
Key Takeaways
- Volume-first keyword lists quietly lose money because search volume ignores conversion behavior, auction cost, and the downstream pipeline that actually determines whether traffic is worth earning 1.
- Treat keyword selection as a portfolio problem ranked by profit-to-cost ratio, then select the top-k prefix that fits budget or production capacity for gains up to 20% over bandit baselines 2.
- A modern automated loop runs four stages—candidate generation, profit-to-cost scoring, prefix selection, and feedback—so realized outcomes continuously update estimates instead of running open-loop on stale volume data.
- Feed the scoring stage with booked calls, qualified consultations, and CRM revenue rather than engagement proxies, since ad exposure alone showed no significant direct effect on satisfaction outcomes 10.
- Privacy regulation and widespread opt-outs thin behavioral inputs 3, 9, so weight first-party conversion data heavily and treat terms near the prefix cutoff as controlled tests rather than direct deployments.
- Apply one profit-to-cost model across multi-location portfolios by feeding location-level V, r, and C into a single ranking pass, which surfaces asymmetries parallel per-site workflows hide 2.
- Keep human editors on intent disambiguation, brand coherence, and the exception queue, since algorithmic ranking cannot catch qualifier signals or positioning conflicts that only appear post-click 8.
- Content managers own threshold setting, first-party signal hygiene, marginal editorial review, and feedback loop enforcement, since the ranking model's accuracy depends entirely on the quality of inputs it receives 6.
Why Volume-First Keyword Lists Quietly Lose Money
Most keyword shortlists still get ranked by search volume, difficulty score, and a rough sense of intent. That habit was defensible when SEO tools first shipped these columns. It is expensive now. Search volume describes how many people might type a term. It says nothing about how many will convert, what a click costs to earn organically or through bid, or whether the resulting traffic ever produces a booked call, a scheduled consultation, or a qualified inbound lead.
The academic literature on sponsored search has been direct on this point for years. Keyword performance is governed by auction dynamics and conversion behavior, not by relevance or demand in isolation 1. A term with 40,000 monthly searches and a 0.4% conversion rate can produce less pipeline than a term with 900 searches converting at 6%, once the cost per click and the production cost of a ranking page are subtracted. Volume-first lists systematically bury the second term.
The consequence for in-house content teams is quiet but compounding. Editorial calendars fill with high-demand topics that attract browsers rather than buyers. Content velocity rises. Cost per qualified lead drifts sideways or up. The problem is not the writing or the SEO fundamentals. It is the ranking primitive at the top of the funnel.
An automated keywords generator earns its budget only when it replaces that primitive with something closer to expected profit per term. The rest of this article explains what that ranking looks like in practice, what modern systems actually compute, and where the loop still needs human hands.
Reframing Keyword Selection as a Portfolio Problem
Profit-to-Cost Ratio as the Ranking Primitive
Treating a keyword list as a shopping cart of individual terms is the wrong mental model. A working automated system treats it as a portfolio under a budget, where each candidate term carries an expected return and a marginal cost, and the job is to select the subset that maximizes profit given a constraint on spend or production capacity.
Rusmevichientong and Williamson formalized this directly. Their adaptive prefix-ordering algorithm ranks candidate keywords in decreasing order of profit-to-cost ratio, then selects a prefix of that ordered list, meaning the top-k terms for whatever k the budget allows 2. Profit per term is modeled as a function of per-keyword cost, query arrival rates, and click behavior, not as a lookup of monthly search volume 2. The ratio itself is the ranking primitive. Volume enters the calculation only through query arrival; difficulty enters only through cost.
The magnitude of the improvement over naive selection matters for anyone building or buying an automated generator. In simulations, the adaptive prefix-ordering approach outperformed standard multi-armed bandit baselines by roughly 7% on average and up to 20% in favorable regimes 2. Those gains come from a single change in ranking logic. No new data source, no additional traffic, no larger budget.
For an in-house content team, the operational translation is straightforward. Every candidate term needs two numbers before it earns a slot on the calendar: an expected profit contribution, derived from conversion rate and average booked-inquiry value, and a marginal cost, whether that is CPC for paid or estimated content production and link-earning cost for organic. Terms are then sorted by the ratio, and the calendar fills from the top down until the budget or production capacity binds. That is the ranking primitive an automated keywords generator should compute.
