
Key Takeaways
- Boutique editorial shops deliver the highest quality floor for flagship reports and CEO bylines, but low velocity and weak post-publish instrumentation make pipeline defense difficult for VPs facing board scrutiny.
- Full-service content agencies own the calendar and design handoff at moderate volume, yet handoff economics and inconsistent CRM integration push cost-to-output higher than the retainer suggests.
- Productized content shops win decisively on cost and velocity for known content needs, but report only on delivery and offer effectively zero attribution rigor or strategic depth.
- Programmatic SEO specialists capture long-tail intent at massive throughput and strong attribution when done well, though thin execution erodes site authority and hidden engineering costs distort the per-page math.
- AI-native content platforms reset unit economics dramatically per Deloitte's comparison 4, but only platforms that route assets through human approval and live pipeline signals are defensible in a board meeting.
- In-house augmentation services embed senior judgment inside the client's operation and inherit its measurement stack, but per-asset cost stays flat at scale and the headcount problem just becomes a contractor budget.
- Hybrid pod models pair a small senior team with an AI production layer, enabling a tight ship-instrument-rework loop that handoff-heavy agencies structurally cannot replicate, provided the humans in the pod are senior.
The measurement gap reframes the vendor question
Eighty-seven percent of B2B marketers wrestle with measuring long-term campaign impact, according to a LinkedIn-published view from three B2B marketing executives surveying their peers on measurement infrastructure 11. That figure is not a footnote. It is the reason the phrase best content marketing companies needs a sharper definition than it usually gets.
When a VP of Marketing types that query, they are rarely shopping for editorial taste. They are looking for a partner that can produce content tied to pipeline they can defend in a board meeting. The traditional shortlist — boutique editorial shops with award shelves, full-service agencies with retainer minimums, freelance benches stitched together by a project manager — was built for a different scoring system. It optimized for traffic, brand lift, and content volume. Pipeline contribution was assumed downstream.
That assumption no longer holds. Buyers research in zero-click environments, attribution windows stretch across quarters, and AI-assisted production has compressed unit economics that retainer math used to depend on. The right question is not which company has the best writers. It is which operating model connects production, distribution, and measurement to revenue without adding headcount. The seven entries below are organized that way — by archetype, not logo.
