
Key Takeaways
- Treat the brief as an operating contract that pre-commits strategic fit, search intent, trust signals, and a measurement metric — not as a topic outline with H2s and a keyword.
- Thin briefs produce expensive drafts: off-brief revisions, weak trust signals, unmeasurable output, and compounding rework, each traceable to a specific field the brief left ambiguous.
- Encode four layers in every brief — reader-in-context, intent anchored to Page Quality and Needs Met 12, authorship and sourcing rules, and a primary metric with benchmark and reporting window.
- Front-load human judgment into the brief before drafting, assign each asset to a single stage of the see-connect-trust-choose-champion framework 2, and audit templates quarterly against a closed revision loop.
The brief as an operating contract, not a topic summary
A content brief earns its keep when it functions as an operating contract between strategy, writers, and the business — not when it lists H2s and a target keyword. The distinction matters because every downstream cost of content operations, from revision cycles to weak trust signals to unmeasurable outcomes, traces back to what the brief did or did not commit to before a writer opened the document.
Google's helpful content guidance frames the standard bluntly: evaluators are directed to ask who created the content, how it was created, and why it was created, with trust named as the most important signal 1. A brief that cannot answer those three questions in its own fields is already leaking quality. The Search Quality Rater Guidelines reinforce the same point from the ranking side — raters exist to measure how people are likely to experience results, which means the brief has to encode the reader's experience, not just the topic's shape 11.
Treated as a contract, the brief pre-commits four things: the strategic fit of the asset, the search intent it must satisfy, the trust signals it will carry, and the metric that proves it worked. Every field maps to a specific failure it prevents. Every omission shows up later as a revision, a rewrite, or a piece of content that ships but cannot be defended against a business question.
Why briefs fail: the four downstream costs of thin inputs
Thin briefs do not produce thin drafts. They produce expensive ones. Every field a brief leaves ambiguous gets resolved later — by a writer guessing, an editor rewriting, or a manager defending a piece of content that never had a clear job to begin with. Four costs show up consistently, and each traces to a specific missing input.
The first cost is off-brief drafts that trigger revision spirals. When strategic fit is left implicit, writers default to topic coverage, which peer-reviewed work on content marketing effectiveness identifies as a weak proxy for what actually drives outcomes — the fit between the asset, the audience context, and the business goal 6. Revisions in this scenario are not craft improvements; they are strategy negotiations happening inside a draft.
The second cost is weak trust signals. Briefs that omit authorship, sourcing standards, and originality requirements ship content that cannot answer Google's who-how-why prompts, the exact questions its helpful content guidance directs evaluators to ask 1. The draft may read cleanly and still fail the standard raters are trained to apply to Page Quality 12.
The third cost is unmeasurable output. Marketing analytics research repeatedly flags the difficulty of attributing content to outcomes when success criteria are set after publication rather than before 8. A brief that skips the metric field guarantees a reporting problem three months later.
The fourth cost is compounding rework. Forrester's survey of content platform users frames this as an efficiency problem, not a production one — the waste sits upstream, at the point where inputs were never specified 10. Each thin brief pays that tax again.
The four layers every scaled brief must encode
Layer one: strategic fit and reader specificity
Strategic fit is the field most briefs skip and most drafts pay for. Peer-reviewed work on content marketing effectiveness finds that outcomes are driven by contextual fit between the asset, the audience situation, and the business goal — not by topic completeness 6. A brief that names only the topic gives the writer permission to cover it; a brief that names the fit tells the writer what has to change in the reader's decision after they finish.
Two brief fields carry this layer. The first is the reader-in-context field: not a persona sketch, but the specific decision moment the asset is written for — the vendor comparison stage, the mid-implementation troubleshooting stage, the post-purchase retention stage. The second is the strategic role field: whether the asset is meant to earn organic entry, defend a category term, support a sales conversation, or move an existing lead one stage forward. These are separate commitments, and drafts drift when they collapse into a single vague goal.
Applied research on structured content planning shows the same pattern in an operational setting: assets built inside a structured planning environment outperform those produced from ad-hoc topic assignments 7. Strategic fit is the field that turns a brief from a writing prompt into a placement decision.
