
Key Takeaways
- Task-level evaluation against client-specific rubrics beats public benchmarks, because model choice produces measurable accuracy differences on real domain tasks like clinical content 7.
- Production observability with drift and cost telemetry, sliced by client and model version, catches silent model updates and defends margin before clients notice quality issues.
- Governance alignment to NIST AI RMF's Govern–Map–Measure–Manage lifecycle, including the 2024 AI-600-1 generative AI profile, shortens enterprise procurement cycles in regulated verticals 2.
- Attribution that joins prompt, output, and downstream qualified calls or bookings is the axis where most visibility tools fail, and where retention is won at QBRs.
- Pure observability platforms deliver operational telemetry and cost defense, but rarely answer the quality, governance, or revenue questions a client raises in a QBR.
- Evaluation-first tools instrument the quality bar with custom rubrics and red-teaming, but leave production blind spots that require pairing with an observability layer.
- Citation and rank trackers report third-party model outputs for client-facing GEO reporting, yet cannot instrument the agency's own pipeline or attribute citations to revenue.
- Execution platforms with built-in visibility trade best-of-breed depth for a single audit trail from prompt to publication to KPI, which favors portfolio coordination over isolated benchmarking.
The Measurement Gap Agencies Are Now Paid to Close
Deloitte's 2026 enterprise AI survey puts the agency opportunity in one number pair: roughly 20% of organizations report revenue growth from AI today, while 74% expect to see it in the future 1. The sample is enterprise buyers describing their own programs, and the figures are self-reported, but the spread is the point. Three out of four executives are budgeting against a return that one in five has actually booked.
That spread is what an agency Head of SEO is now being paid to close. Clients renew when the AI line item on their P&L produces qualified pipeline, not when it produces another dashboard. They churn when the gap between expectation and realized revenue widens for two quarters in a row.
Deloitte also notes that today's AI value is concentrated in efficiency and decision support, not topline lift 1. For an agency book, that means the work of proving ROI from LLM-assisted content, GEO placement, and AI-driven SEO has to be instrumented before it can be sold. Visibility tooling is the instrumentation layer.
The rest of this piece evaluates that layer across four tool classes and a four-axis rubric, so a Head of SEO managing 8 to 40 accounts can build a defensible shortlist instead of a feature parade.
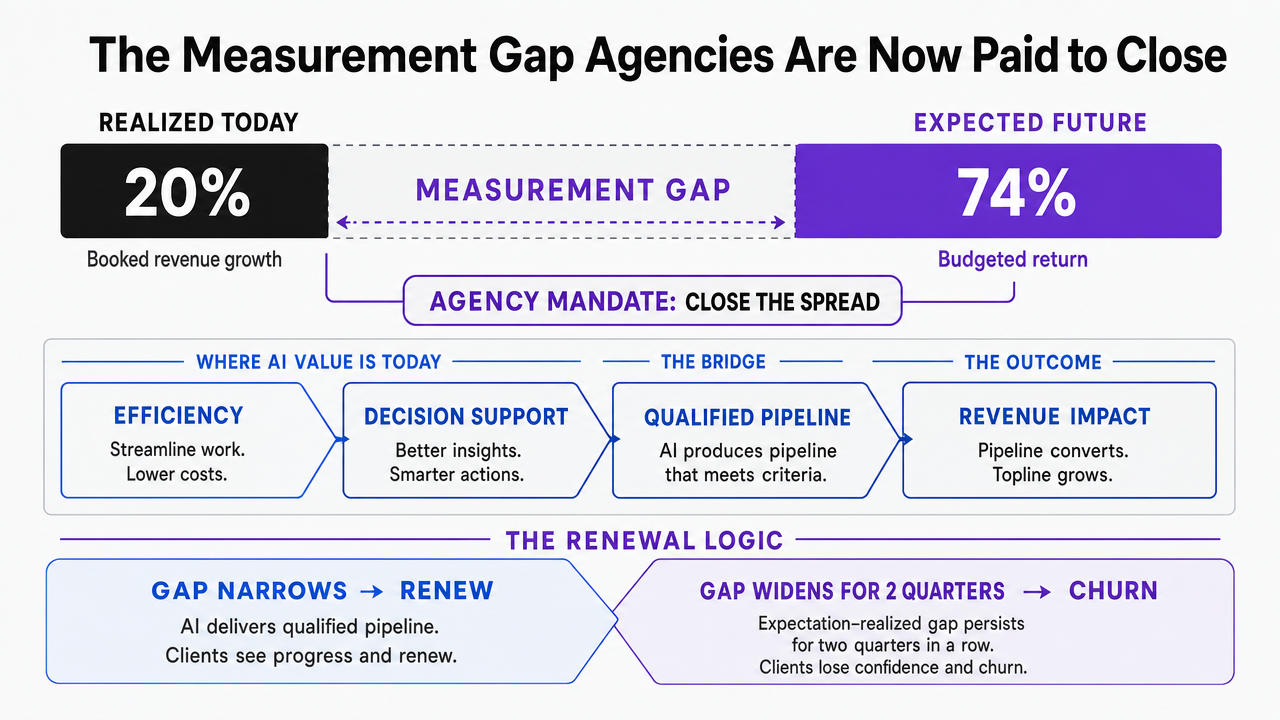 Visualize the expectation-vs-realized AI revenue gap cited from Deloitte, which is explicitly stated in the surrounding prose (20% realized vs 74% expected)
Visualize the expectation-vs-realized AI revenue gap cited from Deloitte, which is explicitly stated in the surrounding prose (20% realized vs 74% expected)
