
Key Takeaways
- Treat the search for SEO writing services as a throughput problem, and separate the interchangeable draft engine from the editorial system the in-house team owns and controls.
- Plan for residual error rates between 5% and 30% in unreviewed drafts depending on subject complexity, which makes a human review layer non-negotiable 3, 5.
- Wrap every draft in five gates — source grounding, factual verification, voice calibration, claims substantiation, and disclosure — each with a defined owner and output.
- Require a source pack with every brief so editors compare claims to named documents rather than re-researching from scratch, which is what keeps review hours predictable.
- Replace the 40-page style guide with a one-page calibration sheet of three to five enforceable rules, run as a separate pass from accuracy review.
- Keep a substantiation file with every article documenting performance, comparative, and capability claims, since FTC enforcement now actively targets deceptive AI-amplified marketing 9, 10.
- Set disclosure by asset class using evidence on reader response, not reflex, since labels minimally affect credibility or sharing intention 2.
- Judge draft engines on cost-per-reviewed-article, budgeting two to three and a half editor hours per piece, and prioritize fewer high-impact articles over raw volume 19.
The production problem behind the search query
A content manager typing "seo article writing services" into Google is rarely shopping for a freelancer. The real problem sitting on the desk is throughput. The editorial calendar shows 20 briefs a month, the team has two writers, and leadership wants organic pipeline contribution by next quarter. The search query is shorthand for a production constraint, not a vendor preference.
That constraint is now well documented. Forrester frames the current B2B content mandate as "more from less" — delivering greater impact with fewer resources, which pushes teams toward prioritization and better operations rather than raw volume 19. McKinsey's 2025 enterprise survey reinforces the gap between intent and execution: AI is widely seen as an innovation enabler, yet most organizations remain stuck in pilots, with uneven value capture across functions including content 18.
That gap is where quality risk enters. The instinct under pressure is to add drafting capacity — a writer marketplace, an agency retainer, a generative model — and treat the output as finished work. Institutional policies from Harvard Business School and the University of Texas now codify a different stance: AI or outsourced drafts are inputs that must be reviewed by a human before publication, full stop 11, 13.
The strategic move is to stop evaluating services and start designing the production system the service feeds into. The rest of this article lays out that system, the evidence behind each control, and the editor-hour math that justifies it to finance.
Draft engine vs. editorial system: the mental model that scales
The most useful reframe for a content manager under throughput pressure is to separate two things that the search query collapses: the draft engine and the editorial system.
The draft engine produces a first version of the article. It can be a freelance writer from a marketplace, a retained agency, a generative model, or a hybrid where a writer prompts a model and edits the result. These options are interchangeable inputs. They differ on speed, unit cost, and revision behavior, but they share one property: none of them produce publishable work on their own. Harvard SEAS states the principle plainly — generative AI is a tool, not a replacement for human expertise and judgment 12. The same logic applies to a $0.10-per-word freelancer.
The editorial system is what the in-house team owns. It is the set of controls that turn a draft into a published article: the source brief, the factual claim audit, the brand voice pass, the substantiation check on any performance number, and the disclosure decision. This is the layer that determines whether output at scale is an asset or a liability.
Once the two layers are separated, the procurement question changes. The manager stops asking "which service writes the best SEO articles" and starts asking "which draft engine costs the fewest review hours to bring to standard?" The editorial system stays constant. Draft engines get swapped in and out based on cost-per-reviewed-article, not cost-per-word. That distinction is what makes the model defensible to finance and durable when the underlying tools change every six months.
What the evidence actually says about AI and outsourced drafting quality
The accuracy range: from 30% wrong conclusions to 94.7% error-free notes
Before designing review controls, a content manager needs a defensible read on how often unreviewed drafts go wrong. Two peer-reviewed studies bracket the range, and the spread between them is the single most important number in this conversation.
At the cautionary end: a study comparing AI-generated and human-written structured abstracts in psychiatry reported that 30% of AI-generated abstract conclusions were factually incorrect, even though expert reviewers rated the abstracts as similar in quality to the human originals on several structural dimensions 3. The scope matters. This was psychiatric literature with specialized terminology and tight inferential logic, not general-interest SEO content. The number does not predict error rates on a product comparison article. It does establish that fluent, well-structured AI output can be wrong in its core claims roughly one time in three when the subject matter is technical.
