
Key Takeaways
- Writer turns brand guidelines into machine-readable rules that flag violations inline, making it ideal for teams running high content volume against a fixed style guide.
- Jasper Brand Voice infers a tone profile from sample content, letting teams set up voice quickly without writing a formal guide, though it lacks approval routing.
- Frase grounds voice at the brief level through SERP-driven content briefs, which suits SEO-led teams but leaves enforcement dependent on brief author discipline.
- Acrolinx scores content against a linguistic standard and gates publication on a numeric threshold, fitting regulated industries where audit trails and compliance matter most.
- Grammarly Business pushes style enforcement into the surfaces writers already use, reducing friction for distributed mid-sized teams without retraining freelancers.
- Vectoron makes approval the routing logic for the whole stack, holding brand memory as a persistent input so nothing ships until a human signs off.
- Brandwatch quantifies share of voice and sentiment across social and earned media, closing the loop on whether campaigns actually moved social visibility.
- Profound treats AI answer engines like ChatGPT, Perplexity, and Google AI Overviews as a measurable channel, surfacing generative share of voice classical SEO tools miss.
- Semrush remains the default classical search visibility layer, delivering keyword and organic SOV reporting that translates into board-level metrics most teams already track.
The three jobs hiding inside 'AI brand visibility'
Search results for "AI brand visibility tools" treat the category as a single thing. It isn't. Once a content team starts evaluating software, the work splits into three distinct jobs, and most listicles collapse them into a generic feature checklist.
Job one is brand memory: the system of record for voice, positioning, audience, and visual identity. Without a defined personality and consistent language, downstream tools have nothing to enforce 1. McKinsey frames the modern version of this layer as the ability to create bespoke tone, imagery, and copy at scale across consumer subsegments 4.
Job two is governance: the approval, compliance, and style-check workflow that decides what actually ships. Harvard's executive education group notes that AI can produce on-voice scripts, articles, and product descriptions quickly, but human oversight is what keeps that output aligned with brand and audience expectations 5.
Job three is visibility measurement: tracking share of voice across classical search, social channels, and AI answer engines like ChatGPT, Perplexity, and Google AI Overviews. A content manager who buys one tool for each job, layered on a shared brand memory, builds a stack that scales. One who buys an "all-in-one" usually ends up doing two of the three jobs in spreadsheets.
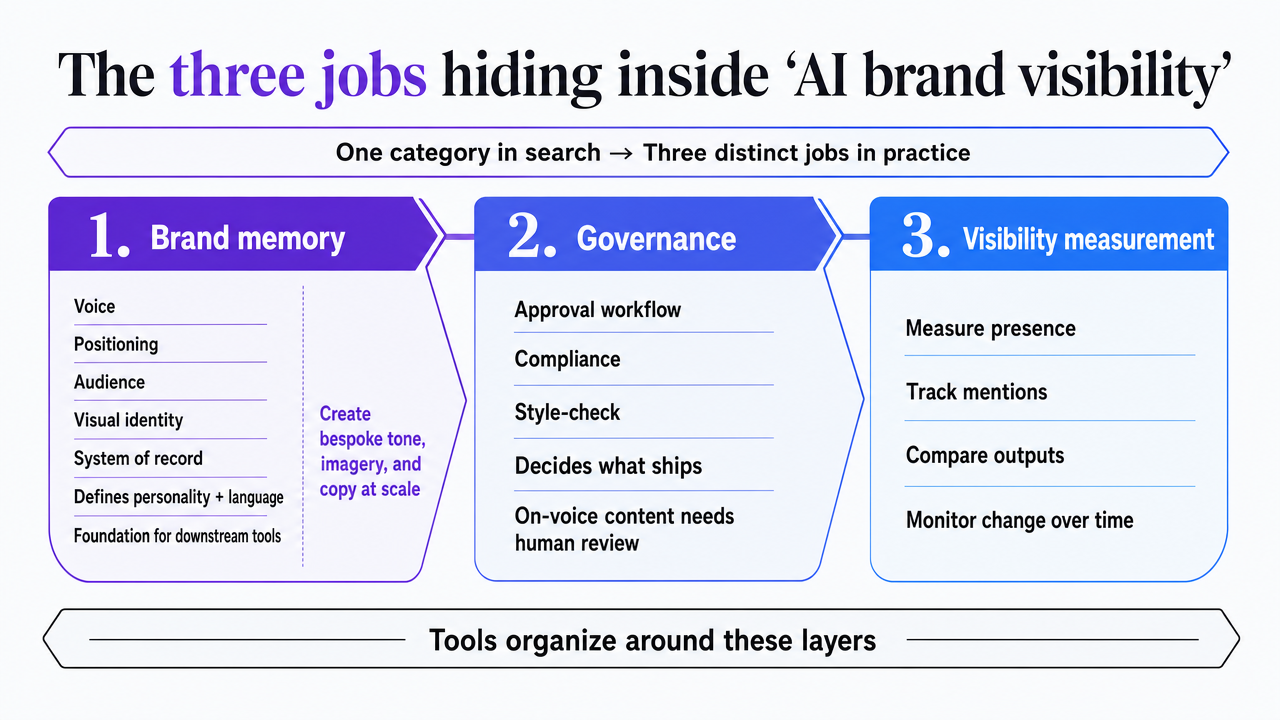 Visualize the article's central framework: the three distinct jobs (brand memory, governance, visibility measurement) that the rest of the article organizes tools around
Visualize the article's central framework: the three distinct jobs (brand memory, governance, visibility measurement) that the rest of the article organizes tools around