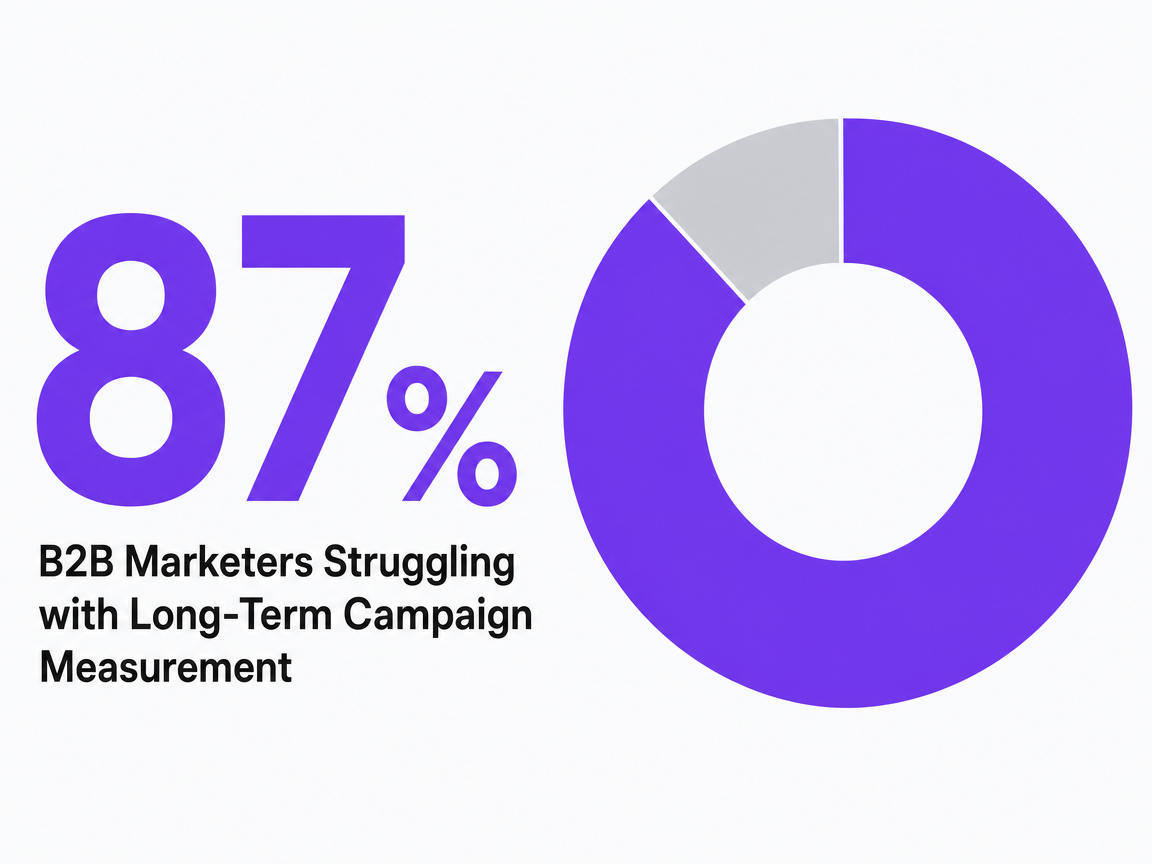 B2B Marketers Struggling with Long-Term Campaign Measurement
B2B Marketers Struggling with Long-Term Campaign Measurement
B2B Marketers Struggling with Long-Term Campaign Measurement
The rubric: production velocity, attribution rigor, cost-to-output
Three variables decide whether a content partner moves pipeline or just decorates a calendar.
Production velocity : Measures how many publishable, on-strategy assets ship per month at a defensible quality floor — not draft volume, not story count, but assets that reach distribution.
Attribution rigor : Measures what the partner can actually prove about revenue contribution. First-touch sourced pipeline is the lowest bar; multi-touch, incrementality-tested, and revenue-aware measurement is the bar Forrester argues B2B teams should be working toward 7.
Cost-to-output : The unit economics: fully loaded cost per published asset, including the internal hours spent briefing, reviewing, and chasing edits.
Every entry below gets scored against the same three. The scoring is deliberately blunt because procurement decisions are blunt. A boutique editorial shop may run laps around an AI-native platform on a single thought-leadership essay, then lose on velocity by an order of magnitude across a quarter. A programmatic SEO specialist may dominate on cost-to-output and fail the attribution test entirely. The rubric exposes those trade-offs instead of hiding them behind case studies.
Seven operating models, scored against pipeline
Boutique editorial shops
Boutique editorial shops are the model VPs reach for when the brief is a flagship report, a CEO byline, or a category-defining essay. Five to fifteen people, usually ex-journalists or senior brand writers, working on a small number of accounts at a time. Production velocity is low by design — three to six finished assets a month is typical — but the quality floor is the highest of any archetype on this list.
The attribution story is where this model gets uncomfortable. Editorial shops rarely instrument their own work past publication. They hand off the asset and trust the client's analytics stack to catch what happens next. For a VP under board pressure to show pipeline contribution, that means the partner cannot help defend the spend. Forrester's argument against sourced-pipeline thinking lands hard here: if the only measurable signal is first-touch attribution on a single landing page, the editorial shop's best work will look underweight in a report it had no hand in building 7.
Cost-to-output is the other constraint. Retainers concentrate spend on a handful of marquee pieces, which limits how often the program can test new angles, audiences, or formats. The model fits when brand authority is the bottleneck. It strains when pipeline is.
