
Key Takeaways
- 10x content is now defined by Google's rater rubric—effort, originality, skill, experience, expertise, authoritativeness, and trust—rather than by word count or a competitor's top-ranking URL 15.
- A depth deficit audit that scores current work against the top three ranking URLs on the seven rater dimensions turns quality from a subjective debate into a measurable delta agencies can close.
- The production model that holds under scrutiny assigns judgment work—source vetting, first-hand evidence, argument construction, final approval—to human strategists while AI absorbs briefing, research synthesis, drafting, and instrumentation 9.
- Focus next on measurement and domain-level governance: segment engagement by audience and topic to defend depth claims 13, and run quarterly pruning audits because helpfulness is a site-wide, continuous signal 5.
The Volume Era Is a Solved Commodity
The economics of publishing thin content have collapsed. Any competent operator can now spin up a briefing template, a freelance bench, and a WordPress queue that ships forty posts a month per client. The output looks like content. It ranks like sediment.
Google's Helpful Content update, introduced in August 2022, made the shift explicit. It established a site-wide signal designed to reward material where visitors feel they had a satisfying experience, while demoting content "primarily created for ranking well in search engines" 5. This signal has since been integrated into core ranking, meaning helpfulness is now a continuous quality tax on entire domains 14. One weak vertical can drag down the rest of a portfolio.
The volume playbook also clashes with a more practical reality: focused, relevant content and clear site structure reliably improve rankings more effectively than high blog post counts. Pruning content frequently outperforms simply publishing more 11. Agency owners managing numerous client programs recognize this in their profit and loss statements. Writer payroll is often the largest cost of goods sold, and each additional thin post represents a liability with associated hosting fees.
Meanwhile, buyer behavior has evolved towards seeking in-depth information. A Forrester study of B2B buyers found that 68% prefer to conduct their own online research rather than engage with a salesperson 7. Self-directed readers do not value brevity or filler; they value content that thoroughly addresses their needs.
The strategic question is no longer about producing more content, but about producing content that measurably surpasses the best existing answers, at unit economics that clients can afford. This guide will address how to achieve that.
Redefining 10x: From Slogan to Operator Standard
What the Original Definition Got Right—and What It Missed
The original concept of "10x content"—content that is ten times better than the best result currently ranking for a given query—was valuable because it mandated comparison 1. It shifted the focus from vague quality aspirations to a specific benchmark on page one. Chaffey's glossary further refined this by incorporating a user-experience perspective, including interface, visuals, layout, and interaction patterns as integral to the quality standard, beyond just word count or keyword coverage 2.
However, the original definition lacked operational guidance. It described the outcome but not the system required to produce it. It offered no method for quantifying the gap between an agency's current output and top-ranking content, no economic model for scaling this quality across a client portfolio, and no measurement framework to prove its impact post-publication.
Peer-reviewed research on content marketing effectiveness helps bridge this gap. A framework study published in PMC identified strategy clarity, alignment with audience needs, journalistic quality, and performance measurement as key contextual factors linked to superior content outcomes 3. This provides a more comprehensive view, treating 10x as the result of a robust production system, rather than a fortunate brief.
Google's Quality Bar as the New Reference Line
The benchmark for 10x content is no longer a competitor's top-ranking URL, but Google's own quality standard, which has been documented with unusual specificity.
The Search Quality Rater Guidelines state that main content is high quality when it requires "a significant amount of effort, originality, and talent or skill to create," and instructs raters to evaluate pages based on experience, expertise, authoritativeness, and trust 15. This provides a seven-part rubric for agencies to score against: effort, originality, skill, experience, expertise, authoritativeness, and trust. Each dimension can be operationalized; for example, effort can be measured by hours and sources, and originality by comparing against existing summaries of the same topic.
The November 2023 update to these guidelines extended coverage to newer formats like short-form video and discussion pages, indicating that this rubric applies across various content types, not just long-form articles 16. Google's public documentation on creating helpful, reliable, people-first content translates the rater standard into practical questions for editors: does the content demonstrate first-hand experience, does it provide substantial value compared to other available information, and would a reader find the experience satisfying 4?
Search Engine Journal noted that Google has been replacing generic E-A-T references with more actionable helpfulness guidance across platforms like Discover, reinforcing the shift from abstract trust signals to concrete production criteria 6. Google's own ranking explainer emphasizes core elements: meaning, relevance, and quality 17.