Why the category split matters now
Two pressures hit content teams at the same time. Output expectations are climbing, and the surfaces where a brand has to show up keep multiplying. Generative AI moved from pilot projects to standing budget lines in 2023, with organizations reporting gen AI use in at least one business function and expecting material effects on their industries 3. The next year, the spending signal sharpened: a May 2024 Forrester survey found that 67% of AI decision-makers planned to increase generative AI investment within twelve months, citing productivity, innovation, cost efficiency, and revenue growth as the four leading objectives 8.
That investment mix is what makes the category split urgent. Productivity money flows toward generation tools. Innovation and revenue money flows toward visibility measurement, including AI answer engines. Cost-efficiency money quietly funds the governance layer that decides what ships. A content manager who buys against only one of those four objectives ends up with a stack that produces drafts faster but can't prove brand lift, or one that measures everything but can't keep voice consistent across twelve freelancers.
The teams pulling ahead treat the three jobs as separate purchase decisions tied to separate metrics: voice fidelity for memory, approval cycle time for governance, and share of voice for measurement. Buying one box labeled "AI marketing" obscures all three.
The rubric: how each tool was scored
Every tool in this roundup was scored against four axes, each tied to one of the three jobs:
- Brand memory depth — how the tool captures voice, positioning, and visual identity, and whether that memory persists across users, briefs, and channels 4.
- Governance workflow — whether approvals, style checks, and compliance routing exist as native features or get bolted on through email and Slack.
- Multi-channel reach — whether on-voice output extends beyond long-form text to scripts, social posts, product copy, and visual assets 5.
- AI-search visibility — whether the tool tracks brand surfacing in ChatGPT, Perplexity, and Google AI Overviews, not just classical SERPs.
No tool wins on all four. The point of the rubric is to expose the trade-off each platform forces. A team buying a memory-heavy tool with no governance layer will move drafts fast and ship inconsistently. A team buying a measurement tool with no memory layer will see the gap but can't close it. The nine entries below are organized by the job they do best, not by category marketing.
Test AI-Driven Brand Consistency in Real Time
Evaluate automated brand voice alignment by launching and measuring live content during your trial period.
The 9 tools, mapped to the three-job stack
Job one: brand memory tools that hold the voice
Brand memory tools answer one question: when a writer, a freelancer, or a model produces a sentence, what does it compare that sentence against? The strongest options in this layer store voice attributes, audience definitions, banned phrases, and approved examples as structured inputs that downstream systems can read. McKinsey describes this as the capability to generate bespoke tone, imagery, and copy across consumer subsegments without losing coherence 4.