Full-service content agencies
The full-service content agency is the default the market has been buying for fifteen years. Strategy lead, editorial director, account manager, a rotating bench of writers and designers, a quarterly planning ritual, and a retainer that scales with output. Velocity is moderate — eight to twenty assets a month at mid-market scope — and the agency owns the calendar, the brief, and the handoff to design.
The problem is the handoff economics. Every asset moves through briefing, drafting, internal review, client review, revision, design, and publishing. Each handoff adds days and burns internal hours the VP rarely tracks. By the time a quarterly business review surfaces a pipeline gap, the calendar is already locked for the next sprint, and the agency's incentive is to ship what was approved, not to rework toward the gap.
Attribution rigor varies. The better agencies have integrated with client CRMs and can speak to assisted-conversion roles for specific assets. Most cannot, and default to traffic, time-on-page, and form fills. Cost-to-output is the weakest score on the rubric: fully loaded cost per published asset, including the internal PM hours the agency does not see, runs higher than the retainer suggests. The model fits brand-led programs. It struggles in pipeline-led ones.
Productized content shops
Productized content shops sell content the way a SaaS company sells seats. A fixed monthly fee, a fixed number of assets in a fixed format — typically blog posts at a defined word count — and a streamlined intake form that replaces the briefing meeting. Velocity is the headline strength: twenty to forty assets a month is common at price points well below a full-service retainer.
The model wins on cost-to-output and loses on strategic depth. The intake form cannot distinguish between a post meant to capture late-funnel comparison searches and a post meant to seed a category narrative. Both get the same treatment, the same writer pool, and the same SEO checklist. For a content program that already knows what it wants and just needs production capacity, that trade-off works. For a program trying to figure out what to want, it does not.
Attribution rigor is effectively zero. Productized shops report on delivery, not impact. They do not instrument assets past publish, and most contracts explicitly exclude performance accountability. The VP keeps the analytics burden. Used as a writing layer underneath an in-house strategy function, the model is efficient. Used as a strategy substitute, it produces volume without direction.
Programmatic SEO specialists
Programmatic SEO specialists build at a different scale than any other entry on this list. Templated page structures, structured data inputs, and automated publishing produce hundreds or thousands of pages targeting long-tail query patterns. Velocity is not the right word — throughput is. A single engagement can ship more pages in a quarter than a boutique editorial shop will write in five years.
The pipeline question is where the model splits in two. Done well, programmatic SEO captures high-intent comparison and category searches that convert at rates closer to direct-response than to top-of-funnel content. Done poorly, it produces thin pages that erode site authority and get penalized in algorithm updates. The difference is data quality at the input layer and editorial judgment at the template layer, neither of which the cheaper end of the market provides.
Attribution rigor is the strongest of the traditional archetypes because the assets are built around tracked query intent. Cost-to-output looks excellent on a per-page basis and worse once the in-house engineering hours to maintain the templates, the data pipelines, and the schema are counted. The model fits programs with defensible long-tail demand. It is a poor substitute for narrative content.
AI-native content platforms
AI-native content platforms are the operating model the rest of the list is being repriced against. The unit economics are the headline. Deloitte Digital's experiment comparing GenAI and human content production found that GenAI-produced emails were created in minutes, while human copywriters spent an average of four hours per email, and the total token cost for eight emails came in under a dollar 4. The same study added a caveat that matters: human-written copy still outperformed AI on some high-intent purchase signals, which is the honest reason this archetype is a platform rather than a replacement for editorial judgment.
Velocity is an order of magnitude higher than any human-only model. Attribution rigor depends on how the platform is built. The category splits between thin wrappers around a foundation model — which produce volume without measurement — and platforms that connect production to live pipeline signals, route every asset through human approval, and track KPI impact after publish. The second group is the one a pipeline-led VP can actually defend in a board meeting.
Cost-to-output is the structural advantage. The same Deloitte research frames content automation as a growth driver for marketing organizations that have rebuilt their operations around it, not as a point tool bolted onto a legacy workflow 3. The model fits teams that want to scale execution without adding headcount and are willing to invest in the approval discipline that keeps quality from collapsing. It does not fit teams looking for a hands-off vendor to outsource judgment to.
