
Key Takeaways
- LLM visibility software inspects model behavior across the full prompt journey—input, retrieved context, tool calls, output, and approval—producing a structured record of what was generated, on what evidence, and by whom.
- NIST frames trustworthy AI as measurable AI built into design and use, and its Generative AI Profile flags limited visibility into model behavior and training data as an active risk 9.
- A complete stack combines four layers: telemetry, repeatable evaluation, provenance signals like watermarking and C2PA metadata, and an approval gate that converts evidence into a publish-or-hold decision.
- Unlike SEO platforms or developer observability tools, visibility software measures the production decision itself, letting multi-location marketing teams scale output while holding cost per approved asset stable.
Why Marketing Leaders Are Asking About LLM Visibility
The integration of large language models (LLMs) into marketing operations has shifted the focus from whether to use AI to how to ensure visibility into its outputs. Marketing teams are increasingly relying on AI for content generation, ad copy, and call summaries, often without individual human review of every piece. This reliance necessitates a new approach to oversight.
Federal guidance, such as NIST's AI Risk Management Framework, emphasizes trustworthy AI as measurable AI, integrated throughout the design, development, use, and evaluation phases 1. The Generative AI Profile highlights a critical challenge: the difficulty in estimating certain generative AI risks due to a "lack of visibility into GAI training data" and the nascent state of measurement 9.
This "lack of visibility" represents a significant operational gap. Unlike SEO platforms that track rankings or analytics stacks that monitor sessions, current tools do not reveal if a model has fabricated a claim, cited outdated information, or misquoted competitor pricing. LLM visibility software is emerging to address this blind spot, prompting budget owners to consider it as a distinct line item.
What LLM Visibility Software Does
LLM visibility software provides inspectability into model behavior across the entire prompt journey: input, retrieved context, tool calls, generated output, and subsequent actions. It continuously captures and structures this data, enabling marketing teams to answer specific questions: what the model produced, based on what evidence, who approved it, and where it was deployed.
This category is evolving to encompass four core functions. NIST's framework advocates for trustworthy AI as a product of integrated design, development, use, and evaluation 1. NIST's testing and evaluation efforts further underscore the importance of observability as repeatable measurement, moving beyond ad hoc checks 2. In essence, visibility software logs events, assesses compliance with standards, verifies origins, and routes outputs for human review before customer exposure.
For marketing organizations, this translates into operational checks that existing tools do not offer. It can identify a fabricated statistic on a service page pre-publication, trace a paid social headline to its original prompt and source documents, and record approvals for regulated claims. The "limited visibility into how models behave and what they were trained on," identified by NIST in its Generative AI Profile, is precisely the gap this software aims to close 9.
The Four Layers of a Visibility Stack
Telemetry: The Raw Record of Model Behavior
Telemetry forms the foundational layer, capturing the prompt, system instructions, retrieved context, any tool or API calls, the model's output, and the downstream action. This comprehensive record is essential for all subsequent layers.
The value lies not in sheer volume but in structured data. Effective telemetry links a published asset to its exact prompt version, retrieval source, model version, timestamp, and the human who handled it. This audit trail allows marketing operations to quickly respond to regulatory inquiries by providing a clear history of a campaign.
NIST's AI Risk Management Framework considers this measurable record a prerequisite for trustworthy AI, emphasizing that trustworthiness must be inherent in design, development, use, and evaluation 1. Such a record supports each of these activities.
For marketing teams managing specialized AI workflows across content, paid media, and call summaries, telemetry also serves as an enduring audit trail, crucial for continuity even with staff changes. The record of model actions and supporting evidence remains accessible, regardless of personnel turnover.
Evaluation: Turning Logs into Repeatable Measurement
While telemetry records what occurred, evaluation determines if those occurrences met established standards. This distinction is vital, as sporadic spot-checking of AI outputs is not robust measurement but rather biased sampling.
NIST's testing and evaluation initiatives, including ARIA and the NIST GenAI Challenge, promote repeatable measurement of AI systems 2. These programs stem from the conclusion that ad hoc inspections are neither scalable nor capable of producing consistent results across different runs or teams.
