
Key Takeaways
- A single visibility score misleads because citation behavior varies sharply across models and shifts under prompt rewording, so accuracy requires composite measurement across coverage, variability, governance, and outcomes 1.
- The disqualification framework forces vendors to clear five criteria before any demo, mapping each to NIST AI RMF functions so marketing directors can defend the choice to a CFO or counsel.
- Multi-model citation tracking matters because patients move between Google AI Overview, Perplexity, ChatGPT, and DeepSeek, and each system attributes sources differently rather than uniformly 16.
- Prompt and input variability testing replaces snapshot scoring, since rewording and regional phrasing can flip whether a practice gets cited and stability scores belong next to visibility numbers 10.
- Sentiment and entity accuracy must resolve at the location level, capturing answer-level polarity per office and slicing by language and geography to surface bias patterns aggregates hide 6.
- Governance with a versioned audit trail separates configuration from approval, logs every prompt and dashboard change, and embeds bias monitoring so conclusions remain reconstructable months later 1, 2.
- Outcome linkage ties each citation event to call tracking, form submissions, and CRM stages, because mention volume alone cannot tell a CFO whether AI presence creates or cannibalizes booked consults 8, 9.
- Pure-play AI visibility trackers clear multi-model coverage but stall on prompt variability, governance, and outcome linkage, making them sensors rather than complete measurement systems.
- Enterprise SEO suites with AI Overview modules offer integration with rank tracking but under-sample Perplexity and DeepSeek and inherit audit trails built for rank changes, not prompt versioning 16.
- Brand mention and sentiment platforms bring strong entity resolution and bias slicing from social listening, but their LLM sampling rarely tests phrasing variance or connects to call attribution 6.
- Vectoron functions as a measurement-plus-execution layer where strategist recommendations route through a Command Center requiring human sign-off, satisfying governance and outcome-linkage criteria in one workflow 1, 8.
- For directors running 20 or more locations, consolidation math favors one governed layer over five stacked contracts, since governance scales worse than cost across audit surfaces and vendors 1, 11.
Why a Single Visibility Score Fails the Accuracy Test
Most AI visibility platforms sell a headline number: a share-of-voice percentage, a citation rate, or a brand-mention index pulled from one model at one moment. That number is comforting to put in a board deck. It is also the wrong unit of measurement for a DSO marketing director who has to defend a software line item against a CFO who already pays for call tracking, rank tracking, and a CRM.
The accuracy problem starts with the models themselves. A 2026 benchmark comparing Google Gemini 2.5 Pro, ChatGPT 4.1, Perplexity AI, and DeepSeek R1 found that citation behavior diverged sharply across systems, with ChatGPT 4.1 scoring well on clarity yet failing to attribute sources properly 16. A score derived from one model does not predict what a patient sees in another. Input variability compounds the issue. Research on large language models under perturbed inputs found stable behavior in routine cases but meaningful degradation as prompts shifted 10. Snapshot scoring hides that drift.
NIST frames trustworthy AI measurement as a continuous discipline across govern, map, measure, and manage functions, not a single output reading 1. Accuracy, in this category, is a composite: multi-model coverage, prompt-variability testing, governance, and a line back to booked patients. The rest of this piece evaluates tools against that bar.