What 'LLM Visibility' Actually Means Inside an Agency P&L
Most vendor decks define LLM visibility as tracking how often a brand surfaces in ChatGPT or Perplexity answers. That definition is too narrow for an agency that owns retention and margin across a portfolio. Citation tracking is one signal. It is not the control layer.
Inside an agency P&L, LLM visibility is the instrumentation that ties prompt, model, output, and downstream business signal together at the client level. It captures the full trace: what prompt was sent, which model handled it, what context was retrieved, what the output said, how it was reviewed, where it was published, and what happened next in qualified calls, bookings, and pipeline. Without that chain, AI-assisted SEO is a black box billed by the hour.
Three layers sit underneath the term:
Evaluation : Answers whether a given output meets a client-specific quality bar, which matters because model choice measurably changes accuracy in regulated domains 7.
Observability : Answers whether production behavior is drifting on latency, cost, refusal rate, or output quality across thousands of generations.
Governance : Answers whether the entire workflow can be audited against a recognized framework when an enterprise client's legal team asks 2.
For a Head of SEO managing 8 to 40 accounts, the P&L test is simpler than the architecture. A visibility tool earns its line item when it shortens the path from "we published content" to "here is the revenue it produced, and here is the evidence the work met your standard." Anything that stops short of that chain is a reporting widget, not a control layer.
The Four-Axis Rubric: Evaluation, Observability, Governance, Attribution
Task-Level Evaluation Against Client-Specific Quality Bars
Public benchmarks do not tell a Head of SEO whether a model can write a behavioral health intake page that survives a clinical director's review. CSET makes the point directly: there are hundreds, if not thousands, of ways to evaluate LLMs, and "benchmark chasing" produces models that win on MMLU or HumanEval without matching real-world behavior 6. The implication for agency buyers is simple. Vendor benchmark slides are marketing. Task-level evaluation is the actual deliverable.
A visibility tool earns this axis when it lets the agency define a quality rubric per client and per content type, then score every generation against that rubric automatically. For a personal injury firm, the rubric might weight statutory accuracy and jurisdictional specificity. For a DSO, it weights procedure language and CDT code alignment. For senior living, it weights regulatory tone and family-facing readability.
The evidence that this matters is concrete. In a peer-reviewed comparison of LLM responses to optic neuritis questions, model choice produced measurable differences in accuracy and comprehensiveness on the same task 7. If two frontier models disagree on a clinical answer, they will also disagree on a client's medical content. Evaluation has to run continuously, not once at procurement.
