
Key Takeaways
- Brandwatch offers deep social archives and strong workflow exports, but its LLM coverage is bolted on and lacks the audited depth of purpose-built AI-search monitors.
- Sprinklr consolidates listening, publishing, care, and ads in one data model, reducing handoff friction, though sentiment requires custom tuning and pricing locks out smaller teams.
- Talkwalker excels at machine-learning anomaly detection and image recognition, surfacing reputation events users never queried, but its LLM coverage lags the dedicated AI-visibility monitors 5.
- NetBase Quid delivers consumer intelligence at the segment level, answering category-perception questions better than social suites, yet overweights features teams focused on mention counting will not use 1.
- Profound indexes prompts across ChatGPT, Perplexity, Gemini, Claude, and AI Overviews, building prompt taxonomies that expose geographic and intent-level visibility gaps a social suite cannot detect.
- AthenaHQ frames LLM visibility as prompt-level competitive share of voice, mapping cleanly onto existing share-of-voice dashboards and working best as a complement to an installed social suite.
- Otterly.AI is the entry-tier LLM monitor, tracking presence and citations across ChatGPT, Perplexity, and AI Overviews at a price point that fits lean teams adding AI-search measurement.
The Measurement Category Just Fractured Into Three
Seven tools on a shortlist do not equal seven competitors. Forrester's Q4 2025 landscape sorts the broader measurement field into distinct categories, including consumer intelligence platforms (CIPs), which it defines as systems that derive real-time insights and reporting from external data sources using proprietary analysis techniques to enable consumer-driven decisions 1. Social suites sit adjacent to that category, evaluated separately for end-to-end workflows from publishing through analytics 11. A third group—purpose-built LLM and AI-search visibility monitors—has emerged outside both Forrester evaluations entirely.
That split matters because the seven products a Marketing VP is currently being pitched almost never compete on the same job. Brandwatch, Sprinklr, Talkwalker, and NetBase Quid sit inside the social suite and CIP traditions, where AI workflows are being layered onto existing listening and analytics infrastructure 3. Profound, AthenaHQ, and Otterly.AI were built after ChatGPT and AI Overviews became consumer surfaces, and they index prompts and answers rather than posts and articles.
Treating these as interchangeable produces a procurement mistake the C-suite will eventually audit. A social suite cannot tell a brand how it surfaces inside a Perplexity answer. An LLM visibility monitor cannot model share of voice across earned media. The rubric in the next section forces each tool to be scored against the job it was actually built to do, not the job the demo deck implies.
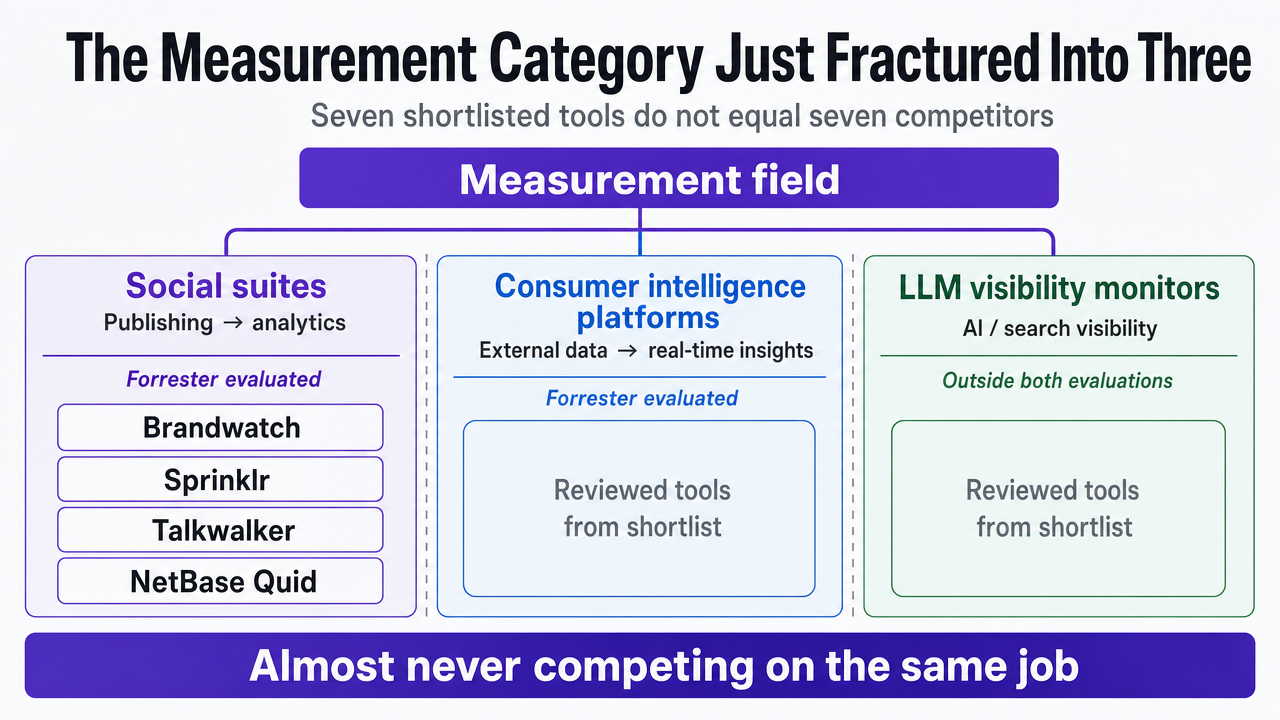 Visualize the three distinct tool categories described in the section: social suites, consumer intelligence platforms, and LLM visibility monitors, mapping the seven reviewed tools into their correct category