The Disqualification Framework: Five Criteria Before Any Demo
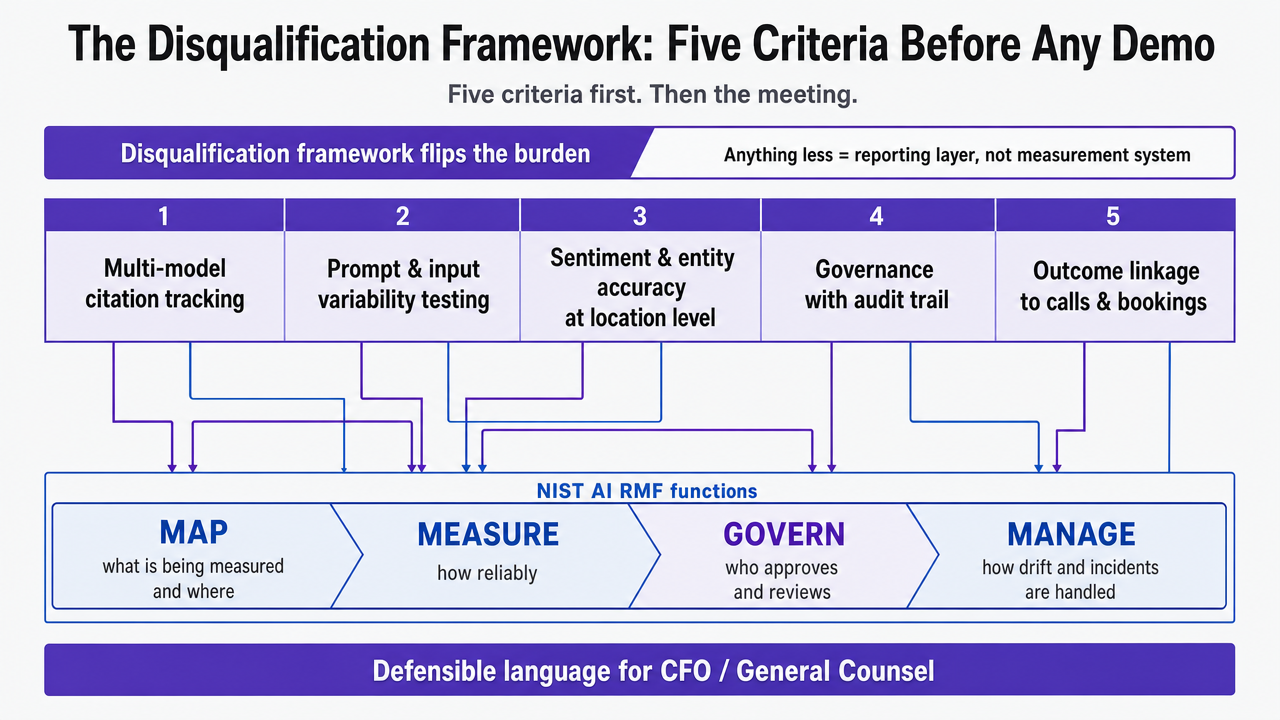
Vendor demos optimize for what looks good in a 30-minute screen share. A disqualification framework flips the burden: a tool earns the meeting by clearing five criteria first. Anything less is a reporting layer, not a measurement system.
The five criteria are multi-model citation tracking, prompt and input variability testing, sentiment and entity accuracy at the location level, governance with an audit trail, and outcome linkage to calls and bookings. Each maps to a NIST AI RMF function: map (what is being measured and where), measure (how reliably), govern (who approves and reviews), and manage (how drift and incidents are handled) 1.
The mapping matters because it gives a marketing director defensible language in front of a CFO or general counsel. "We selected a vendor that satisfies the measure and govern functions of the federal AI risk framework" lands differently than "the dashboard looked clean." It also forces vendors to answer how they handle the parts of measurement they would rather skip: source attribution variance across models, instability under prompt changes, and the line connecting a citation to a booked consult. The next five sections work through each criterion in order.
 Visualize the five disqualification criteria and their mapping to NIST AI RMF functions, which the section explicitly describes as a structured framework
Visualize the five disqualification criteria and their mapping to NIST AI RMF functions, which the section explicitly describes as a structured framework
Criterion One: Multi-Model Citation Tracking That Reflects How Models Actually Cite
A visibility platform that only watches ChatGPT is measuring one window into a multi-window house. The patient researching implant providers in Phoenix may start in Google's AI Overview, switch to Perplexity for citations, and finish in ChatGPT. Each system constructs its answer differently, and each cites differently.
The benchmark study of generative AI tools interpreting the WHO TB mutation catalogue made this concrete. Researchers evaluated Google Gemini 2.5 Pro, ChatGPT 4.1, Perplexity AI, and DeepSeek R1 across accuracy, completeness, clarity, source citation, and hallucinations. ChatGPT 4.1 scored well on clarity but lacked proper citations, while other systems handled attribution differently 16. The scope is medical, not marketing, but the mechanism transfers: citation behavior is a property of the model, not the topic. A DSO brand surfacing in Perplexity with a clean source link does not necessarily surface anywhere in ChatGPT's answer to the same query.
That has direct selection implications. A qualifying tool tracks citations across at least the four major systems patients actually use, distinguishes between an inline citation, a source list reference, and a passing brand mention, and reports each separately. Tools that aggregate everything into a single "AI presence score" hide the variance that determines whether a prospective patient ever sees a link to click.
Two further checks separate measurement from marketing copy. First, the tool should report citation type, not just citation count: an answer that names the practice without linking is operationally different from one that links to the location page. Second, the tool should refresh frequently enough to detect model updates, since the same prompt can produce different citations after a system update. Vendors who cannot answer how often they re-query each model, and how they version their results against model releases, are selling a screenshot.