The operator standard derived from this is clear: a 10x piece must score highly against the rater rubric on every dimension, not just those convenient for an agency. A well-researched piece lacking first-hand experience is a partial success. A compelling first-person account without verifiable expertise is another. The rubric is stringent because the ranking systems it informs are continuous, not occasional.
The Depth Deficit: Measuring the Gap Between What Ships and What Wins
Most agencies do not have a quality problem; they have a comparison problem. Editors typically approve content based on internal style guides and keyword briefs, rather than directly comparing it against the specific URL occupying the top search position. This often results in content that appears professional in isolation but seems thin in context.
A depth deficit audit addresses this comparison gap through a mechanical process. It involves pulling the top three ranking URLs for a target query and scoring each against Google's seven rater dimensions: effort, originality, skill, experience, expertise, authoritativeness, and trust 15. The agency's current content is then scored against the same rubric. The resulting delta reveals the deficit, providing a quantifiable matrix rather than a subjective assessment.
Three common failure patterns emerge from this exercise:
- Derivative research: content that synthesizes the same secondary sources cited by competitors, without incorporating primary interviews, proprietary data, or first-hand accounts. Google's helpful content guidance explicitly asks whether a piece demonstrates first-hand expertise and depth of knowledge, or merely summarizes existing information 4. Extractive summaries inherently fail this test.
- Credential opacity. For a Your Money or Your Life (YMYL) topic, an article on behavioral health written by an anonymous freelancer with a stock-photo byline cannot meet the trust threshold, regardless of its editorial quality. The rater guidelines treat authoritativeness and trust as distinct dimensions requiring verifiable signals, not just a confident tone 15.
- Task incompleteness. This occurs when content answers a query abstractly but fails to fully address the reader's underlying need. For instance, it might define a term when the top-ranking result provides a decision framework, or list options when the winning content offers a comparative analysis that enables reader action.
Peer-reviewed evidence supports viewing this as a systemic issue rather than solely a writer's fault. The determinants study of content marketing effectiveness identifies strategy clarity, audience alignment, and journalistic quality as the contextual factors most strongly linked to superior outcomes 3. A depth deficit arises when these factors are absent from the brief, not when the writer underperforms.
When scored monthly across a client portfolio, the depth deficit becomes a leading indicator. Rankings, traffic, and conversions follow with a lag. Editorial calendars developed without this metric are essentially guesses disguised as plans.
Experience 10x content execution at scale
Test-drive publishing high-impact content with measurable workflow efficiency—no commitments, real campaigns, real results.
Designing for Self-Directed Readers, Not Search Engines
Today's reader, upon arriving at a page, has likely already dismissed several others. They typically open multiple tabs from a search engine results page (SERP), scan each for specific answers, and close those that require excessive searching. This behavior is not an anomaly. A Forrester study of B2B buyers, summarized by LinkedIn, found that 68% prefer to conduct their own online research over engaging with a salesperson, emphasizing that effective content should be empathetic, easy to consume, and interactive 7. Self-directed readers do not value content that begins with a definition and slowly builds to a conclusion; they value content that efficiently completes their task.
This necessitates a shift in content design. A 10x piece is architected for a reader who scans first and reads second—one who expects the decision framework, comparison, or specific numeric range to be visible within the first screen, with supporting reasoning readily available below. Chaffey's UX framework reinforces this: the user experience, encompassing interface, visuals, layout, and interaction patterns, is an intrinsic part of the quality standard, not merely an aesthetic addition to finished copy 2.
Format choices follow the same logic. A 2026 B2B trends report from Demand Gen indicates that 82% of marketers now prioritize short-form video when adapting content for modern buyers 8. This statistic does not negate the value of long-form depth; rather, it argues for multi-format execution. This involves creating an anchor asset that fully develops an argument, complemented by derivative video, comparison tables, and structured summaries that cater to readers who may not intend to read 4,000 words.
Google's helpful content guidance reinforces this approach. Its evaluation questions directly ask whether content provides a satisfying experience for the reader and offers substantial value compared to alternatives already indexed 4. Neither question rewards padding; both reward completeness at the level of granularity implied by the query.
The practical implication for agency editors is straightforward. Every brief must specify:
- an explicit task the content needs to accomplish,
- a scannable structure allowing readers to verify completion within thirty seconds, and
- a supporting layer for the minority who read linearly.
