
Key Takeaways
- Headcount-led scaling has stalled because flat marketing budgets near 7.7% of revenue 3 cannot support doubling writers, editors, and the coordination overhead that follows.
- Three metrics separate real scaling from output theater: cost per published asset, editor hours per asset, and approval cycle days, each exposing different structural constraints.
- Production line redesign must precede tooling, since touch time rarely exceeds 25% of cycle time and AI layered onto sequential workflows inherits the same queue bottlenecks 7.
- AI deployment is a sequencing decision: automate structured stages like keyword clustering and brief scaffolding, assist drafting work, and leave brand voice and regulated review manual 5.
- A derivative tree converts one pillar into five to seven downstream assets at 0.3 to 0.6 editor hours each, multiplying output without restarting research 10.
- Parallel approval architecture, modeled on HPE's nine-days-to-hours compression 1, replaces email chains with shared boards, named approvers, and concurrent review tracks.
- Comparing headcount-led, hybrid, and workflow-led models on identical volume reveals roughly $25,000 to $35,000 in monthly savings across a 96-asset portfolio 10.
- Editor utilization, not writer headcount, drives retainer margin: shifting editors from 30-40% to 70-80% judgment work frees about 200 senior hours monthly per portfolio 7.
Why Headcount-Led Scaling Stopped Working
Headcount-led scaling has become unsustainable due to flat marketing budgets. Since 2021, marketing budgets have remained at approximately 7.7% of company revenue, eliminating the financial flexibility agencies once had to increase content output by simply hiring more writers and editors 3. Despite these budget constraints, expectations for output have not decreased. Agency Heads of SEO are still tasked with producing more briefs, more localized content, and more derivative assets across larger client portfolios, all while operating within the same budget.
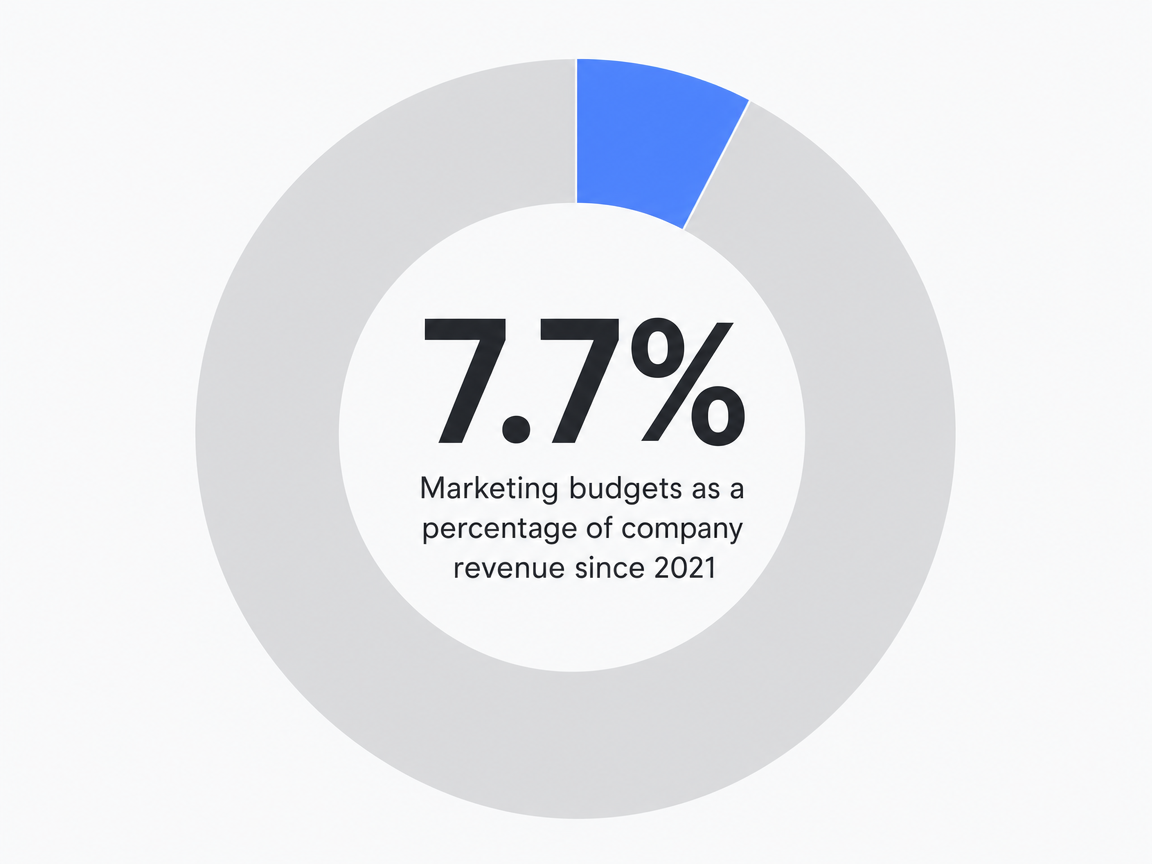 Marketing budgets as a percentage of company revenue since 2021: 7.7%
Marketing budgets as a percentage of company revenue since 2021: 7.7%
The traditional math no longer adds up. An in-house writer, fully loaded, producing eight long-form assets per month, incurs a cost per 1,500-word piece ranging from $100 to $600, even before factoring in editor time, approval coordination, and revision cycles. Doubling output by doubling writers also doubles the editor workload, the approval queue, and the project management overhead, which already consumes a significant portion of the margin on a typical retainer.
What is often perceived as a scaling problem is fundamentally a coordination problem. Sequential approval chains, fragmented feedback, and ambiguous decision-making authority cause briefs to remain in queues much longer than the time writers spend drafting them 8. Adding more writers to a team where the editor is already a bottleneck does not increase throughput; instead, it increases work-in-progress and extends cycle times.