Auction Dynamics and Conversion Behavior, Not Relevance
Relevance is a necessary condition for a keyword to earn traffic. It is not the variable that determines whether the traffic is worth earning. That distinction gets lost in most keyword workflows, and it is why relevance-first shortlists routinely underperform their forecasts.
Empirical work on sponsored search shows keyword performance is shaped by the auction the term sits inside and by the conversion behavior of the users who click, not by topical fit alone 1. Two terms with identical relevance to the same landing page can produce different economics because their bid landscapes differ, their click-through curves differ, and the intent distribution of their searchers differs. A high-relevance term with three well-funded competitors and a bottom-of-funnel intent skew that favors incumbents is not a profitable term. It is an expensive one.
Auction structure applies to organic selection as well, though the currency is different. The competitors are the pages holding the top positions, the bid is the content and authority investment required to displace them, and the click-through curve is dictated by SERP features rather than ad rank. An automated generator that scores organic candidates needs a proxy for this competitive cost, typically some blend of domain-level backlink profiles, content depth in the top results, and query-level SERP volatility.
The practical filter that follows: a keyword should not enter the shortlist because it describes the service well. It enters because the expected conversion behavior of its searchers, discounted by the cost of winning the auction it lives in, clears the profit-to-cost threshold set at the portfolio level.
Inside the Modern Automated Keyword Loop
Four Stages: Candidate Generation, Scoring, Prefix Selection, Feedback
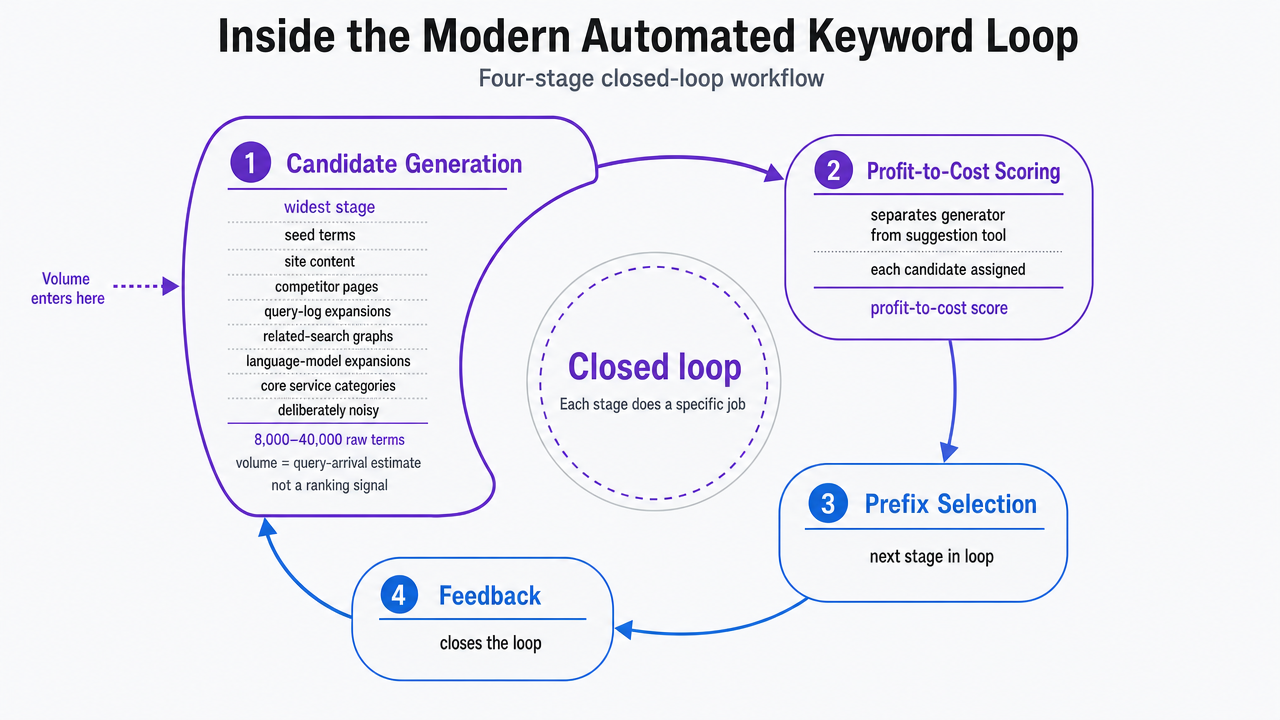
A modern automated keywords generator is not a suggestion engine wrapped around a search-volume API. It is a closed loop with four stages, each doing a specific job the others cannot do alone.