Visualize the three distinct tool categories described in the section: social suites, consumer intelligence platforms, and LLM visibility monitors, mapping the seven reviewed tools into their correct category
Why LLM Surfaces Now Belong on the Brand Health Dashboard
Generative AI moved from novelty to routine inside a single survey cycle. Deloitte's 2025 Connected Consumer study found that 53% of surveyed consumers are either experimenting with or regularly using gen AI, up from 38% in 2024—a year-over-year shift measured in consumer behavior, not B2B buyer intent 6. That distinction matters for a Marketing VP scoping measurement infrastructure: the figure describes household-level adoption of ChatGPT, Gemini, and similar assistants, which is the upstream signal for when AI answers start influencing service-category research.
The purchase-side evidence is moving in the same direction. BCG's analysis of AI-assisted shopping reports that consumers find generative AI increases their confidence in purchase decisions, which reframes assistants as a discovery and evaluation channel rather than a curiosity 7. For multi-location service brands, that means a prospect comparing dental practices, law firms, or home services providers may receive a synthesized recommendation from an LLM before clicking a single SERP result.
Incumbent measurement stacks were not built for this surface. A social suite logs posts and articles; it does not capture how a brand is summarized inside a Perplexity answer or whether ChatGPT names a competitor first. Treating LLM visibility as a separate KPI—tracked alongside share of voice and sentiment—closes a gap the brand health dashboard currently leaves open.
The Six-Dimension Rubric Used to Score Each Tool
A defensible procurement decision needs a fixed yardstick. The rubric below scores each tool against the job the Marketing VP is actually buying for, not the demo narrative.
LLM coverage. : Which generative surfaces does the tool index—ChatGPT, Gemini, Perplexity, Claude, Google AI Overviews—and at what frequency? Prompt-level visibility is the differentiator here, not a monthly summary report.
Social and web breadth. : Volume and depth of monitored sources across owned, earned, and review channels. Forrester's social listening analysis notes that vendors increasingly incorporate machine learning into alerts to surface anomalies and outliers not explicitly defined by users, which raises the bar beyond keyword tracking 5.
Sentiment fidelity. : Accuracy on category-specific language. A dental DSO mention of "sensitivity" is clinical; a law firm mention of "aggressive" is positive. Generic models miss this.
Workflow integration. : Whether visibility data exports into the systems where work actually happens—content calendars, paid media, CRM, review response queues. Forrester argues that social listening data should ignite customer influence across the enterprise rather than sit in a standalone dashboard 12.