Agencies achieving 3-5x output gains are not doing so by out-hiring competitors. They have restructured their production lines around three core operational layers: workflow redesign, strategic AI deployment, and parallel approval architecture. Each layer addresses a different aspect of throughput, and their combined impact is maximized when implemented in the correct sequence.
The Three Numbers That Decide Whether Scaling Is Real
Cost Per Published Asset
Cost per published asset is the only output-normalized metric for comparing operating models. Many agencies track writer rates and editor salaries separately, which obscures the true unit economics. The fully-loaded cost of an in-house writer producing a 1,500-word post typically falls between $100 and $600, once benefits, management overhead, and revision time are included. This wide range can determine whether a retainer generates profit or quietly drains it.
The critical number is total monthly content spend divided by assets actually published, not assets drafted. Drafts stuck in QA for weeks or pieces rejected during client review do not count. When an Agency Head of SEO recalculates this metric using only published assets, the cost per asset often increases by 30 to 60 percent above initial estimates.
Workflow-led production teams aim for a consistent downward trend in this metric quarter over quarter. If the cost per published asset remains flat while volume increases, the agency is scaling superficially, not structurally.
Editor Hours Per Asset
Editor hours per asset is a key bottleneck metric. While writers can be added relatively quickly, senior editors who maintain brand voice, technical accuracy, and SEO judgment are much harder to scale. When editor hours per asset remain above 4, every additional writer hired upstream simply pushes more work into an already saturated queue.
Production teams utilizing AI-assisted drafting with structured brief templates report editor hours dropping into the 1.5 to 2.0 range per long-form piece. This reduction is not due to editors working faster, but rather from removing tasks like research compilation, source verification, outline construction, and initial structural editing from their responsibilities. This allows editors to focus on judgment-intensive work: voice calibration, argument refinement, and final quality assurance 7.
Tracking this metric weekly reveals which stage of the production line is consuming senior capacity. If editor hours remain flat after a tooling rollout, it indicates that the redesign overlooked a critical stage, and the tools are merely being applied to an inefficient process.
Approval Cycle Days
Approval cycle days is a metric clients perceive, even if they cannot articulate it. The delay between draft delivery and publish-ready sign-off is often where retainer profitability erodes. Most agencies measure writer and editor turnaround times but fail to track the approval window, which frequently consumes more calendar time than drafting and editing combined 8.
The target benchmark is single-digit days for standard long-form content and same-day approval for time-sensitive pieces. Hewlett Packard Enterprise (HPE) reduced its content approval time from nine days to a few hours by redesigning its review architecture, not by pressuring reviewers to work faster 1. The lesson is clear: if approval cycle days are stagnant, the problem lies with the routing pattern, not reviewer effort.
