
Key Takeaways
- An automated search tool functions as a retrieval-augmented layer across GA4, Search Console, SEMrush, and Google Ads, eliminating the manual cross-system stitching that consumes analyst capacity each week.
- Five functions borrowed from systematic review tooling—term discovery, cross-database query translation, screening, prioritization and synthesis, and citation recommendation—map directly to SaaS growth workflows 6, 7.
- Evaluate vendors on workflow performance against live accounts, not benchmark demos, and require source traceability, drift monitoring, and index transparency to manage retrieval bias and post-deployment drift 3, 5, 9.
- Stand up the retrieval layer in three 30-day phases: index trusted sources, replicate a past cross-channel decision, then retire at least two standing reports to confirm the tool reduces rather than adds noise 2, 5.
The Query-Translation Tax Hiding in Your Growth Stack
A typical SaaS growth team uses four primary data systems: GA4 for behavior, Search Console for organic query and impression data, SEMrush or Ahrefs for competitive and backlink intelligence, and Google Ads for paid performance. These systems do not share a common query language or entity model for keywords, pages, campaigns, or accounts. Extracting a single answer that requires data from all four—such as "which non-brand queries are losing organic share while paid CPC climbs, and which of those map to pages with declining backlink velocity?"—requires an analyst to manually combine CSVs, pivot them in a spreadsheet, and present findings days later.
This manual data stitching is a recurring cost, paid weekly through salaried headcount, and it increases with the number of channels, properties, and product lines managed. McKinsey's analysis of generative AI in consumer marketing highlights a significant shift: campaigns that once took months for content design, insight generation, and customer targeting can now be executed in weeks or days when AI is integrated for at-scale personalization and automated testing 8. The primary bottleneck is not data volume, but the manual translation between disparate systems.
An automated search tool, as defined here, eliminates this translation tax. It is not merely another dashboard or keyword database. This article will define its function, architectural origins, and how a VP of Marketing should evaluate it.
What 'Automated Search Tool' Actually Means in 2025
From Keyword Lookup to Retrieval-Augmented Insight Layer
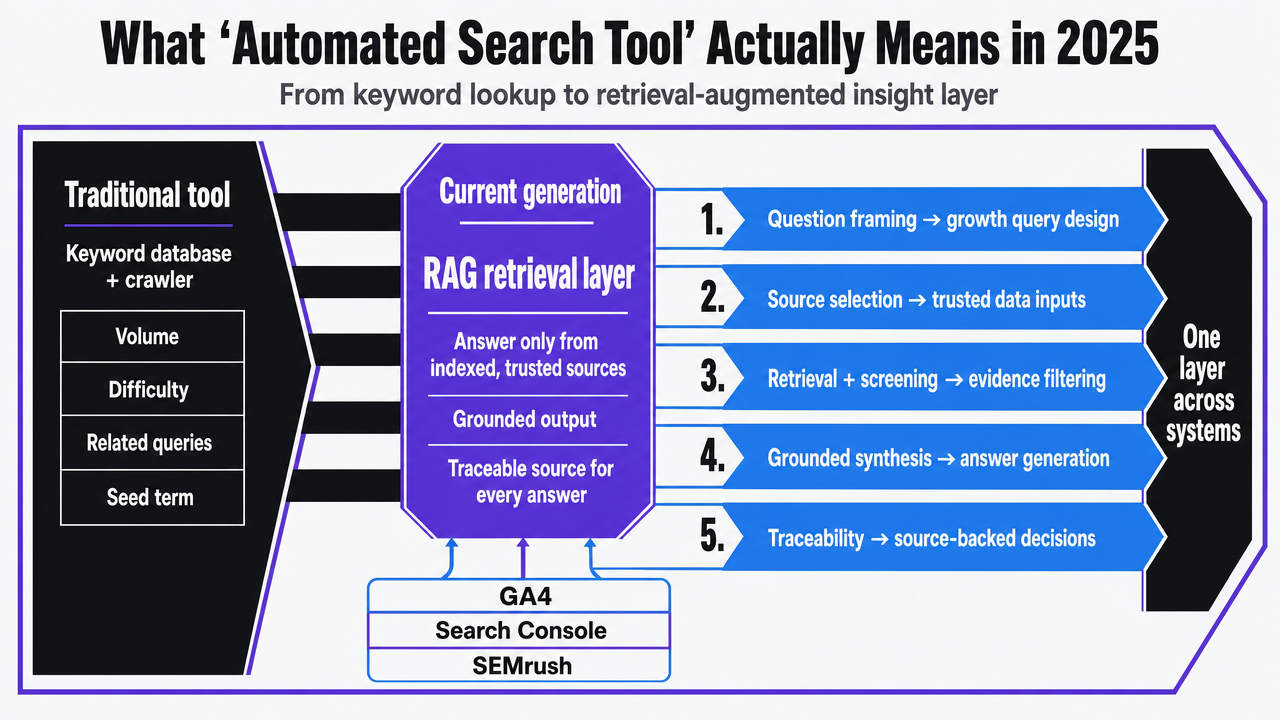
The term "automated search tool" traditionally referred to a keyword database with a crawler, providing volume, difficulty, and related queries for a seed term. This definition is now insufficient. The current generation of tools leverages retrieval-augmented generation (RAG), an architecture where a language model is restricted to answering only from indexed, trusted sources, rather than its own training data. A 2025 review of RAG implementations in healthcare emphasizes its core benefit: grounding model output in a curated retrieval pipeline enhances factual accuracy and provides a traceable source for every answer 5.