- Candidate generation is the widest stage. The system pulls seed terms from existing site content, competitor pages, query-log expansions, related-search graphs, and increasingly from language-model expansions of core service categories. The output is deliberately noisy. For a multi-location dental group, a raw candidate pool of 8,000 to 40,000 terms is typical before any economic filter is applied. Volume enters here only as a query-arrival estimate, not as a ranking signal.
- Profit-to-cost scoring is the stage that separates a generator from a suggestion tool. Each candidate is assigned an expected profit contribution, modeled as a function of per-keyword cost, query arrival rate, and click behavior 2. For paid channels, cost is the auction bid the term is likely to clear. For organic, it is a proxy built from the competitive profile of the current top results. Profit is estimated from historical conversion rates on the closest-matching pages the site already runs, adjusted for the intent signal the term carries 1. Terms without a defensible profit estimate are held in a separate pool rather than forced into the ranking.
- Prefix selection is the budget-binding step. Candidates are sorted in decreasing order of profit-to-cost ratio, and the algorithm selects the top-k prefix that fits the available spend or production capacity 2. The cutoff is not a difficulty score. It is the point where the marginal ratio drops below the portfolio threshold the operator has set.
- Feedback closes the loop. Realized click behavior, ranking outcomes, and downstream conversions update the profit and cost estimates for the next selection pass. Without this stage, the system runs open-loop and drifts within weeks.
Why Convergence Is Independent of Keyword Count
One property of the prefix-ordering approach matters more than any other for teams operating at scale: the algorithm's convergence to a near-optimal selection does not depend on the total size of the candidate pool 2. Doubling the inventory from 20,000 to 40,000 terms does not double the learning cost or degrade the ranking quality.
This is the opposite of what standard multi-armed bandit methods do when the arm count grows large. Bandit approaches must spend exploration budget on every new keyword, and their regret bounds worsen as the decision space expands 2. That is why volume-first shortlists tend to shrink as teams mature; the workflow cannot afford to test more terms without diluting signal.
The operational consequence is direct. A content team can let the candidate pool run wide, seeded aggressively from language-model expansions and competitor scrapes, without paying a proportional cost in decision quality. The ratio ranking sorts the noise to the bottom, and the prefix cutoff never sees it. What binds the system is production capacity and budget, not keyword count. That is the property that makes automation worth running in the first place.
 Visualize the four-stage closed-loop workflow (candidate generation, profit-to-cost scoring, prefix selection, feedback) that structures this section, since the section explicitly walks through each stage in sequence
Visualize the four-stage closed-loop workflow (candidate generation, profit-to-cost scoring, prefix selection, feedback) that structures this section, since the section explicitly walks through each stage in sequence
Test Automated Keyword Discovery On Live Content
Experience real-time keyword analysis and publish optimized content before your trial ends.
The Downstream Conversion Signal Most Generators Ignore
The scoring stage described earlier depends on a conversion estimate. Most automated keyword generators build that estimate from click-through rate, bounce rate, and time on page. Those are proxies for engagement, not for revenue. A term that produces long sessions and low bounce can still fail to generate a single booked consultation, and a term that produces short, decisive sessions can be the most profitable one in the portfolio.
The gap matters because ad exposure and on-page engagement do not, on their own, produce the outcomes that justify the spend. One study of online advertising found no significant direct effect on customer satisfaction in its sample, with brand knowledge mediating the relationship instead 10. The lesson is not that ads fail. It is that the signal a keyword generator needs sits further down the funnel than most systems look. Engagement metrics describe what happened on the page. Profit is determined by what happened after it.
