Key Takeaways
- A content automation wiki works as production infrastructure when it borrows the CDS three-layer model: a structured knowledge base, an inference engine, and a communication mechanism that moves drafts to publish 2.
- Every entry needs six discrete fields—audience profile, voice tokens, evidence library, template schema, validation checklist, and retirement trigger—plus provenance tags that make AI-assisted output auditable 9.
- Lifecycle governance has to be planned before the first entry ships, with named owners, batched human review gates, and explicit retirement triggers, since outdated knowledge degrades downstream output 1.
- Adoption hinges on fit with existing workflow and visible value; entries that surface inside brief generators and prompts get used, while parallel reference shelves get bypassed within a quarter 4.
Why Tribal Knowledge Breaks SaaS Content Teams
Most SaaS content teams run on memory. A senior writer knows which competitor pages to benchmark against, which voice quirks the brand avoids, and which evidence sources the editor will accept. None of it is written down in a form an AI assistant or new contractor can use on day one. When that writer leaves, the team rebuilds the rules from scratch—usually by re-reviewing six months of published articles and guessing.
The symptom shows up in production data. Briefs take longer to write than the articles themselves. Contractor drafts come back off-brand. AI prompts produce passable copy that still needs a full editorial rewrite. Each output requires the same human translation layer because the team's operating knowledge lives in heads, Slack threads, and one-off Loom recordings.
Research on workflow automation in adjacent knowledge-heavy fields makes the cost concrete: unstructured documentation creates administrative drag and reproduces the same decisions across every new task, blocking the throughput gains automation is supposed to deliver 6. The fix is not more documentation. It is documentation in a format machines and humans can both consume.
That is the gap a content automation wiki fills. Not a Notion folder of style guides and SOPs—a structured knowledge layer that stores templates, voice rules, evidence libraries, and validation checks in fields that AI systems can read directly. The teams scaling content output past their headcount treat the wiki as production infrastructure, not reference material.
Borrowing the CDS Blueprint for Content Operations
The Three-Component Architecture
Clinical decision support systems solve a problem that looks structurally identical to the one SaaS content teams face: how to take expert knowledge, encode it in a format machines can act on, and deliver the right output at the right decision point. The peer-reviewed literature describes CDS as built on three components—a knowledge base, an inference engine, and a communication mechanism 2. That trio maps cleanly onto content operations once the labels are translated.
The knowledge base in a CDS holds curated, evidence-graded rules and reference data. In a content automation wiki, the equivalent is the structured asset layer: brief templates, voice token libraries, audience profiles, approved evidence sources, competitor benchmarks, and validation checklists. Each artifact is stored as discrete fields, not buried in prose. The inference engine in a CDS applies logic to that knowledge to produce a recommendation. In content operations, the inference layer is the AI system—LLMs, prompt chains, or agentic workflows—that reads the structured wiki fields and assembles a draft. The communication mechanism in a CDS delivers the recommendation to the clinician through an EHR alert, order set, or summary view. In content production, the communication layer is the CMS, the editorial review queue, and the publishing pipeline that moves a draft through human approval into a live page.
What makes the analogy useful is the discipline it enforces. CDS designers do not store knowledge as freeform notes. They store it in structures the inference engine can parse, because anything else breaks the chain 2. Content teams running AI-assisted production face the same constraint. An LLM prompted with a vague style guide produces vague output. The same model prompted with discrete fields—target audience descriptor, banned phrases, evidence requirements, section schema—produces predictable output that needs less editorial rework.
The three layers also define ownership. The knowledge base is owned by editorial leads and subject experts who curate and approve assets. The inference layer is owned by whoever manages the AI tooling and prompt architecture. The communication layer is owned by production and publishing. Roles map to layers, and accountability stops leaking across the team.
