
Key Takeaways
- A scaled content engine runs on four connected layers—input intelligence, briefing, production, and governance—rather than headcount, with generative AI shifting the bottleneck from drafting hours to brief quality and review capacity.
- Brief specificity is now the moat: eight fields including primary intent, competitor gap, required entities, evidence, voice, audience segment, internal links, and differentiation angle determine whether drafts rank and convert.
- Track the input-to-publish ratio (published pieces divided by queued items per quarter) instead of raw article count; sustained performance above 0.75 signals an efficient engine, while below 0.50 indicates a backlog.
- Sequence the build correctly: establish input intelligence first, then codify briefs from top-performing articles, then install retrieval, factual, and editorial checkpoints before optimizing the drafting layer 1.
Why headcount stopped predicting content output
For most of the last decade, content team capacity scaled predictably: more writers, more articles. That line broke. Generative AI has compressed the marginal cost of drafting to near zero, with case studies documenting one-person teams achieving output "previously the domain of large corporations with substantial resources" 11. The variable that used to govern throughput, writer hours, no longer applies.
What governs it now is the system feeding the model. McKinsey's 2023 survey found marketing and sales among the top business functions deploying generative AI, meaning SaaS content managers must operationalize these tools 5. The teams excelling are not those with the largest rosters, but those whose keyword research, competitor gap analysis, and editorial standards translate directly into draft-ready instructions, with review checkpoints integrated into the production line.
This reframes the content manager's job. The deliverable shifted from coordinating writers to designing the inputs, briefs, and review architecture that transform research into published work at volume. Headcount became a lagging indicator of capability. A two-person team with a tight briefing standard and a disciplined review stack can now outproduce a five-person team using ad-hoc freelancer assignments, because the bottleneck moved from drafting to specification. The following sections detail the four layers of this engine and the operating metric that indicates its effectiveness.
The four layers of a modern content writing engine
Input intelligence: turning research into structured raw material
Input intelligence is where keyword research, competitor gap analysis, SERP intent signals, and internal performance data are converted into structured artifacts for downstream production. This involves deciding which content clusters to build, which queries map to which pages, and which competitor weaknesses warrant new content versus refreshes.
Maturity literature in related fields highlights the importance of this layer. Digital health capability research shows that organizations with low maturity in data, systems, and processes cannot effectively absorb new technology investments, and staged maturity models are crucial for sequencing these prerequisites 1. The same applies to content engines. A team applying generative AI to ad-hoc keyword lists and unsorted competitor exports will produce volume without yield. Conversely, a team that standardizes how research becomes a cluster brief—complete with priority scores, intent classification, and entity coverage requirements—will see compounding returns from every subsequent tool.
Concretely, this layer produces a queue. Each item includes:
- a target query set,
- a competitor benchmark (top three ranking pages with word counts, header structures, and missing entities),
- a business priority score linked to pipeline contribution or page-level conversion data, and
- a content-type designation (new build, refresh, expansion, or consolidation).
Effective managers treat this queue as a weekly artifact, not a quarterly plan. The queue feeds briefing, which feeds production. Skipping this step is the most common reason AI-assisted teams produce more articles without ranking more pages.
Briefing: the field-level anatomy of a production-ready brief
The brief is where most scaled engines either succeed or fail. A production-ready brief is not just a topic and a word count; it is a structured specification detailed enough for a generative model, a freelance writer, or an internal editor to draft an article of the same shape. The fields are the engine.
Eight key fields carry this load:
- Primary intent (the job the reader needs the article to do),
- Competitor gap (specific entities, sub-topics, or evidence types missing from top-ranking pages),
- Required entities and sub-topics (derived from SERP analysis),
- Evidence requirements (specific studies, benchmarks, or data for credibility),
- Voice constraints (tone, perspective, forbidden phrasing),
- Audience segment (e.g., early-stage researcher, operator, buyer),
- Internal link targets (URLs with anchor intent), and
- Differentiation angle (the unique claim the article will make).
Audience segmentation is particularly important. A survey of 893 respondents on AI-driven personalization found that AI-based personalization and content optimization significantly improve customer awareness, experience, and purchase intention 3. This finding justifies the audience-segment field in every brief. A piece for a SaaS content manager evaluating production tools differs from one for the same manager justifying budget to a CFO, even if both target the same query. Briefs that combine these segments into a generic specification produce drafts that rank but do not convert.
