
Key Takeaways
- Semrush SEO Writing Assistant embeds SERP-anchored optimization scoring directly in the drafting surface, letting mid-tier writers hit acceptable optimization bands without editor line-by-line keyword coaching.
- Clearscope standardizes brief generation upstream of drafting, shifting editorial review from structural coaching to faster fact and voice checks that reduce senior-editor dependency.
- Surfer SEO decomposes top-ranking pages into a discrete structural checklist, letting junior editors execute fixes and writers self-QA before pieces reach editorial review.
- Frase compresses research-layer work by synthesizing SERP results and People Also Ask data into outlines, helping generalist editors map unfamiliar verticals without becoming subject-matter experts.
- Jasper contributes drafting throughput only when paired with versioned prompt libraries and stable briefs, since companies report up to 50% drafting-time reductions scoped narrowly to that stage 3.
- Originality.ai enables batch editorial QA on AI-generation likelihood and plagiarism, letting editors triage a risk-scored queue rather than reading every draft manually.
- Airtable holds the stack together by eliminating stage handoff friction, which at 400 articles a month equates to a full-time role the P&L never sees.
- Vectoron consolidates briefing, drafting, QA, orchestration, and execution into one approval-gated workflow, paying back past 30 clients where point-tool handoff losses exceed per-stage gains.
The production math that decides which tools actually matter
An agency shipping 400 SEO articles a month across 30 clients is not running a writing operation. It is running a manufacturing line, and the line's throughput is capped by whichever stage has the fewest hands on it. That stage is almost never drafting anymore. It is briefing, optimization scoring, editorial review, or the handoff between them.
This reframes the tool question. The category called seo content writing tool has expanded to cover seven distinct production stages, and each stage has a different throughput ceiling. Companies using AI for content creation have reported up to a 50% reduction in production time, but that figure is self-reported by adopting companies and scoped to drafting, not to the full editorial chain 3. Applied without a governed workflow, the same tools that halve drafting time can double editorial rework and net out at zero.
Peer-reviewed work on industrial LLM deployment defines scalability as handling increasing data, users, or tasks without significant performance loss 8. That is the standard the shortlist below is measured against. Not features. Not novelty. Whether each tool moves throughput-per-editor without breaking the originality and helpfulness signals that Google's algorithm actually rewards 4.
 Maximum reported reduction in content production time with AI
Maximum reported reduction in content production time with AI
Maximum reported reduction in content production time with AI
How to read this shortlist: throughput contribution over feature count
The seven tools below map to seven production stages:
- SERP analysis
- Optimization scoring
- Drafting
- Briefing
- Editorial QA
- Workflow orchestration
- Execution coordination
Each entry is ranked by what it adds to editor-hours-shipped, not by the length of its feature page.
Prompt quality and context design carry more weight than tool selection at scale. MarTech's guidance on scaling LLM use in marketing frames prompt engineering and programmatic context provision as the primary scalability lever, arguing that better instructions produce better outputs and that wrapping prompts in code lets teams automate data exchange without linear headcount growth 7. Two agencies running the same shortlist can post very different throughput numbers based on how their prompt libraries and approval gates are structured.
Read each tool section for three things:
- which stage it owns,
- what it does to editor throughput, and
- where its trade-off shows up downstream.
Tools that speed drafting but push work into QA are counted honestly. Approval gates between AI-driven stages are treated as non-negotiable, not optional overhead.
 Visualize the seven production stages the article maps its shortlist to, giving readers a framework diagram of the content pipeline before individual tool sections begin
Visualize the seven production stages the article maps its shortlist to, giving readers a framework diagram of the content pipeline before individual tool sections begin
Semrush SEO Writing Assistant: SERP-anchored optimization inside the draft surface
Semrush SEO Writing Assistant occupies the optimization-scoring stage of the stack, and its throughput contribution comes from a single design choice: the feedback lives inside the surface where the writer is already typing. Google Docs, WordPress, and the Semrush editor all pull the same SERP-derived recommendations for target keyword, semantic terms, readability band, and tone. That collapses the round-trip between drafting and optimization review, which is where most agency workflows lose hours.
For a head of SEO managing 30-plus accounts, the practical value is not the score itself. It is that a mid-tier writer without deep SEO training can hit an acceptable optimization band on the first pass, freeing editors from line-by-line keyword coaching. This matches the broader shift documented across 2026 tool coverage, where live in-editor feedback is now standard rather than experimental, and agency stacks increasingly assume writers do not need specialist intervention on every piece 1.
