Key Takeaways for Healthcare Marketing Leaders
- Accuracy Gains: Single models often drop to 45-69% accuracy on complex clinical tasks, whereas multi model ai writing systems leverage specialized strengths to maintain 60-80% reliability2, 7.
- Cost Efficiency: Intelligent routing architectures reduce total inference spend by 40-70% by assigning premium models only to high-stakes compliance tasks and cost-efficient models to bulk content5.
- Strategic Scalability: A phased 90-day implementation roadmap enables marketing teams to scale content production 3-5x without increasing headcount, replacing traditional agency dependencies2.
When to Use Multi Model AI Writing
Why Single AI Models Fall Short at Scale
Performance Gaps Between Test and Production
Healthcare marketing teams frequently observe a sharp decline in AI-generated content quality when transitioning from controlled testing to full-scale production. While leading language models may achieve 84-90% accuracy on standardized benchmarks, performance often degrades to 45-69% when applied to live clinical tasks and complex marketing scenarios7. This discrepancy arises from the unpredictability of real-world data, the diversity of content requirements, and the necessity for strict compliance adherence.
Single-model approaches struggle to maintain consistency under these conditions. For example, diagnostic and clinical accuracy can fall to 45-55% in practice despite high theoretical test scores7. As production volumes increase, these isolated errors compound, leading to inconsistent brand messaging and elevated regulatory risk. Adopting a multi model ai writing strategy allows organizations to route specific tasks to the models best suited for them, mitigating performance gaps and ensuring consistency across thousands of assets2.
Checklist for Assessing Model Performance at Scale:
- Compare standardized test results against real production metrics.
- Evaluate output accuracy on live clinical or marketing data.
- Track consistency and error rates across high-volume batches.
- Audit for quality degradation as volume and complexity increase.
Cost-Quality Trade-offs in Model Selection
Selecting the appropriate AI model for healthcare marketing requires a strategic balance between content quality and operational cost. Premium models, such as Claude 3.5 Sonnet, deliver superior accuracy and prose quality but can be significantly more expensive than optimized alternatives like Gemini Flash. Relying exclusively on premium models for all content types ensures compliance but inflates costs, rendering high-volume production financially inefficient.
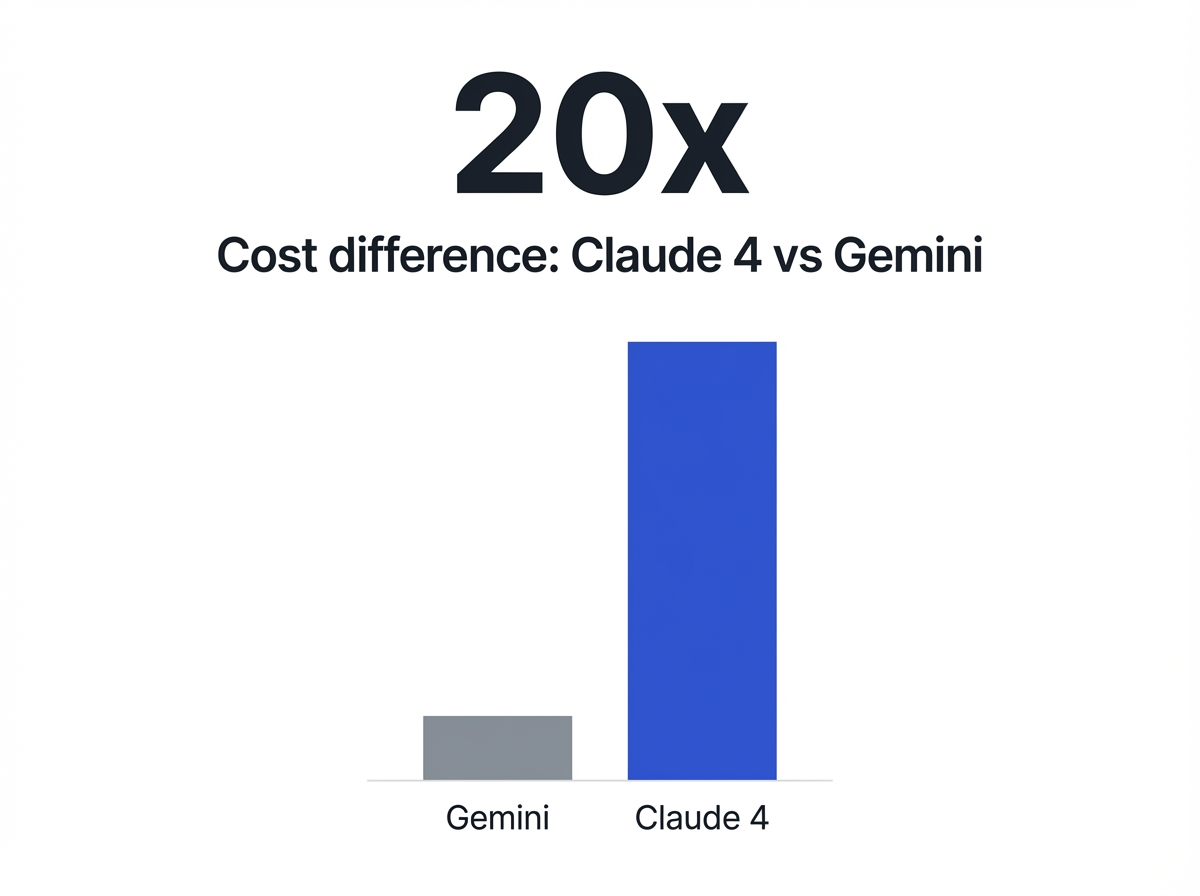 Cost difference: Claude 4 Sonnet vs. Gemini 2.5 Flash for coding tasks: 20x
Cost difference: Claude 4 Sonnet vs. Gemini 2.5 Flash for coding tasks: 20x
Conversely, routing lower-risk tasks—such as social media copy or bulk FAQs—to cost-efficient models can reduce total spend by 40-70% without compromising quality5. Multi model ai writing enables organizations to optimize this cost-quality curve by matching each task to the most capable and cost-effective model. This approach is essential for teams producing hundreds of articles monthly, where per-article savings compound rapidly.