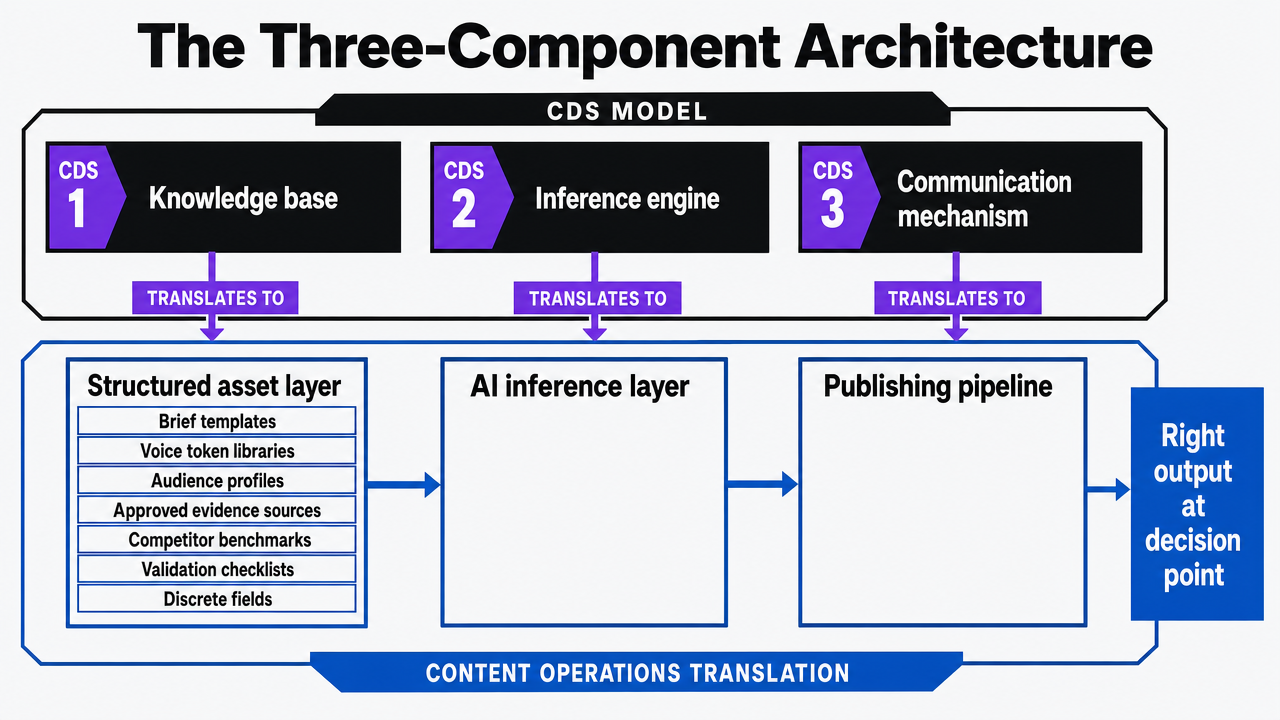 Visualize the CDS-to-content-operations mapping described in the section: knowledge base, inference engine, and communication mechanism translated into structured assets, AI inference layer, and publishing pipeline
Visualize the CDS-to-content-operations mapping described in the section: knowledge base, inference engine, and communication mechanism translated into structured assets, AI inference layer, and publishing pipeline
Structured Entries Beat Freeform Documentation
The case for structure is not aesthetic. It is measurable in how AI systems perform against the inputs they receive. A 2024 review of AI tools for clinical documentation found that 68% of the studies it analyzed focused on data structuring algorithms—the work of converting unstructured text into discrete, labeled fields that downstream systems can process 5. That figure is scoped to clinical documentation research, not marketing tooling, but the underlying principle generalizes: the dominant lever for improving AI output quality in knowledge-intensive workflows is structuring the inputs, not adding more of them.
Content teams routinely make the opposite bet. They write longer style guides, attach more example articles, and append more context to prompts, expecting volume to compensate for ambiguity. The result is documentation that humans skim and AI systems average across. A 4,000-word brand voice document produces less consistent output than a 200-field structured entry that specifies, in discrete slots, what the audience reads, which phrases to avoid, which evidence sources are approved, and what the validation checklist looks like.
The knowledge management literature on CDS makes the same point in a different register: knowledge has to be written, stored, and transmitted in a format that is easy to build and deploy 11. Easy to deploy means parseable. It means an AI agent can read field 12 and know exactly what voice token applies to the introduction, rather than inferring tone from a paragraph of adjectives.
There is a tradeoff worth naming. Structured entries take longer to author than freeform docs. The first version of a wiki schema feels heavier than the Notion page it replaces. The payoff arrives on the second, fifth, and fiftieth article that consumes the same structured entry—each one skipping the translation work that freeform documentation forces a human to redo every time. Teams that measure brief-to-draft time and contractor onboarding hours see the curve cross within the first quarter of disciplined entry authoring.
