
Key Takeaways
- Traditional rank tracking measures a shrinking slice of demand as LLM answers synthesize citations, entities, and topic clusters rather than fixed positions on a ten-blue-links page 6.
- A credible visibility tool measures citation grounding, surface coverage across ChatGPT, Gemini, Perplexity, AI Overviews, and Web Guide, and rejects unreliable AI-authorship scoring 1, 10.
- Score vendors on five criteria: multi-surface coverage, entity-level attribution, defensible sampling, production pipeline integration, and client-ready export quality that survives forwarding to a CFO.
- Measurement-only trackers, SEO suite add-ons, and production-integrated platforms each break at a different point, so agencies should match archetype to their fix-cycle workflow, not the demo polish.
- Portfolio economics turn on analyst hours per report, not seat price, since a two-hour swing across 40 accounts costs roughly half a full-time analyst per month.
- Clients now ask fairness questions about competitor citations, so tools must separate informational, comparative, and branded prompt clusters and log uncited paraphrases as distinct events 5.
- Run a fixed buying sequence: substitute your own prompt set, demand written surface disclosure, test a real citation-loss explanation, and inspect what payload leaves the platform for production 11.
Why AI-Answer Monitoring Broke the Rank Tracker Model
Rank tracking assumes a stable artifact: a ten-blue-links page where a URL either sits at position four or it does not. That artifact is dissolving. Analyst modeling for the 2025-2030 window projects that roughly 25% of search queries could route through LLM interfaces in the coming years, with traditional search engine volume declining by an estimated 25% by 2026 as users shift toward generative assistants 6. Those figures come from industry forecasts, not measured user logs, and adoption curves vary by region and vertical. The direction, however, is not in dispute.
The measurement problem this creates is structural, not cosmetic. An LLM answer is synthesized from multiple retrieved sources, cited inconsistently across sessions, and reorganized by topic rather than ranked by position 1. A client can hold position three on a commercial query and still be absent from the Perplexity answer, the ChatGPT response, and the AI Overview that now sits above the classic result set. Conversely, a page ranked twelfth can be cited in three of four LLM surfaces because its entity data is cleaner.
Agencies reporting only on SERP positions are reporting on a shrinking slice of client demand. The category the market now needs measures citations, entities, and answer surfaces, not rank.
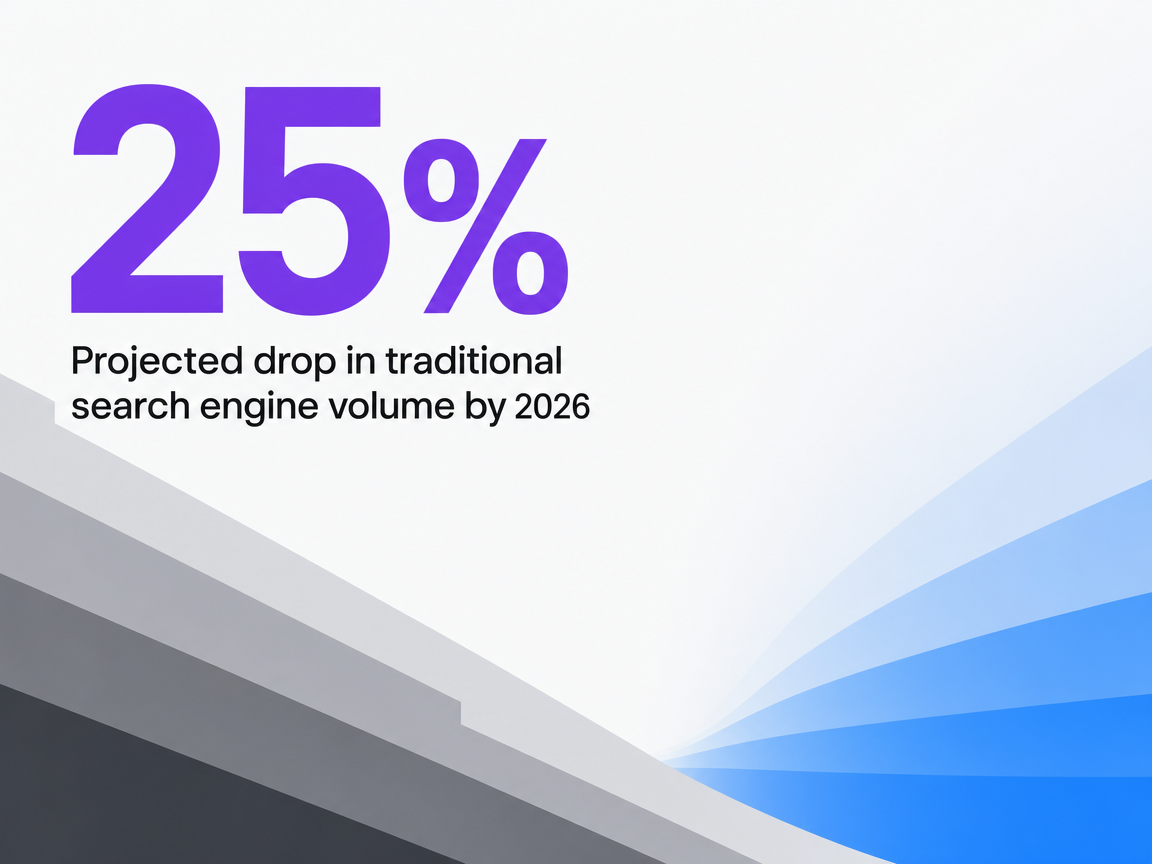 Projected drop in traditional search engine volume by 2026
Projected drop in traditional search engine volume by 2026
Projected drop in traditional search engine volume by 2026
What an LLM Visibility Tool Actually Measures
Citation Grounding and Retrieval Signals