Cost per asset, editor hours per asset, and approval cycle days are the three metrics that distinguish genuine scaling from mere output increases. Every subsequent operational decision should aim to improve at least one of these numbers.
Layer One: Production Line Redesign Before Tooling
Mapping the Stages a Brief Actually Travels Through
Many agencies struggle to visualize their own production line. While they can identify roles like strategist, writer, editor, and account manager, the actual stages a brief undergoes and the handoffs between them often exist informally in Slack threads and project management tickets, without a comprehensive audit. Content maturity begins with instrumenting the pipeline before attempting to change it 6.
A typical long-form brief progresses through eleven to fourteen distinct stages from intake to publication. These include keyword and intent analysis, competitive gap review, brief construction, SME or stakeholder input, outline approval, draft assignment, draft production, source verification, structural editing, line editing, internal QA, client review, revision cycles, and CMS publishing. Each stage has an owner, a queue time, and a touch time, yet most agencies track none of these.
The most significant throughput gain comes from timing every stage for two weeks across a representative sample of briefs. "Touch time"—actual hands-on minutes—rarely exceeds 25 percent of the total cycle time. The remaining time is "queue time," where briefs sit awaiting the next person. Once this distribution is clearly visible, the discussion shifts from writer speed to queue management, which is precisely where AI and parallel routing offer leverage.
Where Sequential Workflows Quietly Lose Throughput
Sequential workflows predictably lose throughput in three areas. First, the editor queue, where all drafts from all writers converge on one or two senior reviewers, creating a rate-limiting bottleneck. Second, the client review window, where briefs await feedback from stakeholders who often review content as a secondary task. Third, the revision loop, where feedback arrives fragmented across emails, document comments, and meeting notes, forcing the writer to piece together intent before making changes 8.
Each of these inefficiencies shares a common structural pattern: work proceeds in series when it could be done in parallel. SEO QA does not need to wait for line editing to complete. Legal or medical accuracy review can run concurrently with client brand review. Image production can proceed without waiting for the final draft. By treating these as parallel tracks instead of a relay race, cycle time can be significantly compressed before any AI tool is introduced.
Redesigning the workflow first is crucial because layering tools onto a sequential workflow simply perpetuates existing bottlenecks. Process-first automation programs yield $5.44 in returns for every dollar invested, with top-quartile teams achieving $8.71 7. Tools cannot fix a production line that has not been properly mapped and optimized.