For a visibility stack, evaluation involves a defined set of checks applied to every system output or a statistically valid sample. These checks include:
- factuality
- brand voice
- claim substantiation against approved sources
- toxicity
- policy compliance
- latency
- cost thresholds
Each check yields a pass, fail, or score, which is appended to the telemetry record. This allows for re-evaluation of the same asset under new standards without re-running the model.
NIST also indicates an expansion of the evaluation toolkit, incorporating statistical models for more robust monitoring 5. For marketing leaders, this means visibility software's credibility depends on its evaluation methods. A vendor that merely logs data without robust evaluation offers storage, not control.
Provenance: Proving an Output's Origin
Provenance addresses the question of an output's origin, distinct from its quality. This becomes critical when regulators, legal counsel, or platform policy teams inquire about the source of a specific claim.
Brookings identifies four primary approaches to provenance: watermarking, content provenance, retrieval-based detectors, and post-hoc detectors 8. Each has varying scalability and reliability.
Watermarking : Embeds a signal directly into the output, scaling well but susceptible to degradation during editing.
Content provenance : Like C2PA, uses cryptographically signed metadata for strong evidence but requires ecosystem support.
Retrieval-based detectors : Compare outputs against known model corpora, offering scalability with probabilistic results.
Post-hoc detectors : Analyze finished content and are generally the least reliable.
NTIA's report on AI output disclosures positions watermarking as a method for establishing provenance through embedded information, framing it as integral to broader accountability 4. The Defense Department's brief on content credentials notes C2PA's rapid progress towards ISO recognition 3.
For marketing organizations, provenance is not a singular feature but a layered system of signals integrated by the visibility stack. A vendor offering only post-hoc detection provides the weakest form of evidence. A solution combining signed metadata with retrieval checks against an approved source library offers more defensible proof.
Approval Governance: The Operational Gate
The first three layers generate evidence; the fourth determines its application. Approval governance introduces human-in-the-loop control, converting telemetry, evaluation results, and provenance signals into a publish-or-hold decision before an asset reaches the customer.
Without this gate, visibility is merely forensic. A fabricated statistic or an outdated claim could still go live, with issues only discovered in audit logs rather than prevented in the approval queue. The NIST Generative AI Profile explicitly states that some risks are difficult to foresee due to limited visibility into training data and immature AI measurement, meaning upstream controls cannot fully replace a pre-deployment checkpoint 9.
Approval governance also operationalizes the evaluation layer. A failed factuality check should route the asset to a specific reviewer, flagging the problematic claim and attaching source documents. A low brand voice score should go to a different reviewer with appropriate authority. This gate transforms advisory evaluations into actionable workflows.
Regulated industries already treat this as compliance infrastructure. The Treasury report on AI in financial services highlights firms using generative AI for risk identification and assessment, aligning with operational risk management guidelines 6. Marketing is following a similar path, with leading teams integrating approval as the top layer of their visibility stack.