For a SaaS growth team, this means that instead of separate queries against GA4, Search Console, and SEMrush, the retrieval layer indexes all these as source documents. A natural-language question, such as "which product pages lost organic share to a specific competitor in the last 60 days," becomes a single retrieval call against a unified index. The model then generates a grounded summary, citing the underlying data rows used.
The same review cautions that RAG systems can inherit biases from their underlying knowledge base and require careful evaluation of retrieval quality, latency, and source coverage 5. This is crucial when a vendor claims "AI search" without demonstrating what is indexed or how recall is measured.
The Five Functions Borrowed From Systematic Review Tooling
The most effective functional taxonomy for an automated search tool originates not from marketing, but from systematic review tooling used by academic researchers for multi-database literature searches (e.g., PubMed, Embase, Cochrane). A 2025 catalog of these tools identifies a stable five-function pattern that closely aligns with the needs of a SaaS growth team across GA4, Search Console, SEMrush, and Google Ads 6.
- The first function is term discovery. Tools like PubReMiner analyze an initial corpus to identify candidate terms a human might not have considered, thereby expanding the query scope 7. In marketing, this translates to mining Search Console and competitor pages for non-obvious query clusters before content creation.
- The second is cross-database query translation. Polyglot Search Translator converts a query from one database's syntax to another's, allowing the same intent to be applied across multiple sources 7. In a growth stack, this automates the manual process of translating a GA4 segment into a Search Console filter and then into a SEMrush keyword group.
- The third is screening: AI-assisted prioritization of records for human review, as seen in Abstrackr and SWIFT-ActiveScreener 6. For marketing, this means triaging which of thousands of ranking keywords warrant a content brief.
- The fourth is prioritization and synthesis, managed by platforms like EPPI-Reviewer, Covidence, and DistillerSR, which consolidate extracted evidence into a unified view 6.
- The fifth is citation recommendation, where tools like LitSuggest and Scite use machine learning to suggest relevant sources a researcher might have missed 7. In growth, this corresponds to recommending the most relevant backlink targets, competitor pages, or internal documents for a given decision.