Content that consistently meets these three criteria often outperforms longer competitors that fail to do so.
The Production Model: Where Humans Decide and AI Does the Reps
A robust 10x operation divides work along a clear line: judgment versus repetition. Human strategists are responsible for decisions that enable content to meet Google's rater standards—including positioning, thesis development, source selection, subject-matter interviews, and final approval. All other tasks are repetitive and can be automated.
Harvard's Professional & Executive Education analysis of AI in marketing clearly outlines this division. Generative tools reduce the time spent on repetitive, data-driven tasks, allowing marketers to achieve more in less time across content, social, and ad workflows, provided human oversight ensures accuracy, originality, and brand integrity 9. This is the operating principle. AI streamlines four tasks that historically consumed significant billable production hours: briefing construction, research synthesis, first-draft assembly, and measurement instrumentation. Human editors handle the four tasks that cannot be delegated without compromising quality: source vetting, first-hand evidence gathering, argument construction, and the final go/no-go decision against the rater rubric.
The briefing process illustrates this arithmetic. Previously, a senior strategist scoping a 40-page pillar on medication-assisted treatment for a behavioral health client might spend six to ten hours analyzing SERP competitors, extracting subheadings, mapping entities, and drafting an outline. AI can now handle this scaffolding in minutes, freeing the strategist to focus on critical judgment tasks—identifying which clinician to interview, pinpointing state regulatory nuances missed by top results, and recognizing reader tasks left unaddressed by competitors.
Peer-reviewed evidence supports this division of labor. The determinants study of content marketing effectiveness identifies strategy clarity, audience alignment, and journalistic quality as the contextual factors most strongly associated with superior outcomes 3. None of these factors are drafting tasks; they are decisions made before a draft exists and enforced after it is written. While AI cannot own these decisions, it can eliminate the friction that prevents strategists from dedicating sufficient time to them.
The predictable failure mode of this model occurs when agencies assign judgment work to AI and reserve repetitive tasks for humans. Google's helpful content guidance explicitly states that content lacking first-hand experience, depth, and demonstrable expertise fails the standard, regardless of production efficiency 4. A model that merely generates faster derivative summaries will scale the depth deficit rather than resolve it.
Unit Economics of 10x for Multi-Client Content Operations
This section is specifically for owners and managing partners overseeing content operations for 20 to 150 client programs, where writer and editor payroll constitutes a major portion of COGS and every operational decision has compounded effects across a portfolio. The economics differ for single-brand in-house teams.
The theoretical argument for 10x content is incomplete without a P&L model. Agency owners cannot produce deeper work if the unit cost per piece increases faster than what clients are willing to pay. PwC's analysis of AI in marketing provides ranges that make this model feasible:
- a 20–50% reduction in production, third-party, and media costs;
- a 3–10x increase in content velocity; and
- a 10–30% improvement in creative effectiveness when AI is deployed strategically, rather than merely as a cost-cutting measure 10.
These are not fixed estimates but variables that operators can populate with actual COGS data and stress-test against client pricing.
The table below illustrates this modeling exercise, using baseline production as the index (1.0x) and applying PwC's provided ranges as variables. No specific dollar figures are included, as these will vary by agency.
| Variable | Baseline (Traditional) | AI-Assisted (Low End) | AI-Assisted (High End) |
|---|---|---|---|
| Production cost per piece | 1.0x | 0.80x (20% reduction) | 0.50x (50% reduction) |
| Monthly content velocity | 1.0x | 3.0x | 10.0x |
| Creative effectiveness lift | Baseline | +10% | +30% |
| Human judgment hours | Full stack | Preserved for strategy, review, approval | Preserved for strategy, review, approval |
Two key observations follow. First, the velocity range is prone to misuse. A 10x velocity gain applied to derivative summaries will produce ten times the depth deficit, not ten times the pipeline. PwC explicitly states that narrow cost-cutting deployments erode brand impact over time 10. The velocity metric is only valuable when the content produced meets Google's rater standards for effort, originality, and expertise 15.
Second, the cost reduction range masks the actual source of savings. These savings do not come from cheaper writers. Instead, they result from compressing the four tasks—briefing, research synthesis, first-draft assembly, and measurement instrumentation—that Harvard's analysis of AI in marketing identifies as repetitive, data-driven work ideally suited for AI 9. Human strategist hours per piece remain relatively constant because the judgment work is not delegated. What changes is the ratio: strategist hours become a larger share of a smaller total cost, which is precisely the composition an agency desires when clients are paying for expertise rather than mere throughput.
