
Key Takeaways
- Treat SEO writing software selection as editorial governance: document structure, scannability, and unique-value rules from neutral sources like VA.gov and the Department of Energy before any vendor demo 7, 10.
- Score shortlisted tools with a weighted rubric covering heading hierarchy, scannability, unique-value detection, E-E-A-T, brand voice, workflow, and approval governance, using the same brief across vendors 5, 7, 10.
- Validate tools against business outcomes by running matched human-only and tool-assisted cohorts, tracking impressions, rankings, conversions, and editor hours rather than trusting vendor case studies 9.
- Stress-test governance by mapping brief, outline, line edit, and sign-off checkpoints into the tool's workflow, with named reviewers, version history, and publication blocks until approvals are logged 6.
- Schedule quarterly blind audits of 10% of published pieces against the original rubric to catch quality drift caused by overreliance on fluent drafts before it scales 3, 4.
Why Tool Selection Is an Editorial Governance Decision
SEO writing software encodes editorial judgment at scale, making every tool choice a governance decision. Content marketing managers must select platforms that reliably enforce brand standards, not just produce clean paragraphs. McKinsey's 2023 survey highlights mainstream enterprise adoption of generative AI, particularly in marketing and sales 2. However, Harvard Professional Education cautions that teams outsourcing strategy to tools risk diluting brand voice and strategic differentiation 3.
This governance perspective reorders evaluation. A tool that drafts quickly but generates thin pages, keyword-stuffed content, or off-voice copy creates downstream editing costs and search risks. The VA.gov Design System explicitly warns against thin or "lite" pages lacking sufficient content 7, and the Department of Energy's SEO guidance states that search engines heavily penalize keyword stuffing 10. Software unable to prevent these issues is not an SEO writing tool; it's a draft generator with inherent editorial debt.
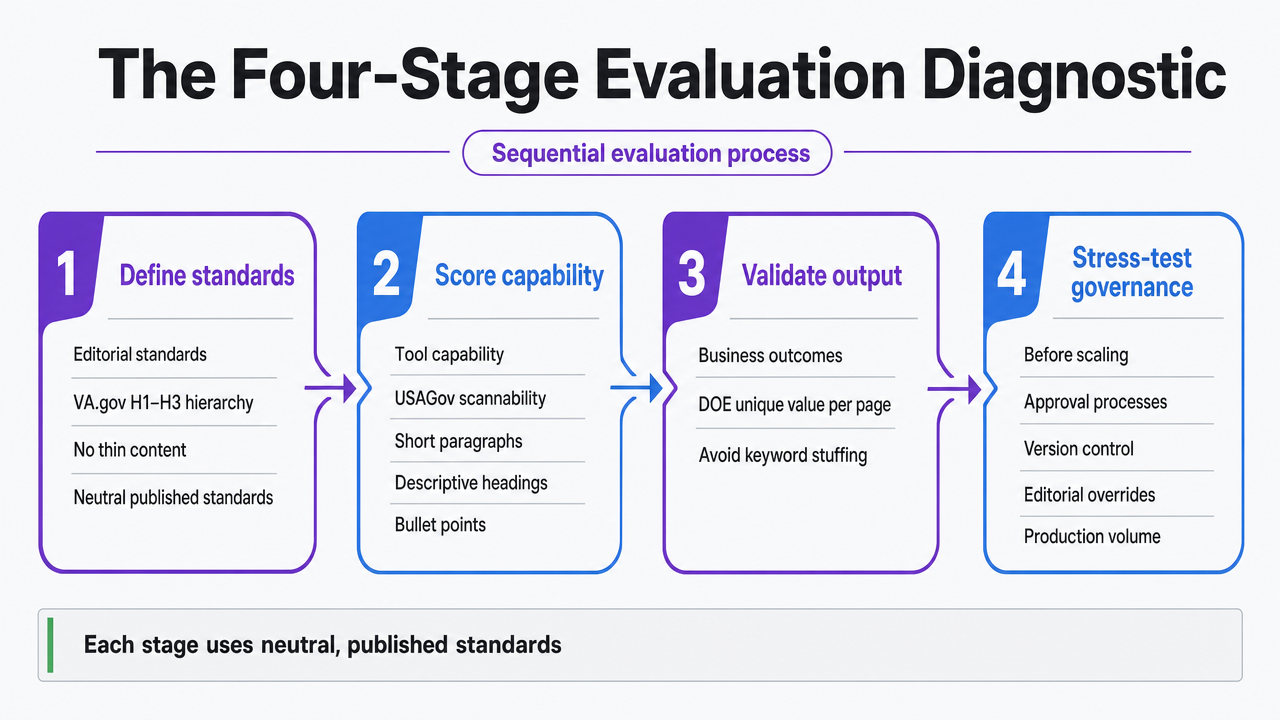
The Four-Stage Evaluation Diagnostic
A robust evaluation of SEO writing software involves four sequential stages:
- defining editorial standards,
- scoring tool capability against those standards,
- validating output against business outcomes, and
- stress-testing governance before scaling usage.