 Visualize the five functions borrowed from systematic review tooling that map to SaaS growth workflows, directly supporting the section's framework
Visualize the five functions borrowed from systematic review tooling that map to SaaS growth workflows, directly supporting the section's framework
Why SaaS Growth Teams Are the Sharpest Use Case
The Manual Stitching Problem Across GA4, Search Console, SEMrush, and Ads
Consider a typical weekly growth review at a Series B SaaS company. The SEO lead exports Search Console data, filtered by non-brand queries and landing page. The paid lead exports Google Ads search terms, joined with keyword-level CPC and quality score. The content lead pulls SEMrush position tracking for competitors. An analyst then spends significant time normalizing keyword strings—handling singulars/plurals, encoded characters, match-type wrappers, and locale variants—before these files can be joined.
This manual joining process is where significant analytical value is lost. Search Console reports clicks at the query level but truncates the long tail. GA4 attributes sessions at the page level with sampled segments. SEMrush provides third-party rank estimates based on different SERP snapshots. Google Ads reports actual auction performance. Each system uses its own time zone defaults, session definitions, and currency conversion logic for international accounts.
Clinical information retrieval research describes a similar challenge: heterogeneous data sources, inconsistent metadata, and the gap between benchmark recall and real-world utility 9. This translates directly to marketing: the bottleneck in a SaaS growth review is not a missing chart, but the hours analysts spend reconciling identifiers across systems not designed for integration.
Channel Coordination, Not Single-Channel Speed, Is the Real Prize
Many AI search tools are pitched on delivering faster keyword research or competitor analysis. While these offer marginal single-channel speed gains, they do not fundamentally transform a growth team's output.
The true value lies in cross-channel coordination. When an SEO strategist discovers a query cluster losing organic share, the immediate follow-up questions are: Is paid already covering it, and at what CPC? Does the landing page have sufficient backlink authority to recover? Have competitors published fresh content recently? Answering this sequence currently requires four separate queries across four systems and an analyst to merge the results. A retrieval layer indexed against all four systems can provide this chain of answers as a single, grounded output with cited underlying data.
Regarding headcount, a growth team of five to fifteen typically dedicates one to two analysts to reporting and cross-system reconciliation. Reallocating this capacity to strategic decisions rather than data preparation represents a significant operational gain. The 2025 generative AI review of healthcare applications makes a parallel point about administrative automation: the benefit is reducing documentation and retrieval burdens on skilled professionals, allowing them to focus on judgment-intensive work 4. In a SaaS growth organization, judgment-bound work is channel coordination; everything preceding it is overhead.
Accelerate Data-Driven Search Insights Instantly
Experience rapid analysis and publish actionable results using real account data during your full-access trial period.
RAG Architecture, Translated for Marketing Data
Retrieval-augmented generation (RAG) is best understood by explicitly naming its four stages. The healthcare RAG review describes this architecture as an indexed retrieval layer feeding a language model that generates answers grounded in source documents, specifically to mitigate hallucination by linking every output to a traceable record 5. This four-stage process applies directly to a SaaS growth stack, even without the clinical terminology.
- Stage one is the indexed source layer. Instead of PubMed and EHR-linked knowledge bases, this index covers GA4 event tables, Search Console query and page reports, SEMrush position and backlink data, and Google Ads search-term and auction-insight exports. Each record is stored with its native identifiers (e.g., page URL, query string, campaign ID, referring domain) and normalized keys for cross-system joins.
- Stage two is the retrieval call. A natural-language question is converted into a structured query plan that accesses relevant indices, retrieves matching rows, and ranks them by recency and relevance. The healthcare review notes that hybrid dense-sparse indexing and multi-hop retrieval are standard for questions spanning multiple source types 5. In marketing, this handles questions like "non-brand queries with declining clicks and rising paid CPC on pages with no new backlinks in 90 days," requiring three retrievals and one merged result set.
- Stage three is grounded generation. The model synthesizes a summary using only the retrieved rows as context, with each claim linked to its underlying record. This is where the hallucination-mitigation property becomes critical: a grounded answer either has supporting data or it does not, allowing a VP to audit the information chain 5.