The trade-off shows up in two places. The recommendation set is anchored to the top-ranking URLs Semrush sampled, which means the tool reinforces SERP consensus rather than challenging it, and thin verticals produce thin guidance. Score-chasing also correlates poorly with helpfulness signals when writers pack in semantic terms to hit a target, so editorial review still needs to catch keyword stuffing dressed up as optimization 4. Treat the score as a floor for drafts, not a ceiling for editors.
Clearscope: brief generation and topic-model discipline at the editor layer
Clearscope sits one stage upstream of Semrush's writing assistant. It owns brief generation, which is the stage where most agency editors quietly lose their weekends. A Clearscope brief compresses the top-ranking URLs for a target term into a topic model, a target grade level, a word-count band, and a ranked list of terms the draft needs to cover. The editor hands that brief to a writer or an LLM and stops rewriting outlines from scratch.
The throughput contribution is measurable at the editor layer, not the writer layer. When briefs are standardized, editorial review shifts from structural coaching to fact and voice checks, which is faster and less senior-dependent. This matters because agency stacks in 2026 increasingly assume the brief itself carries the SEO logic, letting writers without deep optimization training hit target coverage on the first pass 1. It also gives prompt libraries a stable input format when briefs feed drafting LLMs, which is the scalability lever MarTech identifies as more important than the drafting model itself 7.
The trade-off is topic-model conformity. Clearscope's term list is derived from what already ranks, so briefs trend toward SERP consensus and away from original angles. For commodity vertical content that is a feature. For thought leadership or contrarian pieces it flattens voice, and editors have to decide which briefs to override rather than execute. Originality still drives ranking risk more than AI usage does, so the override call is not optional at scale 4.
Surfer SEO: on-page scoring that translates SERP structure into edit tasks
Surfer SEO occupies the same optimization-scoring stage as Semrush's writing assistant, but its throughput contribution comes from a different angle: it converts SERP structure into a discrete edit checklist. Where Semrush surfaces recommendations inline as the writer types, Surfer decomposes the top-ranking pages into structural signals — heading depth, section counts, entity coverage, image density, average word count per H2 — and hands the editor a task list rather than a running score.
For agencies producing 40 to 100 articles a month per editor, that decomposition is where the hours come back. A junior editor working from a Surfer content editor score can execute structural fixes without holding the SERP in their head, and mid-level writers can self-QA against the same task list before the piece hits editorial review. This aligns with the broader normalization of embedded optimization feedback documented across 2026 tool coverage, where the assumption is that writers hit target coverage on the first pass and editors escalate only exceptions 1.
The trade-off is structural mimicry. Surfer's task list is derived from what already ranks, so pages engineered to hit the score tend to converge on the same shape as the SERP. That converges optimization signals but flattens originality, which is the exact signal Google's algorithm rewards independently of AI usage 4. Editors should treat the Surfer checklist as a completion floor for commodity briefs and override it for pieces where the ranking opportunity is a structural gap in the SERP, not conformity to it.
Test AI-powered SEO content at real scale
Publish live SEO content for clients and evaluate workflow efficiency before making any commitment.
Frase: research-layer AI for outline synthesis and answer-engine coverage
Frase sits earlier in the stack than any tool discussed so far. Its throughput contribution lives in the research layer, where an editor or writer would otherwise spend two to four hours reading top-ranking pages, extracting the questions those pages answer, and stitching a coverage map into an outline. Frase compresses that work by pulling SERP results, People Also Ask entries, and related question clusters into a single outline surface, then letting the editor accept, reorder, or override the synthesized structure.
For agencies producing content across unfamiliar verticals every quarter, that compression is where the hours come back. A generalist editor onboarding a new client can produce a defensible topic map without becoming a subject-matter expert first. This matches the pattern documented in market research applications of LLMs, where the models summarize, order, and prioritize qualitative and quantitative inputs faster than manual synthesis and hand editors a starting draft to interrogate rather than build 9. Frase is not doing anything exotic; it is applying that summarization behavior to SERP corpora and question data.