For service verticals, the useful signals are concrete:
- qualified inbound calls tagged to the landing URL,
- booked consultations attributed to the entry keyword,
- form submissions that survive intake screening, and
- revenue realized from the resulting customer.
Feeding these back into the profit estimate reshapes the ranking. Terms that looked mediocre on CTR climb the list when their call-to-booking rate is 3x the site average. Terms with heavy traffic and thin downstream yield drop below the prefix cutoff 2.
Wiring this loop requires call-level and CRM-level data, not just analytics tags. A term's expected profit contribution should be recomputed each cycle using the realized conversion behavior of the pages it fed, weighted by intake quality rather than raw form count. That is the input most generators still do not have, and it is the input that separates a keyword system that estimates profit from one that only estimates traffic.
Where Input Data Degrades: Privacy Constraints on Keyword Systems
Every stage of the profit-to-cost loop depends on inputs that trace back, directly or indirectly, to observed user behavior. Query arrival rates come from search logs. Conversion estimates come from analytics tied to identifiers. Bid landscapes come from auction telemetry that platforms assemble from cross-site signals. When those inputs thin out, the ranking primitive keeps running, but its estimates drift.
Privacy regulation is the most visible pressure on that input layer. Empirical work on GDPR found measurable effects across the data industry that supplies keyword-based online advertising, including reduced observability of user journeys and narrower audience pools available for measurement 3. The regulation did not remove keyword auctions. It changed the density and freshness of the behavioral data that scoring models rely on to estimate click behavior and downstream conversion.
User-facing opt-out mechanisms compound the effect. An empirical audit of 150 websites found that roughly 90% of sites that mentioned email communications or targeted advertising offered an opt-out 9. The prevalence matters more than the exact figure. Opt-out infrastructure is now the default rather than the exception across the properties that produce the behavioral signals keyword generators consume. Every opt-out shrinks the sample the scoring model uses to estimate the conversion rate for a given term, and the shrinkage is not random. Users who opt out tend to cluster in the segments most concerned about tracking, which biases the remaining sample toward less privacy-sensitive cohorts 9.
The operational consequence for content teams is a systematic overconfidence problem. A generator that scores terms using thinning behavioral data will still return a ranked list. The list will look complete. But confidence intervals around each profit-to-cost estimate widen as sample sizes fall, and the prefix cutoff becomes less reliable near the margin, which is exactly where selection decisions matter most.
Two adjustments hold the loop together under these conditions:
- Weight first-party conversion data more heavily than platform-supplied behavioral proxies, since first-party signals from booked calls, form intake, and CRM outcomes are not degraded by third-party opt-outs.
- Treat the top of the prefix as high-confidence and the marginal terms near the cutoff as candidates for controlled testing rather than direct deployment.
The ranking still holds. The uncertainty band around it is simply wider than it was a decade ago, and the workflow has to account for that.