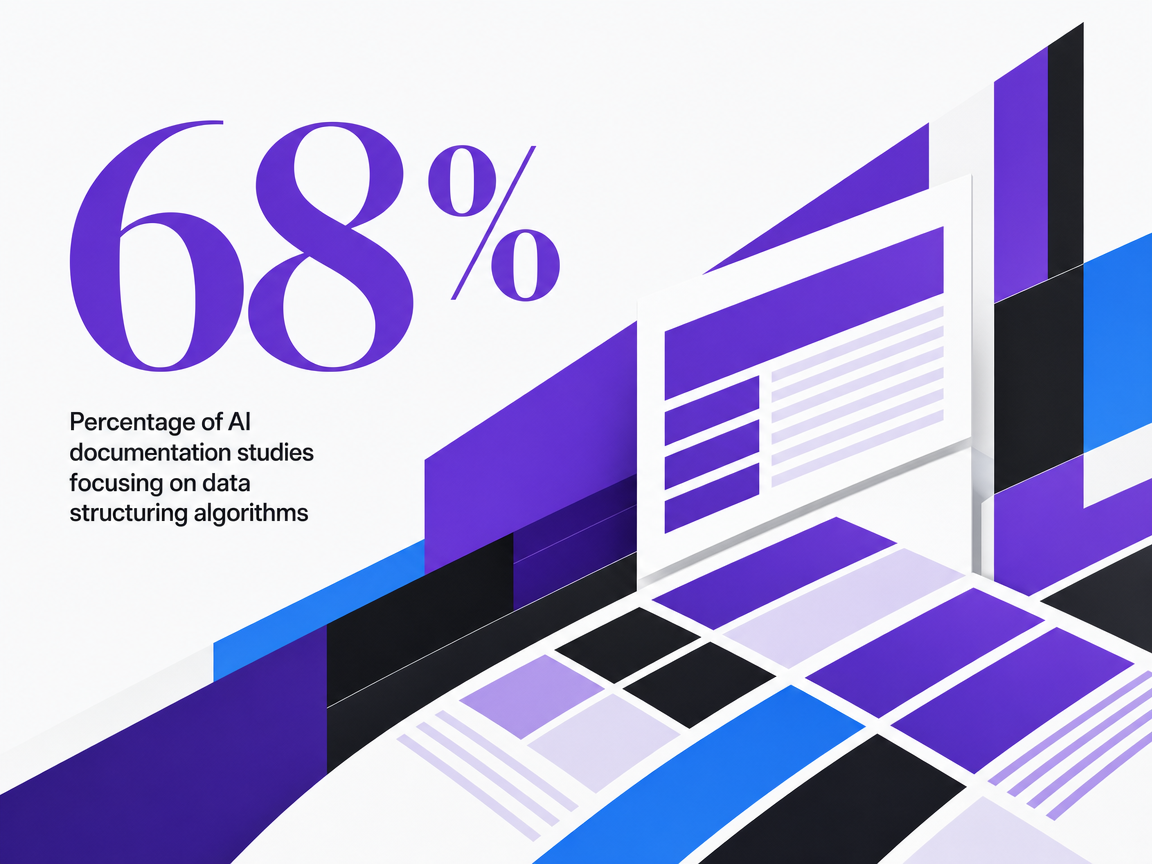 Percentage of AI documentation studies focusing on data structuring algorithms
Percentage of AI documentation studies focusing on data structuring algorithms
Percentage of AI documentation studies focusing on data structuring algorithms
The Anatomy of a Wiki Entry That Feeds Automation
Required Fields for Every Entry
A wiki entry built to feed automation is not a page. It is a record with required fields, each populated before the entry is published to the production system. Six fields cover the working minimum for a SaaS content team running AI-assisted production.
The audience profile field defines the reader in operational terms: job title, team size, what they already know, what decision they are trying to make, and which competing solutions they have likely evaluated. Vague descriptors like "marketing professionals" fail the parseability test. "Content marketing manager at a Series B SaaS company running a team of three to seven" gives the inference layer something to anchor on.
The voice tokens field stores discrete rules: banned phrases, preferred sentence structures, perspective (first, second, third), formality level, and energy. Tokens are listed, not described. A list of twelve banned phrases produces more consistent output than a paragraph about "avoiding marketing jargon."
The evidence library field lists approved sources, acceptable source types, citation format, and any sources that are explicitly off-limits. The template field holds the section schema for the article type—introduction structure, required H2s, expected length per section, and required artifacts like comparison tables or schema markup. The validation checklist field captures every check the draft must pass before publishing: factual accuracy, citation format, voice token compliance, internal link coverage, and SEO requirements. The retirement trigger field names the condition that retires the entry: a competitor launch, an algorithm update, a quarterly review date, or a measurable performance drop.
Compared with an unstructured doc that buries all six in prose, the structured entry lets an AI agent read field five and execute the validation checklist as a deterministic step rather than inferring quality criteria from adjectives. That parseability is the entire point of the format 11.