Each stage utilizes neutral, published standards. Stage one aligns structural rules with the VA.gov Design System's H1–H3 hierarchy and its prohibition on thin content 7. Stage two assesses scannability using USAGov's guidelines for short paragraphs, descriptive headings, and bullet points to ensure quick readability 5. Stage three evaluates whether drafts meet the Department of Energy's unique-value-per-page requirement and avoid keyword stuffing 10. Finally, stage four verifies that approval processes, version control, and editorial overrides remain effective under production volume.
The sequence is crucial. Evaluating capability before defining standards leads to assessments based on vendor features. Skipping governance stress-testing allows quality issues to scale. This diagnostic prioritizes standards first, human checkpoints last, with measurable capability and outcome checks in between.
 Visualize the four sequential evaluation stages described in this section as a process flow, giving readers a structural anchor for the rest of the article
Visualize the four sequential evaluation stages described in this section as a process flow, giving readers a structural anchor for the rest of the article
Stage One: Define the Editorial Standard the Software Must Enforce
Codify Structure Rules Before Comparing Vendors
Content structure is a primary area where SEO writing software either proves its worth or creates rework. Before any vendor demonstration, evaluators should document their existing structural guidelines and require the tool to demonstrate adherence.
The VA.gov Design System provides a practical framework, advocating for an H1–H3 hierarchy that mirrors user search phrases, conversational Q&A blocks for question-based intent, and an explicit ban on thin pages lacking sufficient content 7. The Department of Energy adds that each page should have a unique title and offer distinct value compared to other site pages 10. These combined standards yield a testable checklist:
- one H1,
- descriptive H2s linked to search intent,
- H3s for sub-questions,
- no orphan pages, and
- no duplicate content angles.
This checklist serves as an entry exam. Evaluators provide a brief to the tool and then audit the output against each rule. A platform that generates five H2s without H3 substructure, or drafts a 400-word page on a topic typically covered in 1,500 words by competitors, fails this initial structural assessment, irrespective of brand voice or keyword logic. Codifying these rules prevents demos from becoming mere feature showcases.
Set Plain-Language and Scannability Thresholds
Scannability is a measurable quality with established standards. USAGov advises writers to use short paragraphs, clear headings, bold key phrases, and structured content with bullet points and numbered lists to facilitate quick parsing by readers 5. The Bureau of Indian Affairs offers more specific guidance, recommending no more than five sentences per paragraph and a preference for common words over jargon 1.
These sources translate directly into quantifiable thresholds for evaluation:
- a maximum of five sentences per paragraph,
- a sentence length appropriate for the target audience's reading level (often around ninth grade for service categories),
- a descriptive subhead approximately every 150 to 250 words, and
- the use of bullets or lists for serial information.
Bold formatting should be reserved for terms essential for a scanning reader.
SEO writing software should enforce these thresholds during drafting, not merely flag them post-edit. A tool that produces lengthy paragraphs and then offers a readability score after the fact shifts cleanup to the editor. Superior tools generate content that adheres to these thresholds from the outset and treats deviations as blockers, not suggestions. Evaluators should demand to see the enforcement mechanism, not just a report.
