
Key Takeaways
- The unit of optimization has shifted from page-keyword pairs to entity-claim-citation triples, so briefs must name entities and list sourced claims rather than target phrases.
- Refresh cadence now competes with publish cadence as a primary metric, with pricing, statistical, and definitional claims aging out of retrieval sets on different thresholds.
- SEO, paid, and backlink work should write against one shared entity graph, because consistent claims compound retrieval authority while siloed channels produce claim drift and contradictions.
- Multi-location and multi-service-line operators face compounding coordination costs, making account-level throughput—not per-asset price—the variable that determines whether claim freshness holds across the portfolio.
The optimization unit just changed under marketers' feet
Search did not get a new interface. It got a new unit of optimization.
For two decades, content teams optimized page-keyword pairs: one URL, one primary query, one ranking position to chase. That model assumed a human typing a query, scanning ten blue links, and clicking through. AI-mediated search surfaces—Google's AI Overviews, ChatGPT, Perplexity, Claude—do not behave that way. They retrieve discrete claims from across many pages, assemble an answer, and cite the sources they trust. The page is no longer the atom. The claim is.
That shift breaks the workflows most marketing teams still run on. Briefs are written around target keywords. Editorial calendars are organized by publish dates rather than refresh dates. Backlinks chase domain authority instead of entity authority. Each of these habits was rational under keyword retrieval and is increasingly expensive under retrieval-augmented systems, which reward content structured as verifiable, sourced, machine-readable statements 3.
The reframe this article makes is direct. An automated search engine is now two things at once: the AI discovery layer marketers optimize for, and the internal content system they must build to compete inside it. The rest of this piece walks through what that changes about briefs, refresh cadence, channel coordination, and the unit economics of producing content at the volume retrieval systems now require.
From keyword pages to entity-claim-citation triples
Why keyword retrieval hit a ceiling
Keyword retrieval was always a workaround. The system asked the user to translate intent into a string, then ranked documents by how closely they matched that string. It worked when the index was small and the user was patient.
The clinical literature exposed the ceiling early. A systematic review of how physicians use electronic information retrieval systems found that adoption was limited not by access but by time pressure, search skill, and system usability—doctors knew the answer was in the database and still could not extract it inside a clinical workflow 1. This finding generalized, as knowledge workers across fields spent most of their search budget reformulating queries rather than reading results.
Marketing teams built an entire discipline around that friction. Keyword research tools, SERP analyzers, and topic clusters all exist because the retrieval layer could not infer meaning. Content had to be engineered to match the string the user was likely to type.
Retrieval-augmented systems remove that translation step. The model interprets intent, decomposes it into sub-questions, and pulls discrete passages from across sources to assemble an answer. The user no longer needs to phrase the query well, and the publisher no longer wins by matching the phrase. The optimization target moves upstream, to the structure of the claims themselves.