Criterion Two: Prompt and Input Variability Testing, Not Snapshot Scoring
The same patient query, phrased three ways, returns three different answers. "Best dentist near me," "top-rated dental implant providers in Scottsdale," and "who does All-on-4 in Phoenix" route through different reasoning paths inside the same model. A visibility platform that runs one canonical prompt per week and calls the result a score is measuring its own convenience, not the brand's actual exposure.
The evidence for instability is direct. Research on large language models under input variability found performance stable or improved in more than half of cases under common variations, but degradation appeared as perturbation levels increased 10. Translated into a marketing context: surface-level rewording often holds, but longer-tail phrasing, regional language, and clinical-versus-consumer vocabulary can flip whether a practice gets cited at all.
A qualifying tool runs prompt sets, not prompts. For each tracked topic, it should test branded queries, unbranded category queries, location-specific variants, and at least one adversarial rewording, then report variance, not just the mean. Stability scores belong next to the visibility number. If a vendor cannot show how often a brand's citation rate swings within a single week across phrasing variants, the dashboard is a snapshot dressed as a trend line.
Test AI-driven visibility metrics on real campaigns
Experience live reporting accuracy using your own marketing data before committing to a long-term solution.
Criterion Three: Sentiment and Entity Accuracy at the Location Level
A national share-of-voice number is useless to a DSO running 80 offices. The brand can be cited approvingly in answers about "family dentistry" while the Scottsdale location gets described as "closed" or merged with a competitor two suburbs over. Entity accuracy at the location level is where AI visibility either earns its keep or quietly leaks revenue.
A qualifying tool resolves the practice name, address, phone, hours, and service mix per location, then checks whether each model returns those facts correctly. It also captures sentiment polarity in the answer itself, not just in the reviews the model pulled from. An answer that names the practice but characterizes wait times as "often long" is a different commercial signal than one that calls the same practice "highly rated for sedation dentistry."
Bias monitoring belongs here too. Research on bias in healthcare AI documents how representation and measurement gaps propagate across model outputs, with consequences for which populations get accurate information 6. A visibility tool that reports sentiment in aggregate, without slicing by location and query intent, will average away the patterns that matter most to a regional director deciding where to reinforce reputation work.
Criterion Four: Governance, Audit Trail, and Bias Monitoring
Governance is the criterion that separates a measurement system from a marketing toy. NIST defines the govern function as the policies, processes, and accountability structures that make AI risk decisions traceable and reviewable 1. Translated into a visibility platform, that means three things:
- who can change what is being measured,
- who signs off on conclusions before they reach a P&L conversation, and
- whether the chain of evidence can be reconstructed six months later when a regional VP asks why the brand lost citation share in three states.
A qualifying tool keeps a versioned record of every prompt set, model query, citation result, and dashboard change, with timestamps and user identity. It also separates the analyst who configures tracking from the approver who signs off on reported findings, mirroring the structured, measurable process NIST describes as the baseline for trustworthy AI 2. Tools that overwrite history on each refresh fail this test. So do tools that let any seat-holder mutate the prompt library without a log.
Bias monitoring belongs inside the same governance layer rather than as a side feature. Healthcare AI research documents how representation and measurement bias propagate quietly across model outputs, with disproportionate effects on specific populations 6. For DSO marketing, that translates into citation patterns that may systematically underweight Spanish-language queries, suburban locations, or pediatric service lines. A platform that does not slice visibility and sentiment by language, geography, and demographic-adjacent query intent cannot detect those gaps. The audit trail and the bias slice are the same governance object: both exist so a marketing director can answer, on demand, what the system measured, what it missed, and who approved the conclusion.
Criterion Five: Outcome Linkage to Calls, Consults, and Booked Patients
Citations are inputs. Booked consults are outputs. A visibility platform that cannot draw a line between the two is selling a vanity index, no matter how many models it queries or how clean its sentiment slicing looks.
The click-through problem makes this concrete. Pew found that 58% of respondents conducted at least one Google search in March 2025 that produced an AI-generated summary, and users were less likely to click links when an AI summary appeared 9. That is a behavioral shift inside one channel, measured on general consumer search behavior rather than dental queries specifically, but the operational implication holds: a brand can win citation share inside an AI Overview and still lose the click that would have triggered a tracked call. If the visibility tool stops at the mention, the marketing director cannot tell the CFO whether rising AI presence is creating, replacing, or cannibalizing qualified calls.
