Key Takeaways
- Most SEO readouts report association, not evidence; only a comparable control cohort running in the same window estimates the counterfactual that before-and-after comparisons miss 4.
- Template-driven sites and multi-location portfolios violate independence by default, so cluster-randomized assignment and AIPW-style adjustments are required to keep treated and control pages from cannibalizing each other 3.
- Interleaving compresses readout times on low-traffic pages by attributing clicks at the query-page-pair grain, making it the default instrument for snippet- and schema-level tests once validated on historical data 1.
- Scaling concurrency depends on layered assignment, locked stopping rules, deterministic logging, and guardrails — without that orchestration, overlapping tests fragment traffic and produce correlated readouts that look significant for the wrong reason 11.
Why most SEO 'tests' are association dressed as evidence
The standard SEO workflow looks like a test but rarely behaves like one. A new title pattern ships to 200 service pages on a Tuesday. Two weeks later, clicks are up 11%. Someone declares the title pattern a winner, the change rolls out to the rest of the portfolio, and the case study writes itself. What just happened is association, not evidence. There was no counterfactual, no comparable control group, and no accounting for what else moved in those two weeks — a competitor's outage, a seasonal query shift, an algorithm refresh, or a SERP layout change that reshuffled organic real estate beneath the experiment.
Causal inference exists precisely because this gap is everywhere in business measurement. The discipline's central move is to compare what happened against a credible estimate of what would have happened without the change, and that estimate almost always requires a control group rather than a calendar 4. The peer-reviewed literature on causal reasoning frames this as a shift away from association-based thinking, which is what most SEO readouts still rely on 6.
Controls are not statistical theater. They are the only mechanism that filters out the biases — confirmation, recency, narrative pressure from a client review — that contaminate before-and-after readings 7. An agency that ships changes and watches dashboards is producing stories. An agency that runs SEO testing automation as a disciplined experimentation program is producing evidence its clients can defend.
The methodological spine: controlled experimentation, ported to organic search
Counterfactuals over before-and-after
The fundamental problem of causal inference is that only one potential outcome is observed for each unit 5. A page either got the new schema or it didn't. The version of reality where that same page kept the old markup, under the same week's algorithm state and the same query mix, is not available for inspection. Every honest readout in SEO is an estimate of that missing outcome.
Before-and-after comparisons substitute time for a counterfactual and pay for it with confounding. A control group, by contrast, gives the test owner an unbiased estimate of what the treated pages would have done absent the change 4. The control group is the counterfactual, holding constant everything the analyst cannot see — crawl budget shifts, competitor moves, intent drift on the head terms.
This reframes the question an SEO lead asks at readout. The right question is not "did clicks go up after we shipped?" but "did the treated cohort diverge from a comparable untreated cohort during the same window, by more than chance would explain?" That is the only question controlled experimentation answers, and it is the only answer that holds up under client scrutiny when a quarterly review goes sideways.
A/A validation, guardrail metrics, and the discipline of not peeking
Before any experimentation pipeline produces a readout worth defending, it has to prove it can detect nothing when nothing is there. That is what A/A testing is for. Two identical variants are randomly assigned to two cohorts, the system runs the same statistical machinery it would for a real test, and the result should come back non-significant. The Kohavi practical guide sets the operational benchmark plainly: a correctly configured platform should return non-significant results in roughly 95% of A/A runs 10. Anything materially below that is a sign of a leaky randomization, a contaminated traffic source, or a metric pipeline that is double-counting events.
Guardrail metrics sit alongside the primary KPI to catch the second failure mode — winning on the headline number while quietly damaging something downstream. For SEO, guardrails typically include indexation rate on the treated URLs, crawl error frequency, Core Web Vitals on the affected templates, and on-site engagement metrics that signal whether the click was useful. A title-tag test that lifts CTR but tanks scroll depth and assisted conversions is not a win, and the readout has to surface that before rollout.
The third discipline is structural: do not peek. Repeated significance checks during a running experiment inflate false-positive rates and reward whoever calls the readout earliest 10. The countermeasure is to fix the test duration in advance based on a power calculation, lock the stopping rule into the orchestration layer, and let the system suppress interim results from human dashboards until the window closes. Automation is what makes that rule survive contact with a client who wants the answer on day four.