The test for a brief's discipline is whether two different writers, or a writer and a generative model, would produce drafts with identical coverage, evidence, and differentiation. If not, the brief is underspecified. Many teams find that the gap between their best and average briefs is the largest variable in output quality. Closing this gap requires only attention, not budget.
Production: where AI moves from drafting tool to assembly layer
Production is the layer where the brief becomes drafts. In mature engines, AI is no longer just a writing assistant for individual pieces; it functions as an assembly layer that takes a structured brief and outputs draft variants against the specification. The human role shifts from drafting to specifying, reviewing, and adjudicating between variants.
The economics of this shift are well-documented. McKinsey's 2023 survey identified marketing and sales as one of the top two business functions deploying generative AI, alongside product and service development 5. Lindenwood case research on a one-person content team using generative AI found that these tools "allow individuals and small teams to produce high-quality marketing materials that were previously the domain of large corporations with substantial resources" 11. These findings collectively indicate that the production capacity available to a two-person SaaS content team in 2024 is fundamentally different from that in 2021.
Operationally, the time distribution across the four production activities changes:
- Brief preparation expands to include specification work previously handled in writer-editor exchanges.
- Drafting compresses, as variants are generated in minutes rather than days.
- Review cycles shift from line-editing to fact-checking, voice-matching, and differentiation auditing.
- Revision rounds decrease because well-briefed first drafts are closer to publish-ready than typical freelance drafts.
Articles per FTE per quarter, a common throughput metric, increases. However, a more useful framing is that the bottleneck shifts. In writer-led production, it was drafting hours. In AI-assisted production, it is brief quality on the front end and review capacity on the back end. Engines designed with this reality in mind scale effectively. Engines that merely integrate AI into a writer-led workflow without redesigning brief and review steps see only marginal gains, as the existing system was built around a constraint that no longer applies.
Governance: the review architecture that lets teams ship faster
Governance is often misunderstood as a hindrance. In a well-designed engine, it is the mechanism that enables velocity by allowing managers to approve drafts at the pace of production, rather than queueing them for sequential human polish.
The need for structured review stems from generative model output characteristics. MIT Sloan, citing a Stanford HAI study, reported that general-purpose AI chatbots hallucinated on 58% to 82% of legal research queries, and even specialized tools with retrieval augmentation hallucinated over 17% of the time 7. While legal research is a high-stakes, citation-dense domain, these figures indicate that hallucination rates decrease significantly with retrieval and domain constraints but do not reach zero, even in purpose-built systems. The Harvard Misinformation Review similarly concludes that hallucinations persist even with retrieval-augmented systems and platform guardrails 9.
This evidence dictates the requirements for the governance layer. It needs at least three checkpoints integrated into the production line, not added at the end:
- A retrieval checkpoint grounds claims in cited sources before drafting.
- A factual review checkpoint verifies statistics, study attributions, and named entities against those sources.
- An editorial checkpoint audits voice, differentiation, and internal-link execution against the brief.
This accelerates publishing because each checkpoint catches specific errors early, when fixing them requires a paragraph rewrite rather than a republish. Teams skipping the retrieval checkpoint discover hallucinated citations during editorial review, necessitating a return to drafting. Teams skipping the factual checkpoint find errors post-publication, leading to correction notices and eroding trust. Research on AI-generated marketing content shows consumer reactions depend heavily on context and transparency regarding AI use, highlighting the tangible brand equity protected by governance 2. The review architecture converts AI's drafting speed into trustworthy published throughput, distinguishing scalable engines from those that produce volume requiring later defense.