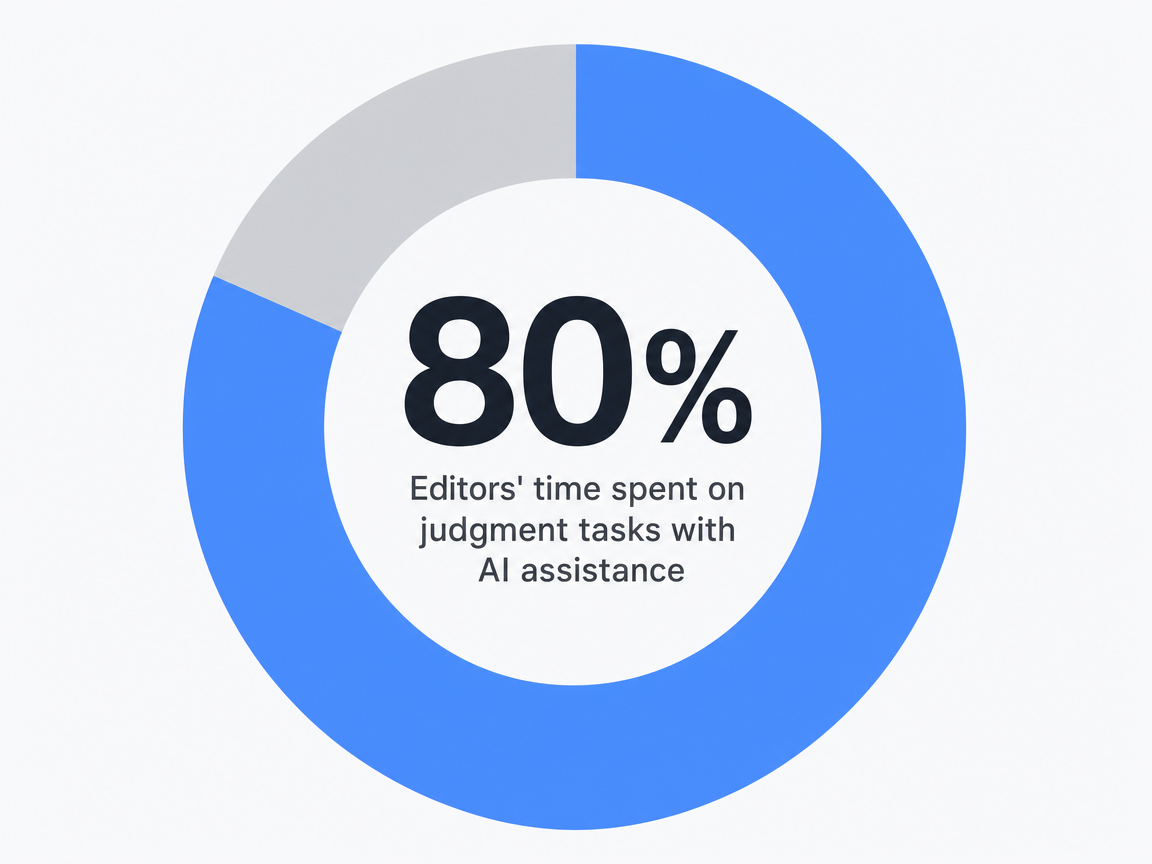 Editors’ time spent on judgment tasks with AI assistance: 80%
Editors’ time spent on judgment tasks with AI assistance: 80%
Scale Content Output Instantly—No Extra Hires Needed
Experience measurable content productivity gains with real, publishable content during your full-access trial.
Layer Two: AI Deployment as a Sequencing Question
What to Automate First, Assist Second, and Leave Manual
AI deployment often fails when approached as a tool selection exercise rather than a sequencing decision. The key question is not which AI writer performs best, but rather which production stages should operate autonomously, which should be human-assisted, and which should remain fully manual because the cost of human judgment outweighs potential automation savings.
Automate stages where input is structured and output is verifiable. This includes tasks like keyword clustering, SERP gap analysis, brief scaffolding from a confirmed outline, source compilation, internal-link suggestions, schema generation, and meta description drafting. These stages consume editor hours without requiring complex editorial judgment. When sequenced this way, process-first automation programs yield $5.44 for every dollar invested 7.
Next, assist stages where AI can accelerate drafting but a human retains ownership of the final output. This category includes first-draft prose, executive summary writing, FAQ generation from research, and image alt-text. The writer's role shifts from generating content from scratch to refining arguments, calibrating voice, and verifying sources. Editor hours per asset can decrease from over 4 to the 1.5 to 2.0 range when this handoff is efficiently structured.
Finally, leave manual the stages where errors are costly. This includes brand voice arbitration, regulated-vertical accuracy reviews, handling executive quotes, and final publish approval. In sectors like healthcare, where compliance reviews carry legal weight, the cost of an automated mistake far outweighs any throughput gain 5. The guiding principle for each stage is: if an incorrect output costs more than ten minutes of human review saves, it should not be automated.
The Asset Derivative Tree: One Pillar Into Seven
Pillar assets are often underutilized. A 2,500-word pillar that is published without generating derivatives leaves 60 to 80 percent of its potential output untapped. Production teams that implement a derivative tree can convert one pillar into five to seven downstream assets without restarting research 10.
A standard derivative tree from a single long-form pillar might include: an executive summary brief, a LinkedIn carousel, three to five short-form social posts, a newsletter feature, a video script for a two-minute explainer, an audio cut for podcast distribution, and a sales-enablement one-pager. Each branch reuses the source verification and argument structure already established in the pillar.