The unit of measurement inside an LLM answer is the citation, not the position. When ChatGPT, Gemini, or Perplexity synthesizes a response, it retrieves candidate passages, scores them for relevance and freshness, and grounds specific claims in specific sources 1. Whether a client brand appears in that answer depends on retrieval mechanics that operate below the surface: which passages were pulled, which were selected as citations, and which were paraphrased without attribution.
A competent visibility tool tracks three grounding signals that traditional rank trackers ignore:
- The first is citation frequency across a defined prompt set: how often a brand's domain is named as a source across repeated queries.
- The second is passage selection: which specific URLs and text blocks are pulled into the answer window.
- The third is freshness sensitivity, since LLM retrieval layers weight recent content differently across surfaces 1.
Agencies evaluating vendors should ask how the tool distinguishes an in-answer citation from a linked source in a follow-up panel. Those are separate visibility states with different client outcomes. A tool that reports both as a single "mention" flattens the data the Head of SEO actually needs to defend or explain a monthly report.
Surface Coverage Beyond Linear Rankings
Google's Web Guide, launched as a Search Labs experiment, organizes results into AI-generated topic clusters rather than a linear top-ten list 9. That shift is not cosmetic. It means a client can be strongly present in one topic cluster, invisible in an adjacent one, and entirely absent from the AI Overview that sits above both. A single "rank" value cannot describe that state.
Surface coverage refers to how many distinct answer environments a visibility tool samples. The working list for agency reporting now includes ChatGPT, Gemini, Perplexity, Google AI Overviews, and increasingly AI-organized SERPs like Web Guide. Each surface uses a different retrieval architecture and citation convention 1. A tool that only samples one or two of these gives the client a partial picture, which becomes a retention risk when a competitor's tool shows the missing surfaces.
Coverage also has a temporal dimension. LLM answers drift session to session, and topic clustering changes as the underlying model updates its groupings 9. Serious tools sample the same prompt set on a fixed cadence and report the variance, not just the snapshot. That variance number is what lets an agency separate real movement from noise in a client review.
The AI-Detection Trap in Quality Scoring
Several vendors now market a "content authenticity" score that flags pages as likely AI-generated, framing the metric as a proxy for quality risk. The underlying research does not support that framing. A 2024 peer-reviewed survey on LLM-generated text detection concludes that the task remains a binary classification problem with high false-positive and false-negative rates across current methods 10. A separate evaluation of detectors in scholarly publishing reports variable performance and warns against using detector output as sole evidence 2.
