
Key Takeaways
- Airtable repairs planning drift by treating the content pipeline as a relational database, keeping briefs, owners, and approval states linked so calendar and actual work stay aligned.
- Notion closes the review bottleneck by collapsing brief, draft, comments, and approval log onto one page, shortening feedback loops when teams enforce sign-off at each status.
- Bynder contains asset sprawl through structured metadata, version control, and expiration dates, making findable, governed assets a first-class primitive rather than an optional tag.
- Contentful preserves taxonomy at scale with typed content models and controlled vocabularies, so schema outlives its creator and new hires learn structure instead of tribal knowledge.
- Sprout Social handles cross-channel handoff by routing approved assets through multi-step review before scheduling, reducing rewrites when writers publish across three or more channels.
- Writer holds brand voice under AI drafting by enforcing style rules, term lists, and prohibited phrases as runtime constraints on every draft, human or machine-generated.
- Vectoron acts as an execution layer across content, SEO, PPC, backlinks, social, and calls, where AI proposes and humans approve before anything ships 3.
Why content stacks break at the seams
Most content teams do not fail at writing. They fail at handoffs. A brief lives in Asana, the draft in Google Docs, SEO notes in Notion, approved copy in a CMS staging environment, and the finished asset in Dropbox. Each surface is fine in isolation, but the seams between them kill cadence.
This pattern shows up predictably:
- Planning drifts because calendars are separate from briefs.
- Reviews stall because comments scatter across multiple tools.
- Assets sprawl because tagging is optional.
- Taxonomy decays when its owner leaves.
- Cross-channel repurposing becomes rewrites because the source of truth is ambiguous.
- Brand voice slips as AI drafting enters the mix without guardrails.
- And nothing closes the loop from published piece back to the strategy that requested it.
A Pennsylvania state pilot found employees using AI most effectively when it augmented human expertise rather than replaced it 9. This finding is crucial: the tools worth evaluating route work through human approval, not those promising hands-off automation. The seven picks below are grouped by which specific seam each one repairs, scored against a consistent rubric, and named for their strengths and weaknesses.
The four-part rubric behind the seven picks
Every tool in this list is scored against the same four dimensions. This rubric provides a shared vocabulary for what "better" means when evaluating a new platform against existing tools like Google Docs, Notion, or Asana, which vendor marketing pages often lack.
Governance : Measures how the tool routes work through human approval before anything ships. This is the primary axis because CMS has stated that AI tools should support, not substitute for, human decisions and oversight 2. A content platform that allows AI-drafted copy to publish without a named approver fails this test. The NIST AI Risk Management Framework organizes trustworthy AI around four functions—govern, map, measure, and manage—and content tools that mirror these functions in their approval loop score higher 1.
Reusability : Measures whether assets carry taxonomy that survives team turnover. This includes tags, metadata, canonical source flags, and search functionality that accurately returns the correct version, unlike simple folder trees.
AI role : Measures whether AI functions as a draft assistant within a document or as an execution layer that acts on approved recommendations across channels. Both are legitimate, but they solve different problems.
Headcount impact : Measures whether the tool absorbs coordination work—like briefing, status chasing, and handoff notes—or adds another surface someone has to maintain. A platform requiring a dedicated admin to configure workflows quarterly would have a negative score here.
Each of the seven tools below receives a one-line score on all four dimensions, plus an honest weakness.
 Visualize the four evaluation dimensions used to score every tool in the article, giving readers a mental model before the individual reviews
Visualize the four evaluation dimensions used to score every tool in the article, giving readers a mental model before the individual reviews
Airtable: fixing planning drift
Planning drift occurs when the editorial calendar and actual work diverge. A brief promised in January slips to February, and by March, its status is forgotten. The symptom is status meetings solely dedicated to reconciling the calendar with writer activities.
Airtable excels by treating the content pipeline as a relational database rather than a spreadsheet. Each content piece is a record with linked fields for owner, target keyword, funnel stage, channel, due date, and approval state. Views filter this data by team, quarter, or campaign without duplicating rows. When a brief's status changes, all dependent views update automatically.
Governance: Moderate. Airtable supports named approvers and status fields, but the approval logic is admin-built. It records sign-off rather than enforcing it, aligning with the CMS position that AI and automation should support human decisions 2, provided the team integrates the approval field as a gate.
Reusability: Strong. Linked records ensure a repurposed asset points back to the source brief, not a copy.
AI role: Draft assistant. Airtable AI summarizes fields and generates short copy within records but does not act across channels.
Headcount impact: Neutral to positive, depending on admin discipline. A well-configured base absorbs status work; a poorly configured one adds maintenance overhead.
Honest weakness: Airtable does not inherently define a good brief. Teams adopting it without an editorial standard may end up with an organized version of the same planning drift.