At the optimistic end: a 2026 study of ambient listening generative AI used to draft clinical notes found that 94.7% of notes (337 of 356) were free from significant errors 5. That is the modern best-case scenario for AI drafting when the model is grounded in a specific, bounded input (in this case, a recorded patient encounter). Even so, the authors flagged that the residual error fraction carried risk of serious harm if uncorrected, and recommended building an efficient review process before deployment.
Read together, the two studies frame the operational range a content team must plan for: residual error rates between roughly 5% and 30% depending on subject complexity and how tightly the draft is grounded in source material. No production model can treat that range as acceptable shipping quality without a review layer. The question is not whether to review, but how much editor time the review costs — a calculation the unit-economics section returns to.
 Visualize the bracketed accuracy range from the two peer-reviewed studies cited in this section to make the operational planning range concrete
Visualize the bracketed accuracy range from the two peer-reviewed studies cited in this section to make the operational planning range concrete
Fluent is not accurate: what reviewers catch that readers miss
The harder failure mode is not the obvious error. It is the plausible one. NIST's text-to-text generation program describes the underlying capability bluntly: the goal is output that appears plausible and indistinguishable from human-produced content 8. Plausibility is the trap. A reader scanning an SEO article cannot tell whether a cited statistic exists, whether a quoted expert said what the draft claims, or whether a comparison reflects the actual product specs. An editor with the source documents open can.
Tone compounds the problem. A study comparing AI- and human-generated health messages found the AI versions were more positive in sentiment but rated slightly lower in clarity 4. Confident phrasing masks soft logic. Reviewers consistently catch three patterns that pass casual reads:
- invented citations attached to real-sounding journals,
- statistics that drift one digit during paraphrase, and
- category claims ("the leading approach," "most teams") with no underlying data.
The takeaway for production design is specific. A review pass cannot be a proofread. It has to verify every numerical claim against a named source, every quoted authority against a primary document, and every superlative against either evidence or deletion. That is the work the editorial system has to absorb regardless of whether the draft came from a freelancer, an agency, or a model.
Designing the editorial system: five quality gates that wrap the draft
The editorial system is a sequence of five gates a draft passes through before it reaches the CMS. Each gate has a defined input, a defined output, and a named owner. The gates are not optional steps to skip when a deadline is tight; they are the controls that distinguish a published article from a draft.
- Gate one: source grounding. Before drafting begins, the brief specifies the source documents the draft must be built from — internal data, named studies, primary interviews, product specs. A draft produced without a source list is rejected at intake. This is the input discipline that makes every downstream gate possible.
- Gate two: factual verification. Every numerical claim, named study, quoted authority, and product specification is checked against the source list. Harvard Business School's marketing policy permits AI to draft articles and ads only when humans proofread them for accuracy and quality 11. The University of Texas marketing communications guidance is more direct: all AI-generated content must be reviewed by a human before publication 13. The same standard applies to freelance and agency drafts.
- Gate three: brand voice calibration. A second editor reads the draft against three to five voice rules the team has codified — sentence length, prohibited phrases, point of view, evidence density. This is a separate pass from accuracy review, because the cognitive work is different.
- Gate four: claims substantiation. Any performance, capability, or comparative claim about a product, service, or outcome requires a documented evidentiary basis in the file. The FTC's 2023 compulsory-process authorization expanded investigative reach over AI-related products and services 9, and the 2024 enforcement sweep targeted companies using AI to amplify deceptive conduct 10. The editorial standard is to keep the substantiation file with the article.
- Gate five: disclosure decision. The team decides per asset whether to label AI involvement, based on evidence rather than reflex. Controlled research on AI-generated content labels found they minimally affect perceived accuracy, message credibility, or sharing intention while still helping readers distinguish AI from human content 2. Disclosure becomes a calibrated choice, not a default.