In-house augmentation services
In-house augmentation services place embedded contractors — a writer, a strategist, sometimes a designer — inside the client's marketing operation for a defined number of hours a week. They use the client's tools, attend the client's standups, and report to the client's content lead. The model trades agency overhead for staffing flexibility, and it sidesteps the briefing cycle because the embedded contractor is already in the room.
Velocity tracks the headcount purchased. Two embedded writers at twenty hours each produce roughly what one full-time hire produces, at a higher hourly rate but without the benefits load or the long-tail commitment. Attribution rigor inherits the client's stack — which is either a strength or an exposure, depending on what that stack actually measures.
The constraint is scaling. Each additional unit of output requires another contracted human, and the per-asset cost stays roughly flat regardless of volume. There is no unit-economics improvement at scale, which is the structural difference between this model and the AI-native platforms above it. The model fits teams that need senior judgment in the room and have the budget to rent it. It does not solve the headcount-cap problem; it reframes it as a contractor budget.
Hybrid pod models
Hybrid pod models stitch a small human team — usually a strategist, an editor, and a senior writer — to an AI production layer and sell the combination as a single retainer. The pod owns the calendar, the brief, and the quality floor. The AI layer handles first drafts, research synthesis, variant generation, and the structured tasks that used to consume junior writer hours. Velocity lands between a full-service agency and an AI-native platform, with a quality floor closer to the agency end.
The attribution story is the differentiator. Because the pod is small and the AI layer is integrated, the same team that ships the asset can instrument it, watch the data, and rework based on what the pipeline shows. That tight ship-instrument-rework loop is what the handoff-heavy agency model structurally cannot do. Cost-to-output lands in the middle of the rubric — better than a full-service retainer, worse than a pure platform, with the strategic depth a productized shop cannot match.
The risk is that pods are only as strong as the humans inside them. The model concentrates judgment in two or three people, which is an advantage when those people are senior and a liability when they are not.
Trial Real-World Content Production, No Restrictions
Experience fully-managed content workflows and measure pipeline impact before committing to a long-term solution.
What separates effective providers from the rest
The Content Marketing Institute's 2026 technology report found that 60% of tech marketers said their content strategies improved over the prior year, while only 12% reported a decline 1. That five-to-one split is the clearest signal in the research of what an effective provider actually does — because the improving cohort shares behaviors the declining cohort does not.
Three behaviors track to the improving side:
- Strategy refinement on a quarterly cadence rather than an annual one. Providers in the improving cohort revisit positioning, audience definition, and topic priorities every ninety days against live performance data.
- Measurement capability built into the engagement, not bolted on after publish. The improving cohort can answer what an asset did, not just that it shipped.
- Tooling integration — production, distribution, and analytics running on connected systems instead of three disconnected vendors emailing PDFs.
The declining 12% tends to share the opposite pattern: annual planning rituals, sourced-pipeline reporting as the only attribution lens, and tool stacks held together by an internal project manager. A VP evaluating a partner can run that three-part test on a discovery call. If the provider cannot describe how they refine, how they measure, and how their tools connect, they are likely operating in the declining group regardless of how their case studies read.