Tool 1 — Writer: brand guidelines as enforceable rules
Writer treats brand guidelines as machine-readable rules, not PDFs. Content teams upload terminology lists, banned phrases, reading-level targets, and approved examples; the platform then flags violations inline as writers draft. The memory layer persists across users, which matters when a content manager rotates five freelancers through a quarterly calendar.
Its strength is governance-ready memory. Voice rules become checks that fire in real time, and the system tracks which writers ship the most violations. Its weakness is measurement: Writer does not track how that voice surfaces in AI answer engines or social channels, so teams pair it with a visibility tool on job three.
Scoring against the rubric: high on brand memory depth, moderate on governance workflow (style enforcement exists, but full approval routing is thin), moderate on multi-channel reach, and absent on AI-search visibility. Content managers running 20+ pieces per month against a fixed style guide get the most value here.
Tool 2 — Jasper Brand Voice: tone capture from sample content
Jasper's Brand Voice feature ingests sample content — past blog posts, landing pages, executive emails — and infers a tone profile that generations are then conditioned on. The capture step is the differentiator. Teams that struggle to articulate voice in writing can produce a working profile by feeding the system 10 to 20 pieces that already feel right.
The trade-off is precision. Inferred voice profiles drift under heavy generation volume, and there is no native approval queue to catch drift before publication. Harvard's executive education group notes that AI can produce on-voice scripts, articles, and product descriptions at speed, but human oversight is what keeps that output aligned 5.
Rubric scoring: moderate-to-high on brand memory depth (sample-based, less rule-based), low on governance workflow, high on multi-channel reach (text formats are broad), and absent on AI-search visibility. Best fit for teams that want fast voice setup without writing a formal guide.
Tool 3 — Frase: brief-level voice grounding for SEO writers
Frase sits closer to the brief than the brand guide. It builds SEO-driven content briefs from SERP analysis, then layers in voice instructions that writers and models follow during drafting. The memory is brief-scoped rather than account-scoped, which suits teams that produce against keyword targets more than against an editorial calendar.
Voice consistency in Frase depends on the discipline of the brief author. A strong brief produces on-voice output; a thin brief produces SEO-shaped filler. The tool does not enforce voice rules after the draft leaves the editor.
Rubric scoring: moderate on brand memory depth (per-brief, not persistent), low on governance workflow, moderate on multi-channel reach (text-heavy), and partial on visibility — Frase covers classical SERP positioning but not AI answer engines. SEO-led teams that already run an external style guide will get the most from it.
Job two: governance tools that route work for approval
Governance tools decide what ships. They check style adherence, route drafts for sign-off, flag legal or compliance risks, and log who approved what. Without this layer, generation speed creates rework: drafts that look on-voice get rejected at the VP level, freelancers re-edit against verbal feedback, and the editorial calendar slips. The tools below treat approval as a first-class workflow rather than an email thread.
Tool 4 — Acrolinx: linguistic compliance scoring at enterprise scale
Acrolinx scores every piece of content against a defined linguistic standard — tone, clarity, terminology, inclusivity — and assigns a numeric grade that gates publication. Enterprise teams use the score as a hard threshold: nothing under 75 (or whatever the team sets) reaches the CMS.
The model is governance-heavy by design. Writers see their score climb or drop as they edit, and editors see aggregated quality trends by author, channel, or campaign. The cost is setup time. Configuring the linguistic standard to match an existing brand voice takes weeks, and the system rewards teams that maintain it.
Rubric scoring: high on brand memory depth (deep linguistic rules), high on governance workflow (scoring gates), moderate on multi-channel reach (text-focused, weaker on visual), and absent on AI-search visibility. Best fit for content teams inside regulated industries or large enterprises where audit trails matter.