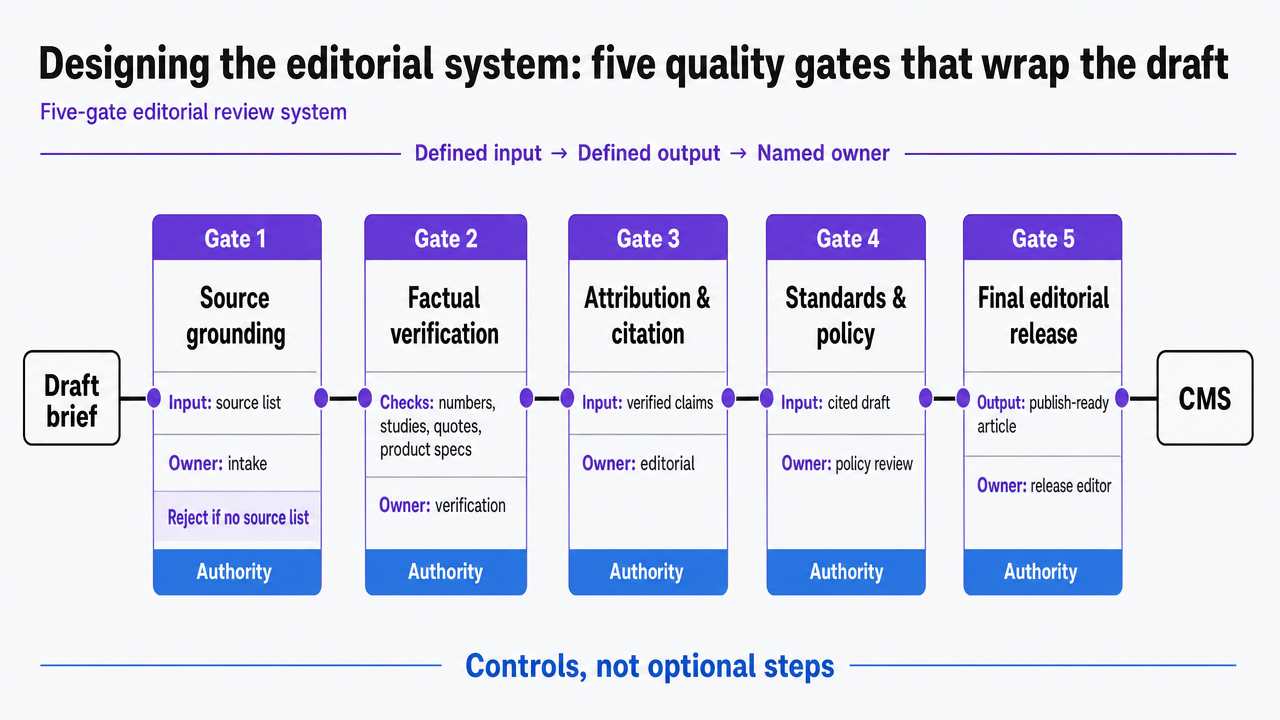 Process infographic visualizing the five sequential editorial review gates described in the section, each with its named control and cited authority
Process infographic visualizing the five sequential editorial review gates described in the section, each with its named control and cited authority
Test AI-Powered SEO Article Production Yourself
Experience real-time article delivery and measure SEO impact before making any commitment.
Source-grounded drafting: the input discipline that makes review possible
The review gates only work if the draft arrives with something to verify against. A draft built from a model's general training data, or from a freelancer's web searches at 11pm, gives the editor no audit trail. Every claim has to be re-researched from scratch, which is why review hours balloon and why teams quietly give up on quality control after the third deadline.
NIST's text-to-text evaluation program treats this as the central design question. Its summarization task generates output from roughly 25 source documents the system is given as input, and evaluation measures the result against those sources rather than against subjective taste 6. The principle transfers directly to SEO production: a draft is only as auditable as its source set.
The operational fix is to require a source pack with every brief. The pack lists the specific documents the draft must draw from — internal data exports, named studies with URLs, primary product documentation, recorded customer interviews, vendor specifications. Any statistic, quote, or capability claim in the returned draft must trace to a line in that pack. Claims without a source citation get cut, not researched.