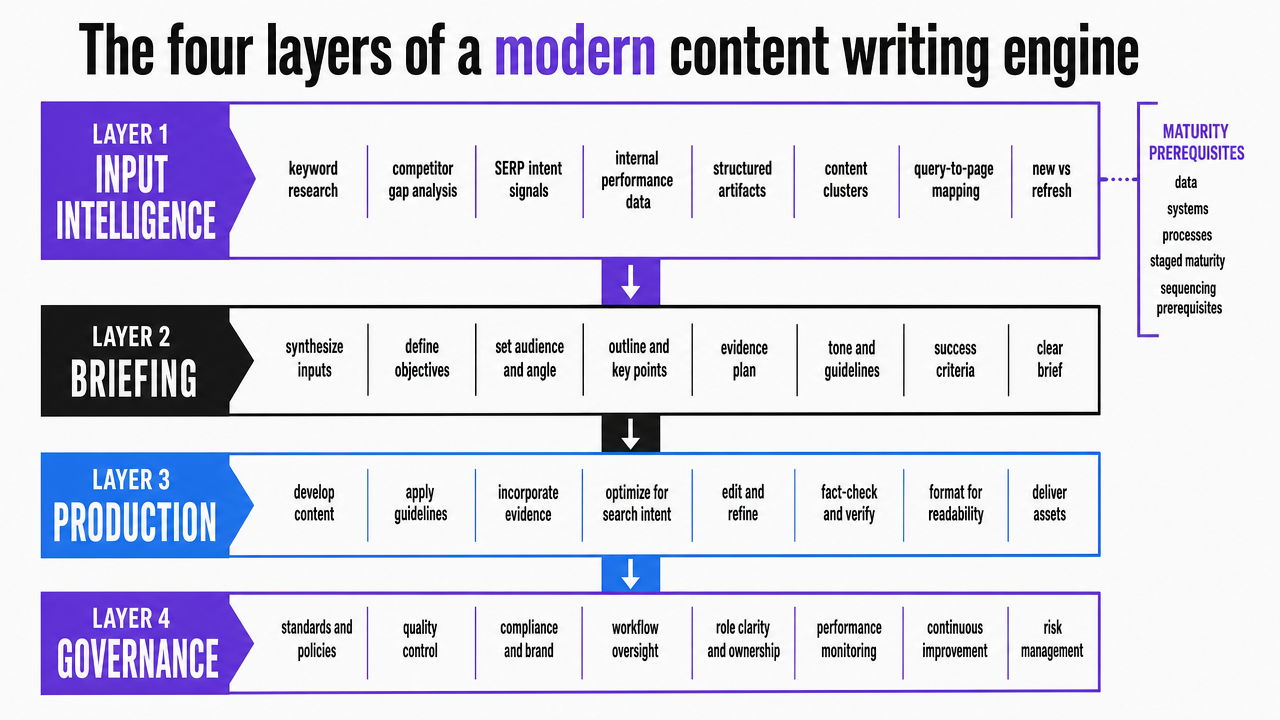 Visualize the four-layer engine architecture (Input Intelligence, Briefing, Production, Governance) described as the structural spine of the article
Visualize the four-layer engine architecture (Input Intelligence, Briefing, Production, Governance) described as the structural spine of the article
The input-to-publish ratio as the engine's operating metric
Article count is an inadequate metric. It rewards activity over throughput and fails to indicate whether the engine converts research into published work or stalls on rework. The input-to-publish ratio, defined as the share of items entering the queue at the input-intelligence layer that are published as on-brief articles within a defined window, is the crucial metric.
Calculated simply, it is published pieces divided by queued items, measured over a rolling quarter. A team that queues 60 cluster briefs and publishes 48 operates at 0.80. A team that queues 60 and publishes 30 operates at 0.50, regardless of dashboard article counts. Drop-off points provide diagnostic value:
- items stalling at briefing indicate underspecified research;
- items stalling in production suggest undraftable brief fields;
- items stalling in governance point to retrieval or factual gaps missed upstream.
This ratio is critical because generative AI inflates the top of the funnel, producing drafts faster and making raw output an unreliable signal. Capability maturity research in related domains argues that volume without staged process discipline leads to investments that do not compound 1. The input-to-publish ratio quantifies this risk. A team consistently maintaining a ratio above 0.75 quarter-over-quarter is running an efficient engine; a team below 0.50 is managing a backlog.
Test a Scaled Content Engine With Live Publishing
Experience rapid, data-driven article production and publish real content using your own keyword and competitor inputs.
Production economics: what changes when AI becomes the assembly layer
The economics of a writer-led content team versus an AI-assisted team are not merely a faster workflow. The time distribution across brief preparation, drafting, review, and revision redistributes, and the constraint on quarterly throughput shifts.