Google's own guidance closes the loop. The company states that appropriate use of AI is not against its guidelines and that ranking evaluation focuses on content quality rather than production method 7, 8. A visibility tool that scores client pages on estimated AI authorship is measuring something Google explicitly does not penalize, using classifiers the academic literature flags as unreliable.
Agencies should treat AI-detection scores as a red flag in a vendor demo, not a feature. The metric worth paying for is whether a page is being cited by LLMs, not whether a classifier thinks a human wrote it.
The Five Criteria That Separate Serious Tools From Dashboards
Multi-Surface Query Coverage
A demo that only shows ChatGPT results is a demo of a product that will underserve a client portfolio within two quarters. The working set of answer environments an agency now has to report on includes ChatGPT, Gemini, Perplexity, Google AI Overviews, and AI-organized SERPs like Web Guide 9. Each of these surfaces uses a different retrieval stack, a different citation format, and a different refresh cadence 1.
Coverage criteria should be scored on three axes:
- Which surfaces the tool samples natively rather than through screenshots
- How frequently each surface is re-queried
- Whether the tool handles surface-specific conventions such as Perplexity's numbered citations versus Gemini's inline links
A tool that covers four surfaces at daily cadence produces a materially different report than one that covers two at weekly cadence, even if both claim "AI visibility tracking" on the marketing site.
Agencies should also ask which surfaces the vendor plans to add and on what timeline, because the surface list is expanding, not stabilizing.
Entity-Level Attribution
Rank tracking treats the URL as the primary object. LLM visibility has to treat the entity as the primary object, because generative answers cite brands, people, products, and places, not just pages. A client may be mentioned by brand name in a Perplexity answer without any of its URLs appearing in the citation panel. A traditional tracker records nothing. An entity-aware tool records a brand mention, links it to the underlying knowledge graph node, and separates it from a linked citation.
The practical test during vendor evaluation: ask the tool to report every mention of a client brand across a 200-prompt set, then ask it to separate cited URL appearances, uncited brand mentions, and competitor mentions in the same answer. A serious tool returns three distinct counts. A dashboard returns one blended number.
Entity attribution also matters for content planning, since production teams need to know which entities LLMs already associate with the client and which are being awarded to competitors 11.
Sampling Method Defensibility
LLM answers vary session to session, model version to model version, and region to region. Any visibility number is therefore a sample, not a measurement. The question is whether the sample is defensible when a client's CMO asks how it was constructed.
A defensible sampling method has four documented components:
- The prompt set and how it was built
- The query cadence
- The model versions and regions queried
- The variance reported alongside each metric
Vendors that cannot produce a written sampling methodology should be scored out. Vendors that produce one but refuse to disclose prompt-set construction should be scored down, because the prompt set is where most measurement bias lives.
The fairness dimension belongs here too. Research on LLM search has flagged that generative systems can privilege certain sources and underrepresent others 5. A tool that samples only high-commercial-intent queries will miss representation gaps on informational queries where competitors may be quietly capturing the entity association. Prompt-set breadth is a defensibility question, not a nice-to-have.
Production Pipeline Integration
Measurement without production is a report that ages badly. The reason a client is missing from an AI Overview is almost always upstream: thin entity coverage, weak structured data, outdated pages, or an FAQ block that does not match the phrasing of high-frequency prompts 11. A visibility tool that surfaces the gap but hands it back to the agency as a PDF forces the same manual triage cycle that made AI-search reporting unprofitable in the first place.
Integration should be scored on how directly the tool routes findings into content work. The specific hooks that matter:
- Exportable briefs tied to underperforming prompts
- Entity gap lists that map to schema updates
- Freshness alerts that trigger a rewrite queue
- Citation-loss signals that flag pages needing reinforcement
A tool that generates any of these as a structured payload the production team can pick up shortens the fix cycle from weeks to days.