This shifts editor work from forensic verification to comparison. Instead of asking "is this true," the editor asks "does this match the source?" That is a faster, more reliable task, and it works identically whether the draft engine is a freelancer, an agency, or a model.
Brand voice calibration without a style-guide bottleneck
Most in-house teams have a 40-page brand style guide that nobody reads. It is the wrong instrument for calibrating drafts at volume. A reviewer cannot hold 40 pages in working memory while reading a 1,500-word article, and freelancers or generative models cannot consistently apply rules they have to scroll through.
The fix is a one-page calibration sheet with three to five enforceable rules: average sentence length, banned phrases, point of view, evidence density per 500 words, and one or two structural defaults like "open with a specific operational problem, not a definition." Rules that cannot be checked in a single read get cut.
The calibration pass is also where reviewers catch tone drift that fluent drafts hide. AI-generated health messages were rated more positive in sentiment but slightly lower in clarity than human-written versions 4. The same pattern shows up in SEO drafts — confident phrasing that softens the underlying claim. Reviewers tighten verbs, cut category superlatives, and restore the directness the brand voice depends on. Run this pass separately from the accuracy gate. Combining them is what causes both to degrade under deadline pressure.
Claims, substantiation, and the FTC question most teams ignore
The riskiest sentences in an SEO article are not the technical ones. They are the unsourced performance claims that slip into product comparisons, capability descriptions, and category framing. Phrases like "the fastest," "trusted by leading brands," "reduces costs by half," or "the only platform that" all look like marketing color. The FTC treats them as advertising claims that need evidence behind them.
The enforcement posture sharpened in two stages. In late 2023, the FTC authorized compulsory process to streamline investigations involving products and services that use or claim to be produced using AI 9. A year later, the commission announced a coordinated sweep against companies using AI to amplify deceptive or unfair conduct that harms consumers 10. The signal to in-house teams is direct: claims about AI tools, AI-produced content, or any quantitative performance assertion sit inside an active enforcement perimeter.
The editorial control is a substantiation file kept with the article. Every comparative claim, statistic, customer outcome, and capability description lists the source document, the date, and the page or section it came from. If a freelancer or a model produces "cuts review time by 40%," the editor either attaches the study that supports it or cuts the number. This is the same standard a regulated advertiser applies to a TV spot, applied at article scale.
Scale SEO Content Production Without Compromising Brand Standards
Discover how leading marketing teams accelerate high-quality article output and maintain editorial control using AI-powered workflows designed for agency-scale SEO demands.
Disclosure as an operational choice, not a moral one
Disclosure tends to get framed as an ethics question, which is the wrong frame for an editorial decision that recurs 20 times a month. The frame that scales is evidentiary: what does the research actually show about how readers respond when AI involvement is labeled, and what does that mean for the asset on the desk today?
Two findings shape the calculation. A controlled study on AI-generated content labels found they minimally affect perceived accuracy, message credibility, or sharing intention while still helping readers distinguish AI from human content 2. MIT Sloan's summary of consumer perception research adds a second layer: when source is unknown, audiences often prefer AI-generated content, but once informed of the source, they show mild human favoritism without developing strong aversion to AI 15. Neither finding supports the assumption that disclosure tanks performance. Neither supports a blanket disclose-everything default either.
The operational rule is to set disclosure by asset class, not by content type. Articles that make first-person experiential claims, name a human author by byline, or quote that author as a subject-matter expert carry a higher disclosure obligation, because the AI involvement contradicts a representation already made to the reader. Reference and explainer content built from cited sources carries a lower one, because the article's authority rests on the citations, not on authorship. The team writes the rule down, applies it consistently across the calendar, and reviews it quarterly against any new evidence. That converts disclosure from a recurring debate into a single policy decision.
Unit economics: editor hours per published article across three models
The editorial-system argument only wins inside finance if it can be expressed as hours per published article. The variables that matter are small in number:
E : editor hourly rate
N : articles published per month
H : review hours per article
Everything else is noise.
A note on audience: this section briefly shifts scope to include agency operators and multi-location marketing leads, who run multiple editorial calendars in parallel and feel the hour math first. The same variables apply to a single in-house team; the multipliers just get larger.