A qualifying tool ties each tracked query and citation event to downstream signals already flowing through the marketing stack: call tracking session data, form submissions, booking platform conversions, and CRM-stage progression. At minimum, that means passing query-level identifiers into call tracking so a citation in Perplexity for "sedation dentistry in Mesa" can be reconciled against the calls that location received that week. Tools that report only mention volume, with no hook into call intelligence or CRM stages, leave the most expensive question unanswered.
Research on integrating biomedical technology with digital marketing argues that digital interaction measurement must connect to clinically and operationally meaningful outcomes, not engagement for its own sake 8. For a DSO, that translation is direct: the unit of accuracy is cost per booked consult attributable to AI surfaces, not citations per thousand prompts.
See How Leading DSOs Quantify Multi-Channel Marketing Impact with AI Precision
Request a walkthrough of real-world dashboards measuring visibility, qualified patient calls, and ROI across all locations—built for enterprise-scale marketing operations.
Applying the Framework: A Shortlist of Tool Categories Worth Evaluating
The five criteria narrow the field faster than any feature matrix. Rather than rank individual vendors, the categories below describe what each type of platform does well, where it stalls against the disqualification framework, and what a DSO marketing director should expect to add or replace to close the gap.
Pure-Play AI Visibility Trackers
The newest category in the stack. These platforms exist to answer one question: how often does a brand appear inside AI-generated answers. Most query four to six major systems on a fixed cadence, report citation counts and share-of-voice, and surface a sentiment label per mention.
Pure-plays generally clear the multi-model criterion and a portion of the sentiment criterion. They struggle on the other three. Prompt-variability testing is usually limited to a single canonical query per topic, which masks the swing documented in research on input perturbation 10. Governance is often minimal: prompt libraries are editable without audit logs, and there is no separation between configuration and approval. Outcome linkage is the steepest gap. Most pure-plays expose mentions, not call or booking attribution, leaving the marketing director to stitch citations to call tracking manually.
The category is worth evaluating when AI presence is genuinely unknown and a brand needs a first read. It is rarely the place to stop. Treat a pure-play as a sensor, not a system, and budget for the integration work required to connect its output to the CRM.
Enterprise SEO Suites With AI Overview Modules
The incumbents added AI Overview tracking as a module on top of rank tracking, backlink analysis, and site audits. The advantage is integration: AI presence sits next to organic rankings, so a director can see whether a query lost its blue link and gained an AI summary citation in the same view.
Coverage is the weakness. Most suites focus on Google's AI Overview and add ChatGPT and Perplexity as secondary feeds, with less depth on DeepSeek or model-specific citation behavior. That matters because citation patterns diverge sharply across systems, and a suite that under-samples Perplexity will misread how a brand actually surfaces 16. Governance is usually inherited from the broader SEO platform: roles and permissions exist, but audit trails are oriented to rank changes, not prompt versioning.
The category fits brands already standardized on one of the major suites and unwilling to add a separate tool. The trade-off is acknowledged depth on AI-specific measurement in exchange for one fewer login and a unified billing line.
Brand Mention and Sentiment Platforms Extending Into LLM Coverage
Social listening and brand monitoring platforms built their measurement layer for forums, news, and review sites. Adding LLM coverage was a natural extension: the underlying entity resolution and sentiment scoring already existed, and AI outputs became another input stream.
The sentiment and entity criteria are usually the strongest part of this category. These platforms have spent years tuning name disambiguation across locations, which matters for any DSO operating in multiple metros where a practice name overlaps with unaffiliated offices. Bias slicing by language and geography is often available because the same engine already segments social mentions that way 6.
The gaps appear on prompt variability and outcome linkage. Most extend their existing sampling logic to LLM queries, which does not test the phrasing variance that determines citation stability. Call and booking attribution generally requires a separate integration. A reasonable evaluation question: what does the platform measure that the SEO suite or pure-play does not, and is that delta worth a second contract.
Vectoron: Measurement Plus Approval Workflow
Vectoron belongs in this shortlist not as another visibility tracker but as a different category: a measurement-and-execution platform that routes AI surface data, call intelligence, and CRM signals through a single approval workflow. The premise is that citations are inputs to decisions, and decisions need governance, not just dashboards.
Against the five criteria, the platform's design choices map closely to the NIST measure and govern functions 1. Specialist strategists handle content, SEO, PPC, backlinks, social, and call intelligence, with each recommendation surfaced through a Command Center that logs the reasoning and requires human sign-off before anything ships. That structure produces the audit trail and analyst-versus-approver separation the governance criterion demands, and it ties measurement to the operational outcomes the outcome-linkage criterion requires 8. Live call and booking data sit in the same loop as visibility signals, which is what closes the gap most pure-plays leave open.