Agencies scaling AI-search work across 40 or more accounts cannot absorb a measurement-to-production handoff that requires an analyst to translate the report every time.
Reporting Export and Client-Ready Outputs
The final criterion is unglamorous and decisive: whether the tool produces reports a client will actually read. Raw citation counts, prompt-level heatmaps, and entity graphs are useful internally, but client reviews need a narrative that ties movement to work done, in a format that survives being forwarded to a CFO.
Export quality should be evaluated on white-label templates, API access for embedding into agency dashboards, and the ability to segment reporting by surface, entity, and prompt cluster. Structured content and entity coverage recommendations should carry into the export so the client sees both the visibility state and the production actions that changed it 11. The scoring rubric below consolidates all five criteria into a weightable framework agencies can adapt to internal RFPs.
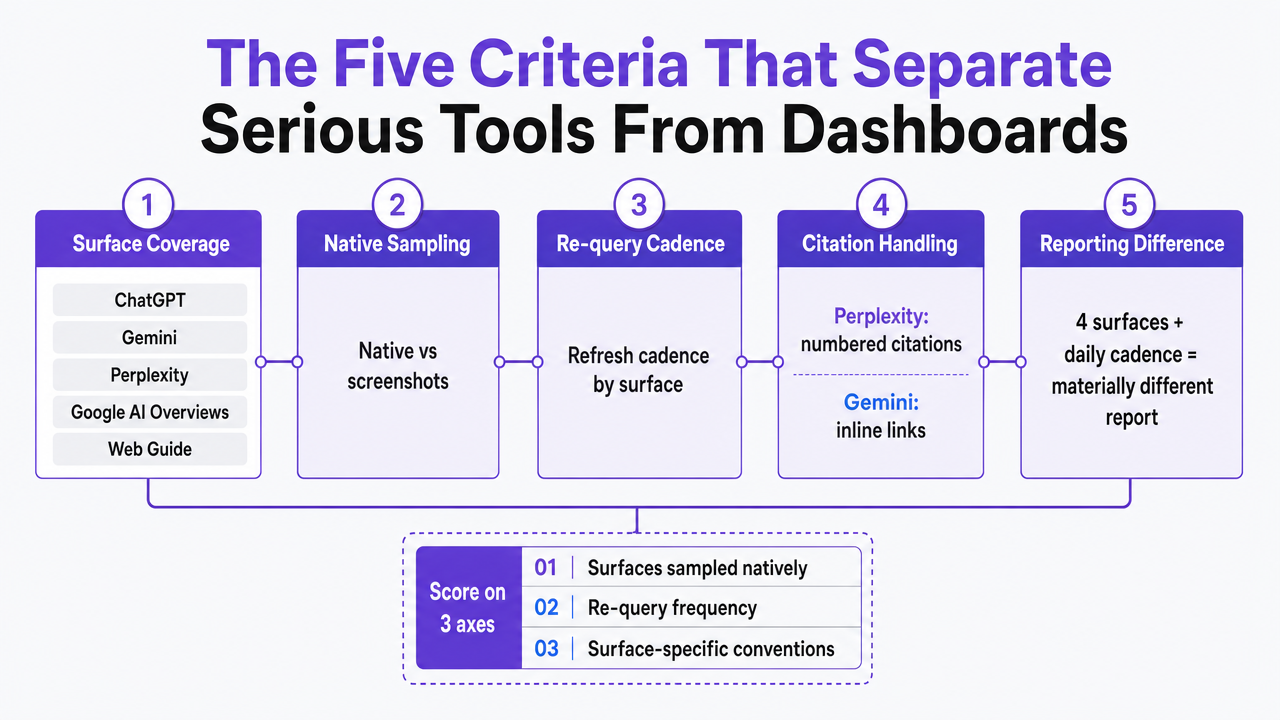 Process infographic visualizing the five scoring criteria as a connected framework agencies can apply during vendor evaluation
Process infographic visualizing the five scoring criteria as a connected framework agencies can apply during vendor evaluation
Test LLM SEO visibility insights on live content
Experience real-time LLM ranking analysis across your client sites before making a long-term commitment.