Time-to-action. : Hours between signal detection and a ranked, assignable recommendation. Dashboards that require an analyst to translate them add latency.
Cost tier relative to in-house headcount. : Annual license plus the FTE hours required to operate the tool, scored against the analyst salary the tool is meant to augment.
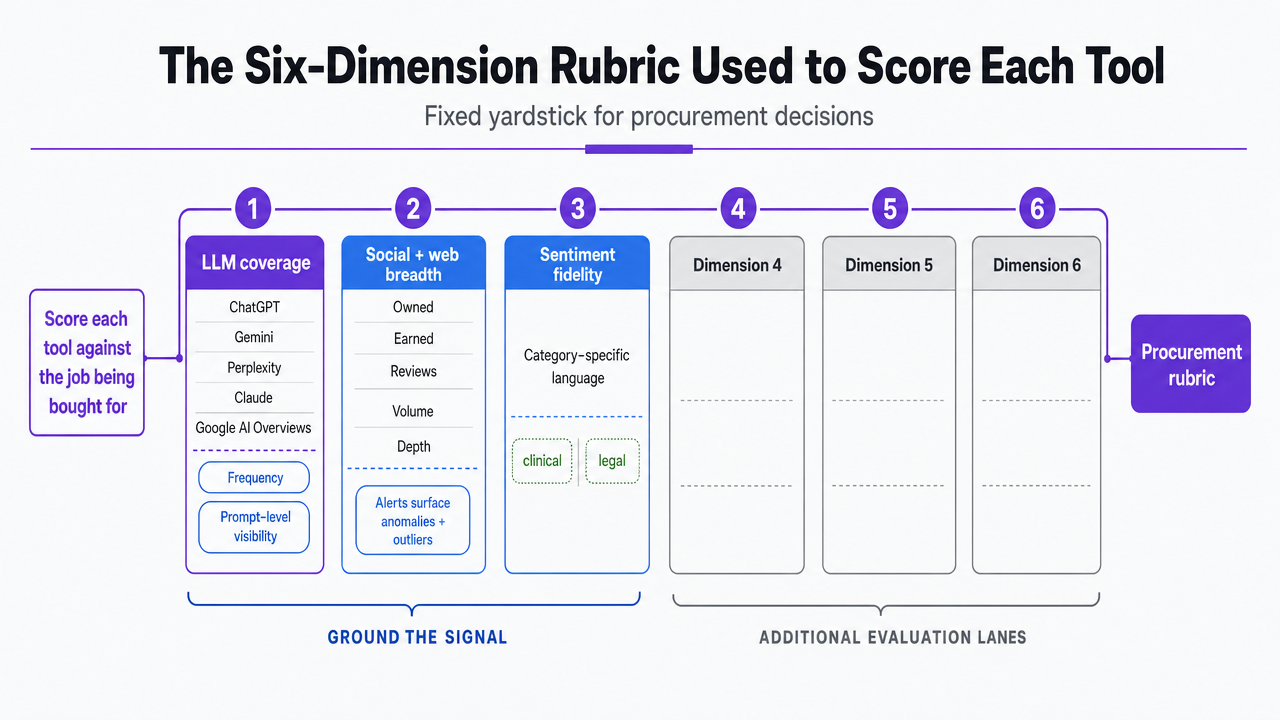 Visualize the six scoring dimensions of the procurement rubric used to evaluate each tool throughout the article
Visualize the six scoring dimensions of the procurement rubric used to evaluate each tool throughout the article
Test AI-Powered Brand Visibility Insights Yourself
Experience real-time brand visibility analysis on your own campaigns before making any commitment.
The Seven Tools, Scored
Brandwatch: Social Suite Depth, LLM Coverage Bolted On
Brandwatch sits inside the social suite tradition Forrester has evaluated for years, with deep historical archives across X, Reddit, forums, blogs, and review sites, and AI-assisted sentiment and topic clustering layered on top 11. For a Marketing VP running a multi-location service brand, that depth pays off in two places: longitudinal share-of-voice tracking against named competitors, and image-recognition queries that catch logo mentions in user-generated content without surrounding text.