Consider a SaaS content team aiming for 40 articles per quarter, a common volume for two-to-ten-person organic teams. In a writer-led model, brief preparation is light (topic, keyword, rough outline). Drafting is heavy, consuming most cycle time. Review cycles are line-edit dominated, with one to three revision rounds typical. Throughput is limited by freelance capacity and internal editing. In an AI-assisted model, where the brief is the specification for a generative system, brief preparation expands significantly. Drafting compresses to minutes per variant, review shifts to fact-checking and differentiation auditing, and revision rounds decrease because well-briefed first drafts are closer to publish-ready.
| Production variable | Writer-led model | AI-assisted model |
|---|---|---|
| Brief preparation | Light: topic, keyword, outline | Heavy: full field-level specification |
| Drafting time per piece | Days to a week per draft | Minutes per variant, multiple variants |
| Review character | Line-editing dominated | Fact-checking, voice, differentiation |
| Revision rounds | 1–3 typical | 0–1 typical with disciplined briefs |
| Throughput constraint | Writer hours | Brief quality and review capacity |
McKinsey's 2023 survey, placing marketing and sales among the top business functions deploying generative AI, confirms this redistribution as the operating reality across the industry 5. Lindenwood case research on an AI-assisted content team found that these tools "allow individuals and small teams to produce high-quality marketing materials that were previously the domain of large corporations with substantial resources" 11. For a content manager, the operational consequence is that increasing quarterly throughput no longer primarily involves hiring more writers. Instead, it means improving the consistency and quality of briefs and enhancing review capacity at the fact-checking and differentiation checkpoints, rather than focusing on line-editing.
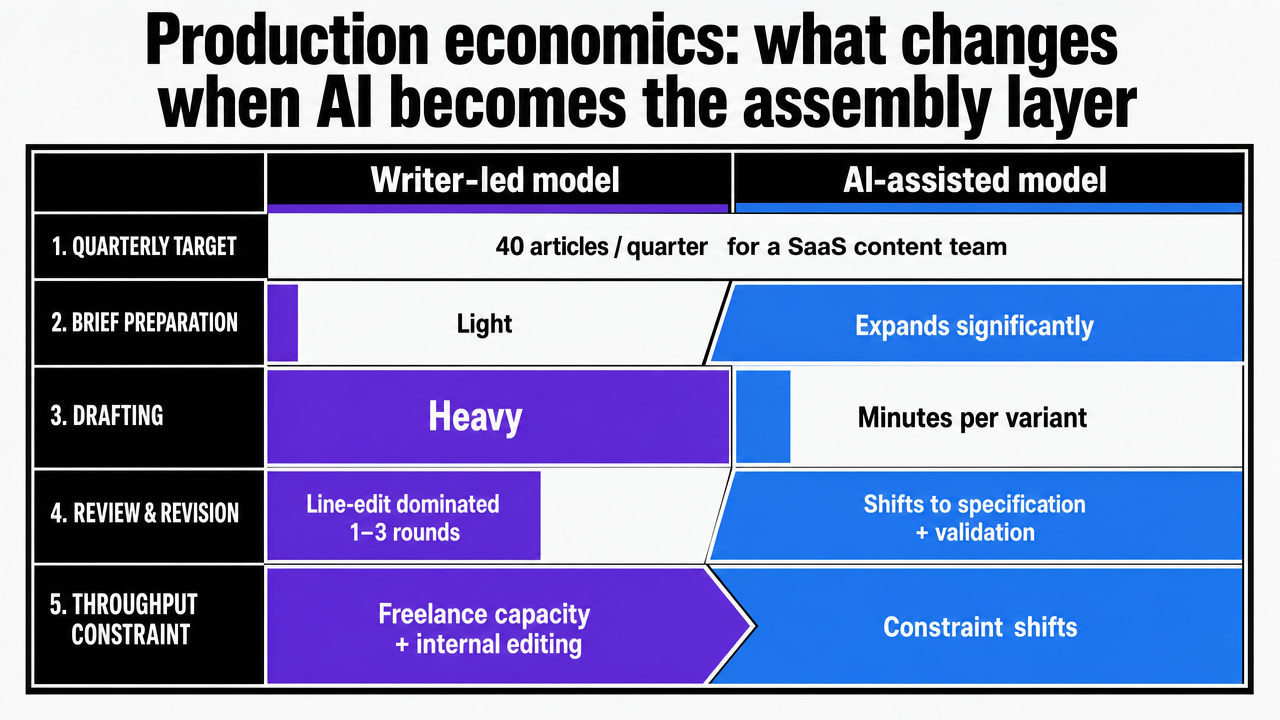 Visualize the comparison table contrasting writer-led versus AI-assisted production models across five operating variables, directly mirroring the table in the section
Visualize the comparison table contrasting writer-led versus AI-assisted production models across five operating variables, directly mirroring the table in the section
Brief specificity, not volume, is now the moat
The competitive advantage of a content team was once measured by publication volume. This metric no longer distinguishes strong engines from weak ones. Generative AI has drastically reduced drafting costs across the industry. Lindenwood case research on a one-person team using these tools starkly illustrates that production capacity once exclusive to large corporations is now accessible to individuals and small teams 11. When everyone has similar drafting power, output ceases to be a differentiator.