Production Observability with Drift and Cost Telemetry
Evaluation tells the agency whether an output was acceptable yesterday. Observability tells the agency whether the production pipeline is still behaving today. The two are different problems.
The observability axis covers four data series at minimum:
- Latency per generation
- Token cost per generation
- Refusal or fallback rate
- Output quality score over time
Each series needs to be sliceable by client, by content type, by model version, and by prompt template. When a vendor pushes a silent model update, the refusal rate or the quality score will move first. An agency that sees the move in a dashboard handles it as a routine ticket. An agency that does not see it learns about the drift from a client complaint.
Cost telemetry is the second non-negotiable. McKinsey's 2025 survey notes that organizations are reporting use-case-level cost and revenue benefits as AI moves from pilot to production 5. Use-case-level reporting is only possible when token spend is attributed to a specific client deliverable, not a shared API key. A visibility tool that cannot break cost down to the workstream cannot defend margin.
Governance Alignment to NIST AI RMF
Enterprise clients in regulated verticals will eventually ask the agency to describe its AI controls in writing. The cheapest answer is to map controls to a framework the client's legal team already recognizes. NIST's AI Risk Management Framework is the current default in the US, and it organizes AI oversight into a Govern–Map–Measure–Manage lifecycle that any visibility tool should be able to instrument 2.
The mapping is direct:
Govern : Translates into policy controls: who can deploy which model for which client, what prompts are approved, what content types require human review before publication.
Map : Translates into prompt and context tracing: every generation carries a record of the inputs, retrieved context, and intended use case.
Measure : Translates into quality and cost metrics scored against the client-specific rubric and the cost-per-deliverable budget.
Manage : Translates into drift detection and incident response: alerts when a metric breaches threshold and an audit trail for the remediation.
A 2024 NIST profile, AI-600-1, extends the framework specifically to generative AI systems, which makes the alignment more directly applicable to LLM workflows than it was a year ago 2. Tools that already speak this vocabulary shorten the agency's enterprise sales cycle. Tools that do not force the agency to build the crosswalk itself.
Attribution That Survives a Client QBR
The fourth axis is the one that decides retention. Attribution is the chain from a specific piece of LLM-assisted output to a specific business signal the client cares about: qualified calls, booked consultations, pipeline added, cost per lead moved.
A visibility tool earns this axis when its data joins cleanly to the client's downstream systems. That usually means call tracking, CRM, and booking platform identifiers carried through the content metadata so an asset produced on a given date can be traced to the leads it influenced. Without that join, the QBR slide reads as activity reporting: pages published, citations earned, mentions tracked. With it, the slide reads as revenue narrative.
McKinsey's 2025 finding that 64% of respondents say AI helps them maintain or increase competitive advantage is the macro tailwind 5. The micro test is harder: can the agency point at one campaign, one model version, one prompt set, and show the revenue line that moved? Attribution is the axis where most visibility tools quietly fail.