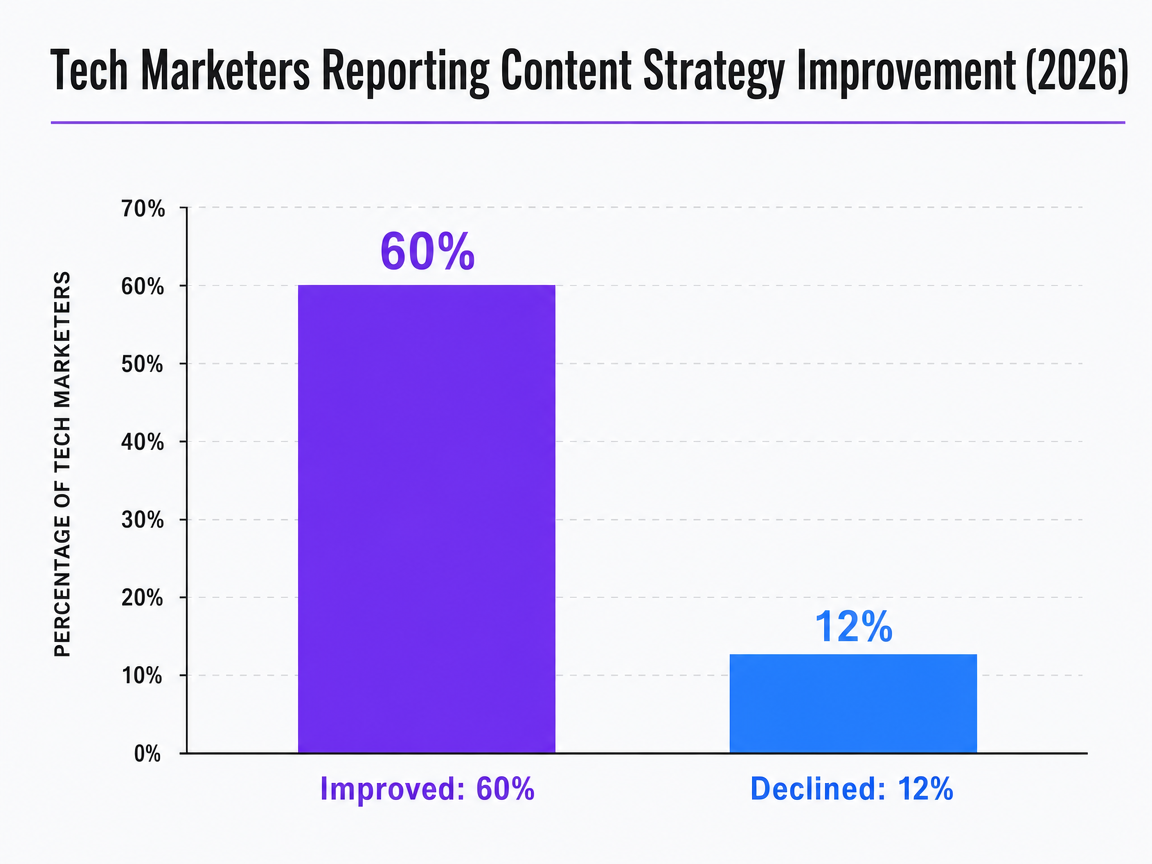 Tech Marketers Reporting Content Strategy Improvement (2026)
Tech Marketers Reporting Content Strategy Improvement (2026)
A bar chart comparing the percentage of tech marketers who saw their content strategies improve versus the percentage who saw them decline.
Distribution and measurement in a zero-click market
Forrester's recent work on zero-click buyer journeys frames the new discovery problem plainly: GenAI summaries, syndicated snippets, and aggregator feeds increasingly intercept the buyer before a website visit ever happens 6. That changes what a content partner has to do. Publishing the asset is no longer the last mile. The asset has to be structured, distributed, and instrumented to win attention in environments the publisher does not own.
The measurement side has moved in the same direction. Forrester's argument against sourced-pipeline thinking lands here for a second reason: if an asset's first touch is a summary inside an AI answer engine, the CRM will never see it 7. Multi-touch, incrementality testing, and revenue-aware analytics are what Nielsen's 2025 report describes as the working tools of marketers adapting to fragmented, AI-shaped media 5. A partner that still reports on traffic and form fills as proxies for pipeline is solving an older problem.
The practical test for a VP is whether the partner can name what they distribute past the website, what they measure past the click, and how they reconcile the two. If those answers are vague, the operating model is built for a market that no longer exists.
Where AI-assisted content underperforms
The honest case against AI-native production sits inside the same Deloitte experiment that makes the speed argument. Human-written copy outperformed AI-generated copy on some high-intent purchase signals, even when the AI version shipped in minutes and the human version took hours 4. The gap was not uniform across the funnel. It concentrated at the bottom, where the buyer was closest to a decision and the language had to do work that templated production could not.