The triple that retrieval systems actually reward
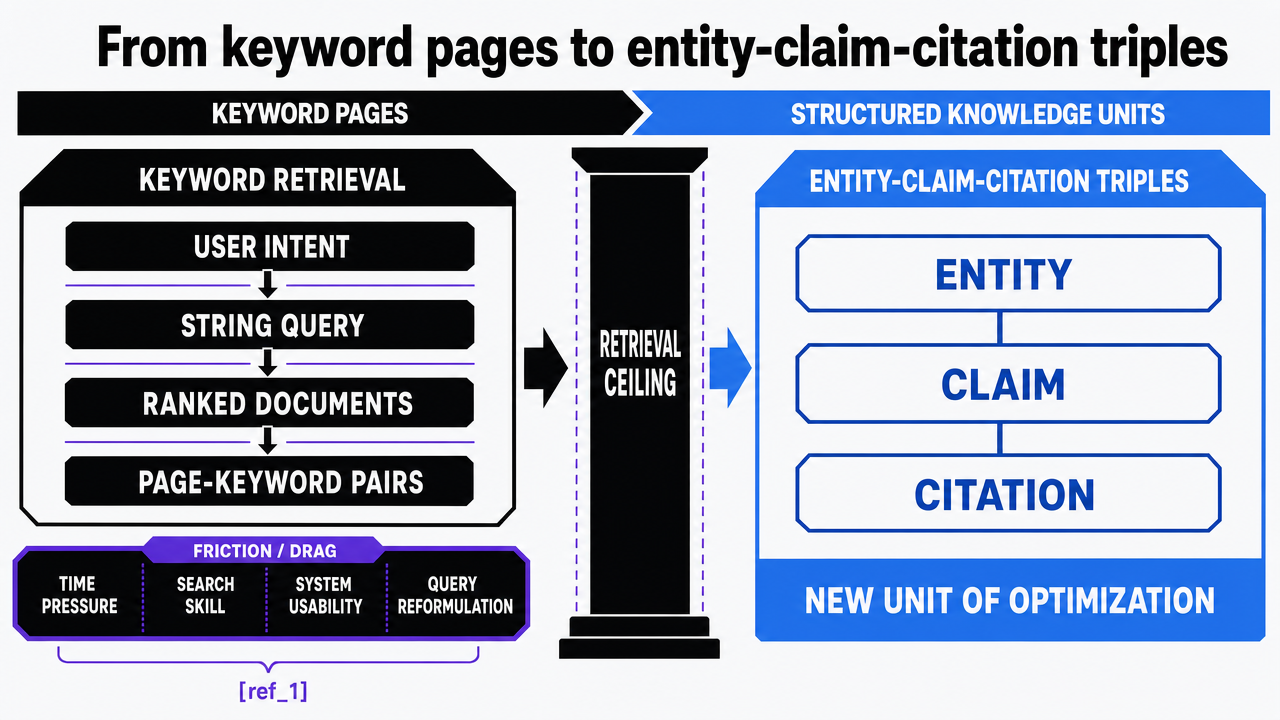
What replaces the page-keyword pair is a smaller, more portable unit: the entity-claim-citation triple. An entity is the named thing the claim is about—a procedure, a product category, a condition, a metric. The claim is a verifiable statement attached to that entity. The citation is the source that backs the claim. Retrieval-augmented systems index, score, and surface content at the level of these triples, not at the level of the URL.
The evidence for why this matters comes from the clinical side, where retrieval-augmented architectures have been measured against traditional methods on accuracy and freshness. A 2025 narrative review of retrieval-augmented generation in medical AI reports that RAG-based systems demonstrated superior performance over traditional methods in tasks such as clinical decision-making and information extraction, because retrieval over curated, structured sources produces more accurate and up-to-date answers than relying on a model's internal weights alone 3. The mechanism that drives that gain in medicine is the same one that determines whether a marketing claim gets cited in an AI Overview: discrete, sourced statements outperform long, undifferentiated prose.
The practical consequence reshapes briefs. A keyword-optimized paragraph repeats a target phrase, varies synonyms, and hopes a passage ranks. A triple-optimized paragraph names the entity explicitly, makes one factual claim per sentence, attaches a source the retrieval system can verify, and uses consistent terminology so the entity resolves cleanly across pages.
Three downstream effects follow:
- Brief templates have to list claims, not keywords.
- Editorial review has to check whether each claim carries a source the model can locate.
- Refresh cycles have to track claim age, because a stale statistic gets dropped from the retrieval set even when the URL still ranks.
The unit of work is no longer the article. It is the claim.
 Visualize the structural shift from page-keyword pairs to entity-claim-citation triples as the new unit of optimization, directly supporting the section's core argument
Visualize the structural shift from page-keyword pairs to entity-claim-citation triples as the new unit of optimization, directly supporting the section's core argument
Sizing the discovery shift without overclaiming it
The scale of the shift is easier to caricature than to measure. Most commentary defaults to either dismissal or hype. The number worth anchoring on sits between them.