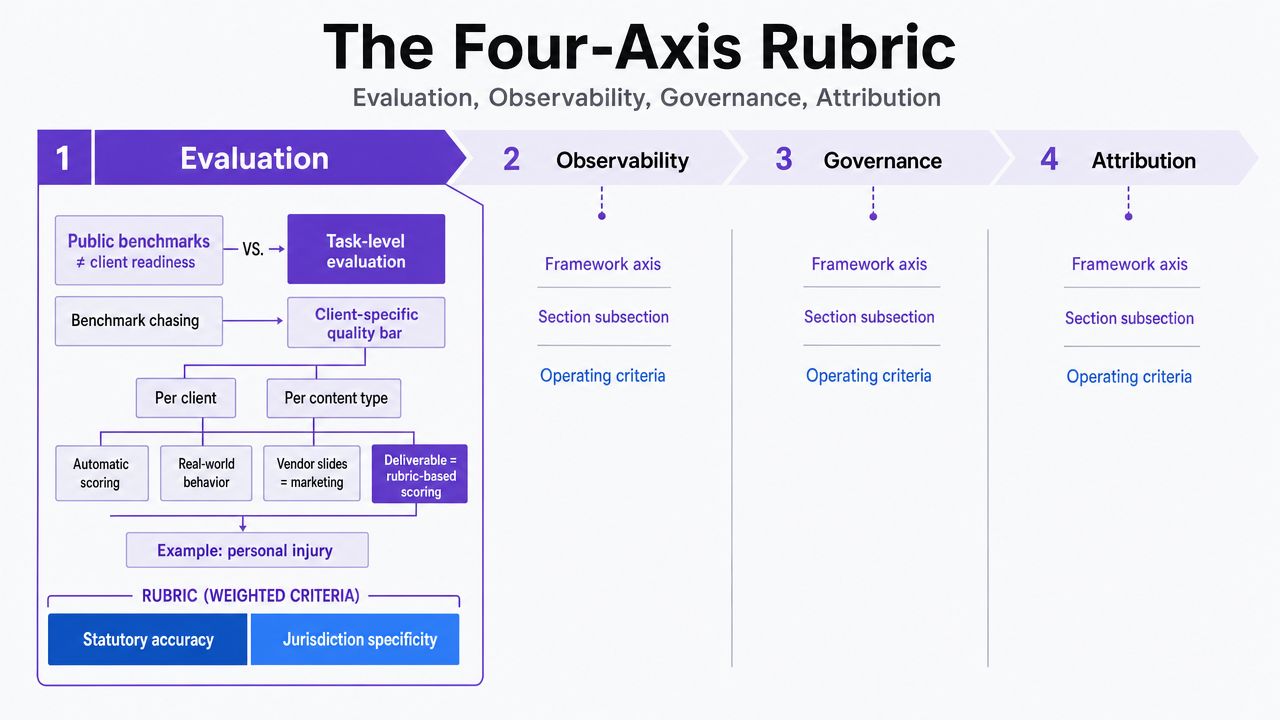 Process infographic that summarizes the four-axis evaluation framework introduced in this section, mirroring the four subsections
Process infographic that summarizes the four-axis evaluation framework introduced in this section, mirroring the four subsections
Test LLM visibility impact on live campaigns
Assess real-time client ROI improvements using advanced LLM visibility workflows before you commit long term.
Why the Category Is Maturing Now
Two adoption data points explain why visibility tooling is moving from optional to expected. McKinsey's early-2024 survey found that 65% of respondents reported their organizations were regularly using gen AI, nearly double the prior wave 8. Stanford's 2026 AI Index puts organizational AI adoption at 88% 4. The trajectory closed most of the remaining gap inside 24 months.
That curve matters to a Head of SEO for one reason. When 88% of client-side organizations are running AI somewhere in the business, the agency is no longer the only party with an opinion about model choice, prompt hygiene, or output quality. Client-side legal, IT, and analytics teams are now in the room during retainer reviews, and they bring their own evaluation criteria.
The same surveys flag the lag. McKinsey's 2025 follow-up notes that organizations are reporting use-case-level cost and revenue benefits, but many still lack the metrics and baselines to attribute performance changes cleanly to AI versus other factors 5. Adoption is near-universal. Measurement discipline is not.
For an agency book, that asymmetry is the opening. Tools that instrument evaluation, observability, governance, and attribution at the client level let a Head of SEO show up to a QBR with the measurement layer the client has not yet built internally. That is a billable position. The window closes once enterprise buyers stand up their own visibility stacks, which is the work happening right now inside the 88% figure.
The Four Functional Classes of LLM Visibility Tools
Class One: Pure Observability Platforms
Pure observability platforms were built for engineering teams running LLM apps in production. Tools in this class focus on traces, spans, token usage, latency distributions, error rates, and prompt-response logging. They treat every LLM call the way an APM tool treats a microservice request.