Layer two: search intent anchored to rater criteria
Search intent belongs in the brief, but not as a keyword and a SERP screenshot. It belongs as a set of commitments a human evaluator would recognize. Google's rater program exists to measure how people are likely to experience results, and the detailed guidelines organize that measurement along two dimensions: Page Quality and Needs Met 12. Briefs that encode intent field-by-field against those two dimensions produce drafts that survive both algorithmic and human review.
Page Quality maps to four brief fields. Purpose names why the page exists for the reader, not for the site. Main content quality specifies the depth, originality, and evidence expected in the body — not a word count, but a bar. Expertise identifies the credentialed author or reviewer whose name appears on the page. Reputation captures any external signal the brief expects the asset to earn or link to, from cited primary research to named practitioner quotes.
Needs Met maps to three more fields. The dominant query interpretation names the single search job the asset resolves. Secondary interpretations list adjacent jobs the asset should handle without diluting the primary one. The failure mode field is the sharpest field in this layer: it states, in one line, the reader experience that would cause a rater to mark the page as not meeting the need. Writers who see that field before drafting rarely produce it.
Anchoring intent to rater criteria has a second effect. It gives editors a defensible standard for rejection. A draft that misses the expertise field is not rejected on taste; it is rejected against a published external standard 11. That distinction compresses revision cycles, because the negotiation shifts from opinion to specification.
Layer three: the trust layer — authorship, sourcing, originality
Trust is a brief field, not a brand outcome. Google's helpful content guidance names trust as the most important signal and directs evaluators to ask who created the content, how it was created, and why it was created 1. A brief that cannot answer those three questions in its own inputs is shipping trust risk into production.
Four fields carry the trust layer. The byline field names the credited author and the reviewer, with the reviewer being a subject-matter expert whose credentials appear on the page. The credentials field lists the specific expertise signals — licensure, years in practice, published work — that will appear near the byline or in a bio module. The sourcing rule field states the evidence standard the draft must meet: primary sources for statistics, named practitioners for operational claims, and a documented method for any comparison. The originality field commits the writer to a specific contribution — an internal dataset, a first-hand observation, a synthesis not available in the top ten results — rather than a paraphrase of existing coverage.
The 2026 Audience Trust Index frames why these fields have gained weight: in an AI-driven search environment, audience trust is now measured as a performance dimension, not assumed as a byproduct of good writing 4. Briefs that leave trust implicit produce drafts that read competently and still underperform against readers and evaluators who are actively looking for authorship and sourcing signals. Making the trust layer explicit at the brief stage is the cheapest place to install it — every later stage costs more and defends less.
Layer four: the measurement contract before the first draft
The measurement contract is the field that ends the argument three months later. It names the metric the asset will be judged on, the benchmark that defines success, and the reporting window that closes the evaluation. Briefs without this field guarantee a reporting problem, because marketing analytics research consistently finds that outcomes set after publication are the hardest to attribute and the easiest to dispute 8.
The B2B Content Marketing Report grounds which metrics belong in the contract. It identifies conversions, lead quality, and website engagement as the metrics B2B marketers rely on most to evaluate content performance 5. A brief that commits to one of those three as the primary metric — and names a secondary supporting metric — gives editors and analysts a shared endpoint. A brief that lists five metrics commits to none.
Three fields make the contract operational. The primary metric field names the single outcome the asset is accountable for, chosen from the metric set the team already reports on. The benchmark field states the expected value: a comparison against a prior asset in the same cluster, an industry benchmark the team has documented, or a baseline cost the team has calculated. CMI's essential measurement guide is explicit that establishing baselines and benchmarks before publication is what allows monthly tracking to produce a signal rather than a report 3. The reporting window field closes the loop by naming when the asset will be reviewed — thirty days for engagement-led assets, ninety days for conversion-led assets, longer for retention-oriented pieces.
The contract has a secondary function: it disqualifies briefs that cannot commit to one. An asset that no one will measure is an asset no one will defend, and the brief stage is where that decision costs the least. Editors who reject briefs on missing measurement fields — before a writer is assigned — protect the team's capacity for the assets that carry a defensible outcome.