The LLM coverage story is less mature. Brandwatch's AI mention tracking surfaces references inside generative answers, but the indexing cadence, prompt variation, and surface coverage have not been audited by Forrester in the same way its social listening capabilities have. A VP scoring it against the rubric should weight LLM coverage as partial, not equivalent to the purpose-built monitors.
Workflow integration is the strongest scoring dimension. Brandwatch exports cleanly into content calendars, paid media QA, and crisis response queues, which aligns with Forrester's argument that listening data should ignite customer influence across the enterprise rather than sit in a standalone dashboard 12. Time-to-action depends on whether an analyst is already in seat to interpret the alerts.
Sprinklr: Workflow Integration Across Care and Marketing
Sprinklr's differentiator is breadth across functions rather than depth in any single one. The platform combines social listening, publishing, customer care, and ad management inside a unified data model, which is the end-to-end workflow pattern Forrester identifies as the defining direction of the social suites category 3. For a service brand where the same brand mention might trigger a review response, a paid retargeting adjustment, and a content brief, that consolidation reduces handoff friction.
Sentiment fidelity is configurable but generic out of the box. Multi-location operators in regulated verticals—behavioral health, dental, legal—will need to invest in custom model tuning before the sentiment scores are trustworthy at the practice level. That tuning is billable professional services time, not a flip-the-switch feature.
LLM visibility is present but secondary. Sprinklr's product roadmap reflects the broader suite pattern of layering AI workflows onto an existing analytics base 11, not a ground-up AI-search index. Cost tier is firmly enterprise. For a marketing org with fewer than five seats and no dedicated social ops team, the license absorbs budget that would otherwise fund execution.
Talkwalker: Anomaly Detection Beyond Predefined Queries
Talkwalker scores well on a dimension most evaluations underweight: the ability to surface mentions and patterns a user did not think to query. Forrester's analysis of the social listening category notes that vendors are incorporating machine learning into alerts to surface anomalies and outliers not explicitly defined by users, which describes Talkwalker's strength precisely 5. For a brand health team, that catches reputation events before they trend.
The platform's image and video recognition reach further than most competitors in the social suite tier, which matters for service categories where customers post photos of work or facilities without tagging the brand. Sentiment fidelity on long-form review text is solid; on short social posts it remains category-generic.
LLM coverage is the rubric's weakest score for Talkwalker. The product is being extended toward AI-surface tracking, but the depth lags Profound, AthenaHQ, and Otterly.AI. Workflow integration into execution systems exists but typically routes through a customer success team rather than native connectors. Cost tier sits below Sprinklr but above the lightweight LLM monitors.
NetBase Quid: Consumer Intelligence at the Segment Level
NetBase Quid is the closest tool on this list to Forrester's consumer intelligence platform definition—systems that derive real-time insights and reporting from external data sources using proprietary analysis techniques to enable consumer-driven decisions 1. It blends social, news, forum, and review data with segmentation analytics that go beyond brand health into category-level consumer behavior modeling.
For a Marketing VP whose C-suite asks questions like "how is our category perceived right now" rather than "how many times were we mentioned," NetBase Quid answers the first question better than any social suite on the list. The segment-level analysis supports message optimization and audience targeting decisions that feed paid and content workflows.
Sentiment fidelity benefits from the CIP-grade analytics layer. LLM coverage, however, is not the product's design point. Workflow integration is strongest into research and strategy functions, weaker into day-to-day execution queues. Cost tier reflects the CIP positioning—above social suites, justified only when the buyer needs segment intelligence, not just mention counting. Scoring it against a pure visibility job overweights features the team will not use.
Profound: Purpose-Built for LLM Answer Tracking
Profound is one of the category-defining tools in the new LLM visibility monitor tier. It indexes prompts across ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews, then tracks which brands are named, how they are described, and which sources the assistants cite. For the job a CMO is now asking about—how the brand shows up inside generative answers—Profound scores at the top of the LLM coverage dimension.