What remains scarce is brief specificity. The instructions a team provides to its production layer determine whether forty articles per quarter rank, convert, and compound, or if they become competent-but-interchangeable filler that quickly loses visibility. A brief that precisely defines the competitor gap, required entities, necessary evidence, and the article's differentiation angle produces drafts that no other team can replicate without similar upstream work. Conversely, a brief that only specifies a topic and word count yields drafts any team can replicate quickly.
Research on consumer reactions to AI-generated marketing content indicates that perceived authenticity and trust are highly dependent on context and transparency regarding AI use 2. Operationally, this means drafts based on thin briefs will appear thin, regardless of the model that produced them. Readers respond to specificity: named sources, distinct claims, and clear evidence of authorial engagement. These signals originate in the brief, not the model.
The strategic implication for content managers is that investment previously directed towards recruiting and retaining writers now shifts to briefing standards, retrieval discipline, and the editorial judgment required to decide which competitor gap to address and from what angle. This work does not scale by hiring more drafters. It scales by codifying the team's best brief practices and refusing to publish anything below that standard.
See How Top Agencies Automate Scaled Content Writing Across Multiple Brands
Request a walkthrough of autonomous content engines that convert keyword and competitor insights into published articles—without manual writer coordination or production bottlenecks.
If you manage content across multiple locations or practices
For content managers overseeing organic programs across multi-location healthcare operators, franchise footprints, or multi-practice portfolios, the engine described still applies. However, the queue economics change in a specific way that determines the viability of scaled production.
Each location or practice typically requires a base of evergreen service content plus location-specific variants: city pages, service-line pages tailored to local intent, and patient-education pieces aligned with the local clinical mix. Without a structured engine, headcount budgets quickly become unsustainable. With an engine, a single cluster brief can specify the shared core content and the location-variable fields (service names, clinician credentials, intake details, locally-cited evidence), allowing the production layer to draft variants against that core. Healthcare marketing literature consistently emphasizes that effective patient communication requires "in-depth investigation of the patients' needs" and segmentation rather than uniform promotion 4, 6.
Two operational notes are specific to this audience:
- First, governance load is higher due to documented regulatory and accuracy obligations in healthcare content marketing that SaaS content does not share 10. The factual checkpoint in the production line must include clinical accuracy review, not just source verification.
- Second, the input-to-publish ratio should be measured per location as well as in aggregate, as portfolio averages can mask locations where the queue stalls due to local-evidence gaps that the central team cannot resolve alone.
Sequencing the build: what to wire first, second, and third
Most teams attempting this build fail due to incorrect sequencing, not component issues. They often start by selecting an AI drafting tool, then try to retrofit briefs and review processes. The sequence that yields compounding returns operates in the opposite direction.
- First, establish input intelligence. Before any model drafts content, the team needs a standing queue of cluster briefs with intent classification, competitor benchmarks, and priority scores. Without this artifact, every downstream investment amplifies noise. Capability maturity research in related domains demonstrates that staged models are essential because skipping foundational layers leads to investments that do not compound 1.
- Second, codify the brief. Analyze the team's three best-performing articles from the last two quarters, reverse-engineer what made their briefs effective for drafting, and integrate those fields into a template that every new piece must complete before drafting begins. This is the most cost-effective and high-leverage step, requiring attention rather than budget.
- Third, install the review checkpoints. Start with retrieval, then factual, then editorial, each assigned to a named person with defined pass-fail standards. Only then is optimizing the drafting layer worthwhile.