McKinsey estimates that AI-powered search could affect approximately $750 billion in annual revenue by 2028, and reports that roughly half of consumers already use AI-enabled search tools 2. Two scope notes matter. First, that figure measures revenue affected by AI-mediated discovery, not revenue captured by any single channel or vendor. It describes the volume of commercial activity passing through a changed interface, not a marketing outcome benchmark. Second, the consumer-adoption read is a usage signal, not a substitution signal—many of those users still touch traditional SERPs in the same session.
What the number does establish is direction and pace. A discovery layer that touches three-quarters of a trillion dollars in annual revenue within three years is not a fringe channel that content teams can defer. It is a layer that will sit between most commercial intent and most brand surfaces, including for B2B SaaS buyers researching categories and healthcare patients researching procedures.
The operational reading is narrower than the headline. AI search does not replace organic traffic models overnight. It changes which content gets cited, which gets summarized away, and which never surfaces because its claims cannot be parsed. Teams that treat the McKinsey estimate as a deadline for restructuring briefs and refresh cycles will be early. Teams that treat it as a forecast to debate will spend 2026 retrofitting content their competitors already structured for retrieval.
Test Automated Content Strategy With Live Output
Evaluate real-time impact of coordinated search-driven content execution on your growth targets before making a commitment.
What an automated search engine actually does to a content operation
Briefs change shape: from target keyword to source-backed claim set
The brief is where the operating model lives or dies. A brief built around a target keyword tells a writer what to rank for. A brief built around a claim set tells a writer what to assert, what to cite, and what the retrieval layer needs to verify.
The shift is mechanical. Each brief opens with the named entity—a procedure, a category, a metric, a product class. Beneath it sits a list of claims the article must make about that entity, each claim paired with the source that backs it and the date that source was published. Synonyms, related entities, and disambiguation notes sit alongside, because retrieval systems resolve entities across documents and penalize ambiguous references.
This is closer to how clinical knowledge systems are built than to how editorial calendars usually run. Scoping reviews of large language models in patient education report that LLM output quality depends directly on the structure and accuracy of the source content the system retrieves, which means content teams now author for two readers: the human scanning a page and the model parsing claims out of it 5.
Three practical changes follow:
- Writers receive sources before they receive an outline.
- Editors check claim provenance before they check prose.
- Every brief carries an expiration field, because a claim with no refresh date will silently rot out of the retrieval set.
Production cadence becomes a refresh cadence
Publish dates used to matter. Refresh dates matter more.
Retrieval-augmented systems score sources partly on recency, because freshness correlates with accuracy in domains where facts change. The 2025 review of retrieval-augmented generation in medical AI documents this directly: RAG architectures outperformed traditional methods on clinical decision-making and information extraction in large part because retrieval over curated, current sources beat reliance on static model weights 3. The same dynamic governs which marketing claims get cited in an AI answer and which get summarized into a competitor's citation slot.
That changes the production calendar. A traditional editorial calendar tracks net-new assets per month. A retrieval-aware calendar tracks two numbers: net-new assets and refreshed claims. A statistic updated last quarter is worth more in the retrieval set than a 2,000-word post published yesterday with no sources.
The operational redesign is concrete. Claims carry version stamps. Refresh queues run on age thresholds:
- Pricing claims at 90 days
- Statistical claims at 180
- Definitional claims at 12 months
Production capacity gets split between new entity coverage and claim maintenance on existing entities. Teams that publish 20 new posts and refresh zero claims a month will lose retrieval share to teams that publish eight and refresh sixty.
 Visualize the age-threshold refresh queues described in the prose (90/180/365 days), supporting the operational redesign argument with the exact thresholds cited in the section
Visualize the age-threshold refresh queues described in the prose (90/180/365 days), supporting the operational redesign argument with the exact thresholds cited in the section
Intent-to-CTA matching, modeled on structured retrieval
The funnel side of content has the same problem in miniature. A visitor arrives with a specific intent; the page offers a generic CTA. Retrieval systems have already solved a sharper version of this matching problem in adjacent domains.