The product's prompt taxonomy is the differentiator. Instead of monitoring a fixed keyword list, Profound builds prompt sets that mirror how prospects actually research a category, then measures share of voice across those prompts over time. For multi-location service brands, that surfaces geographic and intent-level gaps a social suite cannot see.
Social and web breadth is intentionally narrow—Profound is not trying to replace Brandwatch. Sentiment fidelity inside LLM answers is strong because the underlying text is structured. Workflow integration into execution systems is improving but newer than the social suite incumbents. Cost tier sits in the mid-range; the right comparison is against the analyst FTE the tool replaces, not against a $0 baseline.
AthenaHQ: Prompt-Level Share of Voice in ChatGPT and Perplexity
AthenaHQ overlaps with Profound's category but emphasizes prompt-level competitive share of voice as its scoring metric. The platform tracks how often a brand appears in answers to a defined set of prompts, ranks competitors inside those answers, and flags when a competitor displaces the brand in a citation. For a Marketing VP managing a defined competitive set, that framing maps directly onto the share-of-voice dashboards the team already reports.
LLM coverage centers on ChatGPT and Perplexity, with expanding support for Gemini and AI Overviews. Sentiment fidelity is less of a focus than presence and ranking—an intentional product choice that fits the AI-search visibility job.
Social and web breadth scores low by design. Workflow integration is improving but still primarily report-based; the team exports rankings and citation gaps, then routes them into content briefs manually. Cost tier is lower than Profound and significantly lower than enterprise social suites. For a brand that already runs a social suite and needs the LLM layer added, AthenaHQ scores well as a complement, not a replacement.
Otterly.AI: Lightweight AI Search Monitoring for Lean Teams
Otterly.AI is the entry point into the LLM visibility monitor category. The product tracks brand mentions and citations across ChatGPT, Perplexity, and Google AI Overviews using a prompt-based monitoring model, then reports on visibility share and source attribution. For a Marketing VP whose immediate need is a defensible answer to "are we showing up in AI search," Otterly.AI delivers that answer at a price point that does not require a procurement committee.
LLM coverage is solid across the major consumer surfaces. Sentiment fidelity is basic; the tool prioritizes presence and citation tracking over nuanced tone analysis. Social and web breadth is not the product's job, and scoring it against that dimension misreads the category.
Workflow integration is lightweight—exports, alerts, and dashboard views, not deep connectors into content or paid systems. Time-to-action depends on the team's existing execution rhythm. Cost tier is the lowest on this list, which makes Otterly.AI the rational choice for a lean team adding LLM measurement to an existing stack rather than replacing it.
Scorecard: How the Seven Compare Across the Rubric
The matrix below converts the preceding seven tool reviews into a single procurement artifact, scored qualitatively against the six rubric dimensions established earlier. Scoring reflects published capabilities and Forrester's framing of the social suites and consumer intelligence categories 11, not vendor-supplied benchmarks.
| Tool | LLM Coverage | Social/Web Breadth | Sentiment Fidelity | Workflow Integration | Time-to-Action | Cost Tier ||---|---|---|---|---|---|---|| Brandwatch | Partial | Strong | Strong | Strong | Analyst-dependent | Enterprise || Sprinklr | Partial | Strong | Configurable | Strong | Moderate | Enterprise || Talkwalker | Limited | Strong | Strong (long-form) | Moderate | Strong (anomaly alerts) | Mid-enterprise || NetBase Quid | Limited | Strong | Strong | Research-weighted | Analyst-dependent | Enterprise || Profound | Strong | Narrow | Strong (structured) | Developing | Moderate | Mid || AthenaHQ | Strong (ChatGPT, Perplexity) | Narrow | Presence-focused | Report-based | Moderate | Lower-mid || Otterly.AI | Solid (major surfaces) | Out of scope | Basic | Lightweight | Team-dependent | Entry |
The matrix exposes the procurement pattern: no single tool scores well across all six dimensions. A social suite leader and an LLM monitor in combination cover the rubric more honestly than any single product on the list.