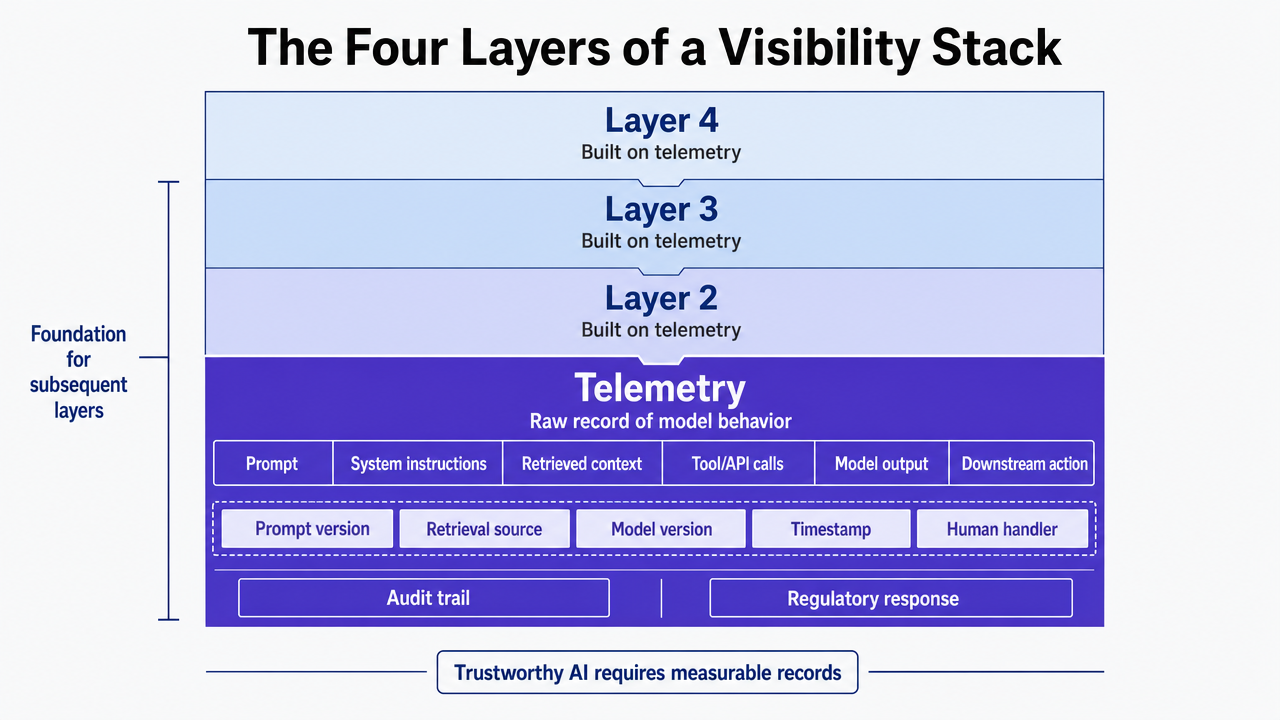 Visualize the four-layer visibility stack architecture described in the section, which is a clear framework with named layers and functions
Visualize the four-layer visibility stack architecture described in the section, which is a clear framework with named layers and functions
Test LLM visibility strategies on live campaigns
Experience measurable impact by deploying and tracking real content initiatives in a full-access environment for seven days.
LLM Visibility vs. SEO Tools and Developer Observability
LLM visibility software is distinct from SEO platforms and developer observability tools, a distinction crucial for marketing budget allocation. SEO platforms assess content performance post-publication, while developer observability tools monitor application behavior in production. Neither addresses the critical moment when an AI system generates a marketing asset and the decision of whether to publish it.
SEO platforms focus on rankings, traffic, and backlinks. They do not record the prompt that generated a paragraph, the sources retrieved by the model, or the substantiation of a claim. A keyword tracker cannot identify a fabricated statistic; it can only show its impact on organic position weeks later, providing post-mortem data at the wrong stage.
Developer observability tools (e.g., LangSmith, Arize, Helicone) operate closer to the model but address engineering concerns: token cost, latency, model drift, and prompt regression. While valuable for model operators, these are largely irrelevant to a marketing operations lead needing to verify who approved a regulated claim and its supporting evidence. These tools log traces but do not gate publication, evaluate brand voice, or produce the audit trail required for legal review.
LLM visibility software for marketing bridges this gap, answering whether an AI-produced asset meets defined standards and providing a record of that decision. NIST's AI Risk Management Framework reinforces this by defining trustworthiness as something measured across design, use, and evaluation, not merely inferred from downstream metrics 1. SEO tools measure outcomes, developer tools measure infrastructure, but visibility software measures the production decision itself, where brand, legal, and pipeline risks originate.
Visibility Patterns in Marketing Workflows
Claim Substantiation for Regulated Content
Service-page copy in regulated industries (e.g., legal, healthcare, home services) often contains claims that are subject to strict scrutiny. AI models generating such pages without substantiation checks create significant liability.
The effective visibility pattern here involves matching every AI-generated claim against an approved source library before reviewer access. A statistic on procedure success rates must trace back to a document in that library. A statement about average response time must link to operational data, not a confident but unsubstantiated sentence from the model.
NIST's Generative AI Profile highlights confabulation as a risk difficult to predict due to immature measurement methods 9. The operational solution is to gate each claim at generation. Failed substantiation routes the asset to a named reviewer, with the specific claim flagged and the missing source attached, preventing a human from having to fact-check from scratch.
Channel-Level Traceability from Prompt to Published Asset
A paid social headline, a service page paragraph, and a call-summary template might all originate from the same retrieval source and prompt. If one generates a complaint, marketing operations needs to quickly identify and address the others.