TrialGPT, an NIH-developed algorithm, searches ClinicalTrials.gov to match potential volunteers to relevant trials and generate summaries explaining why each match fits 7. The mechanism is intent decomposition over structured records: the user's situation gets parsed into eligibility criteria, those criteria query a structured corpus, and the system returns ranked matches with reasoning attached.
That pattern transfers cleanly to marketing. A visitor's query—or the inferred intent behind it—decomposes into a small set of attributes: stage of research, segment, service line, geography. Each landing experience carries the same attributes as structured metadata. The match is computed, not curated by a content marketer guessing which CTA to place where.
The downstream effect is that conversion paths stop being one-CTA-per-page. They become attribute-tagged offers retrieved against attribute-tagged intent, the same way a retrieval system returns claims against a question. Content briefs, landing pages, and CTAs share one schema.
One entity graph behind SEO, paid, and backlinks
SEO content, paid landing pages, and backlink targets usually live in three different spreadsheets owned by three different people. Retrieval-aware operations collapse them into one structure: a shared entity graph that every channel writes against.
The graph is simple in concept. Each entity the brand wants to own—a product category, a procedure, a use case, a competitor comparison—gets a record. Attached to that record are the claims the brand asserts about the entity, the sources backing each claim, the URLs where those claims appear, the paid landing experiences targeting the entity, and the external pages that cite it. One node, every channel's work on it visible in one place.
That structure resolves coordination problems that channel silos cannot. When the SEO team updates a statistic on a pillar page, the paid team sees that the landing page running against the same entity now contradicts the refreshed claim. When the backlink team pitches a guest post, the graph shows which entities lack external citations and which already have ten. When a competitor publishes a sharper claim on the same entity, every asset pointing at that entity surfaces in one refresh queue.
The marketing literature supports the underlying mechanism. Reviews of AI in healthcare marketing find that AI enables more precise targeting and personalization when channels draw from shared analytics rather than siloed campaign data 9. The same logic applies upstream: shared entity data produces consistent claims, and consistent claims compound retrieval authority across surfaces that an automated search engine reads as one signal about the brand.
What automated search engines penalize
Retrieval systems are not neutral about what they ingest. They demote and drop entire categories of content, often silently.
The first category is undifferentiated AI-generated prose with no source structure. Scoping reviews of large language models in patient education report that output quality degrades sharply when the underlying source corpus lacks accurate, structured information—models cannot retrieve what was never authored as a discrete, verifiable claim 5. The same constraint applies in reverse to publishers. A 1,500-word post that paraphrases the same idea six times offers nothing for a retrieval system to extract, and the URL gets passed over for a shorter page that states one sourced fact cleanly.
The second category is orphaned entities. When a brand publishes about a service line on one page, names it differently on another, and never resolves the two, retrieval systems treat the entity as ambiguous and lower confidence in every claim attached to it.
The third category is stale claims. A statistic from 2021 cited in 2025 with no refresh date signals abandonment. The retrieval set drops it, even when the page still ranks on traditional SERPs—two scoring systems running in parallel, with different memories.
Quantify Content Impact with Automated Search Intelligence
See how automated search analysis aligns SEO, PPC, and backlink strategies—enabling unified, data-driven content decisions for complex multi-location or multi-brand portfolios.
If you manage multiple locations or service lines, the math changes
Where coordination cost compounds across a portfolio
For operators running more than one location or service line, the retrieval problem multiplies. A single-site brand maintains one entity graph. A 12-location dermatology group, a SaaS company with eight product lines, or an agency managing 30 client accounts maintains dozens of overlapping graphs that have to stay consistent across every surface an automated search engine indexes.
The coordination tax shows up in three places:
- Claim drift: the same procedure described three different ways across three locations resolves as three weak entities instead of one strong one.
- Refresh lag: a pricing update applied to the flagship page leaves 11 location pages contradicting it for weeks.