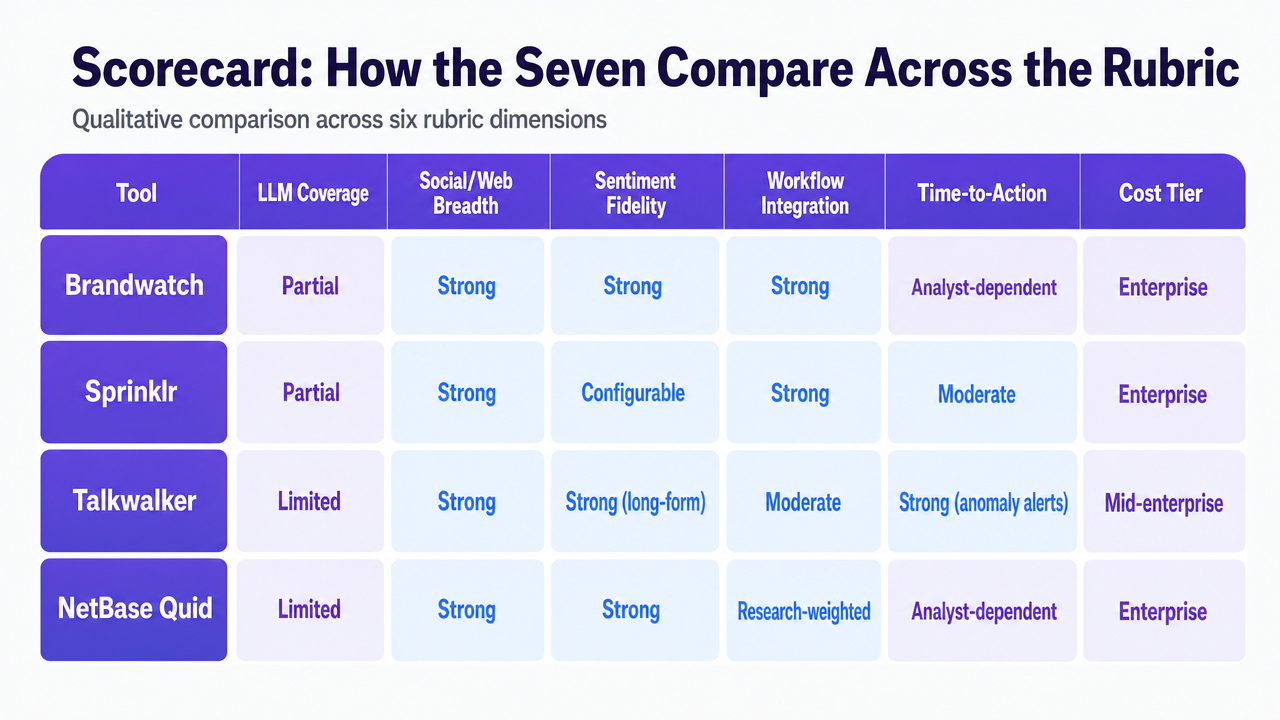 Render the in-article scorecard table as a clean visual matrix comparing all seven tools across the six rubric dimensions
Render the in-article scorecard table as a clean visual matrix comparing all seven tools across the six rubric dimensions
When Each Category Is the Wrong Purchase
Every category on the rubric has a buyer profile that should walk away. Naming those profiles is more useful than another feature list.
A social suite is the wrong purchase when the team has no one in seat to interpret the dashboards. Brandwatch, Sprinklr, and Talkwalker assume an analyst layer that can translate anomaly alerts into ranked actions 5. Without that role, the license funds reports that nobody reads. The same suite becomes correct again the moment a brand crosses into multi-region coverage, where longitudinal share of voice across competitors actually changes content and paid decisions.
A consumer intelligence platform is the wrong purchase when the question the C-suite is asking is "how often were we mentioned," not "how is our category shifting." NetBase Quid's segment-level analytics answer a strategic research question 1. A team that needs mention counting and review response routing is paying CIP-tier pricing for analytics it will not operationalize.
An LLM visibility monitor is the wrong purchase as a standalone measurement stack. Profound, AthenaHQ, and Otterly.AI answer the AI-search question precisely, but none of them replace social and review monitoring. Buying one and retiring the social suite leaves earned media and reputation events unmonitored—a worse position than the one the procurement started from.