Traceability enables this. Each published asset carries a record linking it to its prompt version, retrieved documents, model version, evaluation results, and the approving human. This record resides with the asset, not in a separate log only accessed during crises.
NTIA's report on AI output disclosures views watermarking and embedded signals as part of broader accountability 4. For marketing, this means treating traceability as an inherent property of the asset. A landing page revision in October should resolve to the same chain of evidence as the paid headline that drove traffic to it in July. When a platform policy team or attorney general inquires about a claim's origin, the answer is a verifiable record, not a post-hoc reconstruction.
Cost-Per-Approved-Asset as a Key Performance Indicator
Focusing on "cost per asset" is misleading as it rewards unchecked volume. The more appropriate KPI for a visibility-first workflow is "cost per approved asset"—the total cost of producing content that has passed evaluation, has verifiable provenance, and a recorded approver.
This metric changes how marketing leaders interpret production reports. A team generating hundreds of drafts weekly at a low unit cost may appear efficient until an approval rate of twelve percent is revealed. Conversely, a team producing fewer drafts but achieving an eighty-percent approval rate is more cost-effective per shipped asset and requires less rework.
NIST's AI Risk Management Framework emphasizes building trustworthiness into use and evaluation, rather than measuring it after deployment 1. Cost per approved asset operationalizes this by consolidating evaluation pass rates, reviewer time, and rework cycles into a single, CFO-friendly metric. Marketing teams using specialist AI workflows can compare this metric across different content types, a level of transparency traditional agency invoices often lack.
See How Top Teams Achieve LLM Visibility Across All Marketing Channels
Request a walkthrough of unified LLM visibility software in action—benchmark reporting, workflow orchestration, and live analytics designed for marketing organizations operating at scale.
Operator Economics for Multi-Location Marketing
For multi-location operators—such as DSO groups, behavioral health networks, or multi-office law firms—the challenges of AI content production are amplified. Each location requires unique service pages, local landing pages, paid headlines, and call-summary templates. This multiplication makes traditional agency-managed QA economically unfeasible, highlighting the value of visibility-gated AI execution.
The cost structure shifts across four key inputs:
- review cycles per campaign
- FTE-hours per approved asset
- channels under management per location
- monthly tooling cost
The first three are existing operational variables; the fourth is introduced by visibility software.
| Input | Agency-managed QA | Approval-gated AI execution |
|---|---|---|
| Review cycles per campaign | 3–5 across briefing, draft, revision, legal, publish | 1 gated review per asset with evidence attached |
| FTE-hours per approved asset | Variable, scales linearly with location count | Variable, scales with approval throughput, not output volume |
| Channels under management per location | Coordinated across separate vendors | Unified telemetry across content, paid, social, calls |
| Monthly tooling cost | Embedded in retainer, not itemized | $599/mo platform line (Vectoron trial) |
The key is not which column is inherently cheaper, but which provides a defensible record across numerous locations without a linear increase in headcount. NIST's AI Risk Management Framework stresses that trustworthiness must be built into design, development, use, and evaluation, not reconstructed retrospectively 1. For multi-location operators, this built-in property stabilizes the cost per approved asset as the number of locations grows. Agency QA scales by adding reviewers; visibility-gated execution scales by adding evaluation criteria to the same gate. This simplifies the financial discussion by providing a fixed denominator for the latter approach.