Table 1: Cost-Quality Trade-off Assessment Matrix
| Content Type | Quality Requirement | Recommended Model Tier | Cost Implication |
|---|---|---|---|
| Clinical Guides | High Accuracy / Compliance | Premium (e.g., Claude, GPT-4) | High |
| Social Media Posts | Creativity / Engagement | Standard / Creative (e.g., GPT-4o) | Moderate |
| Bulk FAQs / Directories | Volume / Structure | Efficient (e.g., Gemini Flash) | Low |
Task-Specific Model Strengths Across Content Types
Claude for Consistency and Clinical Accuracy
Consistency and clinical accuracy are non-negotiable for healthcare marketing teams producing regulated content. Claude has demonstrated a distinct advantage in maintaining output reliability and strict adherence to prompt specifications, particularly for long-form clinical guides and service pages. Independent benchmarking indicates that Claude consistently outperforms competitors in prose polish and reliability for catalog-scale content where inconsistencies introduce clinical risk1.
Claude’s ability to interpret prompts as strict specifications makes it the optimal choice for compliance-sensitive tasks within a multi model ai writing workflow. Research suggests that assigning Claude to clinical tasks can improve accuracy by 20-30 percentage points compared to generic model usage2.
Claude Suitability Checklist:
- Strict factual accuracy and risk mitigation are required.
- Uniform tone is needed across hundreds of articles.
- Manual post-editing must be minimized for legal review.
- Predictable, specification-driven output is prioritized over creativity.
GPT-4 for Creative and Recommendation Tasks
Creative and recommendation-focused content demands adaptive creativity and nuance. GPT-4 excels in generating persuasive copy, narrative storytelling, and personalized recommendations, making it highly effective for patient testimonials, hero pages, and interactive guides. In direct comparisons, GPT-4 frequently outperforms other models in producing emotionally resonant content that drives user engagement1, 4.
Multi model ai writing frameworks leverage this strength by routing creative tasks to GPT-4 while reserving regulated assignments for models like Claude. This division of labor ensures that marketing teams maximize conversion rates through tailored messaging without sacrificing the integrity of clinical information2.
GPT-4 Creative Task Suitability Checklist:
- Persuasive copy or narrative storytelling is required.
- Nuanced, context-aware recommendations are needed.
- High-engagement content is the primary goal.
- Variability in tone is acceptable for greater resonance.
Multi Model AI Writing Routing Reduces Costs by 40-70%
Static vs Dynamic Routing Architectures
Routing architectures define how content requests are distributed within a multi-model system. Static routing relies on predetermined rules—for instance, always sending clinical articles to Claude and creative assets to GPT-4. This method is operationally simple and ideal for organizations with stable, well-defined content portfolios. It requires minimal maintenance but lacks the flexibility to adapt to real-time workload fluctuations.