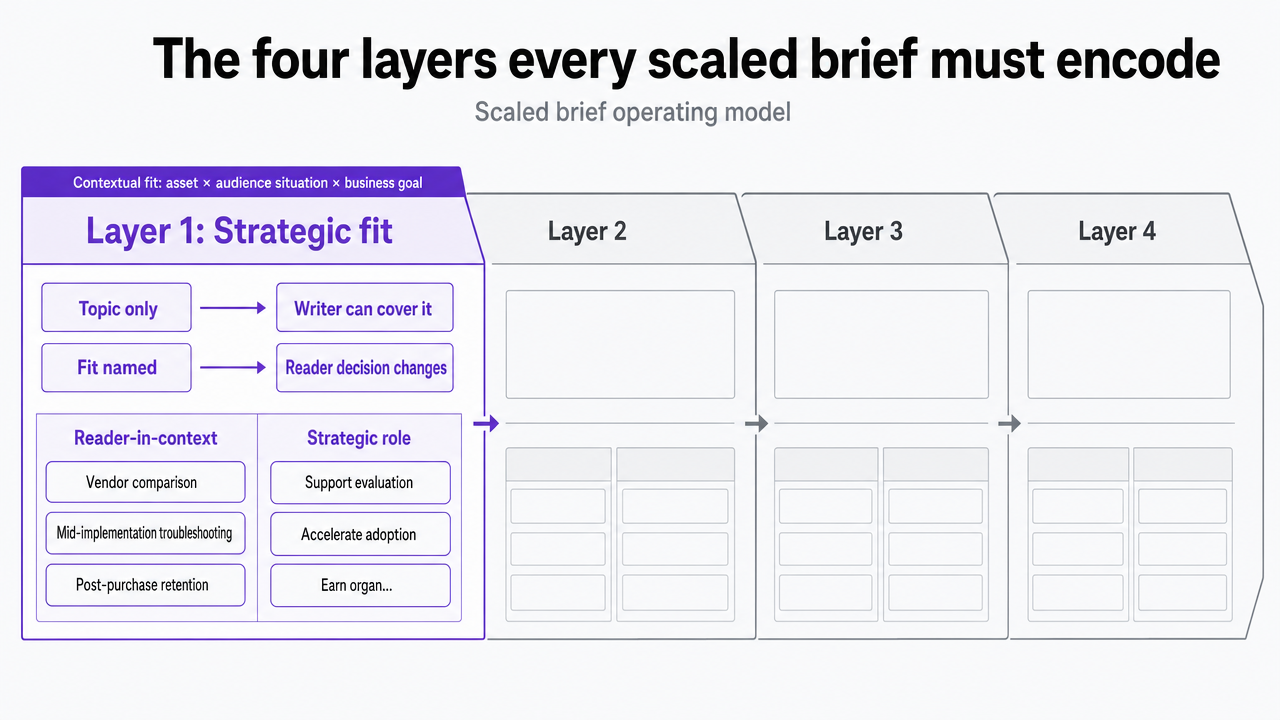 Visualize the four-layer framework that structures every scaled brief, directly supporting the section's core operating model
Visualize the four-layer framework that structures every scaled brief, directly supporting the section's core operating model
Test AI-powered content briefs on live campaigns
Create, approve, and publish high-quality content using AI-generated briefs before making any commitment.
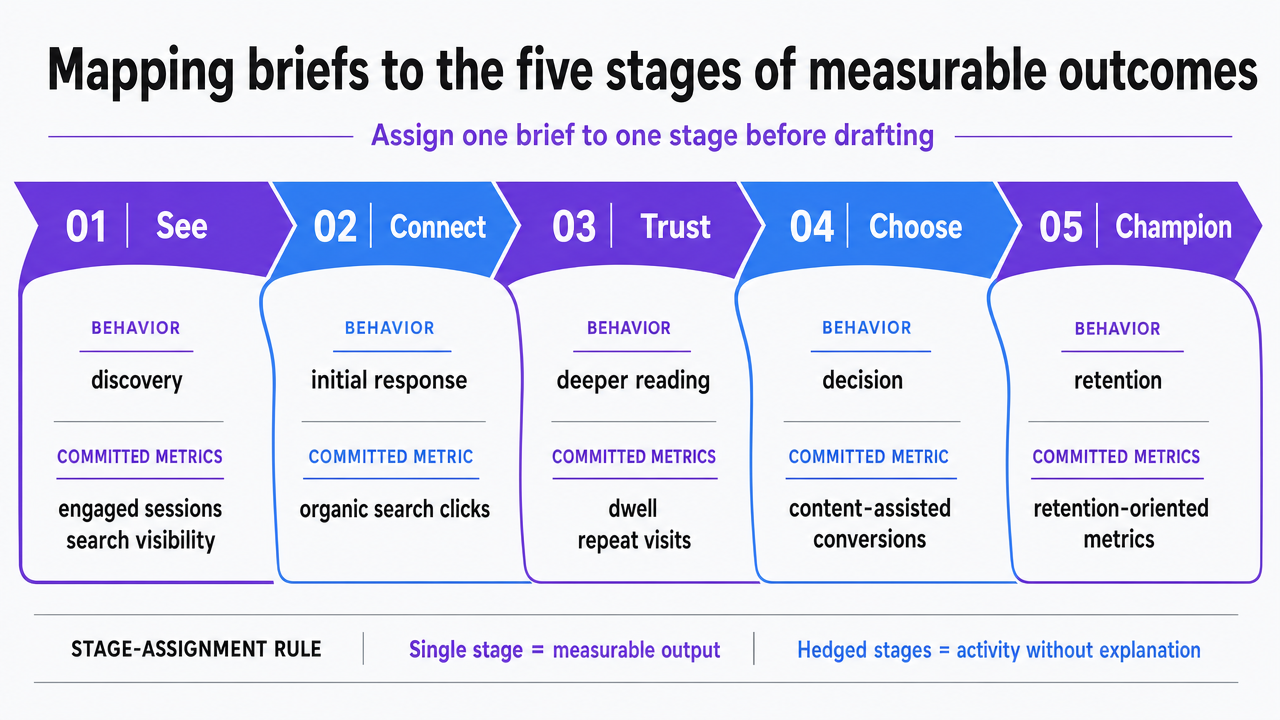
Mapping briefs to the five stages of measurable outcomes
A measurement contract inside a brief is only useful if the metric it names sits at the right stage of the reader's journey. CMI's measurement framework organizes that journey into five stages — see, connect, trust, choose, and champion — and pairs each stage with indicators that reflect what the reader is actually doing at that point: engaged sessions and search visibility for see, organic search clicks for connect, dwell and repeat-visit signals for trust, content-assisted conversions for choose, and retention-oriented metrics for champion 2. Briefs that assign an asset to a single stage before drafting produce measurable output. Briefs that hedge across stages produce reports that describe activity without explaining it.
The assignment rule is narrow.
- A see-stage brief commits to search visibility and engaged sessions as the primary and secondary metrics, and it accepts that conversion counts are not the evaluation window.
- A connect-stage brief commits to organic search clicks and click-through behavior against the target query set.
- A trust-stage brief commits to depth-of-engagement signals — return visits, scroll completion on evidence-heavy sections, secondary asset consumption — and names the trust field from layer three as the input that produces those signals.
- A choose-stage brief commits to content-assisted conversions and lead quality, which the B2B Content Marketing Report identifies as two of the three metrics teams most rely on 5.