Three Tool Archetypes and Where They Break
Measurement-Only Trackers
Pure-play LLM visibility trackers are the newest category on the market and the easiest to demo. They query a defined prompt set across ChatGPT, Perplexity, and sometimes Gemini, then return citation counts, brand mention frequencies, and share-of-voice charts. The dashboards are clean, the export formats are polished, and the sales cycle is short.
The break point is downstream. Measurement-only trackers surface the gap and stop. When a client's brand is absent from three of four AI Overviews on high-intent queries, the tool flags the absence but returns no structured payload the production team can act on. The Head of SEO still needs an analyst to translate the report into content briefs, entity fixes, and schema updates, which is exactly the manual step that makes AI-search reporting unprofitable at 40-plus accounts.
These tools also tend to sample narrowly. Vendors default to commercial-intent prompts because those demo well, leaving informational queries where competitors quietly win the entity association 5. For an agency, that produces reports that look strong until a client's own team runs a broader prompt set.
SEO Suite Add-Ons
The established SEO platforms have all shipped AI-visibility modules bolted onto existing rank-tracking infrastructure. The pitch is consolidation: one login, one contract, one reporting layer that covers classic SERPs and LLM surfaces. For agencies already paying for enterprise seats, the incremental cost looks modest.
The break point is architectural. Rank trackers were built to poll a stable SERP artifact on a fixed cadence. LLM answers require a different retrieval model, because grounding signals, citation conventions, and freshness weighting vary by surface 1. Add-on modules often collapse this variance into a single "AI visibility score" that hides which surface moved and why. When a client asks why the score dropped, the analyst cannot answer without leaving the suite and checking each surface manually.
Coverage of AI-organized results like Web Guide also tends to lag in these products, since the roadmap sits behind other suite priorities 9. Agencies choosing this archetype should audit the actual sampling methodology behind the module, not the marketing page, before renewing at the higher tier.
Production-Integrated Platforms
The third archetype treats measurement as the input to a production workflow, not the output of a reporting tool. These platforms sample LLM surfaces on a defined cadence, attribute citations at the entity level, and route findings directly into content briefs, schema updates, and freshness queues that a strategist approves before execution 11.
The break point sits on the buyer side. Production-integrated platforms require an agency to change how work moves through the shop. If the content team still operates on a monthly editorial calendar built in a spreadsheet, the integration surface goes unused, and the platform gets scored on its dashboard alone, which is not what it was built for. Heads of SEO evaluating this archetype should map the current fix cycle first: when the visibility tool flags a citation loss on Tuesday, who owns the rewrite by Friday, and what approval gate sits between them.
When the workflow is aligned, this archetype compresses the measure-to-fix cycle from weeks to days and removes the analyst-translation step that caps portfolio scale. Vectoron sits in this category, alongside a small set of platforms building toward the same closed loop.
Portfolio Economics: Reading the Real Cost per Monitored Client
Audience scope shifts here from single-account measurement to portfolio operations. A Head of SEO running 15 to 80 client accounts is not buying a visibility tool for one dashboard; they are buying a unit-economics profile that has to hold up across the whole book. The relevant number is not the vendor's monthly seat price. It is the loaded cost per monitored client per month, including analyst hours to translate raw data into a report the account team can send.
That cost profile matters more as AI query share grows. Analyst modeling for the 2025-2030 window projects roughly 25% of search queries could route through LLM interfaces in the coming years 6, which means AI-visibility reporting is moving from a specialty add-on to a line item on every retainer. Absorbing that expansion without adding analyst headcount is the constraint every archetype gets scored against.