Document E-E-A-T and Unique-Value Requirements
Experience, expertise, authoritativeness, and trust (E-E-A-T) are not inherent tool features but signals a draft either possesses or lacks. Digital.gov defines high-quality content as consistent, easy to navigate, produced by an authoritative source, and keyword-optimized 6. The Department of Energy further instructs writers to create content offering unique value, distinct from existing webpages 10. These two standards establish the E-E-A-T baseline any SEO writing tool must meet.
Clear documentation makes this floor testable. Evaluators should specify which authority signals every published page must include:
- author attribution with credentials (where relevant),
- citations to primary sources,
- original data or first-party examples, and
- explicit differentiation from top-ranking competitors for the target query.
The unique-value rule is particularly challenging for generic tools, as most AI drafts tend to converge on the average of existing ranked content.
A robust evaluation directly tests this. Run the tool on a query with strong existing results, then assess whether the draft introduces a new angle, a sourced statistic, or a structural improvement, or if it merely restates the consensus in different words.
Test Advanced SEO Writing Workflows, Risk-Free
Publish live SEO content and measure impact during a full-access, commitment-free trial.
Stage Two: Score Capability Against the Standard
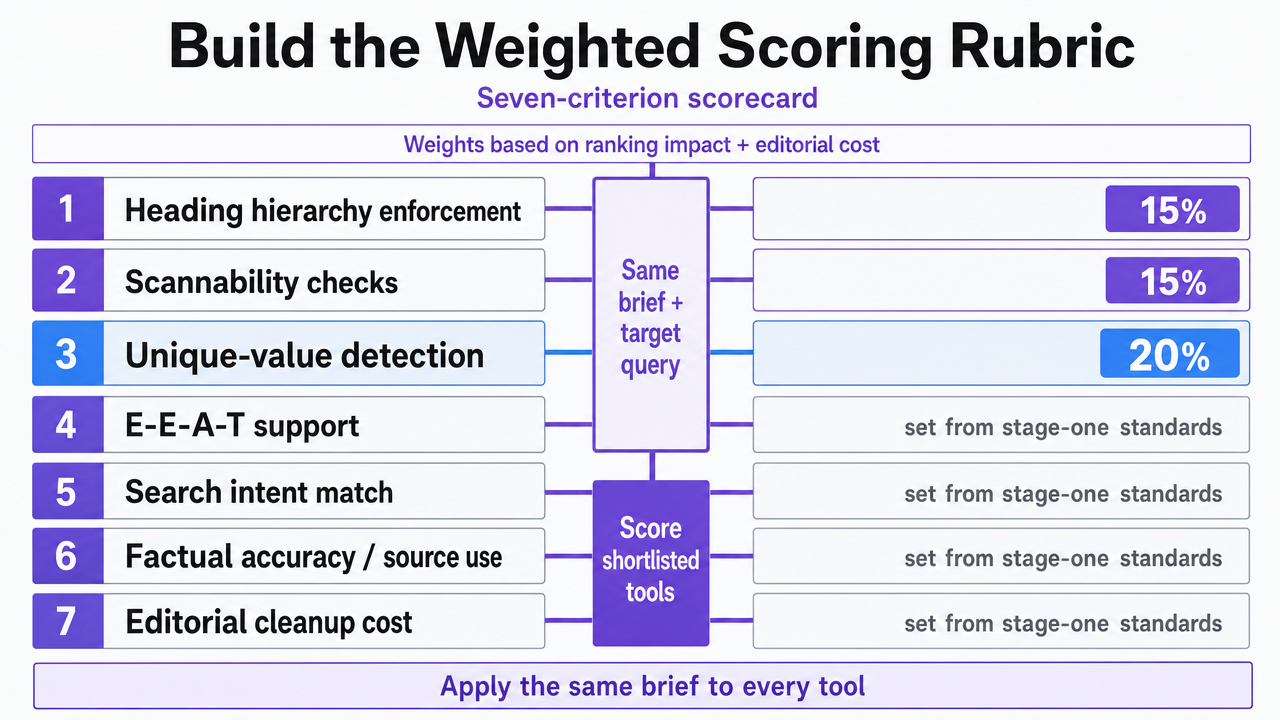
Build the Weighted Scoring Rubric
A scoring rubric is effective only if its weights accurately reflect factors influencing search outcomes. Evaluators should create a seven-criterion scorecard, assigning percentage weights based on impact on rankings and editorial cost, then grade each shortlisted tool using the same brief and target query.