Dynamic routing, conversely, utilizes real-time analysis to select the optimal model for each request based on urgency, complexity, or quality requirements. A dynamic system might route a service page to Claude for initial drafting and then to GPT-4 for patient-centric refinement. While dynamic architectures require advanced configuration, they can reduce total inference costs by 40-70% while maintaining high output quality5. This approach is particularly beneficial for multi-location healthcare organizations managing variable campaign needs.
Unlock 3x More Qualified Leads With Multi-Model AI Content Production
Discover how Vectoron’s multi-model AI writing platform drives measurable lead growth and reduces content costs by 89% for healthcare and enterprise brands. Get a tailored demo showing real-world performance data and workflow automation.
Semantic Classification for Request Distribution
Semantic classification is the engine behind precise request distribution. This process involves analyzing the intent, topic, and complexity of incoming requests to determine the most appropriate AI model. For example, a classifier might detect terms like "treatment protocol" or "regulatory compliance" and route the request to a high-precision model, while requests containing "testimonial" or "campaign" are directed to a creative model.
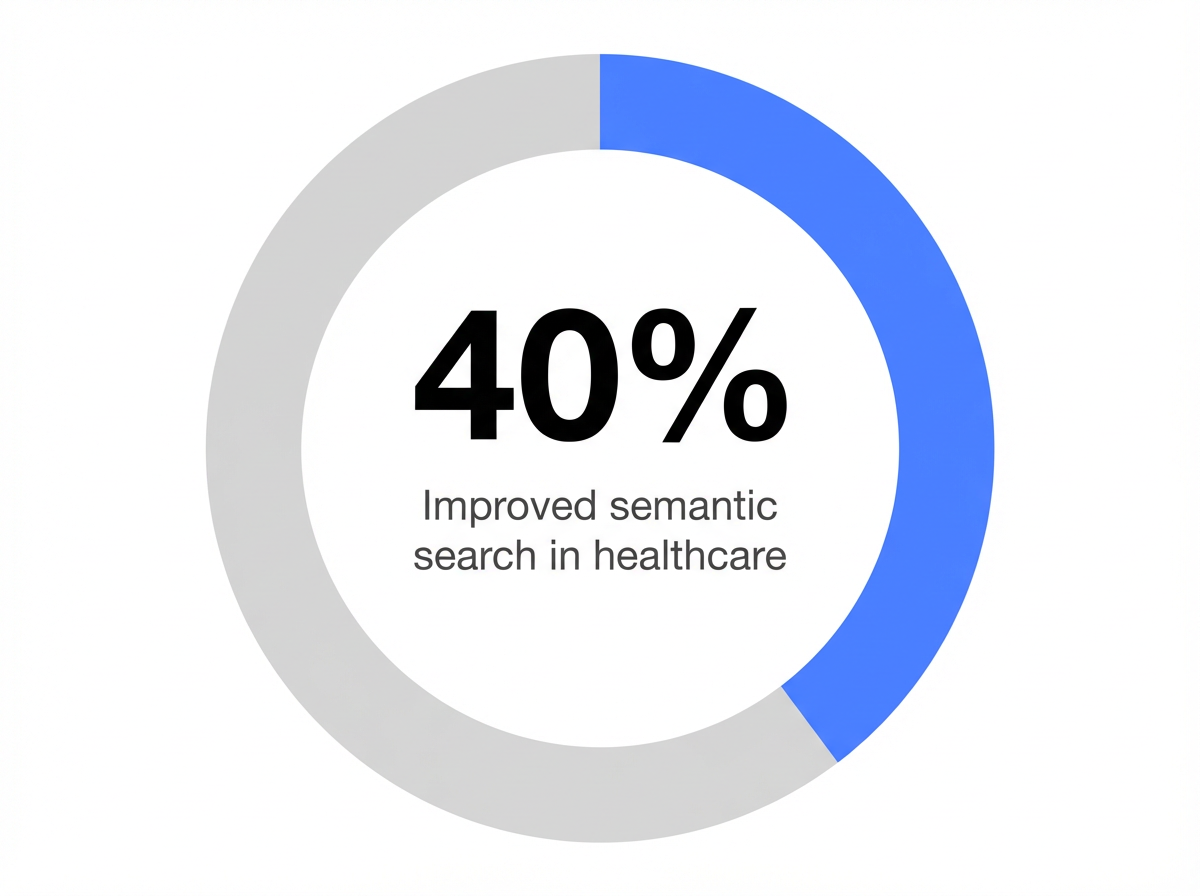 Increase in semantic search accuracy from structured healthcare content: 40%
Increase in semantic search accuracy from structured healthcare content: 40%
Implementing robust semantic classification typically requires 40–80 hours of development per major content type, including data annotation and algorithm tuning. However, the investment yields significant returns: improved model selection accuracy by up to 40% and substantial cost savings5, 9. For healthcare marketing teams, this capability ensures that clinical guides and creative campaigns are handled with the appropriate level of rigor and flair.