- A champion-stage brief commits to retention indicators — logged-in revisits, customer-referenced shares, community citations — that only existing customers can produce.
Stage assignment also disciplines the editorial calendar. Marketing analytics research finds that teams struggle most when a single asset is expected to satisfy multiple attribution windows at once 8. Assigning one stage per brief closes that window before it opens.
 Visualize the see-connect-trust-choose-champion journey with the specific metric committed at each stage, directly supporting the section's stage-assignment rule
Visualize the see-connect-trust-choose-champion journey with the specific metric committed at each stage, directly supporting the section's stage-assignment rule
Where AI-assisted production is safest: front-loading judgment into the brief
AI-assisted drafting fails when it inherits ambiguity. The failure mode is predictable: a writer or a model given a topic and a keyword produces plausible prose, an editor spends the revision cycle relitigating strategy inside the draft, and the finished asset carries none of the trust signals a human evaluator would recognize. The point of leverage is upstream. When judgment is front-loaded into the brief, AI becomes a production accelerant rather than a strategy substitute.
Google's helpful content guidance is explicit that how content is created is one of the three questions evaluators are directed to ask, and that automation in production has to be assessed against reader usefulness, not disclosed as an end in itself 1. That framing places the burden on the brief, not the drafting tool. If the brief already commits to the reader-in-context, the dominant query interpretation, the failure mode, the byline, the sourcing rule, and the primary metric, a model has almost no room to drift. If the brief commits to none of those, the model will drift by default — and a human writer will too.