Tool 5 — Grammarly Business: style guide enforcement inside the writer's workflow
Grammarly Business pushes style-guide enforcement into the surfaces writers already use — Google Docs, browser editors, email clients. Teams upload a style guide, set tone targets, and writers see inline suggestions as they type. The friction is low, which is the point: governance only works when writers actually encounter it.
The limit is depth. Grammarly's style enforcement handles tone, formality, and banned terms well, but it does not run a multi-stage approval workflow or score drafts against a numeric threshold. Compliance-heavy teams will need a second tool.
Rubric scoring: moderate on brand memory depth, moderate-to-high on governance workflow (inline checks beat post-hoc reviews), high on multi-channel reach (every surface a writer touches), and absent on AI-search visibility. The strongest fit is mid-sized content teams with distributed writers and freelancers who need consistency without retraining.
Tool 6 — Vectoron: approval-first publishing grounded in brand memory
Vectoron treats approval as the routing logic for the whole stack. Brand memory — voice, positioning, competitors, products, market context — is extracted from a company's website and held as a persistent input that specialist strategists draw from when proposing content, SEO, PPC, or social work. Every recommendation surfaces with the strategic reasoning behind it, and nothing ships until a human signs off.
The data-governance angle matters here. A McKinsey case cited in California Management Review found that businesses using anonymized data with privacy-by-design achieved a 30% improvement in personalization accuracy while keeping privacy safeguards intact 2. Approval-first systems extend that principle to brand inputs: every data source feeding the model is governed before it shapes output.
Rubric scoring: high on brand memory depth, high on governance workflow (approval-first by design), high on multi-channel reach, and partial on AI-search visibility through the broader execution loop.
Job three: visibility measurement across search, social, and AI answers
Visibility measurement tools answer a question the first two layers cannot: is the brand actually surfacing where buyers look? That surface is no longer just Google. It includes social conversations, retail search, and increasingly the answers generative engines produce when prospects ask comparison questions. The three tools below cover different slices of that surface, and most mature teams run two of them in parallel.
Tool 7 — Brandwatch: share of voice and sentiment across social channels
Brandwatch monitors social conversations, news mentions, and forum discussions, then quantifies share of voice and sentiment against named competitors. Content teams use it to measure whether a campaign actually moved the needle on social visibility, not just whether the post got likes.
The case for putting social SOV on the rubric is empirical. A peer-reviewed study of AI-driven social media marketing reported a direct effect of 0.83 (p ≤ 0.001) of AI personalization on brand recognition and purchase intent, alongside a 0.572 effect of AI tools on customer information search behavior 9. Personalization that surfaces on social does change recognition — but only if a team can measure where the brand actually appears.
Rubric scoring: low on brand memory depth, low on governance workflow, high on multi-channel reach (social and earned media), and partial on AI-search visibility through emerging mention tracking. Pair with a memory tool to close the loop.
Tool 8 — Profound: tracking brand mentions in ChatGPT, Perplexity, and Google AI Overviews
Profound runs prompt panels against generative engines — ChatGPT, Perplexity, Google AI Overviews, Gemini — and tracks how often a brand appears, how it is described, and which competitors get cited alongside it. The output is a generative share-of-voice metric that classical SEO tools do not produce.
The category is young, and methodology varies by vendor. Profound's value is treating AI answer surfaces as a measurable channel rather than a curiosity. Content managers use the data to identify which topics the model already associates with the brand, which competitors dominate adjacent prompts, and which content gaps explain the gap. The output then feeds back into the brand memory and brief layers.
Rubric scoring: low on brand memory depth, low on governance workflow, moderate on multi-channel reach (limited to generative engines), and high on AI-search visibility. Currently the most direct way to instrument the channel most 2024-era stacks ignored.
Tool 9 — Semrush: classical search share of voice and keyword visibility
Semrush remains the workhorse for classical search visibility. It tracks keyword rankings, organic traffic share, backlink profiles, and competitor positioning across Google and Bing, and most content teams already have a seat. The reason it earns a slot on this list is the rubric, not the brand recognition: classical SERP visibility still drives the majority of trackable demand for most content categories.