When modeled accurately, this range suggests that an agency producing 40 pieces per month at baseline cost could potentially scale to 120–400 pieces at 50–80% of the unit cost, with a 10–30% increase in effectiveness. This is the arithmetic behind 10x economics. It doesn't require extraordinary effort; it requires a production model that assigns repetitive tasks to AI and critical decisions to humans, ensuring content surpasses the best existing indexed results.
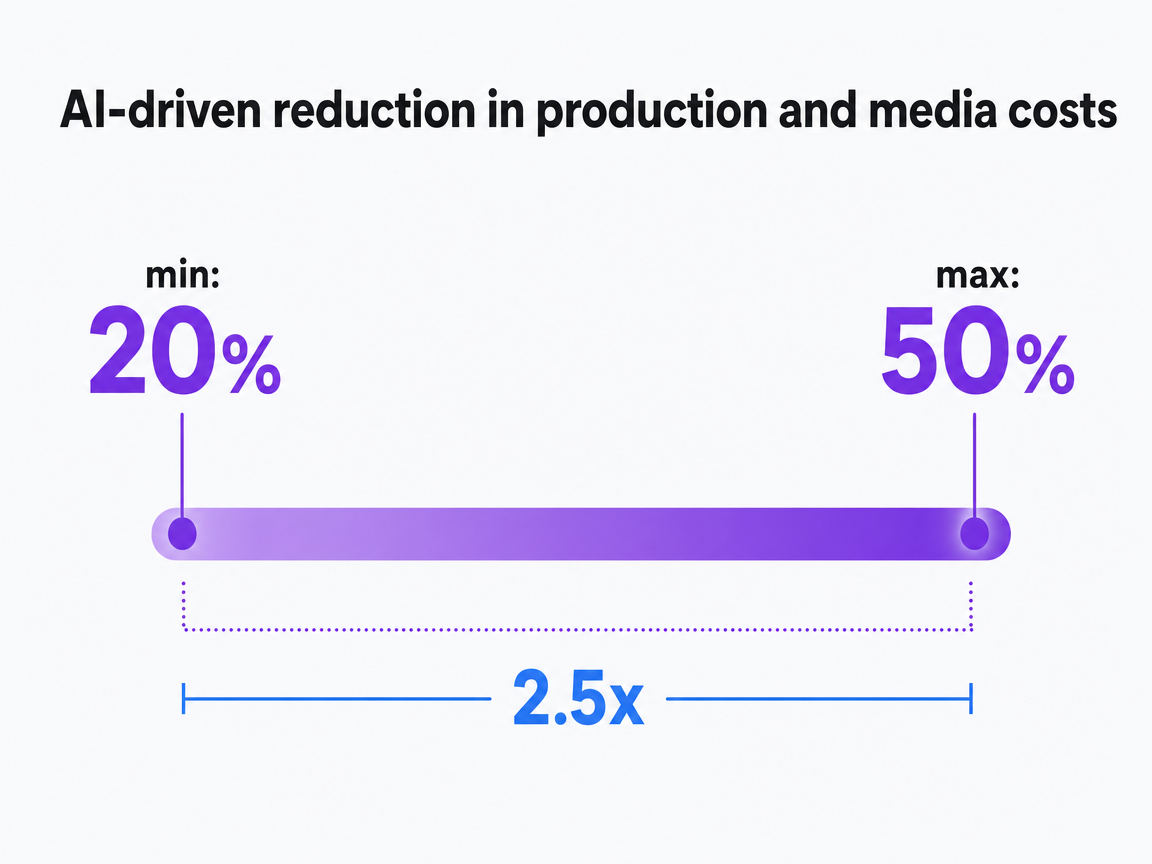 AI-driven reduction in production and media costs
AI-driven reduction in production and media costs
PwC reports that strategic use of AI in marketing can lead to a 20-50% reduction in production, third-party, and media costs.
See How Leading Agencies Scale 10x Content Without Sacrificing Quality
Connect with our team to benchmark your content process against AI-powered production models proven to reduce cycle times by up to 70% and increase content performance metrics across multi-channel campaigns.