The trade-off is answer-engine coverage bias. Frase optimizes for the questions already surfaced by Google's PAA and related-search infrastructure, which means outlines converge on the queries the SERP has already indexed. That is useful when the target keyword is a mature commercial term and dangerous when the ranking opportunity is a question the SERP has not yet clustered. Editors should treat Frase outlines as a completion floor for topic coverage and layer prompt-driven angle generation on top when the brief calls for originality that PAA data will not surface 4.
Jasper: drafting throughput with prompt libraries agencies can standardize
Jasper sits at the drafting stage, which is the single largest throughput lever in the stack and also the most overhyped. The realistic delta is that companies using AI for content creation have reported up to a 50% reduction in production time, a figure self-reported by adopting companies and scoped to drafting rather than to the full editorial chain 3. That number holds only when the drafting layer is fed a stable brief and a versioned prompt library. Without both, the savings evaporate into editorial rework.
The reason Jasper earns a slot over a raw LLM API is workflow packaging. Its templates, brand voice profiles, and shared prompt libraries let an agency standardize how each client's drafts get generated, which is the scalability lever MarTech identifies as more important than the underlying model: better context and instructions produce better outputs, and reusable prompt structures let AI production grow without linear headcount expansion 7. Heads of SEO can assign a client-specific voice profile once, version it, and stop relitigating tone in every draft cycle.
The trade-off is generic output when prompt discipline slips. Duplicate or thin AI content still degrades rankings because algorithmic weight sits on originality and helpfulness, not on AI origin 4. Treat Jasper as a drafting engine that only compounds when its prompt library is maintained as a versioned asset, not a shared doc.
Originality.ai and editorial QA: closing the loop on scaled AI output
Every stage discussed so far speeds work into the editorial layer. Originality.ai owns the stage that keeps that layer from becoming the new bottleneck. It scores drafts for AI-generation likelihood, plagiarism overlap, and factual claim density, and it does so in bulk rather than piece by piece. For an agency shipping several hundred articles a month, that batch behavior is the point: QA cannot be a manual pass on every draft when drafting volume has doubled.
The throughput contribution shows up in editor triage. Instead of reading every AI-drafted piece for originality, editors work a queue sorted by risk score and spend senior time on the drafts most likely to trip helpfulness or duplicate-content signals. That matters because the ranking risk from scaled AI output is not the AI origin itself but the generic, low-differentiation phrasing that thin prompts produce, and Google's algorithm weights originality independently of how a draft was written 4.
The trade-off is false positives. AI-detection tools misclassify human-written passages often enough that scores should trigger review, not rejection. Pair the tool with a documented approval gate rather than an automated kill switch, consistent with the govern-map-measure-manage sequence NIST recommends for AI systems in production 10.
Airtable and workflow orchestration: making the stack a system, not a shelf
Six tools speeding six stages produce a shelf, not a system. Airtable earns its slot because it holds the stages together. It is where a brief moves from Clearscope into a writer's queue, where a Jasper draft picks up its Originality.ai score, where an editor claims a piece, and where a client-facing status column updates without a status meeting. The throughput contribution is not what Airtable does inside any single stage; it is the elimination of the handoff friction between them.
For an agency running 400 articles a month, that friction is measurable. Every stage transition without an orchestration layer costs an editor five to fifteen minutes of context reconstruction, and at 400 pieces that adds up to a full-time role the P&L cannot see. Airtable's automations, views, and API access let heads of SEO wire the stack so a brief's completion triggers the drafting prompt, a draft's approval triggers the QA queue, and a passed QA score triggers the publish task. This is the programmatic-integration behavior MarTech identifies as the actual scalability lever: wrapping prompts and stages in code so data exchange happens without a human courier 7.
The trade-off is configuration debt. Orchestration only compounds when the schema is maintained as a versioned asset with documented owners.
See How Leading Agencies Streamline SEO Content Production With AI Coordination
Connect with a solutions expert to review workflow automation for your agency, benchmark your current SEO content process, and identify opportunities to scale output without expanding your team.
Vectoron: unified execution when point tools stop paying back
The first six entries in this shortlist solve one production stage each. Vectoron sits in a different category: it consolidates the drafting, briefing, QA, orchestration, and execution-coordination stages into a single approval-gated workflow, along with the SEO, PPC, backlinks, social, and call-intelligence layers a multi-service agency would otherwise run in parallel stacks. It belongs on this list not because it out-features a point tool at any single stage, but because at 30-plus client scale the handoff losses between point tools begin to exceed the throughput gains inside them.