Treatment units for SEO: page, template, cluster, or location
Choice of treatment unit is where most SEO experiments are won or lost on the whiteboard, before a line of code ships. The unit determines what "one observation" means, how many independent observations the test has, and whether the statistical machinery downstream is solving the right problem.
Four units cover most agency work:
- Page-level assignment treats each URL as an independent unit and works for tests on large content libraries where pages compete for distinct query sets.
- Template-level assignment treats the template as the unit and rolls the change across every page that inherits it — appropriate for schema, internal-link patterns, or layout changes where applying the variant to half the pages would create visual inconsistencies a crawler interprets as quality noise.
- Cluster-level assignment groups topically related pages and randomizes by cluster, which reduces interference when treated and control pages would otherwise compete for the same head terms.
- Location-level assignment, common in multi-location healthcare portfolios, treats each location's full page set as the unit — useful when the hypothesis is about a market-level signal rather than a page-level one.
The trade-off is power. Coarser units mean fewer independent observations, which means longer tests or larger effect sizes required for significance. The right unit is the smallest one that does not violate independence for the specific change being tested.
Interference is the central problem, not a footnote
Why template-driven and multi-location sites violate iid by default
Classical experimentation assumes the units in a test are independent and identically distributed. SEO portfolios rarely satisfy that assumption for more than a handful of pages at a time. The moment a template-level change ships to half of a site's service pages, the treated pages start competing with the control pages for the same head queries, the same featured snippet slot, and the same crawl budget. The treatment leaks into the control by construction.
Multi-location healthcare portfolios make this worse. A 40-location dermatology group testing a new schema pattern on half its location pages does not have 20 independent treated units and 20 independent control units. It has 40 pages bidding against each other in overlapping metro SERPs, with shared brand authority, shared internal linking, and shared canonical signals. When the treated locations win, part of what they win is taken from the control locations sitting one rank below them on the same query.
This is not a hypothetical concern. SEO interventions materially reshape what users see in search results, which means treated and untreated pages are operating inside the same finite attention pool 8. Ignoring that interaction does not make the bias go away. It buries the bias inside the readout and inflates the apparent lift of whatever shipped.
Interference-aware designs and AIPW-style adjustments
The fix starts at the design stage, not the analysis stage. Cluster-randomized assignment groups pages that are likely to interfere — pages targeting overlapping query sets, pages within the same metro, pages sharing a canonical parent — and randomizes the cluster rather than the page. The cluster becomes the independent unit, which restores the iid assumption at a coarser grain and trades statistical power for unbiased estimates. Recent methodological work has produced practical tools for detecting spillovers directly inside randomized trials, giving test owners a way to verify whether interference is actually contaminating a specific design rather than assuming the worst case 2.
When clean separation is impossible, the analysis layer has to carry the load. The most rigorous treatment in adjacent literature comes from sponsored search, where ads on the same results page interfere with each other and violate iid in exactly the way SEO pages do on a single SERP. Researchers working on Bing Ads formalized direct, homophily, and allocational interference and used augmented inverse probability weighting to recover unbiased effects. Modeling interference changed the performance of click-prediction models inside live experiments, meaning the unadjusted readouts were measurably wrong 3. The scope is sponsored search, not organic, but the structural problem — competing units on a shared surface — transfers cleanly.
For an SEO experimentation pipeline, the operational takeaway is concrete: classify every proposed test by its interference risk before assignment, default to cluster randomization for template and location tests, and reserve AIPW-style adjustments for cases where the design cannot eliminate spillover and the effect size matters enough to warrant the additional modeling.
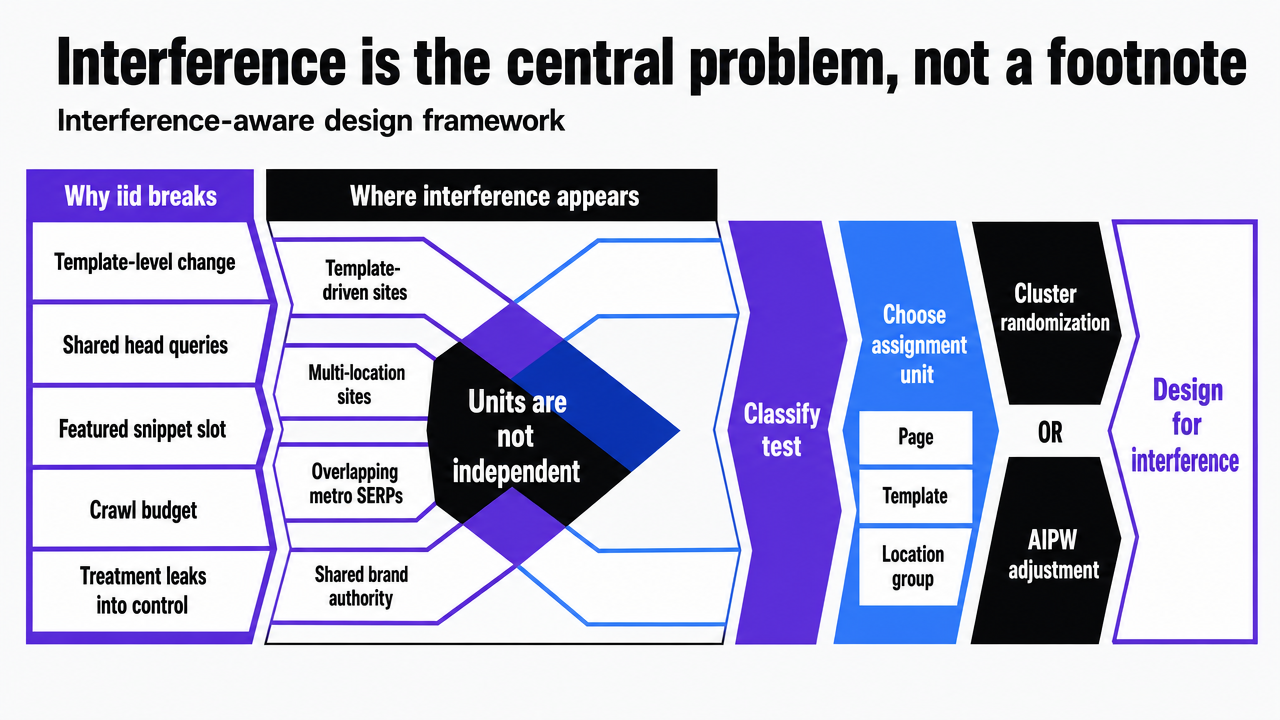 Visualize the interference-aware design framework that the section explains: classify test, choose assignment unit, apply cluster randomization or AIPW adjustment. This is a process/framework the article walks through in prose
Visualize the interference-aware design framework that the section explains: classify test, choose assignment unit, apply cluster randomization or AIPW adjustment. This is a process/framework the article walks through in prose
Run Live Automated SEO Tests Instantly
Validate SEO experimentation workflows and measure impact in your own production environment, risk-free for seven days.
Interleaving: a sharper instrument for ranking-impacting changes
Standard split tests struggle with ranking changes for a simple reason: most SEO experiments live on pages that do not receive enough traffic to power a clean readout in a reasonable window. A snippet test on a service page that gets 80 impressions a day will need months to detect anything short of a double-digit lift. By the time the readout arrives, the SERP has moved, the query mix has drifted, and the original hypothesis is stale.
Interleaving sidesteps the traffic problem by changing what gets compared. Instead of assigning some users to ranking function A and other users to ranking function B and waiting for two populations to diverge, interleaving merges the two ranked lists into a single results page and attributes clicks back to whichever underlying ranker contributed each shown result. Every impression contributes evidence about both variants at once, which is why the method is more sensitive than parallel A/B tests for ranking comparisons and detects preferences with fewer impressions than the standard design 1.
For SEO, the practical analog applies to any change that alters which result a user picks from a SERP the agency does not control directly: title rewrites, meta description variants, FAQ schema, review snippets, image thumbnails on shopping or local results. The agency cannot interleave inside Google's ranker, but it can construct paired tests at the URL level where two variants compete for the same query cluster across a matched set of pages, then attribute click outcomes from Search Console at the query-page pair grain. The unit of evidence becomes the query, not the user session, which compresses readout times on low-volume pages.
The literature also warns that not all interleaving variants are equally trustworthy. Some algorithms introduce bias toward one ranker or the other, and the choice of attribution rule shapes the result 1. The operational consequence for an SEO testing pipeline is that the interleaving method has to be validated on historical data before it goes into production, the same way an A/B platform earns trust through A/A runs. Once validated, interleaving belongs in the toolkit as the default instrument for snippet- and schema-level tests on pages where waiting six weeks for a split-test readout is not an option.
Automating the pipeline: hypothesis to rollout without combinatorial overhead
Concurrent experiments and the fragmentation tax
An agency running a single SEO test at a time will never produce the volume of validated learnings a portfolio of clients demands. The math forces concurrency. A pod managing 20 healthcare accounts with even a modest cadence of three tests per account per quarter is looking at 60 simultaneous experiments at any given moment, and that is before factoring in the holdout cohorts each test needs to preserve.
Concurrency comes with a tax. As the number of overlapping experiments grows, the share of traffic that belongs cleanly to a single test shrinks. Research on large-scale search experimentation documents this directly: the number of concurrent experiments that influence search results can fragment traffic exponentially, complicating analysis when many tests share the same users and surfaces 11. The same dynamic applies to an SEO portfolio where multiple tests target overlapping query clusters, share canonical parents, or sit on templates that inherit from a common parent layout.
The orchestration response is layered assignment. A test on a global template change occupies one layer. A test on cluster-level internal linking occupies another. A test on snippet variants occupies a third. Within each layer, units are randomized independently of the other layers, which keeps the marginal cost of adding a test bounded as long as the layers are genuinely orthogonal. Layers that touch the same surface have to be serialized or explicitly designed to interact, with the interaction modeled in the analysis. Skipping that classification step is how an experimentation pipeline silently produces correlated readouts that all look significant for the same underlying reason.
Orchestration layer: assignment, logging, and uncertainty quantification
The orchestration layer is the part of an SEO testing automation stack that most agencies underbuild. It carries four responsibilities, and none of them are optional once concurrency moves past a handful of tests.
- Assignment. Every unit — page, template, cluster, or location — gets a deterministic assignment to treatment, control, or holdout based on a hashed identifier, recorded with a timestamp and the test ID. Deterministic assignment is what makes re-analysis possible weeks later when a client asks why a specific URL ended up in the treated cohort.
- Logging. The system records what variant was served, what Search Console reported for that URL on that day, what crawl events touched it, and what on-site behavior followed. The log is the audit trail that survives staff turnover and the readout document that gets attached to the eventual rollout decision.
- Statistical machinery. The pipeline carries a shared estimator — fixed pre-test power calculations, locked stopping rules, and uncertainty quantification that reflects the assignment design rather than an off-the-shelf t-test that assumes iid units the experiment does not have 5. Cluster-randomized tests get cluster-robust standard errors. Interleaving tests get the attribution rule validated in production.
- Governance. The orchestration layer enforces the not-peeking rule by withholding interim significance from human dashboards, surfaces guardrail violations automatically, and routes rollout decisions to a named approver rather than to whoever happens to be looking at the dashboard on day four.
If you manage multiple locations: a portfolio economics comparison
This subsection narrows to agency leads running organic programs across multi-location healthcare portfolios, where the economics of testing look different from a single-brand site. The relevant question is not whether controlled experimentation is technically possible. It is whether the cadence of validated changes per account can clear the cost of building and maintaining the pipeline.
The comparison below uses variables rather than invented dollar figures. Treat T as the test count per account per quarter, H as analyst hours per test, and R as time-to-readout in weeks. The values are illustrative ratios for an agency managing 10–30 multi-location healthcare accounts.
| Operating model | Tests per account per quarter (T) | Analyst hours per test (H) | Time-to-readout (R) | Concurrent tests per account |
|---|---|---|---|---|
| Manual sequential testing | 1 | High (design, pull, analyze by hand) | 8–12 weeks | 1 |
| Spreadsheet-assisted | 2–3 | Moderate | 6–10 weeks | 1–2 |
| Automated pipeline with shared statistical engine | 6–10 | Low (hypothesis intake plus review) | 2–4 weeks (interleaving where applicable) | 4–8 across orthogonal layers |
The leverage point is not the per-test cost. It is the shared infrastructure across accounts. A statistical engine, an assignment service, and a logging schema built once amortize across every account on the platform, which is why the cost-per-validated-change drops as the portfolio grows. The same orchestration logic that prevents fragmentation within one account 11prevents it across the portfolio, because the layers are defined at the platform level rather than rebuilt per client. Agencies that try to operate this model with a spreadsheet and a senior analyst hit a ceiling at roughly the size where concurrent tests start interfering and nobody has time to notice.
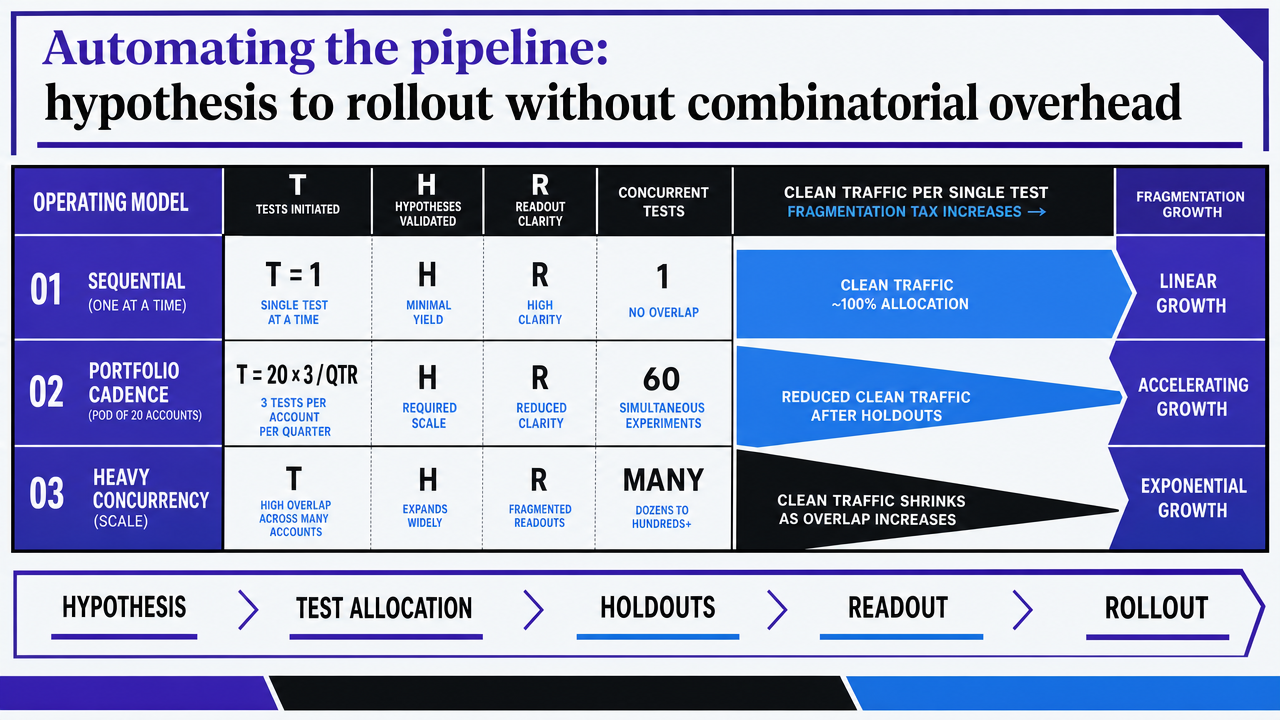 Render the comparison table from the 'portfolio economics comparison' subsection as a clean visual table, since the article explicitly presents a three-row operating-model comparison with variables T, H, R and concurrent test counts
Render the comparison table from the 'portfolio economics comparison' subsection as a clean visual table, since the article explicitly presents a three-row operating-model comparison with variables T, H, R and concurrent test counts
Reduce Content Testing Cycles with Autonomous SEO Experimentation
See how leading agencies are automating SEO test execution and analysis—eliminating manual bottlenecks and accelerating data-backed decision making across enterprise-scale web portfolios.
Running tests in healthcare and other regulated footprints
The reflex assumption among agency leads is that controlled experimentation belongs in e-commerce and SaaS, not on patient-facing pages. The evidence points the other way. A peer-reviewed evaluation of A/B testing on a clinical trial recruitment website concluded that controlled web experiments are a workable approach for optimizing patient-facing recruitment materials, provided the ethical and regulatory framing is built into the design rather than bolted on after the fact 9. The constraint is not whether to test in healthcare. It is what gets tested, on what surfaces, and with what oversight.
The practical line for an SEO testing pipeline operating across multi-location healthcare accounts runs through three filters:
- Scope. Tests on title patterns, schema markup, FAQ blocks, internal linking, and template-level metadata sit comfortably inside the experimentation envelope because the variants present the same clinical information differently rather than presenting different clinical claims. Tests on substantive medical copy — symptom descriptions, treatment efficacy language, contraindication phrasing — leave the SEO experimentation lane and enter medical review, where the orchestration layer's job is to route the variant out of the random-assignment pool entirely.
- Identifiers. Search Console and on-site behavioral data are sufficient for almost every SEO readout an agency needs. The pipeline does not require PHI to compare CTR on a treated cohort of location pages against a control cohort, and the governance posture is cleaner when the log explicitly cannot resolve to a patient identity. Test owners who find themselves wanting PHI to interpret a readout have usually drifted into a conversion-rate-optimization question that belongs in a different system with different controls.
- Documented approval. The audit trail the orchestration layer produces — assignment timestamps, variant served, guardrail status, readout date, approver — is the same artifact a compliance reviewer or client medical director will ask for when a test ships across patient-facing pages. Building that artifact as a byproduct of the pipeline, rather than reconstructing it after a question is raised, is what makes the cadence of validated SEO changes defensible inside a regulated footprint instead of confined to the marketing pages outside it.
Reading results when AI Overviews and CTR patterns shift underneath
A live experiment assumes the measurement surface holds still long enough for the treated and control cohorts to diverge for reasons the test owner cares about. AI Overviews, expanded snippet treatments, and shifting SERP layouts violate that assumption on a rolling basis. The cohort-level comparison the orchestration layer was designed to surface is still valid; the global readout pinned to last quarter's CTR baselines is not.
The defense is built into the design rather than the dashboard. Comparing treated against control inside the same window absorbs most environmental shifts because both cohorts experience the same SERP changes, the same AI Overview rollouts on the same query clusters, and the same seasonality. That is the entire point of running a control group rather than a calendar 4. When an AI Overview appears for a head term mid-test, it suppresses CTR on both arms, and the difference between them remains the cleanest available estimate of the variant's effect.
Three operational adjustments matter:
- Segment readouts by SERP feature presence so a snippet test does not get credited or penalized for traffic the variant never reached.
- Track impression share alongside CTR — a flat click count on rising impressions is a different result than a flat click count on falling impressions.
- Widen the guardrail set to include assisted conversions and on-site behavior, because SEO interventions reshape what users see and click on a finite attention surface 8, which means a CTR win that does not survive to a downstream action is not the win the readout claims.
Frequently Asked Questions
References
- 1.Large-Scale Validation and Analysis of Interleaved Search Evaluation.
- 2.New Method Reveals How Businesses Can Run Better Experiments.
- 3.Causal Inference in the Presence of Interference in Sponsored Search Advertising.
- 4.Causal Inference in Economics and Marketing.
- 5.Causal Inference: A Statistical Learning Approach.
- 6.An Introduction to Causal Inference.
- 7.Why control an experiment? From empiricism, via consciousness to telepathy.
- 8.The SEO effect. Mapping the optimized landscape around ....
- 9.A/B design testing of a clinical trial recruitment website.
- 10.Practical Guide to Controlled Experiments on the Web: Listen to Your Customers Not to the HiPPO.
- 11.Online controlled experiments at large scale.