The Measurement Gap That Makes 10x Unprovable
An agency cannot credibly claim 10x performance if it cannot measure it. This represents a common operational pitfall for most content programs: they invest in depth, publish content that seemingly surpasses top-ranking results, yet report on aggregate sessions and keyword rankings that fail to isolate which specific content resonated with which reader on which topic.
Forrester's analysis of B2B content operations quantifies the narrowness of current measurement capabilities. Only 41% of B2B marketing organizations can analyze content performance metrics by audience, and just 34% can do so by theme or topic 13. The majority operate without insight into the two dimensions most crucial for validating a 10x claim. An agency reporting quarterly on "content performance" without audience and topic segmentation is reporting on general trends, not specific results.
The consequence is strategic, not merely analytical. Google's ranking systems continuously weigh originality, relevance, and quality through both page-level and site-wide signals 14. If an editor cannot discern which content drove qualified engagement within specific reader segments, they cannot determine if the investment in depth is yielding compounding returns or if one segment is silently hindering the overall portfolio. The rater rubric used pre-publication becomes theoretical after launch.
Addressing this does not require a new analytics stack, but rather instrumentation decisions made during the briefing stage. This includes defining the target reader segment, the specific task the content must accomplish, and the post-publication signals—such as scroll depth by segment, assisted conversions by topic cluster, or return visits by author—that will confirm or refute the depth hypothesis. Enterprise research from CMI found that 61% of enterprise marketers reported content strategy improvement in the last 12 months, emphasizing that strategy must precede tools 12. Instrumentation is where this sequencing becomes practical. Without it, 10x remains a claim the agency cannot defend and the client cannot verify.
Site-Wide Risk: Why One Weak Vertical Drags a Portfolio
The Helpful Content update introduced a factor agencies still tend to underestimate in their planning: a site-wide signal. Google's own documentation describes this system as designed to reward pages where visitors feel satisfied, while demoting sites that appear to publish primarily for search engines 5. The unit of evaluation is the entire domain, not just individual URLs.
For an agency managing a single client site, this is a quality issue. For an agency managing 20 to 150 clients, it becomes a governance problem. A single weak vertical—for example, a senior living client whose location pages were created two years ago by a former freelancer—can lower the ranking potential of every well-researched pillar published on the same domain. Since the helpfulness signal is now integrated into core ranking, this drag is continuous, not a temporary penalty an editor can simply wait out 14.
This exposure is compounded when a client portfolio includes Your Money or Your Life (YMYL) categories. Rater guidelines apply higher trust and expertise thresholds to health, legal, and financial content, and the standard for main content demands effort, originality, and demonstrable skill 15. Thin location pages or templated FAQ blocks that might pass for a home services client can fall short on a behavioral health domain, thereby depressing the performance of other pages that would otherwise rank well.
The operational solution is a quarterly domain-level audit coupled with pruning authority. Pages that fail the rater rubric must either be rewritten to meet the depth standard or removed. Editorial calendars focused solely on adding new content cannot effectively manage this risk.
An Operating Model Worth Defending
The volume era rewarded agencies for sheer output. The current era rewards agencies that can prove content surpasses the best existing indexed answers, produce it at client-acceptable unit economics, and instrument it sufficiently to defend that claim ninety days post-publication. These three requirements—a high quality bar, efficient production economics, and a robust measurement layer—form a single, interconnected system, not three separate initiatives.
In practice, this model is straightforward. Human strategists make the critical decisions that ensure content meets Google's rater standards for effort, originality, and expertise 15. AI streamlines briefing, research synthesis, drafting, and instrumentation—the repetitive tasks that historically consumed agency margins 9. Editorial calendars incorporate a depth deficit score, not just a publish date. Domain-level audits are conducted quarterly because the helpful content signal is site-wide and continuous 5. Client reporting segments performance by audience and topic, addressing the measurement gap identified by Forrester 13.
An agency operating under this model does not out-publish its competitors; it out-decides them. The Vectoron platform was built to support operators making this transition, preserving human judgment for every approval while AI handles the repetitive tasks that once defined agency payroll.