Semrush does not measure voice consistency, does not route work for approval, and does not yet match Profound on generative engine tracking. It does, however, give content managers a defensible baseline metric — organic SOV by topic cluster — that translates into board-level reporting.
Rubric scoring: low on brand memory depth, low on governance workflow, moderate on multi-channel reach, and high on classical-search visibility with partial coverage of AI Overviews. The default measurement layer for teams that need one tool and have not yet split the job.
 Improvement in personalization accuracy with anonymized data
Improvement in personalization accuracy with anonymized data
Improvement in personalization accuracy with anonymized data
Governance debt: the failure mode that erases the speed gain
Content teams that buy generation before governance accumulate what looks like productivity and behaves like rework. Drafts get produced in hours, then sit in review queues for days. Freelancers ship copy that scans on-voice and fails legal. Editors retype feedback into Slack threads that no one indexes. The speed gain shows up on the generation dashboard and disappears in the publishing calendar.
This is governance debt: every shortcut around approval workflow, style scoring, and source control compounds into rework that cancels the original time savings. McKinsey's modeling puts the upside of generative AI in marketing at roughly 5–15% of total marketing spend, but that estimate assumes the productivity actually reaches the published asset rather than burning off in revision cycles 7. A team generating four times faster while reviewing six times slower nets out below where it started.
The diagnostic is straightforward. Track approval cycle time alongside draft velocity. If drafts per writer climb while time-to-publish flattens or extends, the stack is producing governance debt. The fix is structural — a memory layer that feeds writers the same rules editors enforce, and a routing layer that closes the loop before publication, not after.
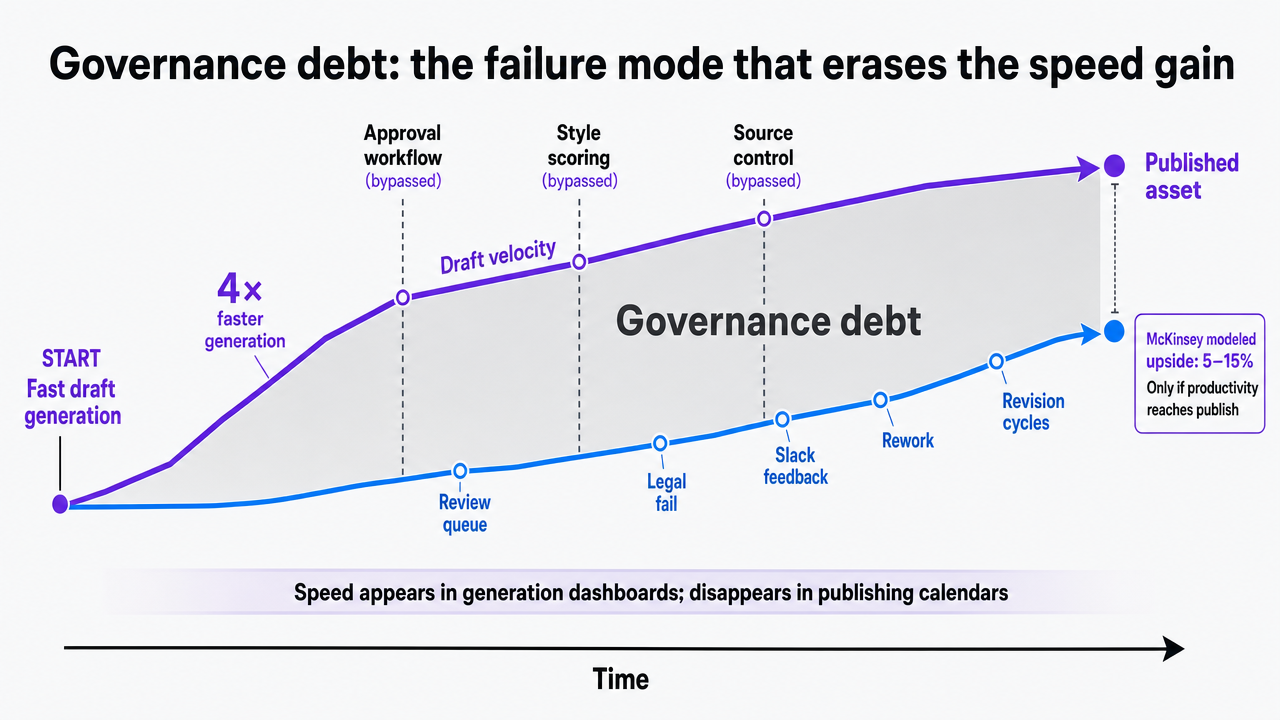 Illustrate the governance debt concept by showing the diverging trajectory of draft velocity vs. time-to-publish, anchored to the cited 5–15% productivity range from McKinsey that appears in the prose
Illustrate the governance debt concept by showing the diverging trajectory of draft velocity vs. time-to-publish, anchored to the cited 5–15% productivity range from McKinsey that appears in the prose
See How Leading Brands Achieve Consistent Voice with AI-Powered Brand Visibility Tools
Request a demo and discover how enterprise teams and agencies use advanced AI to automate brand consistency, streamline approvals, and maintain voice across every channel—at scale.