Three production models cover most of the market.
| Production model | Draft cost per article | Review hours per article (H) | Monthly editor hours (N=20) | Residual error exposure |
|---|---|---|---|---|
| Fully outsourced human writers | Vendor rate | 1.5 to 2.5 | 30 to 50 | Variable by writer |
| AI-only, no review | Near zero | 0 | 0 | Up to ~30% factual error on technical claims 3 |
| AI-drafted + in-house review | Near zero | 2.0 to 3.5 | 40 to 70 | ~5% residual at best case 5 |
Two observations carry the model. First, the AI-drafted plus reviewed path does not save editor hours over outsourced human drafting — it often adds them, because source-grounding and claim verification take time the freelance arrangement quietly skips. Second, the AI-only path looks free until the residual error exposure is priced in. A 30% incorrect-conclusion rate is a peer-reviewed finding from psychiatric abstracts, not a general SEO benchmark 3, but even the modern best case sits near a 5% residual on tightly grounded drafts 5. Neither is acceptable shipping quality.
The defensible finance pitch follows Forrester's framing: deliver greater impact with fewer resources by prioritizing the assets that matter, not by maximizing raw volume 19. Reducing N from 20 to 12 high-priority articles, while holding H at the level the review gates require, almost always produces better organic pipeline contribution than publishing 20 lightly reviewed pieces. That is the trade leadership should be asked to make.
What to ask any service before signing: a draft-engine procurement checklist
By this point the procurement question is narrow. The team is not buying a writer. It is buying a draft engine that has to feed the editorial system at the lowest review cost per article. Six questions surface that information faster than a sales call.
- What source material will the draft be built from? A service that cannot name the inputs is selling general training data or unsupervised web search. Both inflate verification hours, since NIST's text-to-text evaluation principle — measure output against the source documents it was generated from — has no anchor to apply 6.
- How are numerical claims, quotes, and citations attributed? Ask for a recent sample with footnoted sources. No sample, no signature.
- What is the substantiation posture on product, performance, and comparative claims? The FTC's expanded compulsory process over AI-related products and services 9 and its 2024 enforcement sweep on deceptive AI conduct 10 sit on the publisher, not the vendor.
- How are revisions priced when factual rework is required? Rework billed at the original rate transfers risk back to the buyer.
- What disclosure does the service apply to its own output? Calibrate to the team's per-asset disclosure rule, not the vendor's default.
- Will the service work inside the team's source brief and voice sheet? A vendor that resists structured inputs is optimizing for its margin, not the team's editorial system.
 Incorrect conclusions in AI-generated psychiatric abstracts
Incorrect conclusions in AI-generated psychiatric abstracts
Incorrect conclusions in AI-generated psychiatric abstracts
Frequently Asked Questions
References
- 1.The impact of generative AI on social media: an experimental study.
- 2.Impact of Artificial Intelligence–Generated Content Labels On ... - PMC.
- 3.Quality and correctness of AI-generated versus human-written ....
- 4.Comparing AI and human-generated health messages in an Arabic ....
- 5.Quality of Clinical Notes Created by Ambient Listening Generative AI.
- 6.GenAI: Text-to-Text (T2T) - NIST AI Challenges.
- 7.2024 NIST Generative AI (GenAI): Evaluation Plan for Text-to-Text ....
- 8.NIST GenAI FAQ.
- 9.FTC Authorizes Compulsory Process for AI-related Products and ....
- 10.FTC Announces Crackdown on Deceptive AI Claims and Schemes.
- 11.Marketing AI Guidelines | About - Harvard Business School.
- 12.AI Marketing Guidelines | Harvard John A. Paulson School of Engineering and Applied Sciences.
- 13.AI Generated Content - University Marketing and Communications.
- 14.HOW DO PEOPLE REGARD AI-CREATED CONTENT?.
- 15.Study gauges how people perceive AI-created content.
- 16.AI-generated Versus Human-generated: Creative Content in ....
- 17.The economic potential of generative AI: The next productivity frontier.
- 18.The State of AI: Global Survey 2025.
- 19.The Definition Of “More From Less” In B2B Content Strategy And Operations.