For an agency Head of SEO, the value is operational telemetry. When a content workflow generates 4,000 outputs a month across 22 client accounts, the observability layer is what catches a model version change, a vector store regression, or a runaway token cost before the next invoice lands. Cost telemetry sliced by client, prompt template, and model version is the line item that defends margin during a retainer renegotiation.
The limitation is that observability platforms in this class were not designed to answer the question a client actually asks in a QBR. They report on system behavior, not on content quality against a domain rubric or on revenue contribution. Quality scoring is usually a custom integration. Attribution to qualified calls or bookings is out of scope. Governance mapping to a framework like NIST AI RMF requires the agency to build the crosswalk itself 2.
Pure observability earns its place inside a larger stack. It rarely stands alone as the visibility layer a Head of SEO presents to a client-side legal or analytics team.
Class Two: Evaluation-First Tools
Evaluation-first tools start from the opposite end. Instead of instrumenting production traffic, they instrument the quality bar. The platform lets a team define rubrics, run model comparisons, score outputs against reference answers, and red-team prompts for safety failures before content reaches a client review queue.
This class maps directly to the task-level evaluation axis. CSET's survey of LLM evaluation methods stresses that benchmark scores on MMLU or HumanEval do not predict real-world behavior, and that custom, task-specific evaluations are what separate marketing from measurement 6. Evaluation-first tools give an agency the apparatus to build those custom evaluations per client and per content type, then run them on every generation or on a sampled cadence.
The healthcare and behavioral health verticals make the case sharply. A peer-reviewed comparison of LLM responses on optic neuritis questions found measurable accuracy differences between frontier models on the same medical task 7. An agency producing patient-education content for a behavioral health network cannot rely on a vendor's benchmark slide to justify model choice. Evaluation-first tooling is how that choice gets defended in writing.
The trade-off is production blind spots. Evaluation platforms tend to be strongest at pre-deployment and weakest at continuous drift detection across live traffic. Cost telemetry and incident response usually require pairing with an observability layer. As a standalone purchase, this class buys quality defense, not operational coverage.
Class Three: Citation and Rank Trackers
Citation and rank trackers are what most marketing buyers picture when they hear "LLM visibility tool." Platforms in this class poll ChatGPT, Perplexity, Gemini, and similar surfaces with target prompts, then report how often a client brand appears in answers, which sources get cited, and how rankings shift week over week.
The signal is real, and for clients whose buyers are now researching inside chat interfaces, it is the closest analog to the SERP tracking an agency has billed for a decade. A Head of SEO can show a client which prompts surface their brand, which competitors dominate adjacent prompts, and which content assets are being cited as sources. That is a defensible reporting layer for the GEO portion of a retainer.
The limitation is scope. Citation trackers measure outputs of third-party models the agency does not control. They do not instrument the agency's own LLM-assisted production pipeline, so they cannot answer evaluation, observability, or governance questions about how the agency itself uses AI. They also cannot attribute a citation to a downstream qualified call or booking without a separate analytics join.
This class belongs in the stack as a client-facing reporting tool. It does not replace the internal control layer that defends quality, cost, and audit posture across the agency's own workflows.
Class Four: Execution Platforms With Built-In Visibility
The fourth class collapses production and visibility into one workflow. Execution platforms in this category run the content, SEO, and adjacent marketing work, and instrument every generation as it happens. Evaluation rubrics, cost telemetry, approval routing, and audit logs are properties of the platform, not bolt-ons.
The agency case for this class is portfolio economics. When a Head of SEO is managing 8 to 40 accounts, stitching together a pure observability tool, an evaluation-first tool, a citation tracker, and a separate execution stack creates four integrations the agency has to maintain. Each integration carries its own seat cost, its own data model, and its own failure mode. Execution platforms with built-in visibility trade some best-of-breed depth for a single audit trail from prompt to publication to KPI.
Vectoron sits in this class. Its specialist strategists run content, SEO, PPC, backlinks, social, and call intelligence work through an approval-first Command Center, with prompt traces, model selection, evaluation outputs, and cost data attached to every deliverable. Recommendations carry the strategic reasoning, and nothing ships without human sign-off. The honest scope: depth on production workflow and governance, with citation tracking and deep model-research evaluation typically handled by integrations or paired tools.