- Channel desync: paid landing experiences targeting a service line cite numbers the SEO team has already replaced.
Each gap costs retrieval authority that compounds across the portfolio rather than failing in one place.
Operator economics: agency, in-house, and AI-platform models compared
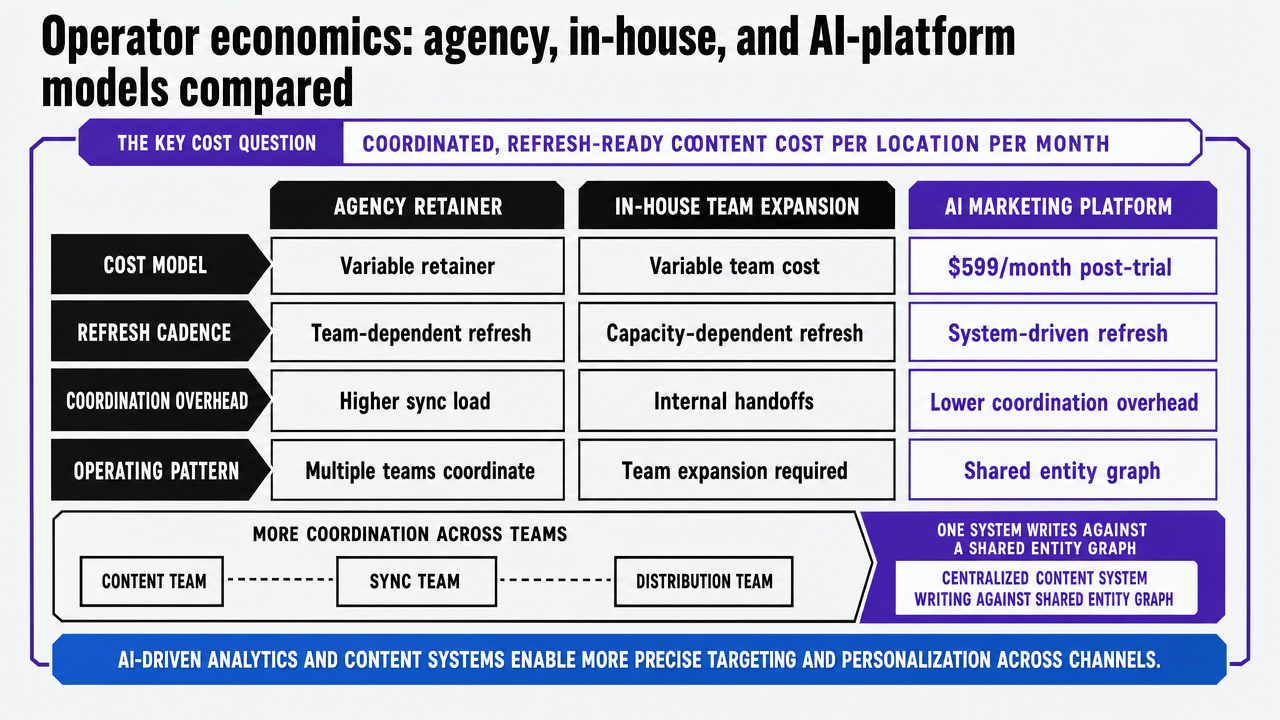
The cost question is not how much content costs per asset. It is how much coordinated, refresh-ready content costs per location per month, at the cadence retrieval systems reward. Three operating models produce that output differently.