 Visualize the six required fields described in the section as a structured schema, supporting the article's framework for wiki entries
Visualize the six required fields described in the section as a structured schema, supporting the article's framework for wiki entries
Machine-Readable Formats and Provenance Tags
Fields are necessary but not sufficient. The format the fields live in determines whether the inference layer can actually consume them. YAML front matter, JSON schemas, or database records with typed columns all work. A heading-and-paragraph Notion page does not, because the AI agent has to re-parse the structure on every read and guesses where one field ends and the next begins.
The practical move is to pick one format per entry type and enforce it. A product comparison article entry, a how-to article entry, and a thought leadership article entry can have different schemas, but every instance of a product comparison entry uses the same field names, types, and order. Order matters because prompt chains that read field three expect field three to contain the same thing every time.
Provenance tagging is the second layer. Each entry needs metadata about its origin and trust state: who authored it, when it was last validated, which AI model touched it, whether the draft was human-reviewed before publication, and which source documents informed it. NIST guidance on synthetic content recommends tracking provenance, labeling AI-generated material, and maintaining audit trails so downstream consumers can evaluate trust 9. The same logic applies inside a content wiki: an entry validated by a senior editor in March carries different weight than one drafted by an LLM and never reviewed.
Provenance tags also unlock audit when something breaks. If an article underperforms or a factual error ships, the tags trace the failure back to the specific entry version, the model that consumed it, and the reviewer who approved it. Without that trail, root cause analysis collapses into guessing.
Test Content Automation Workflows With Live Publishing
Experiment with automated content production and publish wiki articles directly to your team’s workspace during your trial.
Lifecycle Governance: Create, Validate, Deploy, Retire
Planning Knowledge Management Before the First Entry
The most common failure mode for content wikis is not bad entries. It is the absence of a plan for who owns the entries after they ship. Best Practice 5 in the clinical decision support literature states the rule directly: knowledge management processes must be planned early, with explicit responsibilities for maintaining and updating knowledge assets, or the system drifts into obsolescence within a single operating cycle 1. The same study notes that organizations without that planning end up with outdated or misaligned assets that quietly degrade the workflows depending on them 1.
For a content team, planning early means answering four questions before authoring entry one:
- Who owns each entry type—product comparison templates, voice tokens, evidence libraries?
- What cadence triggers a review—quarterly, after every algorithm update, or against a performance threshold?
- What evidence is required to validate a new entry before it enters the production system?
- What is the explicit handoff when an owner leaves the team?
Naming the owner matters more than naming the cadence. An entry with a quarterly review date and no assigned reviewer becomes an entry that never gets reviewed. Production leads who treat ownership as a field in the entry itself—same parseability discipline as audience profile or voice tokens—keep governance from collapsing into a calendar reminder no one reads.
Human-in-the-Loop Review and AI Approval Gates
AI drafts entering the wiki need approval gates, not because models hallucinate occasionally but because unreviewed AI output compounds. An entry written by a model, never validated, then consumed by the inference layer to produce dozens of articles, propagates whatever error it contained across every downstream draft. The NIST AI Risk Management Framework names this pattern directly: trustworthy AI use depends on incorporating accountability and oversight into design, development, and ongoing evaluation, not just at the moment of deployment 8.
A workable gate structure has three checkpoints:
- Draft entries created by AI are tagged as unvalidated and held out of the inference layer until a human reviewer with subject authority signs off.
- The reviewer's approval is recorded as a provenance field on the entry—name, date, model used to draft, sources consulted—matching the provenance practices NIST recommends for synthetic content 9.
- Any material edit to an approved entry resets it to unvalidated until re-approved.
The gate has to fit the production rhythm, not block it. CDS research on workflow integration warns that controls bolted onto an existing flow without fit create either workarounds or abandonment 3. The practical pattern is to batch reviews—a senior editor reviews new and updated entries in a fixed weekly window rather than approving each one as it lands. That batching keeps throughput stable while preserving the audit trail that makes failures traceable later.
Retirement Triggers and Versioning
Entries decay. A product comparison template written in Q1 against three competitors goes stale when a fourth competitor launches in Q3. A voice token list calibrated for a Series A audience misfits a Series C reader profile. Without retirement triggers, the wiki accumulates entries that look authoritative but quietly produce off-target drafts.
Retirement should be a field, not a judgment call. Each entry carries an explicit condition: a date, an event, a performance threshold, or a dependency on another entry. When the condition fires, the entry moves to a retired state—still readable for audit purposes, removed from the inference layer's working set. The CDS literature makes this lifecycle explicit because outdated knowledge in a decision support system produces worse outcomes than no knowledge at all 1.