See How Leading Teams Quantify and Optimize Brand Visibility with AI
Request a walkthrough of AI-driven brand analysis tools used by enterprise marketers to benchmark visibility, track brand consistency, and surface actionable insights—without expanding your team or managing additional vendors.
If You Manage Multiple Locations: The Stack Consolidation Math
This section narrows to a specific operator profile: a Marketing VP overseeing 15 or more locations in legal, dental, behavioral health, home services, or senior living, where the visibility question multiplies by every market the brand operates in.
The budget math gets uncomfortable fast. A full visibility stack for that operator typically combines a social suite (enterprise tier), a consumer intelligence platform for category and segment analysis 1, and an LLM visibility monitor to cover ChatGPT, Perplexity, and AI Overviews. Each tool assumes an analyst can translate its outputs into ranked actions 5. Without that analyst, the licenses become reporting infrastructure that nobody operationalizes 12.
The variable model below holds vendor pricing as unknowns and exposes the FTE assumption most procurement decks hide:
| Cost Line | Variable | Notes ||---|---|---|| Social suite license | A (enterprise annual) | Scales with seat count and data volume || CIP license | B (enterprise annual) | Often quoted per use case or segment scope || LLM visibility monitor | C (mid-tier annual) | Prompt set size drives pricing || Analyst FTE (fully loaded) | D × N | N = analysts required to synthesize across L locations || Total annual | A + B + C + (D × N) | Excludes integration and services |
For most multi-location operators, the line that breaks the budget is D × N, not A, B, or C. Three tools generate three dashboards in three formats, and the synthesis work scales with location count rather than tool count. Forrester's framing is consistent on this point: listening and intelligence data create value when they ignite cross-functional decisions, not when they sit in parallel dashboards 12.
The consolidation question is whether the operator pays for three measurement surfaces plus the analyst layer, or invests in a unified execution stack where visibility signals route directly into ranked, approvable actions across content, paid, and review response. The second path removes D × N from the equation.
From Visibility Signal to Approved Execution
Measurement maturity in this category is no longer the bottleneck. The seven tools reviewed above can answer most questions a Marketing VP needs to ask about share of voice across social, web, and AI-generated answers. The gap sits one step downstream: the distance between a ranked insight and an approved piece of work shipping across content, paid, or review response.
Forrester's framing of consumer intelligence platforms is explicit on this point. The category creates value when it derives real-time insights from external data and feeds them into consumer-driven decisions, not when it produces parallel dashboards 1. The same report's emphasis on real-time action across crisis detection, reputation management, and message optimization assumes a downstream system capable of executing on the signal 2. Most visibility stacks stop at the insight.
That is where the procurement question reframes. A Marketing VP scoring the seven tools against the rubric will find combinations that cover the measurement surface—typically a social suite paired with an LLM visibility monitor. The next decision is whether the synthesis layer is a human analyst translating three dashboards into briefs, or an execution stack that routes ranked recommendations through human approval before work ships. Vectoron operates in that second layer—not as another visibility dashboard, but as the approval-first execution surface where visibility signals become assigned, sourced, and trackable work across content, SEO, paid, and review channels.
Frequently Asked Questions
References
- 1.The Consumer Intelligence Platforms Landscape, Q4 2025.
- 2.Act On Real-Time Insights With A Consumer Intelligence Platform.
- 3.Four Takeaways On The State Of Social Suites.
- 4.Unlocking the next frontier of personalized marketing.
- 5.Social Listening Platforms Aim To Serve All User Types.
- 6.2025 Connected Consumer: Innovation with trust.
- 7.Consumers Trust AI to Buy Better. Brands Need to Move Quickly..
- 8.The Role of Artificial Intelligence in Personalizing Social Media Marketing.
- 9.AI Will Shape the Future of Marketing.
- 10.Forrester's Upcoming Consumer Intelligence Platforms Landscape.
- 11.The Forrester Wave™: Social Suites, Q4 2024.
- 12.Unleash Social Listening Data's Potential.