The design premise is that specialist AI strategists surface ranked recommendations from live client data — booked calls, cost per lead, pipeline movement — and route every recommendation through a Command Center for human approval before execution. That matches the govern-map-measure-manage sequence NIST recommends for AI systems in production, applied at the workflow layer rather than bolted on as a review step 10. It also reflects the programmatic-integration behavior MarTech identifies as the actual scalability lever, where prompts and stages are wrapped in code so briefs, drafts, QA scores, and publish tasks move without a human courier 7.
The trade-off is category commitment. A unified execution platform replaces two or three point tools an agency already pays for and standardizes prompt libraries, approval schemas, and reporting formats across clients. That compresses editor throughput significantly but requires migrating existing workflows rather than adding another tab. Heads of SEO evaluating the consolidation should measure the switch against the handoff-friction cost documented in the orchestration section, not against the license cost of any single replaced tool.
Cost per published article across four production models
The tool question resolves faster once the unit economics are on the table. The chart below models cost per published 1,500-word SEO article across four production configurations that most agencies actually run:
- an in-house staff writer,
- a freelance network,
- an AI-drafted piece with human editorial pass, and
- an orchestrated AI stack with an approval workflow.
Dollar totals are left as reader-input ranges rather than fabricated point estimates, because writer rates, editor rates, and tool licenses vary too widely across markets to publish a single number without misleading someone.
Two assumptions carry the model. First, the AI-assisted rows apply an up-to-50% production-time reduction to the drafting stage, drawn from MGID's reporting that companies using AI for content creation have observed that delta 3. The figure is self-reported by adopting companies, scoped to drafting rather than the full editorial chain, and should be treated as an optimistic ceiling rather than a guaranteed outcome. Second, editorial hours do not scale down at the same rate as drafting hours; on AI-drafted work, editorial time frequently increases per piece before it decreases, because originality and helpfulness checks become the binding constraint once drafting is cheap 4.
Columns to populate for each row:
- writer labor hours per article,
- blended writer rate,
- tool cost allocated per article (Clearscope brief, Semrush or Surfer score, drafting license, QA scan),
- editorial hours per article,
- blended editor rate,
- total cost range, and
- monthly capacity per editor at a 160-hour month.
The orchestrated-stack row should also carry a handoff-friction credit: the five to fifteen minutes per stage transition that disappears when briefs, drafts, and QA scores move programmatically rather than through a human courier 7. That credit is where the orchestrated model separates from the AI-drafted-with-edit model on paper, and it is the line item heads of SEO should stress-test against their own timesheet data before signing a consolidation contract.
If you manage 30+ client accounts: when the stack should consolidate
Scope shift: this section is for heads of SEO past the 30-client mark, where the P&L stops rewarding additional point tools and starts rewarding integration. Below that threshold, running Clearscope, Surfer, Jasper, Originality.ai, and Airtable side by side pays back. Above it, the handoff friction between them scales faster than the throughput each one adds.
Three signals mark the crossover:
- Editors spend more than 20% of their week reconciling status across tools rather than shipping edits.
- Prompt libraries fragment because each client's voice profile lives in a different surface.
- Approval gates become inconsistent across accounts, which is the exact failure mode NIST's govern-map-measure-manage sequence exists to prevent 10.
When two of the three appear, the orchestration cost has already exceeded the license savings.
Consolidation math is straightforward: measure editor hours lost to stage transitions against the switching cost of migrating prompt libraries and approval schemas into a unified platform. That is the programmatic-integration lever MarTech identifies as the real scalability multiplier 7, and it only compounds when the schema is owned by one system rather than seven.
Governance: one approval gate design, not seven
Seven tools running side by side tend to spawn seven approval conventions. A Clearscope brief gets signed off in a shared doc, a Jasper draft gets approved in Slack, an Originality.ai score gets waved through in a spreadsheet, and a publish task gets confirmed in a Trello card. Each convention is defensible in isolation. Together they produce inconsistent audit trails across clients, which is the exact fragmentation NIST's govern-map-measure-manage sequence is designed to prevent 10.
The fix is a single approval schema applied at every stage where AI output enters human judgment:
- brief acceptance,
- draft acceptance,
- QA-score override, and
- publish release.