 Websites offering opt-out for email or targeted advertising
Websites offering opt-out for email or targeted advertising
Websites offering opt-out for email or targeted advertising
Applying One Profit-to-Cost Model Across a Portfolio of Locations
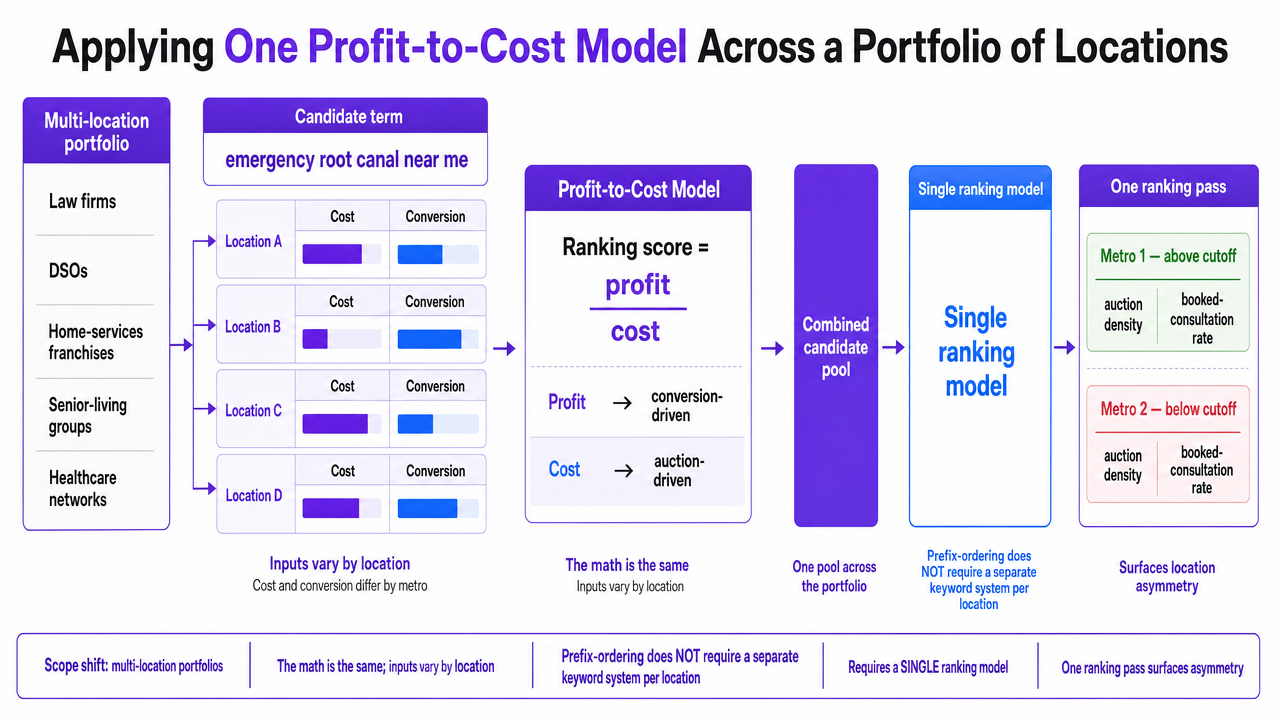
Note: this section shifts scope from single-site content teams to operators running multi-location portfolios—law firms with regional offices, DSOs, home-services franchises, senior-living groups, and healthcare networks. The math is the same. The inputs vary by location, and that variation is the point.
The prefix-ordering approach does not require a separate keyword system per location. It requires a single ranking model that accepts location-level inputs for cost and conversion, then ranks the combined candidate pool across the portfolio 2. A term like emergency root canal near me may clear the profit-to-cost cutoff in one metro and fall below it in another, purely because the local auction density and the location's booked-consultation rate differ. One ranking pass surfaces that asymmetry; parallel per-location workflows hide it.
The variables an operator needs at the location level are compact. The table below defines them without inventing benchmarks, since realistic values depend on vertical, geography, and intake quality.
| Variable | Definition | Source at the location level |
|---|---|---|
| V | Average booked-inquiry value (revenue per qualified booking) | CRM, intake system, or call-tagging outputs |
| r | Conversion rate from click to booked inquiry | First-party analytics joined to CRM |
| C | Marginal cost per click (paid) or amortized production cost per ranked page (organic) | Ad platform reports or content-ops accounting |
| τ | Portfolio profit-to-cost threshold for prefix cutoff | Set by operator based on budget and capacity |
Expected profit per click for a term at a given location resolves to (V × r) − C. The profit-to-cost ratio is ((V × r) − C) / C. Locations feed their own V, r, and C into the ranking, and terms are sorted across the whole portfolio in decreasing order of that ratio 2. The prefix cutoff at τ determines which term-location pairs earn a slot on the production calendar or bid sheet.
Two operational habits keep this model honest:
- Recompute V and r per location on a fixed cadence using realized bookings rather than form fills, since intake quality varies sharply across sites.
- Review the term-location pairs sitting just above and just below the cutoff each cycle; that margin is where portfolio reallocation produces the largest gains without expanding total spend.