The criteria and weights are derived from the standards codified in stage one.
- Heading hierarchy enforcement, drawing from VA.gov's H1–H3 rule and thin-content prohibition 7, carries approximately 15% weight.
- Scannability checks—paragraph length, bullet structure, descriptive subheads—account for another 15%, based on USAGov's standard for easily parseable content 5.
- Unique-value detection receives the highest weight at 20%, reflecting the Department of Energy's emphasis on originality and differentiation 10.
- E-E-A-T support, covering author attribution, citation handling, and primary-source integration, is 15%.
- Brand voice control is also 15%.
- Workflow integration (CMS connection, version history, comment threads) takes 10%, and
- approval governance completes the rubric at 10%.
Each tool receives a score from one to five per criterion, multiplied by its weight, then summed. A platform excelling in draft fluency but failing unique-value detection cannot achieve a high weighted total, reinforcing that the rubric, not the demo, dictates the outcome.
 Show the seven weighted rubric criteria explicitly enumerated in the prose so readers can apply the scoring model
Show the seven weighted rubric criteria explicitly enumerated in the prose so readers can apply the scoring model
Test Brand Voice Preservation With Live Samples
Brand voice is a criterion often confidently described by vendors but rarely proven. The test is straightforward: upload three to five existing brand samples to the tool, generate a draft on a previously published topic, and then compare the output side-by-side with the original.
A thorough comparison examines three layers.
- The lexical fingerprint includes preferred terms, banned words, and sentence cadence.
- The structural fingerprint covers typical article openings, whether it leads with a claim or a scene, and transition handling.
- The argumentative fingerprint assesses the type of evidence used (data, case examples, expert quotes) and the brand's stance on contentious issues.
Harvard Professional Education's review of marketing AI research identifies overreliance on tools without human oversight as a key factor in brand voice dilution and loss of strategic differentiation 3. For evaluators, this means a tool producing generic content, even if structurally sound, fails this stage regardless of its SEO score. Evaluators should run the same brief through three vendors and ask three brand-savvy editors to blindly identify the in-house sample. If they cannot, the tool's voice fidelity is genuine; otherwise, it scores low.
Audit Keyword Integration for Stuffing Risk
Keyword behavior distinguishes specialized SEO writing software from generic AI drafters. The Department of Energy explicitly states that search engines heavily penalize keyword stuffing, emphasizing natural integration and unique value over density 10. Digital.gov reinforces this, defining quality content as keyword-optimized, authoritative, and easy to navigate, not keyword-saturated 6.
The audit is mechanical. Evaluators analyze the tool's draft for a target query by counting keyword frequency relative to total word count, identifying unnatural constructions or repeated headings, and assessing whether semantically related terms cover the topic or if the draft merely reiterates the head term. A 1,200-word draft using the primary keyword 18 times in stiff phrasing is a failure. A draft using it five times across the H1, lead paragraph, one H2, and natural body mentions, while expanding into related concepts, is a success.
A deeper test involves prompting the tool to optimize more aggressively. Observe whether it adds value or simply stuffs keywords. This reveals if the platform's optimization logic respects the DOE's penalty or treats density as an end in itself.
Stage Three: Validate Against Business Outcomes
Tie Tool Output to Search and Conversion Metrics
Even a high-scoring tool must demonstrate tangible business impact. Stage three moves evaluation from the demo environment to analytics, grading output by its earned value rather than its readability.
The metric set should be focused and outcome-weighted. For each piece produced, evaluators track four signals:
- organic impressions and click-through for the target query cluster,
- ranking position movement over 60-90 days,
- page conversion rate against the team's baseline for that content type, and
- editorial cost per published draft in editor hours.
A tool that boosts impressions but not conversions generates traffic without intent fit. A tool that maintains conversion rates while reducing editor hours achieves the productivity gains McKinsey associates with generative AI in marketing 9.
The validation period requires a control group. Evaluators should publish matched cohorts of human-only and tool-assisted drafts with similar query difficulty and traffic potential, then compare the four signals across cohorts. Cohort comparisons are more reliable than single-piece analyses, providing defensible data when financial stakeholders question subscription value and preventing vendor case studies from replacing internal data.