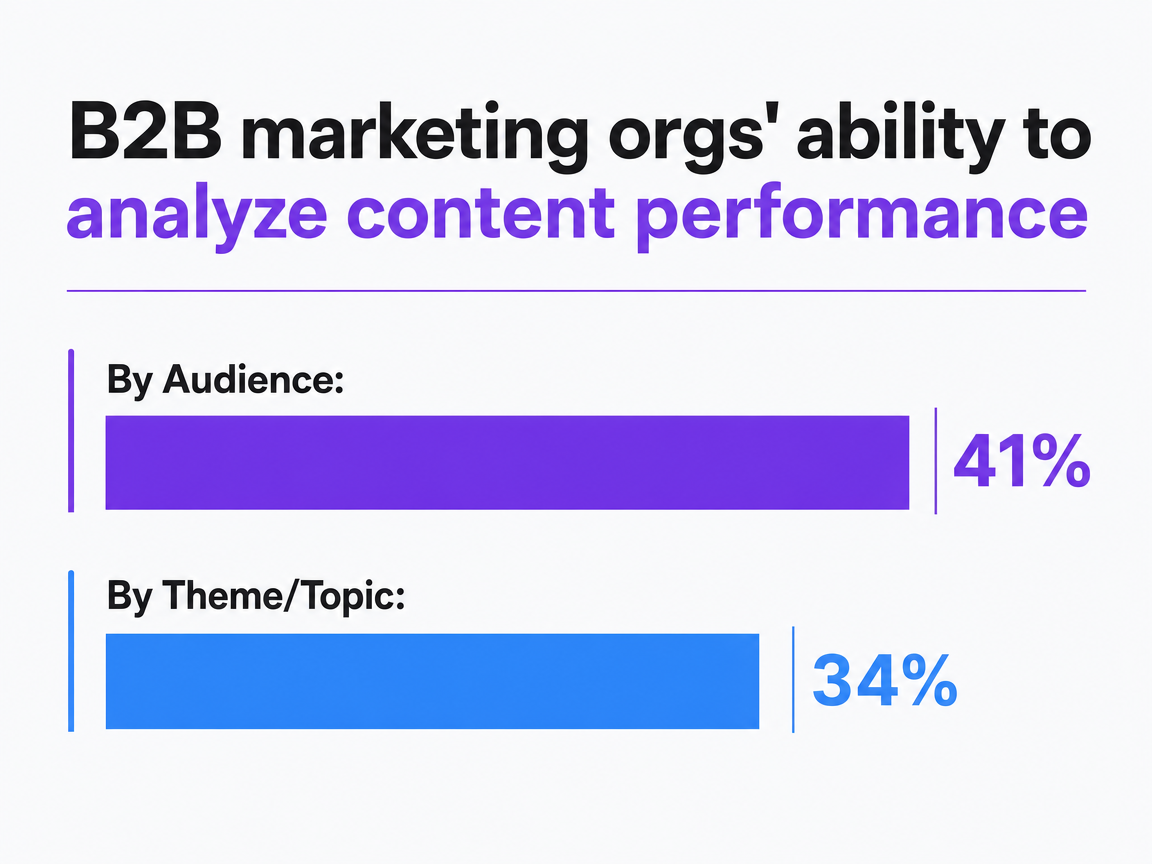 B2B marketing orgs' ability to analyze content performance
B2B marketing orgs' ability to analyze content performance
Data from Forrester shows the percentage of B2B marketing organizations that can view and analyze content performance metrics by audience (41%) versus by theme or topic (34%).
 B2B buyers preferring self-directed online research
B2B buyers preferring self-directed online research
B2B buyers preferring self-directed online research
Frequently Asked Questions
References
- 1.What is 10x Content and Why Does it Matter?.
- 2.10X Content definition - Digital marketing Glossary.
- 3.Determinants of content marketing effectiveness: Conceptual framework and empirical findings from a managerial perspective.
- 4.Creating Helpful, Reliable, People-First Content.
- 5.What creators should know about Google's August 2022 helpful content update.
- 6.Google Updates Guidance On Helpful Content System and Discover.
- 7.3 B2B Content Marketing Takeaways from a Forrester Research Study.
- 8.How to Adapt Your Content for the Modern B2B Buyer.
- 9.AI Will Shape the Future of Marketing.
- 10.Marketing in the AI era: To matter more or cost less?.
- 11.How Content Volume Affects SEO Rankings.
- 12.Enterprise Content and Marketing Trends: Insights for 2026.
- 13.What's Next In B2B Content? Five Important Focus Areas For 2022.
- 14.A guide to Google Search ranking systems.
- 15.Search Quality Rater Guidelines: An Overview.
- 16.Search Quality Raters Guidelines update.
- 17.How Does Google Determine Ranking Results.