 Visualize the variable definition table and profit-to-cost formula that the section explicitly provides, showing how location-level inputs feed one ranking model
Visualize the variable definition table and profit-to-cost formula that the section explicitly provides, showing how location-level inputs feed one ranking model
See How Automated Keyword Generation Surfaces High-Value Search Terms Fast
Connect with our team to review live demos of AI-driven keyword discovery and see benchmark data on how automation accelerates profitable term identification for agency and enterprise-scale content teams.
Where Human Editorial Judgment Still Governs the Loop
Automation earns the ranking pass. It does not earn the decision. Even a well-tuned prefix-ordering system produces a shortlist that needs editorial hands before it becomes a calendar or a bid sheet, and the reasons are structural rather than sentimental.
The first hand-off is intent disambiguation. A term like free consultation can sit at the top of a personal-injury firm's profit-to-cost ranking on the strength of historical conversion data, then attract a wave of price shoppers when it actually runs. Query strings do not carry the qualifier signals an intake team recognizes on the phone. Research on AI-assisted content workflows argues directly for this checkpoint: incorporating popular keywords from user searches improves discoverability, but human editors are needed to catch nuance and audience fit the algorithm misses 8. The editor is not overriding the ratio. They are correcting the intent estimate the ratio was built on.
The second is brand and message coherence. A generator that scores terms in isolation will surface profitable candidates that fight the positioning of adjacent pages, cannibalize existing rankings, or force a tone the brand does not use. Those costs do not appear in the profit-to-cost estimate. They appear later, as diluted authority and inconsistent voice across the site.
The third is the exception queue. Terms with thin behavioral data, sensitive verticals, or ambiguous compliance implications should route to a reviewer rather than auto-publish. The workflow that pairs algorithmic ranking with an approval gate is the one that scales without producing regrettable pages at the margin.
Operating the System: What Content Managers Own
The ranking model does not run itself. It runs on inputs a content manager owns, and the quality of those inputs determines whether the prefix cutoff sits in the right place. Four operating responsibilities matter more than the rest.
Threshold setting. : The portfolio profit-to-cost threshold is a policy decision, not an algorithmic one. Set it too low and the calendar fills with marginal terms; set it too high and production capacity sits idle. Managers should recalibrate the cutoff each quarter against realized pipeline, not against forecasted profit 2.
First-party signal hygiene. : The conversion rates feeding the scoring stage come from analytics joined to CRM and call-intake data. When tagging drifts, the ranking drifts with it. A weekly audit of URL-to-booking attribution keeps the estimates honest, particularly where third-party behavioral data has thinned.
Editorial review at the margin. : Terms near the cutoff carry the widest uncertainty bands and produce the largest reallocation gains when reviewed. Managers should route that band to human editors while letting the high-confidence prefix flow through, a hybrid pattern consistent with how AI-assisted content workflows perform best 8.
Feedback loop enforcement. : Realized bookings, not form fills, update the next scoring pass. Without that discipline, the system drifts toward engagement proxies and away from profit. AI-based ad targeting produces meaningful ROI gains over non-algorithmic approaches, but those gains depend on the quality of the data being fed back 6. Owning the loop is what turns an automated keywords generator from a suggestion tool into a portfolio engine, and it is the work that stays with the team regardless of which platform, including Vectoron, executes the ranking.
Frequently Asked Questions
References
- 1.An Empirical Analysis of Search Engine Advertising: Sponsored Search and Keyword Selection.
- 2.An Adaptive Algorithm for Selecting Profitable Keywords for Search-Based Advertising Services.
- 3.The Effect of Privacy Regulation on the Data Industry: Empirical Evidence from GDPR.
- 4.Privacy Risks with Facebook's PII-Based Targeting: Auditing a Data Broker’s Matching Process.
- 5.Examining the Data Practices of Social Media and Video Streaming Services.
- 6.Computing advertising intelligent computing and push based on ....
- 7.Digital transformation and marketing: a systematic and thematic review.
- 8.Beyond algorithms: The human touch machine-generated titles for ....
- 9.An Empirical Analysis of Data Deletion and Opt-Out Choices on 150 ....
- 10.Impact of Online Advertisement on Customer Satisfaction With the ....