The efficiency case is what makes this the safest insertion point. Forrester's survey of content platform users frames content operations as an efficiency-outcomes problem, with the waste concentrated upstream at the input stage rather than at the drafting stage 10. Applied research on structured planning environments shows the same pattern: assets produced from structured inputs outperform those produced from ad-hoc assignments, regardless of who or what does the drafting 7.
Two operator rules follow.
- Spend more editorial minutes on the brief than the team currently spends on revisions — the trade is one-for-one in the other direction, and the revision minutes disappear.
- Do not let AI generate the brief fields that carry strategic commitment: the reader-in-context, the failure mode, the byline, the primary metric. Those are the human judgments the rest of the system compounds.
AI belongs in draft acceleration, variant production, and formatting compliance, working against a brief a manager has already signed.
See How Structured Content Briefs Multiply Output Without Sacrificing Quality
Connect to discuss data-driven workflows that streamline content briefing, reduce revisions, and enable your team to publish more high-impact assets per quarter—without adding new writers.
If you manage multiple locations or a client portfolio
The master brief plus location variables model
Managers running content across multiple locations, franchise networks, or a client portfolio face a different operating problem than single-brand teams. The strategic work — reader-in-context, dominant query interpretation, trust layer, primary metric — is largely shared across locations that share a service line. What changes is a narrow set of variables: geography, practitioner names, licensure specifics, service availability, local proof points, and a handful of intent modifiers that shift by market. Rebuilding the full brief for each location repeats strategy work that has already been paid for.
The master brief plus location variables model separates the two. A master brief carries every field from the four layers — strategic fit, search intent anchored to Page Quality and Needs Met 12, the trust layer, and the measurement contract — as fixed inputs for the service line. A location variables sheet carries only the fields that must change per market: the local byline and credentials, the location-specific proof points, the geographic query modifier, and any regulated language variants. Writers or drafting models receive the merged output, not two documents.
The model has a governance benefit. When a rater-aligned standard is set once at the master level, every location inherits it 11, which closes the drift that appears when each market rewrites its own strategy without a shared bar.
Economics of brief reuse across a portfolio
Portfolio economics turn on how many times a single strategic decision gets reused before it needs to be remade. The master brief is the reuse unit. Its cost is paid once per service line; the per-location cost drops to the variables sheet plus a light editorial pass.
The table below uses operator variables only. Teams can populate their own values against a documented baseline, which is the input CMI's measurement guide identifies as the prerequisite for calculating content ROI at scale 3.
| Variable | Per-location build | Master brief plus variables |
|---|---|---|
| Editorial hours per brief | Full brief hours × locations | Master hours + variables hours × locations |
| Briefs per location per month | N | N, sharing the master |
| Strategy decisions remade | Every location, every asset | Once per service line |
| Revision cycles per asset | Location-specific negotiation | Variables-only clarification |
Forrester's survey of content platform users frames the same efficiency case at the portfolio level: the waste sits upstream, in inputs that are rebuilt rather than reused 10. Portfolio operators who install the master-plus-variables model recover editorial capacity without adding writers, and the recovered capacity moves toward the assets that carry a defensible measurement contract.