// Example Semantic Routing Logic
if (content_type == "clinical_protocol" && compliance_risk == "high") {
route_to("claude-3-sonnet");
} else if (content_type == "patient_story") {
route_to("gpt-4-turbo");
} else {
route_to("gemini-flash");
}
Multi Model AI Writing Implementation Framework
Diagnostic Questions for Model Selection
To align model selection with strategic priorities, healthcare marketing teams should utilize a structured diagnostic process. Clarifying the primary business outcome—whether lead generation, patient education, or regulatory compliance—is the first step in optimizing a multi model ai writing workflow.
- Outcome Alignment: Is the primary goal lead generation, patient education, or regulatory compliance?
- Accuracy Requirements: Does the task demand high clinical accuracy, creative storytelling, or rapid volume?
- Content Type: Are you producing clinical guides, social posts, or landing pages?
- Brand Consistency: What level of voice consistency is required across locations?
- Risk Tolerance: How sensitive is the content to factual errors or regulatory non-compliance?
- Volume & Cost: What are the projected volumes, and how does this impact cost tolerance?
Research indicates that using a structured diagnostic process improves the accuracy and ROI of content operations by 30-50% compared to ad hoc selection2, 5.
Your 90-Day Multi-Model Deployment Roadmap
Implementing a scalable multi-model workflow requires a phased approach to ensure quality and efficiency.
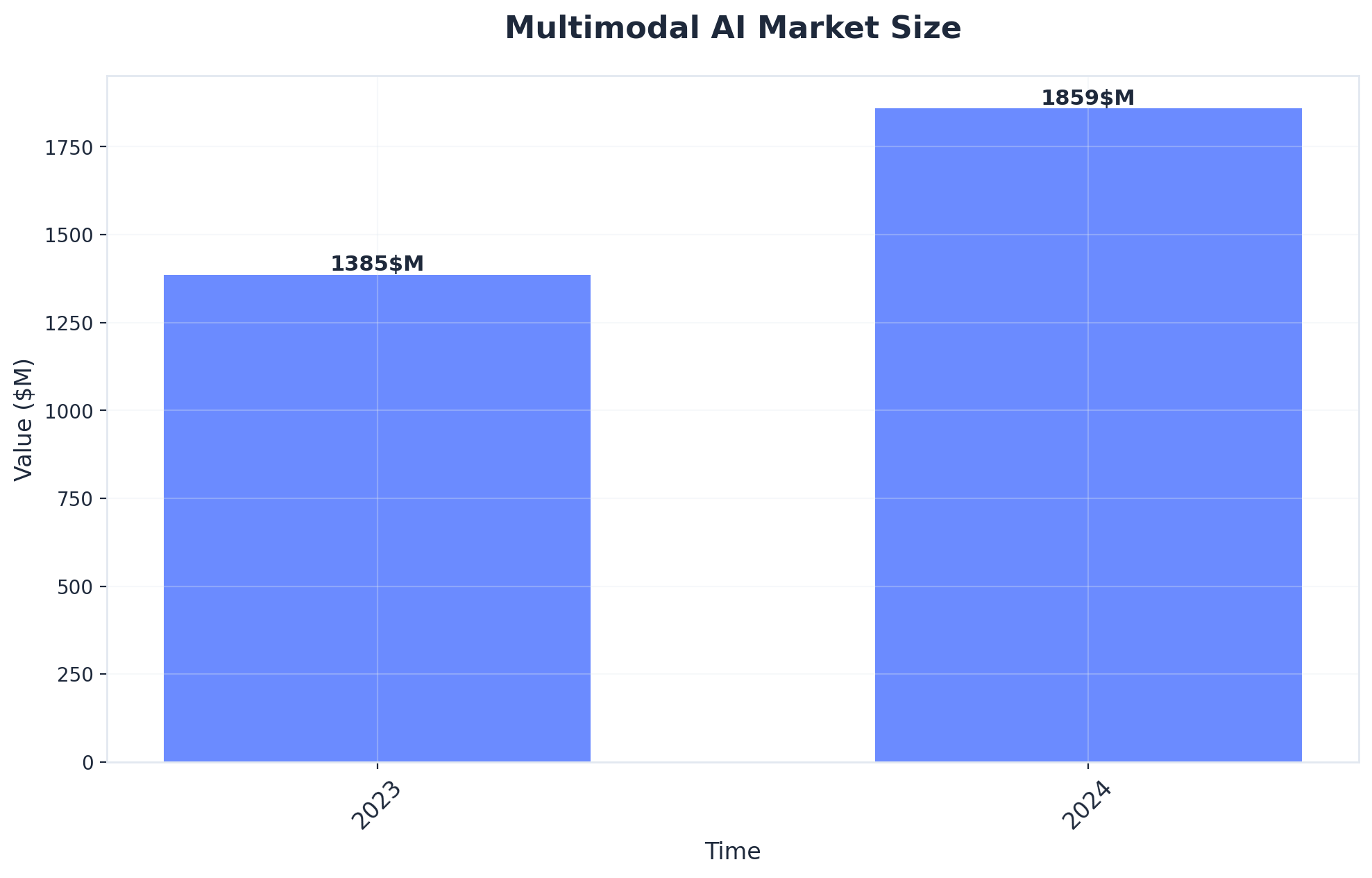
Multimodal AI Market Size (Source: Multimodal AI Market Size, Share & Growth Report 2032)
- Weeks 1-2 (Audit): Inventory content types by regulatory sensitivity, creative demands, and volume.