Compare Tooling Cost to the Marginal Writer Hire
Budget justification relies on a simple comparison: cost per published article from a writer versus cost per published article from a tool subscription, both measured against the same quality standard. The mathematical structure is more important than the specific inputs, which vary by team and vertical.
For a writer, divide the fully-loaded monthly cost (salary, benefits, taxes, software, overhead) by their sustainable monthly article output at the team's editorial standard. For example, a senior writer producing six long-form pieces monthly at cost X yields a per-article cost of X/6. For the tool, divide the subscription cost plus editor hours needed to bring drafts to the same standard by the tool's enabled monthly article output. If a tool allows an existing editor to ship 12 pieces instead of six at the same quality, the denominator doubles, often reducing the per-article cost below that of a writer hire, even with editor time factored in.
McKinsey identifies marketing and sales as a primary beneficiary of generative AI productivity gains, with content creation being a high-leverage use case 9. However, this comparison holds only when the quality bar is fixed. Cost-per-article calculations that ignore editor cleanup, rework rates, or search performance will be inaccurate. Evaluators should publish the formula, inputs, and quality threshold alongside the cost figure to ensure financial discussions remain anchored to output, not just subscription line items.
See How Leading Teams Evaluate and Deploy SEO Writing Software at Scale
Request a walkthrough of enterprise-grade AI workflows for content production, approval, and measurement—optimized for agencies and brands managing high-volume SEO initiatives.
Stage Four: Stress-Test Governance Before Scaling
Map Approval Checkpoints Into the Workflow
Governance distinguishes a tool that merely ships drafts from one that ships drafts safely. Before scaling usage, evaluators must map all existing editorial approval checkpoints and verify that the software preserves each within its native workflow.
A typical map includes four checkpoints:
- brief approval,
- editorial review of the outline,
- line edit of the full draft, and
- final sign-off before publication.
In regulated sectors (e.g., legal, healthcare), a compliance or clinical review checkpoint is added between line edit and publish. SEO writing software that consolidates these into a single draft-and-publish flow removes critical brand controls, regardless of output quality.
Evaluators should verify three mechanical capabilities at each checkpoint:
- named-reviewer assignment with an audit trail,
- version history preserving pre-edit drafts alongside approved versions, and
- the ability to block publication until required signatures are captured.
Digital.gov's quality definition assumes consistent, authoritative content 6, which requires an intact chain of custody. A platform allowing direct CMS publishing without logged approval fails this stage, as governance debt accrues silently until an off-brand or non-compliant page appears in search results.
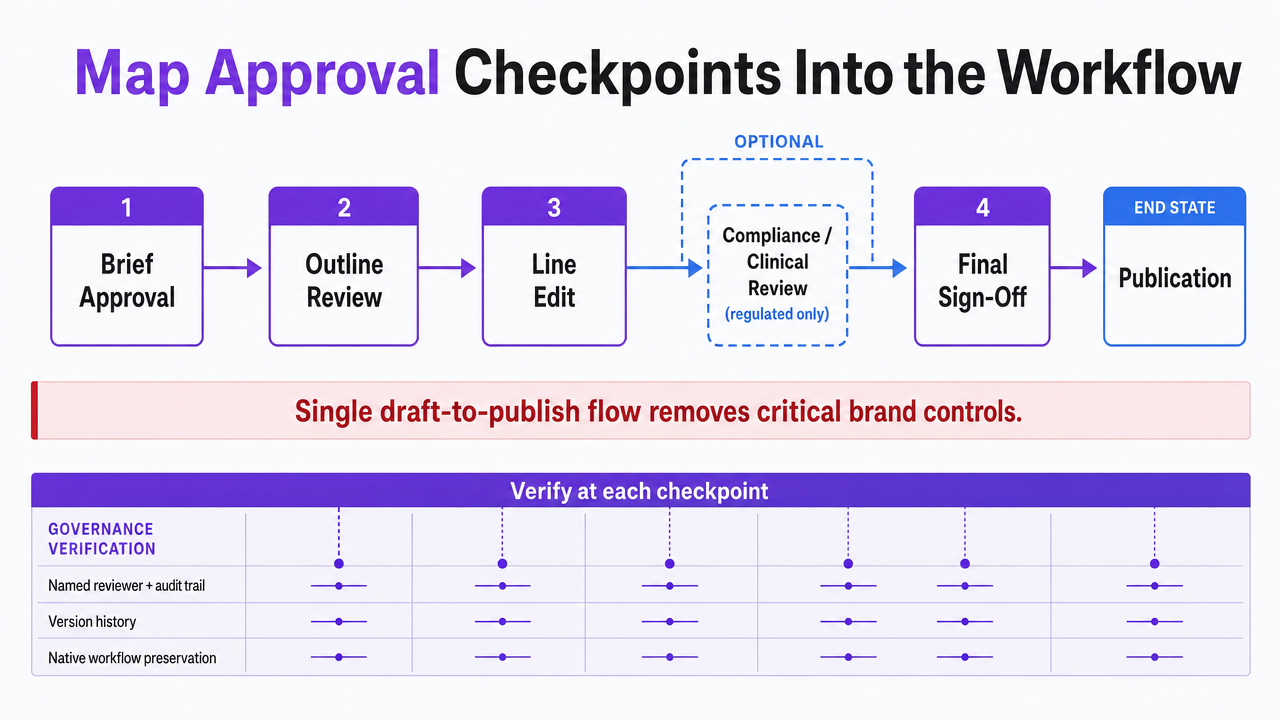 Diagram the four (plus optional regulated) approval checkpoints described in this section as a governance workflow