If you manage multiple locations: stack economics across 10 sites
Audience switch: this section is written for content managers supporting 10-location service operators, not single-site teams.
The stack math changes when one editorial calendar feeds ten locations. Voice has to hold across local pages, paid copy, and review responses, and the governance layer carries ten times the rework risk if it slips. Three cost paths dominate the decision.
| Path | Monthly cost shape (10 sites) | Voice consistency | Approval routing |
|---|---|---|---|
| Traditional agency retainers | Per-location retainer, varies by market | Drifts across account teams | Email and Slack threads |
| Patchwork of point AI tools | Per-seat licenses across 3–5 vendors, varies by stack | Inconsistent without shared memory | Bolted on per tool |
| Unified approval-first platform | $599/mo trial anchor, scales by usage | Single brand memory across locations | Native to the workflow |
McKinsey's productivity modeling puts generative AI's upside in marketing at roughly 5–15% of total marketing spend, an estimate built on assumptions about talent, governance, and integration holding up 7. Applied to a $1M annual marketing budget across 10 sites, that range translates to $50K–$150K in modeled productivity capacity per year — capacity that only converts if the governance layer keeps pace with the generation layer. The path that wins is whichever one closes that gap with the fewest handoffs between locations.
Building the stack: a 90-day sequence for in-house teams
The fastest path to a working stack is sequential, not parallel. Trying to evaluate memory, governance, and measurement tools in the same quarter produces decision fatigue and a half-deployed pilot in each layer.
- Days 1–30: codify the memory layer. Write the voice attributes, banned phrases, and approved examples as structured inputs before any tool ingests them. A documented voice that downstream systems can read is what separates enforcement from suggestion 1. Pilot one memory tool against a single content type — long-form blog or product pages — and measure voice fidelity across three writers.
- Days 31–60: install governance. Add the approval workflow on top of the memory pilot. Track approval cycle time and rework rate as the primary metrics. If drafts per writer climb but time-to-publish flattens, the governance layer is the bottleneck.
- Days 61–90: instrument visibility. Connect a classical search tool and a generative-engine tracker to the published output. Baseline share of voice in both surfaces before optimizing. The measurement layer only earns its slot when it changes what gets briefed next quarter.
Frequently Asked Questions
References
- 1.Maintaining a Consistent Brand Voice & Why it is Important.
- 2.Balancing Personalized Marketing and Data Privacy in the Era of AI.
- 3.The state of AI in 2023: Generative AI's breakout year.
- 4.The next frontier of personalized marketing.
- 5.AI Will Shape the Future of Marketing.
- 6.Marketing and sales soar with generative AI.
- 7.The economic potential of generative AI: The next productivity frontier.
- 8.Generative AI Trends For All Facets of Business.
- 9.The Role of Artificial Intelligence in Personalizing Social Media Marketing Strategies and Its Impact on Customer Experience.
- 10.The Role of AI in Modern Marketing.