Teams that follow this sequence can achieve a defensible input-to-publish ratio within one quarter. Teams that prioritize the model first will spend the same quarter rebuilding the foundational layers they initially bypassed.
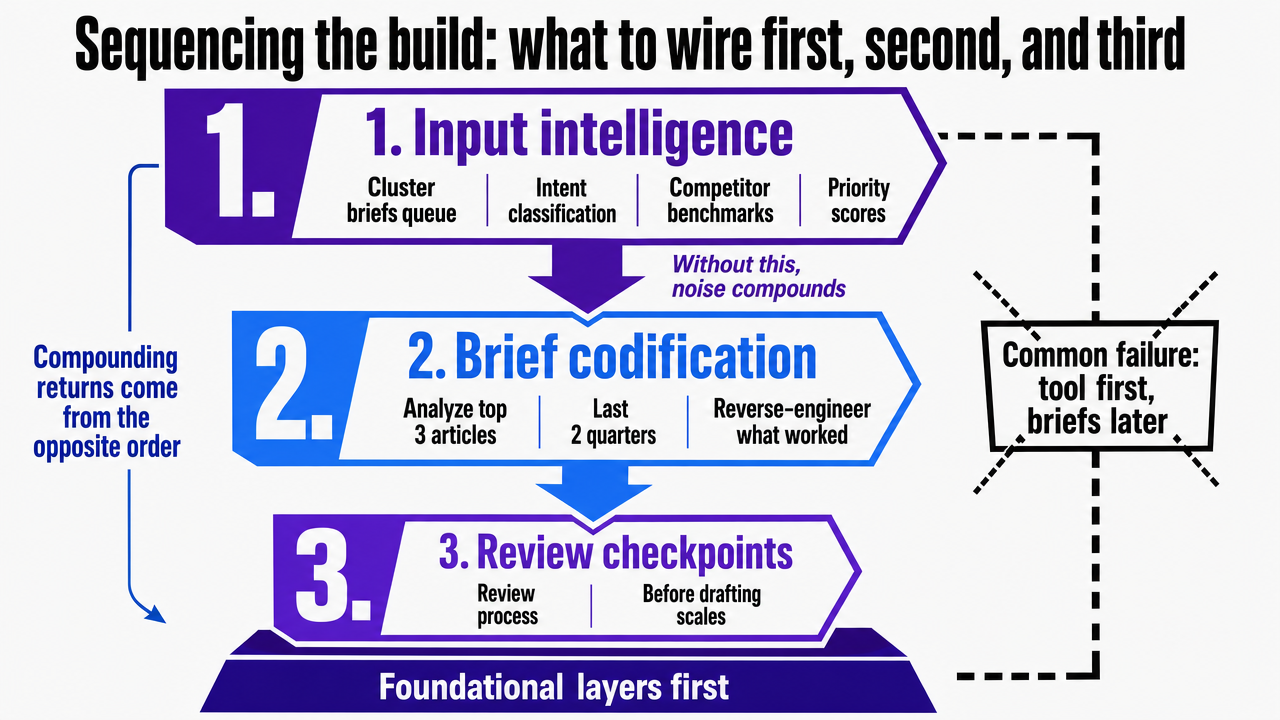 Visualize the cited three-step build sequence (input intelligence, brief codification, review checkpoints) which the section explicitly frames as the correct operational order
Visualize the cited three-step build sequence (input intelligence, brief codification, review checkpoints) which the section explicitly frames as the correct operational order
Frequently Asked Questions
References
- 1.Digital health and capability maturity models—a critical literature review.
- 2.The Effects of AI Generated Marketing Content on Consumer Perception, Trust, and Behavior.
- 3.The Role of Artificial Intelligence in Personalizing Social Media Marketing Strategies and its Impact on Customer Experience.
- 4.The impact of marketing strategies in healthcare systems.
- 5.The state of AI in 2023: Generative AI’s breakout year.
- 6.Systematic Analysis of Literature on the Marketing of Healthcare Services.
- 7.When AI Gets It Wrong: Addressing AI Hallucinations and Bias.
- 8.Is Artificial Intelligence Hallucinating?.
- 9.New sources of inaccuracy? A conceptual framework for studying AI hallucinations.
- 10.The impact and challenges of digital marketing in the health care industry.
- 11.From concept to creation: The role of generative artificial intelligence in modern content production.