The class is worth shortlisting when the agency's bottleneck is coordination across channels and clients, not isolated model benchmarking. It is the wrong class when the agency only needs a reporting widget on top of an existing production stack.
 Comparison infographic visualizing the four tool classes described in the section's subheads, which is a comparison framework explicitly laid out in the prose
Comparison infographic visualizing the four tool classes described in the section's subheads, which is a comparison framework explicitly laid out in the prose
See How Leading Agencies Quantify LLM Visibility and Client ROI—Without Expanding Headcount
Request a tailored walkthrough of AI-powered visibility and reporting tools that benchmark LLM performance, automate insights, and streamline multi-client oversight for scalable SEO delivery.
Portfolio Economics: Unified Visibility Across a Client Book
This section shifts scope from single-account thinking to the portfolio operator running 8 to 40 retainers. The question is no longer whether a visibility tool helps one client. It is whether the tooling layer scales without a linear add of evaluation analysts, QA reviewers, and reporting specialists.
The variables below are what move on an agency P&L when a unified visibility layer replaces per-account tooling and manual review. Figures are illustrative variables, not benchmarks; the only anchored number is the $599/month trial price referenced in the closing CTA context.
| Cost or effort category | Without unified visibility | With unified visibility layer |
|---|---|---|
| Evaluation labor (hours per client per month) | Variable, scales linearly with account count | Fixed rubric setup, amortized across the book |
| Observability tooling (seat cost) | Per-tool seats across 3–4 platforms | Consolidated seat under one platform |
| Incident remediation (hours per drift event) | Reactive, triggered by client complaint | Proactive, triggered by threshold alert |
| QBR reporting (hours per client per quarter) | Manual data joins across tools | Pre-built attribution from prompt to KPI |
| Compliance review (hours per enterprise client) | Custom crosswalk per audit request | Pre-mapped to NIST AI RMF 2 |
The economics compound at the seat and incident lines. Each additional account under a fragmented stack adds evaluation hours and reporting hours that do not amortize. Under a unified layer, the rubric, the trace schema, and the governance crosswalk are built once and reused across the book. The marginal cost of the next client is closer to onboarding than to building.
That compounding is what makes use-case-level cost and revenue reporting feasible at portfolio scale rather than just on a flagship account.
A Buying Sequence That Matches How You Actually Sell Retainers
The wrong way to buy LLM visibility is to demo five platforms in parallel and pick the one with the prettiest dashboard. The right way matches the order in which an agency actually wins and defends a retainer.
Sequence the purchase against the sales motion:
- Evaluation. Before any client-facing pitch, the agency needs task-level rubrics that prove model choice and prompt design produce content that survives a domain expert's review 6. Without that, the rest of the stack is decoration.
- Observability. Once production is live across multiple accounts, drift, cost, and refusal-rate telemetry are what prevent the next surprise invoice or quality complaint. This is the layer that protects margin between QBRs.
- Governance. When the agency starts pitching enterprise clients in legal, healthcare, or behavioral health, the NIST AI RMF crosswalk becomes a procurement gating item 2. Tools already mapped to Govern–Map–Measure–Manage shorten that cycle.
- Attribution. The QBR is where retention is won, so the layer that joins prompt, output, and downstream revenue signal is the final piece, not the first.
Buying in this order matches how the book actually grows.
Frequently Asked Questions
References
- 1.The State of AI in the Enterprise - 2026 AI report | Deloitte US.
- 2.AI Risk Management Framework | NIST.
- 3.The 2025 AI Index Report | Stanford HAI.
- 4.The 2026 AI Index Report | Stanford HAI.
- 5.The State of AI: Global Survey 2025.
- 6.Evaluating Large Language Models.
- 7.Evaluation and comparison of large language models' responses to questions about optic neuritis.
- 8.The state of AI in early 2024: Gen AI adoption spikes and the tide is rising.