEO 2026: Rebuilding for AI Answer Engines.
- 3.AI Is Destroying SEO. Rank Now Requires Answer Engine Optimization.
- 4.You Ask, I Answer: Google AI Answers and SEO Impact?.
- 5.GEO: Generative Engine Optimization.
- 6.What is retrieval-augmented generation (RAG)?.
- 7.AI Search Visibility (AI SEO / AEO / GEO Tracker).
- 8.Answer Engine Optimization (AEO): AI visibility in 2026.
- 9.Generative Engine Optimization: everything you need to know for 2026.
- 10.Trustworthiness in Retrieval-Augmented Generation Systems.
- 11.Winning in the age of AI search.