Diagram the four (plus optional regulated) approval checkpoints described in this section as a governance workflow
Pressure-Test for Overreliance and Quality Drift
Quality drift is a delayed failure mode. A tool performs well initially, usage scales, and months later, the editorial bar subtly drops because reviewers trust the draft rather than auditing it. Research on AI-assisted writing in academia shows that reliance without critical oversight correlates with reduced critical thinking and a regression to the model's default output 4. This cognitive mechanism—deferring judgment to a fluent draft—applies to any team publishing AI-assisted content at volume.
The stress test is procedural: quarterly, sample 10% of published pieces and grade them against the original rubric from stage two, blinded to the tool used. Score deltas exceeding one point on any criterion trigger a review to identify the source of drift: editor fatigue, weakened prompts, or a model update. Harvard Professional Education's review similarly warns that overreliance on AI without human oversight dilutes brand voice and strategic differentiation 3. Scheduling this audit before scaling is the only way to detect and correct drift cost-effectively.
When the Tool Is Only Part of the System
Even a high-scoring SEO writing tool produces only a draft. Search performance depends on the surrounding ecosystem:
- current intent-reflecting keyword research,
- internal linking for topical authority,
- performance data informing future briefs, and
- approval processes gatekeeping publication.
Software that only handles drafting and outputs raw text to a disconnected stack merely recreates the briefing-and-handoff cycle it aimed to compress.
Digital.gov frames quality content as consistent, authoritative, and easy to navigate 6, implying a systemic approach, not just a single output. Navigation relies on site-level internal linking decisions. Authority builds from cumulative coverage across topic clusters. Consistency stems from every draft adhering to the same standard, which is a workflow property, not a draft property. The Department of Energy's emphasis on unique titles, internal linking, and ongoing maintenance reinforces that SEO outcomes result from a connected pipeline 10.
This perspective reframes the shortlist. Evaluators should ask if the tool is part of a platform connecting strategy, drafting, approval, and performance tracking, or if it merely adds another tab to a fragmented stack. Vectoron is designed for this connected approach; the evaluation rubric remains applicable regardless.
Frequently Asked Questions
References
- 1.Writing for the Web: Best Practices.
- 2.The state of AI in 2023: Generative AI's breakout year.
- 3.AI Will Shape the Future of Marketing.
- 4.Exploring the effects of artificial intelligence on student and academic life.
- 5.SEO Tips for Content Writing - USAGov.
- 6.Tapping Into SEO: How Government Websites Can Improve Content.
- 7.Writing for SEO - VA.gov Design System.
- 8.Search optimization for PDF documents | Digital.gov.
- 9.The economic potential of generative AI: The next productivity frontier.
- 10.Search Engine Optimization Best Practices - Department of Energy.