The honest trade-off: brands that want only a visibility number will find the platform broader than the category. Brands that want measurement connected to the work it should trigger across 20 to 200 locations will recognize the value in not running four contracts to reach the same conclusion. A 14-day trial at $599 per month gives an operator time to test the full loop on real queries and real call data before committing.
 Compare the four tool categories against the five disqualification criteria, directly supporting the section's comparison of vendor categories
Compare the four tool categories against the five disqualification criteria, directly supporting the section's comparison of vendor categories
If You Manage Multiple Locations: The Consolidation Math
A note on audience: this section is written for marketing directors running 20 or more locations, where tool sprawl compounds faster than at single-site practices. The arithmetic changes when every contract is multiplied by a location count.
The typical DSO measurement stack at 50 locations carries five line items:
- a pure-play AI visibility tracker,
- a rank tracking suite,
- GA4 with a paid connector,
- call tracking, and
- an agency reporting layer that stitches the rest together.
Each vendor charges per location, per seat, or per tracked keyword. The reporting layer exists because the other four do not talk to each other. None of them, on their own, answers whether a citation in Perplexity produced a booked consult in Mesa.
The illustrative consolidation math below uses variables rather than invented prices, with one published figure as an anchor.
| Cost component | Stacked approach | Unified measurement-plus-execution layer |
|---|---|---|
| Visibility tracker | V × L | Included |
| Rank tracking | R × L | Included |
| Call intelligence | C × L | Included |
| Reporting/agency stitching | A monthly | Included |
| Anchor price point | Sum of above | $599/mo trial |
Two operational notes belong with the table. Research on AI in healthcare quality management reports administrative workload reductions of up to 30% when digital health and AI solutions replace manual coordination 11. Most of that gain in a DSO context comes from collapsing reporting handoffs, not from the analytics themselves. Second, governance scales worse than cost: every additional tool adds another audit surface, another permissions model, and another vendor to question when a regional VP asks why citation share dropped 1.
What to Ask a Vendor Before Signing
Demos reward charisma. Procurement rewards specificity. The questions below force a vendor to answer the parts of the disqualification framework that slide past most sales calls.
- Which models do you query, and how often do you re-query after a known model update? Citation behavior shifts across systems and across versions 16. A vendor that cannot name its refresh cadence is selling a screenshot.
- How many phrasing variants do you run per tracked topic, and do you report variance alongside the mean? Snapshot scoring hides instability that input perturbation research has already documented 10.
- Show the audit log for a prompt change made 90 days ago. If history is overwritten on refresh, the platform fails the govern function NIST defines as foundational 1.
- How do citation events pass into call tracking and the CRM? If the answer involves a CSV export, outcome linkage is a sales claim, not a feature 8.
- Can you slice sentiment and citation share by language, location, and service line? Aggregate reporting averages away the bias patterns that matter most 6.
A vendor that answers all five without deflection has earned the second meeting.
 Hospital Adoption of Predictive AI (2023 vs 2024)
Hospital Adoption of Predictive AI (2023 vs 2024)
Comparison of the percentage of U.S. hospitals that have adopted predictive AI in 2023 versus 2024, showing an increase from 66% to 71%.
Frequently Asked Questions
References
- 1.AI RMF Core - AIRC - NIST AI Resource Center.
- 2.Foundations for Effective Risk Management of Artificial Intelligence.
- 3.Hospital Trends in the Use, Evaluation, and Governance of Predictive AI, 2023-2024.
- 4.Health Equity and Ethical Considerations in Using Artificial Intelligence (AI) in Public Health.
- 5.Ethical and legal considerations in healthcare AI.
- 6.Addressing bias in big data and AI for health care.
- 7.Monitoring performance of clinical artificial intelligence in health care.
- 8.Conceptual Model for the Integration of Marketing Strategies and Biomedical Technology to Enhance Patient Engagement and Health Outcomes.
- 9.Do people click on links in Google AI summaries?.
- 10.Performance of Large Language Models Under Input Variability in Clinical Information Extraction.
- 11.Large language models in healthcare quality management.
- 12.Large Language Models in Healthcare and Medical Applications.
- 13.Artificial Intelligence in Predictive Healthcare: A Systematic Review.
- 14.2025 Watch List: Artificial Intelligence in Health Care.
- 15.Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile.
- 16.Benchmarking Generative AI Tools for Interpretation of the WHO TB Mutation Catalogue.
- 17.Evolving Health Information-Seeking Behavior in the Context of AI- and Voice-Assisted Technologies.