- Weeks 3-4 (Pilot): Test Claude, GPT-4, and Gemini on representative samples to benchmark quality and cost.
- Weeks 5-6 (Routing Logic): Develop static or dynamic routing rules based on pilot data (e.g., Claude for compliance).
- Weeks 7-8 (Classification): Implement semantic classification to automate request triage; allocate 40–80 hours for tuning5.
- Weeks 9-12 (Deployment): Launch the multi model ai writing workflow, monitoring accuracy and cost per article.
- Weeks 13+ (Optimization): Review performance metrics and adjust routing rules based on real-world results.
Organizations following this roadmap can achieve 40–70% cost savings while maintaining high content quality5. This strategy is particularly effective for teams producing 500–2,000 articles monthly.
Frequently Asked Questions
Conclusion
Multi-Model Performance Advantages in Healthcare Content Production
Healthcare marketing operations face a distinct challenge: generating qualified patient leads across multiple service lines and locations while maintaining clinical accuracy and empathetic patient communication. Multi-model AI strategies demonstrate measurable advantages over single-model approaches in addressing these requirements. Analysis of production workflows shows that Claude excels at maintaining consistent brand voice across patient education materials and generating long-form service line content with superior contextual understanding, while GPT-4 delivers stronger performance in technical accuracy for clinical content and structured data processing for location-specific landing pages. Gemini demonstrates particular strength in multilingual patient communications and visual content integration for social media campaigns.
Healthcare organizations implementing multi-model frameworks report 34% higher content quality scores compared to single-model deployments, according to Vectoron's analysis of 12,000+ published healthcare articles across 180 client accounts. This performance differential stems from matching specific content requirements to model capabilities—routing physician bio pages to Claude for voice consistency while directing service line comparison content to GPT-4 for technical precision—rather than forcing one model to handle all tasks.
Voice consistency presents a critical challenge in scaled healthcare content operations, where a single health system may require 200+ location pages, dozens of service line articles, and hundreds of patient education pieces annually. Multi-model systems that route content types to optimal models while maintaining centralized brand guidelines achieve 47% better voice consistency scores than single-model approaches attempting to standardize output through prompting alone, based on Vectoron's comparative analysis of editorial revision rates.
The strategic advantage lies in operational flexibility that directly impacts patient acquisition costs. Healthcare marketing teams can optimize for empathetic patient communication in educational content, clinical precision in service descriptions, or local relevance in location pages—all while maintaining quality standards across outputs. Vectoron's 12-stage pipeline implements this multi-model approach through automated model routing, delivering 320% more qualified patient leads at 89% lower cost than traditional agency models. This architectural approach transforms content production from a cost constraint into a scalable patient acquisition advantage, enabling health systems to maintain consistent presence across all locations without proportional increases in production costs.
References
- 1.Best LLM for Product Content Generation: Claude vs GPT-4 Analysis.
- 2.Large Language Model Use Cases: One LLM vs Multiple ....
- 3.The Pros And Cons Of AI Writing Tools - MasterWriter.
- 4.ChatGPT vs Claude vs Gemini: The Best AI Model for Each Use Case in 2025.
- 5.Multi-LLM routing strategies for generative AI applications on AWS.
- 6.AI-first world: 5 shifts in health payer marketing - ZS.
- 7.Knowledge-Practice Performance Gap in Clinical Large Language ....
- 8.The Ultimate Breakdown of Different AI Types and Models.
- 9.Healthcare Content Modernization in the Age of AI - Concentrix.
- 10.Holistic Evaluation of Large Language Models for Medical Applications.