- Stage four is human approval. The same review highlights that retrieval bias and source-coverage gaps persist even in well-designed systems, necessitating a human reviewer rather than autonomous publishing 5. For a growth team, this reviewer is the strategist who determines if the retrieved evidence supports a brief, a bid adjustment, or a backlink campaign. The architecture eliminates manual stitching but preserves the need for human judgment.
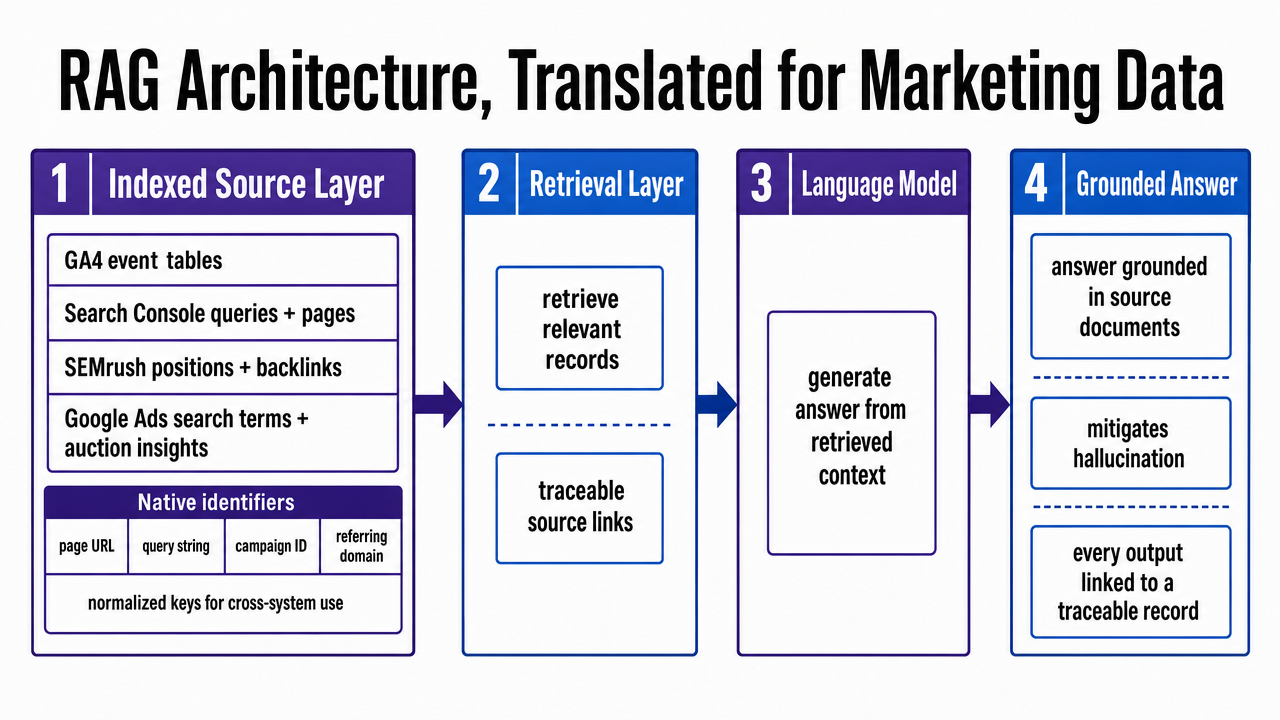 Diagram the four-stage RAG architecture explicitly described in the section, showing how retrieval-augmented generation applies to marketing data sources
Diagram the four-stage RAG architecture explicitly described in the section, showing how retrieval-augmented generation applies to marketing data sources
Manual Analyst Workflow vs. Automated Retrieval Workflow
The most effective way to assess the benefits of a retrieval layer is to compare the cost of answering the same growth question under both manual and automated workflows. McKinsey's analysis of generative AI in consumer marketing states that campaign work, previously requiring months for content design, insight generation, and customer targeting, can now be completed in weeks or days when AI is integrated for personalization and automated testing 8. While this figure applies to enterprise-scale consumer marketing, and cycle compression depends on AI being deeply integrated, the comparison below holds variables steady for a typical SaaS growth team.