Versioning runs alongside retirement. When an entry is updated rather than retired, the previous version is preserved with its provenance intact, and the new version inherits a fresh validation requirement. That history matters when an article underperforms and the team needs to know which version of which entry produced it. Without versioning, root cause analysis stops at the article level and never reaches the input that actually drove the output.
Throughput Math: Unstructured Docs vs. Structured Entries
The case for structured entries has to survive a basic question: does the format actually move production numbers? The answer lives in three variables every SaaS content lead already tracks—briefs per week, hours per brief, and contractor onboarding hours.
Consider a team shipping six briefs per week. With unstructured documentation, a brief typically pulls from a style guide, two or three example articles, a competitor scan, and whatever the editor remembers about the audience. Each brief restarts that synthesis. The work compounds: six briefs times the per-brief translation tax, every week, with no decay in the per-unit cost as volume grows.
Structured entries change the slope. The first brief against a new article-type entry costs more, because the entry itself has to be authored against the schema. Every brief after that reads the same fields, and the inference layer assembles the draft without re-deriving audience, voice, or evidence rules. The per-brief hour count drops, and the drop holds across volume.
Contractor onboarding shows the same shape. Unstructured docs require a new contractor to read, infer, and ask. Structured entries hand the contractor a parseable record—audience profile in field one, voice tokens in field two, validation checklist in field five. Onboarding shifts from interpretive reading to schema review.
The research on AI-assisted documentation supports the direction: structuring inputs is the dominant lever for output quality in knowledge-intensive workflows 5. The throughput gain is not theoretical. It is the same brief, authored once, consumed many times.
Systematize Your Content Automation Wiki with Proven, Scalable Workflows
Connect with specialists to see how enterprise teams document, operationalize, and govern automated content processes—ensuring every article moves from research to publish without workflow gaps or production delays.
Adoption: Why Wikis Get Built and Then Ignored
A wiki that no one uses is a more expensive failure than no wiki at all. Research on clinical decision support adoption found that familiarity and perceived usefulness drive whether practitioners actually engage with the system—gaps in either dimension produce underutilization even when the underlying tools are sound 7. Content teams hit the same wall. Writers and contractors default to old habits when the wiki feels heavier than the workaround.
Three failure patterns recur:
- Friction at the point of use. If a writer has to open five tabs to consume a single entry, the entry loses to a Slack DM asking the editor directly. Entries have to surface inside the tools the team already works in—brief generators, AI prompts, CMS templates—not as a separate destination.
- Invisible value. Contributors who do not see the entry feeding downstream output treat it as paperwork. Production leads who publish before-and-after metrics—brief hours dropped, contractor ramp time cut, revision rounds reduced—turn the wiki from overhead into evidence.
- Misfit with workflow. AHRQ guidance on decision support adoption stresses that systems must be designed around the user's real decision points, not bolted on as a parallel process 4. A wiki schema that ignores how briefs actually get authored will be bypassed within a quarter. Production leads who interview writers before locking the schema, then adjust field structure to match how the team already thinks, get adoption that holds.
The Operating Layer, Not the Reference Shelf
A content automation wiki earns its keep when it sits inside the production pipeline, not next to it. The reference-shelf version—pages a writer might open before drafting—produces marginal gains at best. The operating-layer version is read by the inference engine on every job, enforces validation as a deterministic step, and carries provenance tags that make every output auditable 9. The shift is from a place teams look things up to a system that supplies the rules production runs on.
The practical test is whether the wiki has consumers downstream. If only humans read it, it is documentation. If AI agents, brief generators, and validation scripts read it, it is infrastructure. Production leads building toward the second state design entries as records with typed fields, assign owners as data, and treat retirement as a state transition rather than a cleanup task 1.
The teams pulling this off ship more articles per writer-hour and onboard contractors in days, not weeks. Platforms like Vectoron are built around exactly this premise—structured knowledge feeding continuous production—rather than retrofitting it onto a documentation tool.
Frequently Asked Questions
References
- 1.Identifying Best Practices for Clinical Decision Support and Knowledge Management in the Field.
- 2.Physician Knowledge Base: Clinical Decision Support Systems.
- 3.Clinical Decision Support.
- 4.Clinical Decision Support.
- 5.Improving Clinical Documentation with Artificial Intelligence.
- 6.A priority to accelerate workflow automation in health care.
- 7.Health Care Professionals’ Knowledge and Practices Regarding Clinical Decision Support Systems.
- 8.AI Risk Management Framework | NIST.
- 9.Reducing Risks Posed by Synthetic Content.
- 10.NIST AI Public Working Groups - AIRC.
- 11.Clinical Decision Support Systems - NCBI Bookshelf.