Two patterns explain the underperformance:
- Original point of view — a perspective the buyer has not read elsewhere — is hard to generate from training data that already contains the consensus.
- Nuanced positioning against a named competitor, where one wrong word breaks trust, still rewards a senior writer who has sat through the sales calls.
A pipeline-led content program should route those assets to humans and let the AI layer handle the volume around them. Treating the question as all-or-nothing produces worse output than either model would on its own.
See How Leading Teams Streamline Content Production for Predictable Pipeline
Get a detailed walkthrough of AI-powered workflows used by top agencies and enterprise brands to coordinate multi-channel content, reduce manual effort, and drive higher conversion rates without increasing headcount.
Consolidation economics: stacked vendors vs. unified model
The stacked vendor model is the default mid-market content programs grow into rather than choose. A content agency on retainer for narrative work. An SEO agency for technical and ranking work. A freelance bench for overflow and specialty formats. An internal project manager — sometimes half of one — to keep the calendars, briefs, and invoices from colliding. Each line item is defensible on its own. The aggregate is where the math gets uncomfortable.
The worksheet below is illustrative, not benchmarked. The ranges are variables a VP can replace with actual contract values; only the unified-model trial price is a specific figure.
| Line item | Typical annualized range | Hidden internal cost |
|---|---|---|
| Content agency retainer | $8K–$25K/month | PM hours, review cycles |
| SEO agency retainer | $4K–$15K/month | Coordination with content agency |
| Freelance bench | $2K–$10K/month | Sourcing, QA, onboarding |
| Internal PM time | 0.5 FTE equivalent | Opportunity cost on strategy |
| Unified AI-assisted model | $599/month trial baseline | Approval discipline |
Consolidation is not a discount story. It is a coordination story. The unified model wins when handoff costs and attribution fragmentation are higher than the line items on the invoice — which, for most pipeline-led programs, is where the real spend already sits.
A decision framework keyed to your constraint
The right operating model depends on which constraint is binding. Three constraints cover most of the procurement decisions VPs actually make.
If the binding constraint is a headcount cap and the team already owns strategy, the AI-native platform or hybrid pod wins on unit economics. The approval discipline is the cost. Teams that cannot commit a senior reviewer to ship-quality sign-off should not pretend the model fits.
If the binding constraint is attribution maturity — the board wants revenue-aware reporting, not form fills — the hybrid pod and the better programmatic SEO specialists are the realistic shortlist. Full-service agencies make the cut only when their CRM integration is already built, which is rare. Sourced-pipeline reporting is not enough to defend the spend 7.
If the binding constraint is vertical risk — legal, behavioral health, healthcare, financial services — judgment density matters more than throughput. The hybrid pod or in-house augmentation route concentrates that judgment where regulators and buyers can read it. Volume-first models will write the wrong sentence at the wrong time.
 Buyers Reporting Negative Experiences with Personalization
Buyers Reporting Negative Experiences with Personalization
Buyers Reporting Negative Experiences with Personalization
Frequently Asked Questions
References
- 1.Technology Content and Marketing Trends: 2026 Insights.
- 2.Enterprise Content and Marketing Trends: Insights for 2026.
- 3.Marketing content automation - Deloitte Digital.
- 4.Human-AI marketing collaboration - Deloitte Digital.
- 5.Nielsen releases its 2025 Annual Marketing Report looking at the power of data-driven marketing.
- 6.How To Create Stand-Out B2B Content In A Zero-Click World.
- 7.B2B Marketers: It's Time To Ditch Sourcing Metrics.
- 8.2023 Nielsen Annual Marketing Report.
- 9.Study: Only 27% Of Marketing Automation Users Say It Impacts Contribution To Pipeline.
- 10.Gartner Survey Reveals the Pitfalls of Personalization to Avoid.
- 11.Three Marketing Executives Predict the Future of B2B Measurement.