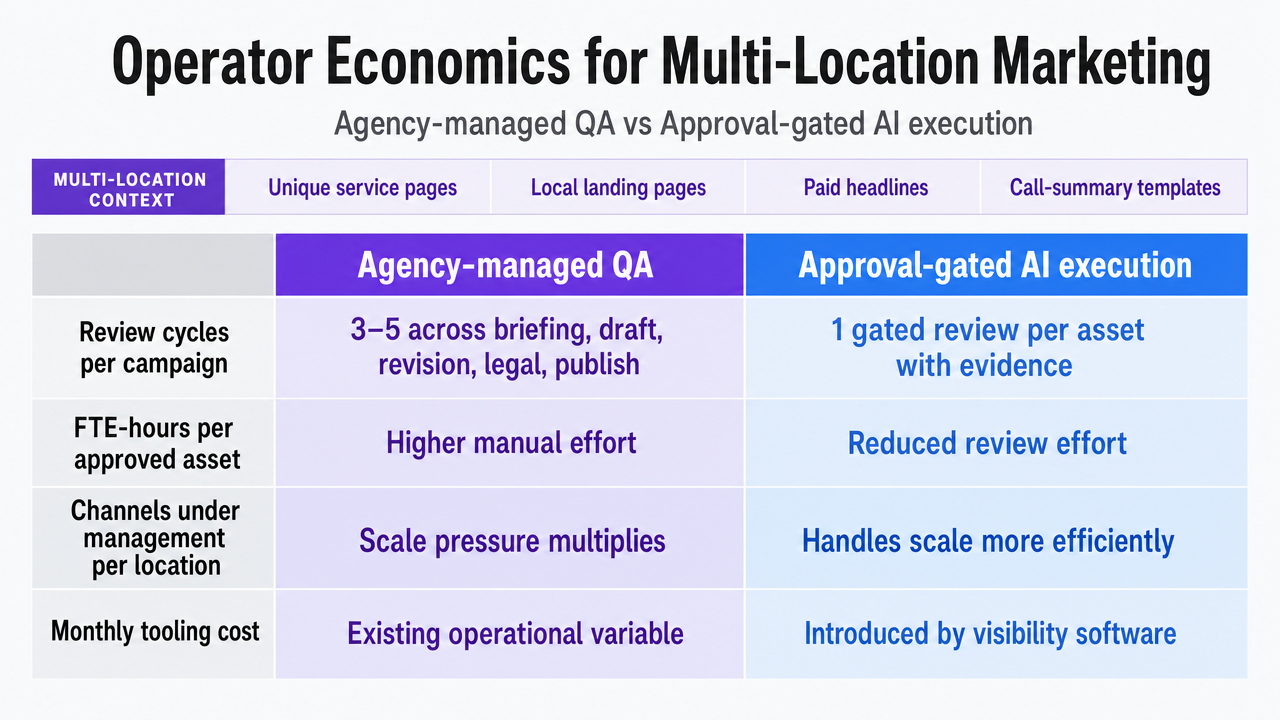 Translate the in-article comparison table into a clearer side-by-side visual comparing Agency-managed QA vs Approval-gated AI execution across the four operating inputs cited in the section
Translate the in-article comparison table into a clearer side-by-side visual comparing Agency-managed QA vs Approval-gated AI execution across the four operating inputs cited in the section
Vendor Questions for LLM Visibility Software
While many LLM visibility pitches may sound similar, critical differences emerge when asking targeted questions aligned with the four layers of a visibility stack.
On telemetry. Inquire what is recorded for every output and if the record links the published asset to the prompt version, retrieval source, model version, and named approver. A vendor that logs prompts and outputs but cannot trace a live URL back to this complete chain offers only partial evidence.
On evaluation. Ask which checks are included, which are configurable, and how scores are generated—rule-based, model-graded, or statistical. NIST has expanded the evaluation toolbox to include statistically valid methods for repeated monitoring 5. A vendor whose evaluation layer relies solely on one model grading another, without statistical grounding, provides a weaker form of measurement than current federal guidance suggests.
On provenance. Determine which of the four detection families (watermarking, content provenance, retrieval-based, post-hoc) the product covers and how it integrates them 8. Solutions relying on a single family are limited. Comprehensive coverage that combines signed metadata on generated assets with retrieval checks against an approved source library offers more defensible evidence.
On approval governance. Confirm if a failed evaluation can route a specific asset to a named reviewer, with the problematic claim and source documents attached, before publication. If the response describes a notification, the product is logging. If it describes a gate, it provides control.
Frequently Asked Questions
References
- 1.AI Risk Management Framework.
- 2.AI test, evaluation, validation and verification (TEVV) | NIST.
- 3.Strengthening Multimedia Integrity in the Generative AI Era.
- 4.AI Output Disclosures: Use, Provenance, Adverse Incidents.
- 5.New Report: Expanding the AI Evaluation Toolbox with Statistical Models.
- 6.Artificial Intelligence in Financial Services.
- 7.Reducing Risks Posed by Synthetic Content: An Overview of Technical Approaches to Digital Content Transparency.
- 8.Detecting AI fingerprints: A guide to watermarking and beyond.
- 9.Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile.