
Key Takeaways
- CRO programs plateau because of operating-model defects, not tactical ones — a five-layer stack of measurement, hypothesis pipeline, experimentation, personalization, and governance turns scattered tests into a continuous production line.
- Measurement integrity is the foundation: a versioned spec defining conversion events, denominators, attribution windows, and segmentation dimensions before testing prevents the unreliable inferences flagged in analytics methodology research 7.
- Personalization is where compounding returns appear, with leaders generating 40% more revenue from personalization activities and typical lifts of 10–15%, but only if measurement and governance can support stable segments 10, 12.
- Build bottom-up: staff measurement first, then the hypothesis pipeline, then experimentation, then personalization, with governance threaded through from day one — particularly where tracking touches health-adjacent data 12.
Why most CRO programs plateau after the first quarter
Most conversion optimization programs follow a predictable arc. The first ninety days produce visible wins — a headline rewrite, a form field removed, a checkout step collapsed — and the dashboard moves. By month four, the lift curve flattens, the test backlog turns into a graveyard of inconclusive results, and the growth team starts blaming traffic mix or seasonality.
The plateau is rarely a tactics problem. It is an operating model problem.
Programs that stall tend to share three structural defects. They treat CRO as a rotating queue of tactics rather than a hypothesis-driven process with defined stages — data collection, segmentation, funnel analysis, ideation, prioritization, testing, and learning 1. They optimize against measurement layers that were never standardized, so conversion rates drift with every event-taxonomy change and denominator mismatch 7. And they confine "conversion" to a single landing page rather than the multi-step omnichannel paths users actually travel before they convert 9.
The growth teams pulling ahead are not running more tests. They have collapsed strategy, execution, and measurement into a single always-on loop, with each layer producing inputs for the next. The hypothesis backlog feeds the experimentation engine. The experimentation engine feeds the personalization layer. The personalization layer feeds back into measurement. Governance sits across all of it.
What follows is a five-layer operating system for building that loop, and the sequencing logic for staffing it without adding headcount.
The five-layer CRO operating system
From tactic library to production line
The CRO literature out of digital retail describes the work as a sequence of seven stages: data collection, segmentation, funnel analysis, ideation, prioritization, testing, and learning 1. That model is accurate, but it reads as a process diagram. Growth teams running it as a process tend to execute it linearly — collect for a quarter, ideate for a month, test for two — and end up with a backlog that ages faster than it ships.
Reorganizing those same seven stages into a five-layer stack turns the process into a production line that runs continuously. Measurement sits at the base. The hypothesis pipeline draws from it. The experimentation engine consumes hypotheses and returns evidence. The personalization layer applies the evidence to segmented audiences. Governance wraps the entire stack — event taxonomy, privacy posture, statistical thresholds, decision rights.
Each layer has its own throughput metric:
- Measurement is judged on definitional stability and data completeness.
- The hypothesis pipeline is judged on backlog depth and the share of hypotheses tied to a documented behavioral signal.
- The experimentation engine is judged on tests shipped per month and the rate of conclusive reads.
- Personalization is judged on incremental revenue per segment.
- Governance is judged on the absence of incidents.
The reframe matters because it shifts the question. Instead of asking which tactic to try next, the team asks which layer is currently the bottleneck — and invests there.
 Visualize the five-layer stack described in the section as a vertical operating-model diagram, reinforcing the production-line reframe
Visualize the five-layer stack described in the section as a vertical operating-model diagram, reinforcing the production-line reframe
Layer one: measurement integrity as the foundation
Before a single test ships, the measurement layer decides whether anything the team learns will be true. Most CRO programs skip past this and pay for it later, when a winning variant fails to replicate or a stakeholder challenges a result the analytics can't defend.
The JMIR methodological guidelines on web analytics for health information resources make the underlying problem explicit: raw metrics without a clear analytical framework can produce incorrect inferences, and the field still lacks universal standards for defining and reporting conversion-adjacent metrics like session duration, bounce rate, and conversion rate itself 7. Two analysts looking at the same GA4 property can produce different conversion rates because they chose different denominators, different event definitions, or different attribution windows. Neither is wrong. Both are unreliable.
A defensible measurement layer answers four questions in writing before any experiment runs:
- What counts as a conversion event, defined at the event-parameter level?
- What population sits in the denominator — sessions, users, or qualified sessions filtered by intent signals?
- Over what attribution window is the conversion attributed?
- Which dimensions are required for segmentation reads, so that subgroup analyses don't degrade into post-hoc fishing?
Treat this as a measurement spec, versioned like code. When the spec changes, historical comparisons get a footnote. When a new conversion event is added, its denominator is declared at creation, not negotiated during the readout.
The discipline matters more in regulated environments, where data completeness is constrained by what trackers are permitted to collect 12. A measurement layer built on standardized definitions and documented denominators is the only foundation that will hold up across a multi-quarter program. Everything above it — the hypothesis backlog, the experimentation engine, the personalization rules — inherits its accuracy from this layer or fails because of it.
Layer two: a disciplined hypothesis pipeline
A hypothesis backlog is the difference between a CRO program that compounds and one that recycles the same five ideas every quarter. Most teams keep a list. Few keep a pipeline.
The distinction is structural. A list is a queue of proposed changes. A pipeline is a managed inventory where every hypothesis carries an origin signal, a predicted effect size, an audience scope, and a falsifiable read condition before it earns a test slot. The CRO framework out of digital retail names this work explicitly — segmentation and funnel analysis precede ideation, and ideation precedes prioritization 1. Teams that invert the order, ideating first and hunting for data to justify the idea afterward, produce backlogs full of opinions.
Three intake sources keep the pipeline honest:
- Behavioral signals from the measurement layer — drop-off points, rage-click clusters, form abandonment by step.
- Qualitative signals from session replay, support tickets, and sales-call notes.
- Structural signals from usability audits, which still surface high-leverage problems even at well-resourced institutions; studies of academic medical center websites have found that many fail basic usability criteria affecting how users locate appointment information and provider details 4.
Prioritization needs a scoring rubric the team will actually use under deadline pressure. ICE and PIE work; so does any rubric that forces explicit estimates of impact, confidence, and effort. What matters is that the scores get written down at intake, not negotiated in the standup where the loudest voice wins.
The pipeline metric to watch is the share of shipped tests that produced a conclusive read — win, loss, or clean null. A backlog producing mostly inconclusive results is signaling either weak hypotheses or insufficient traffic per cell, and the fix is upstream, not in the test itself.
Test Conversion-Focused Content in Real Time
Experiment with live content to directly measure conversion optimization impact before making a commitment.
Layer three: experimentation rigor borrowed from clinical trials
The ceiling on most marketing experimentation programs is set by the rigor of the methodology, not the volume of tests. Teams ship variants, declare winners on p-values from underpowered samples, and watch the lift disappear in production. The fix is not more tests. It is borrowing the experimental discipline that already exists in the clinical-trial literature.
The applicability is direct. Research on A/B testing inside electronic health record systems shows that rigorous experimentation methods can be deployed in high-stakes clinical environments to iteratively improve decision support tools, with explicit attention to randomization integrity, sample sizing, and the ethical considerations that come with running live experiments on real users 6. If the method holds for clinician-facing workflows, the bar for a marketing landing page is lower in stakes but should not be lower in technique.
Four practices separate a clinical-grade experimentation engine from a typical CRO program:
- Pre-register the hypothesis, primary metric, and minimum detectable effect before the test launches — not after the data starts moving.
- Power the test against the segment that actually carries the conversion, not the aggregate session count.
- Define the decision rule in advance: what reading wins, what loses, what triggers an extension, and what counts as a clean null.
- Honor the null. Programs that quietly re-cut data until they find a winning subgroup are running noise generators, not experiments.
Velocity still matters. The discipline above raises the cost per test, which makes test slot allocation a strategic decision rather than an editorial calendar. Higher-traffic surfaces — appointment booking flows, pricing pages, primary product entry points — earn most of the slots because they hit power thresholds quickly. Lower-traffic surfaces move to qualitative methods or sequential testing rather than chasing significance on samples that will never get there.
The output of a rigorous engine is not just more confident lift numbers. It is a body of evidence the personalization layer can actually trust.
Layer four: the economics of personalization
Personalization is the layer where the experimentation engine starts paying compounding returns. A test that proves a variant works for one audience is a single data point. A test that proves a variant works differently across two or three defined segments is the raw material for a segmentation rule that runs in perpetuity.
The economic case is well-documented. McKinsey's consumer research finds that companies excelling at personalization generate 40% more revenue from those activities than average players, that effective personalization typically drives a 10–15% revenue lift across the businesses studied, and that 71% of consumers now expect personalized interactions 10. The figures come from large-scale cross-industry surveys and case examples, not a single vertical, so the magnitudes should be treated as directional rather than as a guaranteed lift for any specific funnel.
What the numbers settle is the prioritization question. A growth team weighing whether to invest in segmentation infrastructure — identity resolution, audience definitions, content variants per segment — is choosing between a flat conversion curve and one that bends. The 40% revenue gap between leaders and average players is not a tactic gap. It is an infrastructure gap.
Three segmentation tiers carry most of the lift in practice:
- Acquisition-stage segmentation differentiates first-time visitors from returning prospects and adjusts the call to action accordingly.
- Intent-stage segmentation reads behavioral signals — pricing-page visits, comparison-content engagement, demo-form starts — and routes high-intent traffic to shorter conversion paths.
- Lifecycle-stage segmentation, the most valuable and the hardest to instrument, ties post-conversion behavior back into acquisition messaging so the same person sees a different page on their second and third visit.
Each tier depends entirely on the measurement layer. Segments built on unstable event definitions produce unstable lifts. And each tier depends on the governance layer, because the data required to personalize is also the data most likely to trigger privacy obligations. The personalization ceiling is set by how much segmentable data the team can collect, retain, and act on within the rules that apply to its category — a constraint that becomes a hard wall in regulated verticals, and the subject of the next layer.
Layer five: governance, tracking, and the HIPAA constraint
Governance is where most CRO programs discover that their personalization ambitions and their compliance posture are on a collision course. The data that powers a high-performing segmentation engine — page-level behavior, form interactions, identifiers stitched across sessions — is the same data that triggers regulatory obligations in any vertical touching health, payment, or sensitive consumer categories.
The HHS guidance on online tracking technologies is explicit about the threshold. Information collected by pixels, cookies, and similar trackers on the sites and apps of covered entities and business associates generally constitutes protected health information when it relates to an individual's past, present, or future health, health care, or payment for health care and identifies the individual 12. That definition pulls common analytics implementations — third-party advertising pixels firing on appointment pages, session-replay tools recording form input, retargeting tags on symptom-related content — into the scope of HIPAA's Privacy and Security Rules. A 2024 federal court decision vacated portions of the guidance, narrowing some of its reach, but the underlying framework remains the operating constraint for any covered entity instrumenting its funnel 12.
For SaaS growth teams selling into regulated buyers, the constraint is inherited. If the product processes health-adjacent data on behalf of a covered entity, the marketing site and the in-product analytics fall under the same scrutiny that buyer's compliance team applies to clinical systems.
A governance layer that holds up under audit does four things:
- Maintains a tracker inventory mapped to data categories and legal basis, refreshed on a defined cadence.
- Enforces a server-side measurement path for any conversion event that could carry identifiable health context, so PHI never leaves the controlled environment via third-party pixels.
- Defines retention windows per event class and deletes on schedule.
- Routes any new tag, pixel, or personalization rule through a documented review before it reaches production.
The practical effect on the CRO program is that test slots and segmentation rules get evaluated against a compliance review alongside their experimental design. That added step is the cost of running personalization in a regulated category — and the reason governance belongs in the operating system, not bolted on after an incident.
Quantify the Impact of Data-Driven Conversion Optimization at Scale
Connect with our team to see benchmark-driven conversion strategies in action and learn how leading SaaS and agency teams accelerate pipeline growth and lower CAC without increasing headcount.
If you manage multiple locations: account-level CRO economics
The lens shifts here. Up to this point, the operating model has been described as it applies to a SaaS growth team optimizing a single product surface. For growth leaders inside multi-location healthcare operators or digital agencies running CRO across a portfolio of sites, the math changes — and the change is structural, not incremental.
The default operating model in this segment is one retainer per site or per service line. A per-site agency relationship produces per-site analytics specs, per-site hypothesis backlogs, and per-site experimentation calendars. Total program cost scales as R × N, where R is the average monthly retainer and N is the number of locations. Measurement standardization scales the wrong direction: each new site adds another event taxonomy to reconcile, another vendor's definition of a conversion, another denominator to argue about during quarterly reviews.
The account-level alternative inverts the structure. One measurement spec governs N sites. One hypothesis pipeline draws from pooled behavioral signals across the portfolio, which raises the statistical power available for any test at the segment level. One experimentation engine ships tests against site clusters that share traffic characteristics, then applies winning patterns across the cluster rather than re-running the test at each location.
| Variable | Per-site retainer model | Account-level continuous optimization |
|---|---|---|
| Program cost | R × N sites | Single account fee, independent of N |
| Analytics specs maintained | N (one per agency relationship) | 1 governing spec, N implementations |
| Experiment velocity per location | Capped by per-site traffic and per-site staffing | Cluster-pooled traffic raises power; patterns replicated across sites |
| Measurement standardization cost | Reconciliation overhead grows with N | Fixed at spec creation |
| Omnichannel integration | Fragmented per vendor; integration cost borne per channel 9 | Single integration layer across digital, call center, physical 9 |
The leverage point in healthcare specifically is the scheduling funnel. The scoping review on automated patient self-scheduling documents labor savings, cost reduction, shorter cycle times, improved patient satisfaction, and higher patient attendance and loyalty as outcomes that follow directly from reducing friction in self-service flows 3. Optimizing that single funnel once, well, at the account level — and rolling the winning pattern across every location — captures those benefits N times for the cost of one program. Running N parallel retainers to optimize the same funnel produces, in the best case, N versions of the same answer.
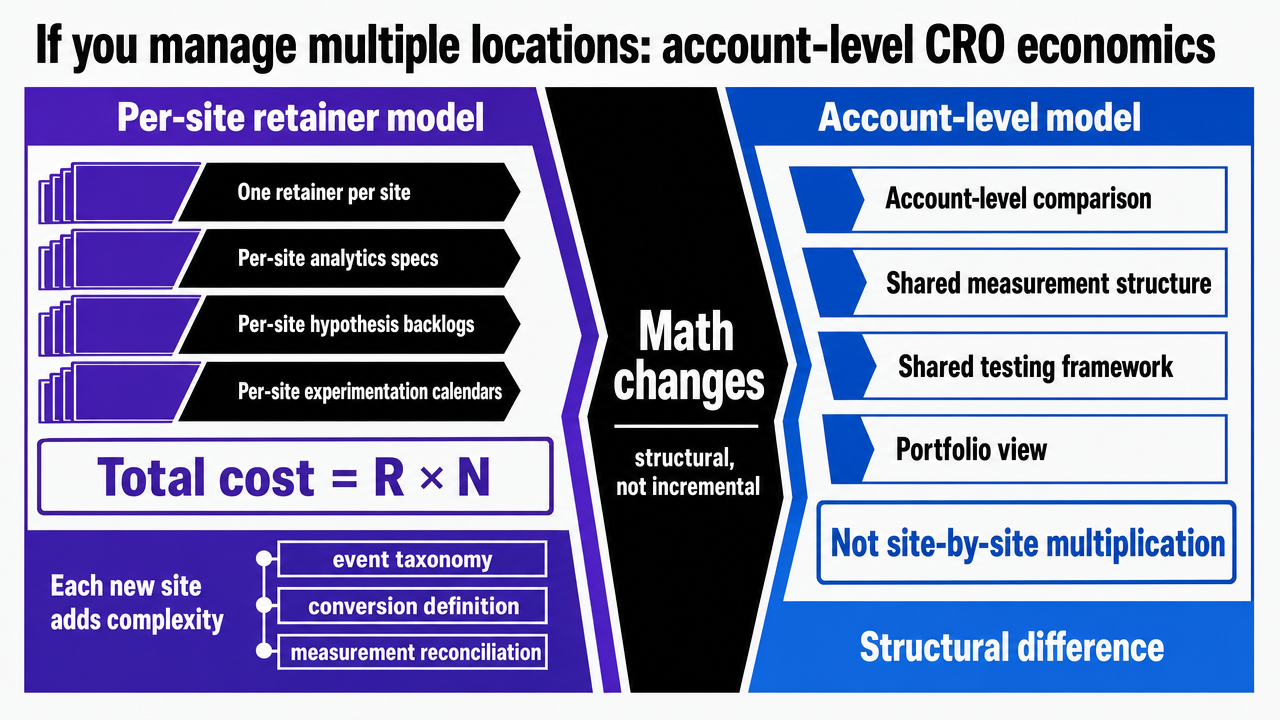 Render the per-site retainer vs. account-level comparison table from the section as a side-by-side comparison infographic, making the structural cost difference scannable
Render the per-site retainer vs. account-level comparison table from the section as a side-by-side comparison infographic, making the structural cost difference scannable
Where AI changes the cost-per-experiment math
Rigorous experimentation has a unit cost. Pre-registration, powered samples, segment-level reads, and pre-committed decision rules all add hours to every test slot, which is why disciplined CRO programs ship fewer tests than the trade press suggests they should 6. The constraint is rarely creative. It is the cost of doing the work properly.
AI-driven execution shifts the constraint by reducing the labor cost of the steps that surround the test itself. Drafting variant copy, generating segment-specific content blocks, reconciling event taxonomies across properties, summarizing inconclusive readouts into reusable learnings — these are the line items that consume analyst and copywriter hours between tests, and they are the line items where AI specialist roles now produce usable output without a headcount increase.
The effect on the operating model is specific. Hypothesis intake from behavioral signals can run continuously rather than in monthly cycles 1. Variant production for segmented audiences scales with the number of segments rather than with the number of writers, which is the precondition for the personalization tiers described earlier 11. And measurement reconciliation across multi-step omnichannel paths — the integration cost flagged in the omnichannel literature — drops because one execution layer maintains the spec across channels 9.
What does not change is the experimental method. AI lowers the cost of producing test inputs and synthesizing test outputs. The decision rules, power calculations, and governance reviews still belong to the humans accountable for the program.
Sequencing the build: what to staff first
Building all five layers in parallel is the failure mode. Programs that try it produce half-instrumented analytics, a hypothesis backlog without behavioral signals to draw from, and a personalization layer pointed at segments the measurement layer can't reliably populate.
The sequence runs bottom-up:
- Measurement first, because every layer above it inherits its accuracy from the event taxonomy, denominators, and conversion windows defined here 7.
- Hypothesis pipeline second, once the behavioral signals are stable enough to source ideas from data rather than from opinion 1.
- Experimentation engine third, scaled to the surfaces with enough traffic to hit power thresholds.
- Personalization fourth, only after the experimentation engine has produced segment-level evidence worth productionizing 10.
- Governance threads through all four from day one — it is the cheapest layer to build early and the most expensive to retrofit, particularly where tracking touches health-adjacent data 12.
Staffing follows the same order. The first hire — or the first AI specialist role — owns the measurement spec. The second owns the hypothesis pipeline and intake discipline. Only after those two roles produce stable output does adding experimentation and personalization capacity return more than it costs. Growth teams now have the option to staff these functions through an AI-driven execution layer rather than headcount, which is the model platforms like Vectoron are built around.
Frequently Asked Questions
References
- 1.Developing a conversion rate optimization framework for digital retailers.
- 2.Efficient patient care in the digital age: impact of online appointment scheduling on health care delivery.
- 3.Barriers to and Facilitators of Automated Patient Self-scheduling for Health Care Organizations: Scoping Review.
- 4.An Analysis of US Academic Medical Center Websites: Usability Study.
- 5.Applying Website Rankings to Digital Health Centers in the United States: A Cross-sectional Usability Analysis.
- 6.Applying A/B Testing to Clinical Decision Support.
- 7.Methodological Guidelines for Systematic Assessments of Health Information Resources and Digital Health Interventions: Web Analytics Component.
- 8.The Impact of Digital Patient Portals on Health Outcomes, System Efficiency, and Patient Attitudes: Updated Systematic Review.
- 9.An Overview of Omnichannel Interaction in Health Care Services.
- 10.The value of getting personalization right—or wrong—is multiplying.
- 11.What is personalization?.
- 12.Use of Online Tracking Technologies by HIPAA Covered Entities and Business Associates.