| Dimension | Manual Analyst Workflow | Automated Retrieval Workflow |
|---|---|---|
| Time-to-insight on a cross-channel question | 2–3 business days, gated by analyst availability | Same-session, gated by reviewer judgment |
| Query reproducibility | Lives in an analyst's spreadsheet; rarely rerun identically | Stored as a structured retrieval call, rerunnable on demand |
| Source traceability | Implicit in CSV filenames and tab notes | Each claim cited to the underlying record 5 |
| Coordination overhead across SEO, PPC, content | Three system owners, one analyst, one merge step | One retrieval call against a shared index |
| Campaign cycle envelope | Months for full insight-to-launch sequences | Weeks or days at the upper bound of AI integration 8 |
Two important caveats accompany this comparison. First, the cycle-time compression applies only to data preparation and insight generation. Creative review, legal sign-off, and media buying timelines are not shortened by a retrieval layer. Second, the McKinsey figure assumes the AI layer operates on integrated data with a defined approval process; pilots using disconnected exports will not yield the same results 8. For a VP of Marketing, the honest assessment is that the retrieval workflow eliminates a specific type of labor—cross-system stitching—and the cycle-time gain is proportional to how much of this labor currently impedes decision-making.
Evaluating an Automated Search Vendor Without Getting Burned
Benchmark Performance Is Not Workflow Performance
Vendor demonstrations typically showcase benchmark performance: precision and recall on a curated test set, response latency for a clean query, and accuracy on a canned question. These metrics do not predict real-world performance against a live growth stack.
A scoping review of clinical information retrieval explicitly addresses this discrepancy. Many systems perform well on benchmark datasets but behave unpredictably in actual clinical workflows, and external validity remains a persistent evaluation challenge because most studies do not measure impact on real decisions 9. An older tutorial on healthcare IR reaches a similar conclusion, arguing that authoritative source selection and systematic strategy are more critical for reliable output than raw retrieval scores 10.
A VP of Marketing should ask two specific questions during a demo. First, insist on running the demo against the team's actual GA4 and Search Console accounts, not a vendor sandbox, using a question the team manually answered last quarter. Compare the retrieved results to the original spreadsheet. Second, ask the vendor to demonstrate the recall curve for long-tail queries—those truncated by Search Console or thinned out by SEMrush's third-party index. Benchmark accuracy on head terms is expected; workflow accuracy on questions that drive actual briefs and bid changes is the only metric worth negotiating.
Post-Deployment Drift, Source Traceability, and Bias
A retrieval layer is not static. The underlying language model is updated, index schemas change with new fields from GA4 or Search Console, and source data drifts as teams add properties or migrate ad accounts. The Duke Margolis report on AI-enabled decision tools frames this as a post-market surveillance issue: dynamic model updates and performance drift mean evaluation must continue after deployment, requiring adaptive monitoring frameworks to track safety and effectiveness as the tool evolves 3.
For marketing, this translates into three critical contract terms:
- First, demand source traceability for every output—each generated claim linked to its underlying record, with the retrieval call logged and rerunnable. The healthcare RAG review identifies traceability as the foundational property distinguishing grounded systems from hallucinating ones, noting that retrieval bias persists when source coverage is uneven 5.
- Second, require drift monitoring: scheduled re-evaluation of retrieval quality against a held-out set of questions controlled by the team, not the vendor.
- Third, insist on index transparency—a clear inventory of what is indexed, what is excluded, and when each source was last refreshed.
The AI-CDSS literature adds a fourth concern: algorithmic bias and the risk of overreliance leading to deskilling of human users 1. A growth team that stops scrutinizing retrieval output due to speed gains has not achieved efficiency, but rather a faster path to error.