The economics significantly improve when this process is integrated into the workflow from the outset, rather than retrofitted after publication. Editor hours per derivative can drop to the 0.3 to 0.6 range because voice and accuracy issues were resolved during the pillar stage. AI handles format conversion, length compression, and platform-specific rewrites, allowing the editor to approve rather than construct. A four-person team producing 12 pillars per month can ship 60 to 84 published assets when the derivative tree is a default part of the process. This multiplier is often overlooked by agencies that benchmark output against draft volume instead of total asset volume.
Layer Three: Approval Architecture Built for Parallel Review
Diagnosing the Coordination Failure Pattern
Approval delays are rarely due to reviewers lacking time; they are typically caused by routing patterns that force decisions to move sequentially through inboxes. The diagnostic signs are consistent across agencies: unclear decision authority, feedback scattered across email threads and document comments, and a lack of automation to route assets to the next reviewer upon sign-off 8. This often results in a draft landing in a stakeholder's inbox on Monday, being reviewed on Wednesday, returning with conflicting comments, and bouncing back to the writer on Friday for revisions that require a reconciliation call.
Three symptoms confirm this pattern: cycle-time variance widens significantly between pieces, with some clearing in two days and others taking three weeks despite similar scope. Revision rounds tend to compound rather than converge, as each reviewer sees the asset without context from previous feedback. Writers spend more time tracking status than drafting, and editors absorb coordination tasks unrelated to editorial judgment.
The solution is not faster reviewers, but a change in routing that allows independent review tracks to run in parallel and consolidates feedback in a single location where all stakeholders can see prior comments before adding their own.
What HPE Changed to Compress Approval From Nine Days to Hours
Hewlett Packard Enterprise (HPE) reduced its content approval time from nine days to a few hours by replacing the email-based approval chain with a shared tracking board featuring automated notifications and escalation rules 1. The structural changes implemented are crucial to understand, as the impact was less about the tool itself and more about how the tool necessitated a workflow transformation.
Reviewers stopped receiving drafts as email attachments and began accessing them on a single board where status, owner, and deadlines were visible to everyone. SEO review, brand review, legal review, and stakeholder review all ran in parallel against the same draft, rather than sequentially. Comments were centralized, allowing subsequent reviewers to see previous feedback and avoid redundant or conflicting input. Automated notifications triggered when a stage opened and escalated when deadlines passed, eliminating the manual follow-up previously handled by account managers.
Two design choices are particularly important for agencies adopting this model. First, decision authority for each stage is clearly defined before the asset enters review—specifying who can approve, flag, or only comment. Second, the system defaults to parallel processing: any review that does not depend on the output of another review runs simultaneously. Sequential routing becomes the exception, requiring specific justification, rather than the default. When approval cycle days are stagnant under the current architecture, the routing pattern, not reviewer effort, is the lever for change.
Consolidation Economics: Three Operating Models Compared
The economics of content scaling become clear when an agency models the same output target using three different operating systems. Consider a portfolio of 12 client accounts, each producing 8 long-form assets per month—totaling 96 published pieces, plus the derivative tree for each pillar. The three models below assume identical output volume and quality, making the production line's structure the only variable.
| Operating Model | Cost Per Published Asset | Editor Hours Per Asset | Approval Cycle Days |
|---|---|---|---|
| Headcount-led (3 writers + 1 editor, fully loaded) | $400–$600 | 4.0–4.5 | 7–9 |
| Hybrid (freelance roster + in-house editor) | $250–$450 | 3.0–3.8 | 5–8 |
| Workflow-led (AI drafting + human editor + parallel approval) | $100–$220 | 1.5–2.0 | 1–3 |
The headcount-led model incurs the highest per-asset cost because each brief carries full staff overhead, and editor hours remain high (above 4) as senior reviewers handle research compilation, structural editing, and approval coordination 9. Approval cycles are sequential via email, leading to 7-to-9-day windows 8.
 Editors’ time spent on judgment tasks with AI assistance: 80%
Editors’ time spent on judgment tasks with AI assistance: 80%
The hybrid model reduces per-asset cost by using variable-rate freelancers for drafting, but it does not significantly impact editor hours. The in-house editor still manages brand voice, source verification, and the same sequential approval chain. Margin improves on the writing side but remains flat for editing.