Same fields, same owner roles, same timestamp behavior, same escalation path when a score falls outside tolerance. Heads of SEO should treat this schema as a versioned asset, not a policy memo, because prompt libraries and approval gates are the two artifacts that determine whether AI content production compounds or fragments as client count grows 7. One gate design, applied seven times, produces a defensible record. Seven gate designs produce a liability.
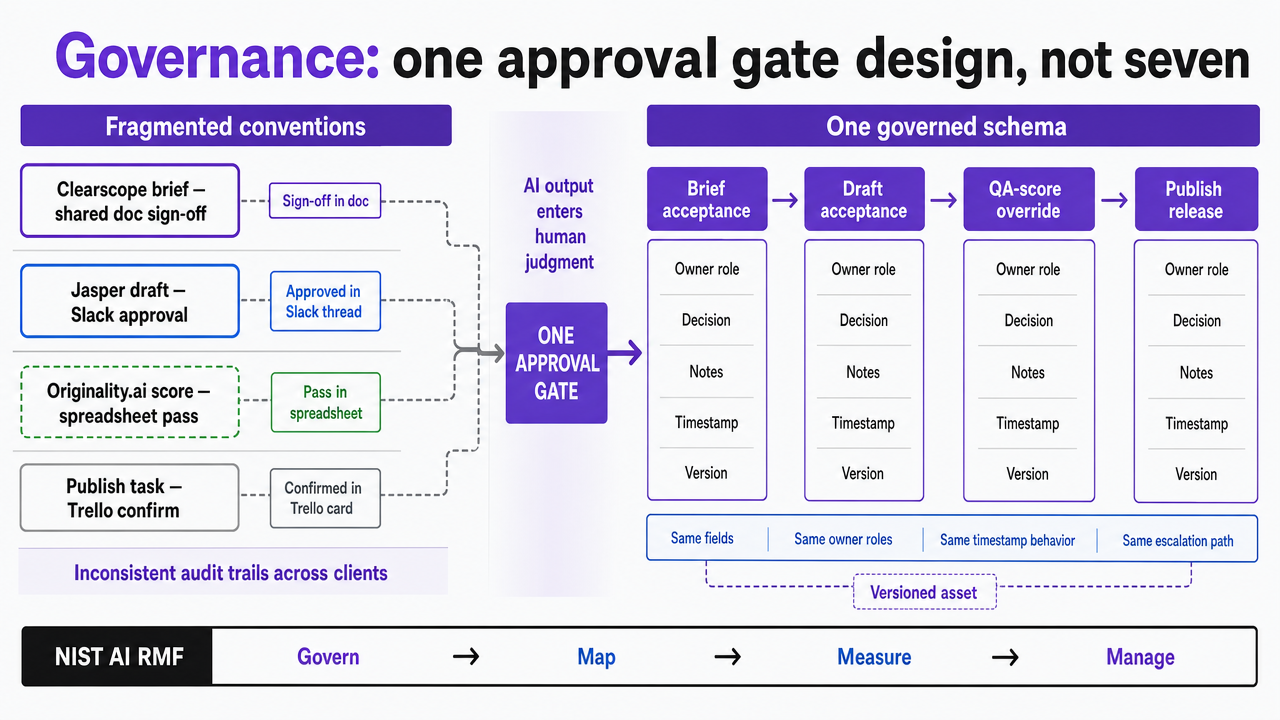 Illustrate the single unified approval gate schema the section prescribes, contrasting the fragmented seven-tool approval pattern against one governed schema applied across all AI-to-human handoffs
Illustrate the single unified approval gate schema the section prescribes, contrasting the fragmented seven-tool approval pattern against one governed schema applied across all AI-to-human handoffs
Frequently Asked Questions
References
- 1.10 Best SEO Content Optimization Tools in 2026 - OneLittleWeb.
- 2.Our Top Content Writing Tools for SEO.
- 3.AI's Impact on SEO and Content Marketing.
- 4.The Impact Of AI-Generated Content On SEO.
- 5.Impact of Generative AI on Content Creation and SEO in 2024.
- 6.The Impact of Large Language Models.
- 7.How to scale the use of large language models in marketing.
- 8.Industrial applications of large language models.
- 9.How Large Language Models are Changing Market Research..
- 10.AI Risk Management Framework | NIST.