Dashboard Fatigue Is the New Alert Fatigue
AHRQ identifies alert fatigue as a critical failure mode in clinical decision support: excessive, poorly integrated notifications cause clinicians to dismiss them, sometimes missing crucial alerts 2. Marketing teams face a similar issue. The average VP of Marketing already receives daily anomaly alerts from GA4, weekly position-change emails from SEMrush, real-time bid alerts from Google Ads, and Slack notifications from Looker.
An automated search tool that merely adds another alert stream exacerbates this problem. The key evaluation question is whether the tool reduces the number of standing dashboards the team consults, or simply adds another. A retrieval layer proves its worth when the team can retire two or three scheduled reports within its first quarter because the information they provided is now available on demand. If the tool introduces its own default alerts that cannot be disabled or routed through existing channels, it demonstrates the same workflow-fit failure described by AHRQ, merely in a marketing context 2.
Accelerate Data-Driven Search Insights with Automated Analysis
Discover how leading agencies and enterprise teams reduce manual analysis time by 60% using unified automated search tools to coordinate SEO, PPC, and backlink strategies for measurable acquisition gains.
If You Run a Portfolio: Cross-Brand Retrieval for Multi-Product SaaS
This section is for VPs of Marketing managing a portfolio of two or more SaaS products under one company, or a parent brand with acquired sub-brands sharing an analytics infrastructure. Single-product teams can skip ahead.
Portfolio operators encounter a specific version of the data stitching problem. Each product typically has its own GA4 property, Search Console domain, SEMrush project, and often its own Google Ads account within a manager hierarchy. Cross-brand questions crucial for portfolio strategy—such as which product is cannibalizing another's branded queries, where paid bids compete internally, or which backlink targets serve multiple properties—cannot be answered within a single property's interface.
A retrieval layer indexed across all properties transforms the unit of analysis. The same grounded-generation pattern that mitigates hallucination in a single-product stack also works at the portfolio level when the index treats brand as a dimension rather than a partition 5. The practical test for a vendor is whether retrieval can return a result set spanning three GA4 properties and two ad accounts in a single call, with brand-level traceability for each cited row. If the demo requires running the same question multiple times and merging the output, the tool has not solved the portfolio problem; it has merely shifted the stitching burden from the analyst to the operator.
A 90-Day Path to a Working Retrieval Layer
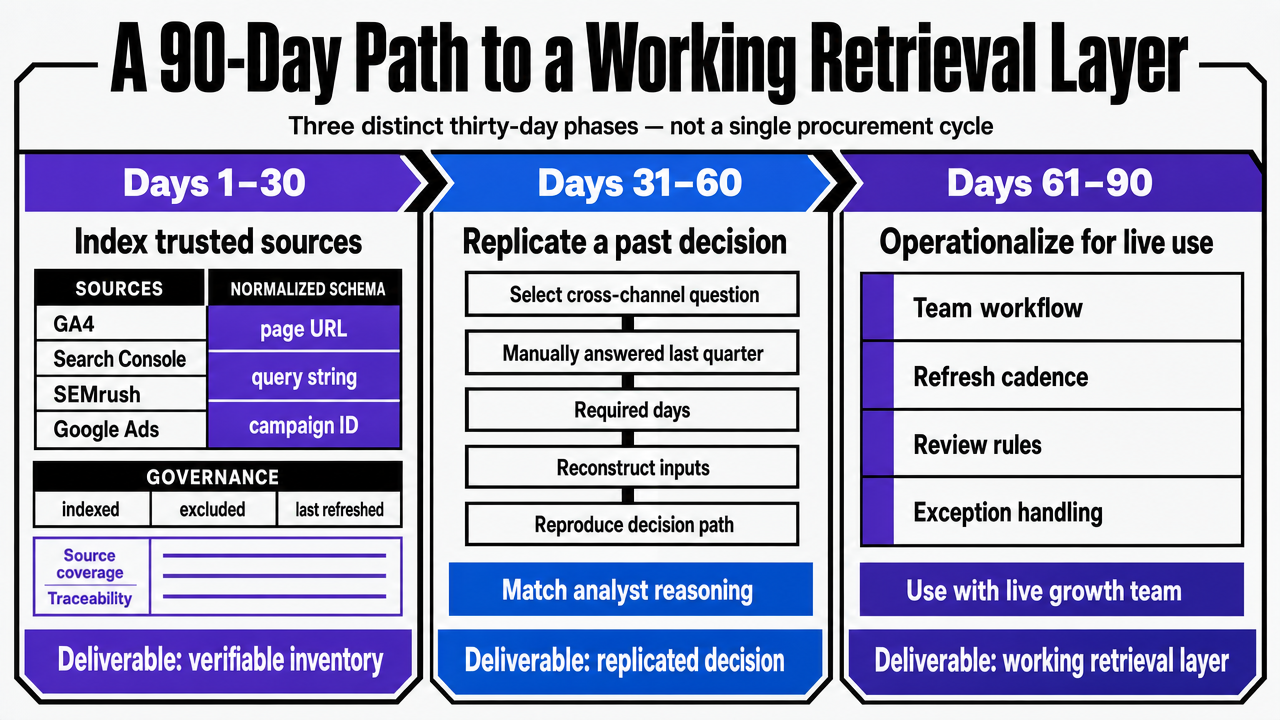