The workflow-led model, exemplified by platforms like Vectoron, simultaneously improves all three metrics. AI handles structured stages—keyword clustering, brief scaffolding, source compilation, and first-draft prose—allowing human editors to focus on judgment tasks, reducing editor hours to the 1.5-to-2.0 range 7. Parallel approval routing replaces email chains, compressing cycles from days to hours, mirroring HPE's success 1. Process-first automation programs yield $5.44 per dollar invested, with top-quartile teams reaching $8.71, directly contributing to increased gross margin per retainer 7.
Across 96 monthly assets, the cost difference between the headcount-led and workflow-led models translates to approximately $25,000 to $35,000 in monthly savings at the portfolio level, even before accounting for the derivative tree multiplier that workflow-led teams produce by default 10. The critical decision for an Agency Head of SEO is not which model is cheapest, but which model can maintain quality while scaling efficiently, a question answered by analyzing editor utilization.
Unlock Enterprise-Scale Content Production—No Additional Headcount Required
See how leading agencies and in-house teams accelerate content output with AI-driven workflows, cutting production times by up to 70% while maintaining brand and SEO standards. Request an expert consultation today.
Editor Utilization and Margin Per Retainer
Editor utilization is a critical factor in retainer profitability. In traditional, headcount-led agencies, senior editors often spend 60 to 70 percent of their week on non-editing tasks, such as chasing reviewers, reconciling fragmented feedback, compiling research, and rebuilding outlines. This means that a single editor on the P&L effectively provides closer to half an editor's worth of actual editing capacity.
Workflow-led production, facilitated by platforms like Vectoron, reverses this ratio. When AI handles brief scaffolding, source compilation, and first-draft prose, and parallel approval routing eliminates administrative chase work, editors can dedicate 70 to 80 percent of their time to judgment tasks: voice calibration, argument tightening, accuracy review, and final QA 7. This increased utilization means one editor can manage the volume that previously required two, providing a structural reason for gross margin expansion per retainer, unlike the focus on writer-rate arbitrage common in many agencies.
The margin shift compounds across the entire portfolio. For a 12-account book producing 96 pillar pieces and over 400 derivatives monthly, reducing editor hours per asset from 4.0 to 1.8 frees approximately 200 senior hours each month without requiring additional hires 10. These freed hours can either absorb new accounts at near-zero incremental cost or be redirected to strategy work, for which clients pay premium rates. Editor utilization, rather than writer headcount, is the key variable determining whether a content function scales profitably or merely visibly.
The Operator Decision in Front of Agency Heads of SEO
The fundamental decision for Agency Heads of SEO is not whether to scale content, but rather which production model their agency will operate with in the next 18 months. The headcount-led model is no longer capable of managing its backlog under current budget constraints. The three layers—production line redesign, AI deployment, and parallel approval architecture—compound sequentially: redesign reveals queue time, AI removes structured work from senior capacity, and parallel approvals compress client-facing cycle days.
Agencies that approach this solely as a tooling exercise will likely spend the next year evaluating various writing assistants, only to find their per-asset costs remain flat. In contrast, teams achieving 3-5x output gains first instrument their pipeline, strategically sequence automation for verifiable stages, and rebuild approval routing for parallel review. They then integrate tools, like those offered by Vectoron, into a workflow that is designed to absorb and leverage them effectively 7. Platforms like Vectoron are designed for operators who have already committed to this approach and seek an integrated production engine, a seamless brief-to-publish workflow, and a robust approval architecture, rather than piecing together solutions from multiple vendors.
The immediate next step is practical: time every stage of one representative brief for two weeks, calculate the cost per published asset using only the published denominator, and then determine which operating model the next quarter's retainer math necessitates.
Frequently Asked Questions
References
- 1.How a Content Approval Process Went From 9 Days to a Few Hours.
- 2.Scaling PPC Campaigns Sustainably: Use The SCALE Framework.
- 3.Which 2025 Marketing Predictions Actually Came True?.
- 4.Compliance Review Program.
- 5.General Compliance Program Guidance.
- 6.7 Ways to Use Content Maturity Models.
- 7.How to Optimize Your Content Workflow with Automation.
- 8.Why Creative Approvals Take So Long.
- 9.Team Extension vs Traditional Hiring: A Smarter Way to Scale Teams.
- 10.The Complete Guide to Repurposing Content: Maximize Your Marketing ROI in 2025.