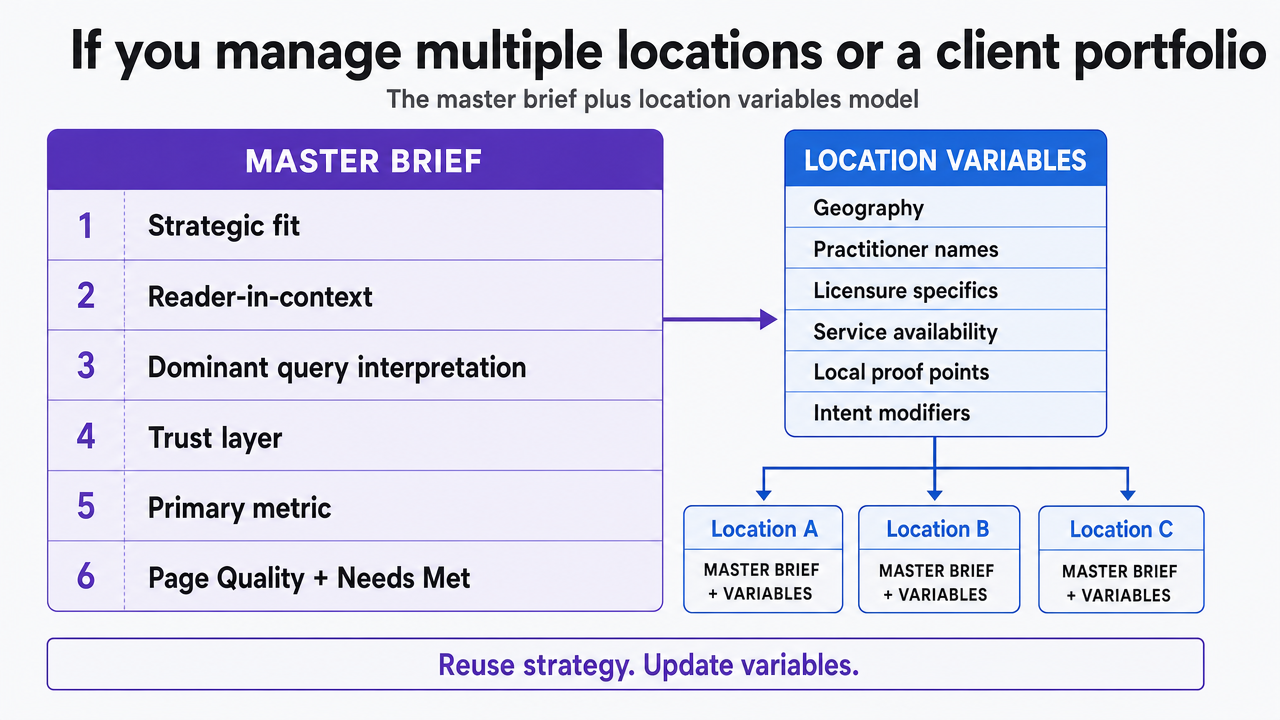 Visualize the master brief plus location variables operating model described in the section, showing how strategic fields are reused and only variables change per location
Visualize the master brief plus location variables operating model described in the section, showing how strategic fields are reused and only variables change per location
Running briefs as a system: cadence, audits, and revision loops
A brief template that ships in January and never gets touched again decays inside a quarter. Search intent shifts, rater guidance updates, metric definitions change, and the trust fields that mattered last year become table stakes this year. Managers who treat the brief as a living system — with a scheduled cadence, a documented audit, and a closed revision loop — protect the leverage every earlier section describes.
Cadence has three moving parts. Individual briefs move on the reporting window their measurement contract names — thirty days for engagement-led assets, ninety for conversion-led ones. The template itself moves on a quarterly review, timed to whatever rater guidance or helpful content updates Google has published in the interim 1, 12. The metric set inside the template moves on the same monthly reporting cadence CMI recommends as the baseline for content measurement, so the fields the brief commits to match the fields the team is actually pulling in reports 3.
The audit is narrow and mechanical. Editors sample five briefs per service line each quarter and score them on four checks:
- Did the brief name a single stage from the see-connect-trust-choose-champion framework 2?
- Did the trust fields produce the authorship signals that shipped?
- Did the draft need revisions the brief could have prevented?
- Did the primary metric report against its benchmark?
The output is a short list of template fields to sharpen, not a scoring exercise.
The revision loop closes the system. Every revision request logged against a shipped draft gets tagged to the brief field that failed — strategic fit, intent, trust, or measurement. Fields that fail twice in a quarter get rewritten in the master template before the next cycle. That single discipline is what turns briefs from a documentation habit into a compounding asset.
Frequently Asked Questions
References
- 1.Creating helpful, reliable, people-first content.
- 2.5-Step Content Marketing Measurement Framework.
- 3.How to Measure Content Marketing: The (Updated) Essential Guide.
- 4.Content Marketing Measurement in 2026: The Audience Trust Index.
- 5.The 2023 B2B Content Marketing Report.
- 6.Determinants of content marketing effectiveness: Conceptual ....
- 7.Evaluating the Effectiveness of Digital Content Marketing Under ....
- 8.A qualitative analysis of the marketing analytics literature.
- 9.Conceptualising and measuring social media engagement.
- 10.Brief: Marketing And Media Efficiency Outcomes Drive Content ....
- 11.Search Quality Rater Guidelines: An Overview.
- 12.General Guidelines.