The table below uses variable ranges for agency and in-house models because no supplied research benchmarks those figures, and uses the published $599/month post-trial price as the anchor for the AI-platform column. Reviews of AI in healthcare marketing note that AI-driven analytics and content systems enable more precise targeting and personalization across channels, which translates into lower coordination overhead when one system writes against a shared entity graph rather than syncing three teams 9.
| Variable | Agency retainer | In-house team expansion | AI marketing platform |
|---|---|---|---|
| Monthly cost basis | Retainer $X–$Y per account, often per-location billing | Loaded salary $A–$B per FTE, fixed regardless of output | $599/month, account-level (post-trial) |
| Assets produced per month | Capped by retainer scope | Capped by FTE capacity | Capped by approval throughput, not production |
| Refresh cadence | Quarterly or on-request | Ad hoc, depends on backlog | Continuous, age-threshold queues |
| Locations or service lines per dollar | Scales linearly with billing | Scales linearly with headcount | Account-level, all sites covered |
| Coordination overhead | Account managers, status calls, handoffs | Internal standups, contractor sync | Command Center approval, shared entity graph |
The differentiator is not unit cost. It is how each model handles the second variable—refresh cadence—at portfolio scale. An agency retainer that produces 12 new assets a quarter cannot maintain claim freshness across 30 location pages. An in-house team sized to refresh 30 location pages cannot also expand entity coverage. A platform priced at the account level decouples cost from location count, which is the variable that actually compounds in a multi-site operation.
 Visualize the three-column operating model comparison from the article's table, summarizing how cost, refresh cadence, and coordination overhead differ across agency, in-house, and AI-platform approaches
Visualize the three-column operating model comparison from the article's table, summarizing how cost, refresh cadence, and coordination overhead differ across agency, in-house, and AI-platform approaches
The trust caveat that has operational consequences
AI-mediated discovery rewards content the model can verify and demotes content it cannot. That makes accuracy a production constraint, not a brand value.
Reviews of AI in healthcare marketing note that AI enables more precise targeting and personalization, but warn that opaque algorithms and misused data erode the trust the channel depends on 10. The operational reading is narrower than the ethics framing usually allows. When a brand publishes a claim the retrieval layer cannot match against a credible source, the model either drops the claim or substitutes a competitor's. Trust failures show up as missing citations, not as reputational events.
Two practical controls follow. Every claim in a brief carries a source the retrieval system can independently locate, not an internal link standing in for evidence. And any AI-assisted draft passes a provenance check before publish—each statistic, each definition, each comparison tied to a verifiable origin. The control is editorial, but the consequence is distributional.
An operating model for the next 24 months
The teams that compound retrieval authority over the next two years will share four operating habits, not four tools.
- Briefs name the entity and list source-backed claims before they list a target keyword. The writer's job is to assert and cite, not to weave a phrase.
- The editorial calendar tracks refreshed claims as a first-class metric alongside net-new assets, with age thresholds queuing pricing, statistical, and definitional claims on different cadences.
- SEO, paid, and backlink work all write against one entity graph, so a refreshed claim on a pillar page propagates to the landing experience and the outreach target in the same cycle.
- Every claim carries a verifiable source the retrieval layer can independently locate, because models drop what they cannot confirm and substitute a competitor's citation in its place 5.
The constraint behind all four habits is throughput. Producing structured, sourced, refresh-ready content at the cadence retrieval systems reward exceeds what most in-house teams or quarterly agency retainers can sustain. Platforms like Vectoron compress that throughput into one account-level program, which is the variable that matters when the unit of optimization is the claim, not the page.
Frequently Asked Questions
References
- 1.How Well Do Physicians Use Electronic Information Retrieval Systems?.
- 2.Winning in the age of AI search.
- 3.Enhancing medical AI with retrieval-augmented generation.
- 4.How Artificial Intelligence Is Changing Health and Health Care.
- 5.Large language models in patient education: a scoping review of applications, evaluation, and challenges.
- 6.Artificial intelligence in healthcare and medicine: clinical applications and challenges.
- 7.NIH-developed AI algorithm matches potential volunteers to clinical trials.
- 8.The Role of AI in Hospitals and Clinics: Transforming Healthcare in the Digital Era.
- 9.Artificial Intelligence in Healthcare Marketing: Opportunities and Challenges.
- 10.Artificial Intelligence in Healthcare Marketing: Opportunities and Challenges.