A retrieval layer that successfully integrates with a live growth team is built in three distinct thirty-day phases, not within a single procurement cycle.
- Days 1–30: Index trusted sources. Connect GA4, Search Console, SEMrush, and Google Ads at the account level, establishing a normalized key schema for page URL, query string, and campaign ID. Reject any vendor architecture that cannot clearly show what is indexed, what is excluded, and when each source was last refreshed. The healthcare RAG review emphasizes source coverage and traceability as foundational properties for any grounded system, and the same standard applies here 5. The deliverable by day 30 is a verifiable inventory, not an answer.
- Days 31–60: Replicate a past decision. Select a cross-channel question that the analyst team manually answered last quarter—one that required days and multiple CSVs—and run it through the retrieval layer using the same data window. Compare the cited rows to the original spreadsheet. Clinical IR research is clear: benchmark accuracy does not predict workflow performance, and external validity must be measured against actual organizational decisions 9. If the retrieved output misses long-tail queries that the analyst manually identified, this indicates a point for negotiation, not immediate rollout.
- Days 61–90: Retire two standing reports. The effectiveness of a retrieval layer is measured by what it eliminates. By day 90, the team should have decommissioned at least two scheduled dashboards or recurring exports because the questions they addressed are now available on demand. If Slack alert volume has increased rather than decreased, the workflow-fit failure identified by AHRQ in clinical decision support has reappeared in marketing 2. Platforms like Vectoron are designed to coordinate this retrieval-to-execution loop across SEO, PPC, content, and backlinks under a unified approval surface, but the 90-day discipline is crucial regardless of the vendor.
 Visualize the three 30-day implementation phases explicitly outlined in the section as an operating plan
Visualize the three 30-day implementation phases explicitly outlined in the section as an operating plan
Frequently Asked Questions
References
- 1.AI-Driven Clinical Decision Support Systems: An Ongoing Pursuit of AI-Driven Clinical Decision Support Systems to Improve Healthcare Delivery.
- 2.Clinical Decision Support.
- 3.Evaluating AI-Enabled Clinical Decision and Diagnostic Support Tools Using Real-World Data.
- 4.Generative Artificial Intelligence Use in Healthcare.
- 5.Retrieval augmented generation for large language models in healthcare: A comprehensive review.
- 6.Digital Tools to Support the Systematic Review Process.
- 7.AI Resources for Systematic Reviews.
- 8.How generative AI can boost consumer marketing.
- 9.Clinical Information Retrieval: A Literature Review.
- 10.Information Retrieval for Healthcare.