The table below is a variables-only framework. Agencies plug in their own seat cost, prompt volume, and blended analyst rate to produce a cost per report figure that can be defended in a margin review.
| Variable | Measurement-Only Tracker | SEO Suite Add-On | Production-Integrated Platform ||---|---|---|---|| Monitored prompts per client per month | 100-300 | 50-150 | 200-500 || Surfaces sampled natively | 2-3 | 1-2 | 3-5 || Analyst hours per monthly report | 4-8 | 3-6 | 1-3 || Translation step to production briefs | Manual | Manual | Structured payload || Cost per report formula | (seat cost / clients) + (analyst hours × rate) | (incremental module cost / clients) + (analyst hours × rate) | (seat cost / clients) + (analyst hours × rate) |
The decisive line is the analyst-hours row. At 40 accounts, a two-hour swing per client per month is 80 hours, roughly half a full-time analyst. That delta, not the sticker price on the vendor contract, is where portfolio margin is won or lost.
 Projected share of search queries handled by LLMs in the near future
Projected share of search queries handled by LLMs in the near future
Projected share of search queries handled by LLMs in the near future
See How Leading Agencies Track LLM Visibility and Strategic Impact at Scale
Request a walkthrough of automated LLM visibility reporting and benchmarking—built for agencies managing multi-client SEO, with transparent outputs and actionable performance data.
Fairness, Representation, and the Reports Clients Will Ask About
Clients have started asking a question that rank reports were never built to answer: why does a competitor keep showing up in ChatGPT answers on queries where the client outranks them on Google? The question is a fairness question dressed as a visibility question, and the honest reply requires data most tools do not collect.
Research on the future of search flags that LLM systems can privilege certain sources and underrepresent others, producing representation gaps that classical retrieval metrics miss 5. Those gaps concentrate on informational and comparative queries, where the model synthesizes an answer from a small set of trusted domains and quietly locks competitors into the entity association. A visibility tool that only samples branded and high-commercial-intent prompts will report clean numbers while the client's category authority erodes on the queries that feed the top of funnel.
Agencies should ask vendors three specific questions before signing:
- Does the tool report representation share across informational, comparative, and branded prompt clusters as separate figures?
- Does it flag when a competitor is cited on a query where the client is not, and log that as a distinct event rather than a null?
- Does the export label prompts where the answer paraphrased the client without citation, since that is a fairness state the client will notice and ask about?
Tools that return one blended "share of voice" number cannot support that conversation.
A Buying Sequence That Survives Vendor Demos
Most vendor demos are optimized to hide the weaknesses that matter. The prompt set is curated, the surfaces sampled are the ones the tool covers best, and the client accounts on screen have been cherry-picked for movement. A buying sequence that survives contact with a sales engineer runs in a fixed order and refuses to skip steps.
- Prompt substitution. Before the demo begins, agencies should send the vendor a prompt set of 50 queries drawn from three live client verticals, mixing branded, informational, and comparative intents. Any tool that cannot ingest an external prompt set inside the demo window is scored down.
- Surface disclosure. The vendor names every LLM surface sampled, the cadence, the model versions queried, and the regions covered, in writing. Vague answers here predict vague reports later 1.
- Citation-loss test. Pick a client page that lost an AI Overview citation in the last 60 days and ask the tool to explain why. A serious tool points to a freshness gap, an entity mismatch, or a competitor's structured content gain 11. A dashboard shows a red arrow.
- Production handoff. Ask what leaves the platform when a gap is found: a brief, a schema payload, a rewrite ticket, or a PDF. The answer determines whether the tool compresses the fix cycle or extends it. Vectoron and a small set of peers built around this handoff; measurement-only trackers cannot fake it in a demo.
Frequently Asked Questions
References
- 1.When Search Engine Services meet Large Language Models.
- 2.Can we trust academic AI detective? Accuracy and limitations of AI-generated text detection tools in scholarly publishing.
- 3.How NORC Is Protecting Data Quality in the Age of AI.
- 4.Artificial Intelligence Tools for Detection, Research and Writing.
- 5.The future of search: a conversation with Chirag Shah.
- 6.When Will AI Search Beat Google? 2025–2030 Forecast.
- 7.Google Search's Guidance on Generative AI Content on Your Website.
- 8.Google Search's guidance about AI-generated content.
- 9.Web Guide: An experimental AI-organized search results page.
- 10.A Survey on LLM-Generated Text Detection: Necessity, Methods, and Challenges.
- 11.LLM and Visibility: How to Optimize Your SEO?.