Notion: closing the review bottleneck
Review is where most content pipelines slow significantly. A draft goes out for feedback, and comments scatter across Google Docs, PDFs, and Slack. By the end of the week, the writer reconciles multiple conflicting versions. The bottleneck is not the reviewers, but the number of surfaces involved.
Notion addresses this by collapsing the draft, brief, comment thread, and approval log into one page. Blocks handle structured briefs, the draft sits below, inline comments resolve or persist, and a status property gates progress. Reviewers see the strategic rationale alongside the copy, shortening the feedback loop.
Governance: Moderate to strong. Page history and comment resolution create a traceable record, aligning with demands for reproducibility and explainability in early AI workflow guidance 6. Approvals still depend on the team defining sign-off at each status.
Reusability: Moderate. Databases and relations work, but Notion search degrades with large workspaces. Tagging discipline is key for finding past briefs.
AI role: Draft assistant. Notion AI summarizes threads and drafts within a page but does not route work across channels.
Headcount impact: Positive when the workspace is well-architected and enforced. Negative if every team builds its own template.
Honest weakness: Notion requires significant configuration and punishes casual use. Teams treating it as a shared doc tool may replicate review sprawl within a prettier interface.
Test AI-powered content workflows in real time
Experience accelerated content production and publish live assets during your complimentary trial—no waiting or commitment required.
Bynder: containing asset sprawl
Asset sprawl occurs when the same logo exists in multiple folders, some outdated, leading writers to pick incorrect versions. This problem compounds with each campaign. A product photo reused across channels often has different crops, color grades, and file names. Legal issues arise when outdated disclaimers are embedded in widely used images.
Bynder, a digital asset management platform, prevents this scenario. Assets carry structured metadata—campaign, channel, expiration date, approval state, usage rights—and search returns the current approved version. Version control is enforced. When a file is retired, references to it are flagged downstream. The NIST Manage playbook recommends storing documentation in an organized, secure, and accessible repository with continuous monitoring 5. This principle applies directly to creative assets: findable, governed, and reviewed assets are superior to a shared drive with good intentions.
Governance: Strong. Approval states, usage rights, and expiration dates are first-class fields, not optional tags.
Reusability: Strong. Structured metadata and taxonomy templates ensure predictable asset retrieval across teams.
AI role: Draft assistant. Auto-tagging and visual search speed retrieval; the platform does not act across channels.
Headcount impact: Positive at scale, negative below it. A team publishing 20 assets monthly will feel the overhead, while a team managing thousands across regions will save time.
Honest weakness: Bynder is priced and configured for organizations that treat brand assets as governed inventory. Smaller content teams often find the setup cost prohibitive and revert to Drive.
Contentful: taxonomy that survives scale
Taxonomy decay is a slow failure. A team ships content with clean tags initially, but over time, schema revisions lead to multiple versions with different field names and no clear canonical. The content remains, but the structure that made it findable is lost.
Contentful is a headless CMS built around content models. Every asset is an instance of a defined type—article, product spec, testimonial, glossary entry—with required fields, controlled vocabularies for tags, and references between records. Schema changes apply across existing entries, preventing old and new formats from coexisting. This discipline ensures taxonomy survives team turnover, as the model outlives its creator. This structural benefit is particularly important for regulated industries. Harvard Law School's Center on the Legal Profession views knowledge management as capturing best practices, onboarding new staff, identifying experts, and transferring knowledge 10. A headless model with typed content and named owners concretizes these functions, allowing new hires to learn from the schema rather than tribal knowledge.
Governance: Moderate to strong. Roles, environments, and publish permissions are granular. Approval workflows exist but require configuration; content is not gated until the team wires the gate.
Reusability: Strong. Typed content and API-first delivery mean the same entry can power a website, app, and email without duplication.
AI role: Draft assistant. AI features generate and translate field content; the platform does not orchestrate work across channels.
Headcount impact: Positive at scale, but front-loaded. Proper content modeling takes weeks, a cost incurred before time is recovered.
Honest weakness: Contentful assumes developer support for the content team. Marketing managers needing to change fields, add content types, or adjust taxonomy often face engineering tickets, slowing agility.
Sprout Social: cross-channel handoff without rewrites
When a blog post is published, social media leads often rewrite intros for LinkedIn, community managers trim quotes for Twitter, and paid media teams question image consistency. Nothing is truly reused; each channel starts over from the same source material, producing slightly different messages.
Sprout Social integrates the social calendar as a downstream extension of the content pipeline. Assets flow from the CMS or DAM with metadata intact. Approval chains route posts through legal, brand, or executive review before scheduling. Publishing queues distribute approved copy across LinkedIn, Instagram, Facebook, and X, with channel-specific formatting handled by the platform, not the writer.
Governance: Strong. Multi-step approval workflows, message rejection with comments, and audit logs of who published what and when. This trail aligns with the reproducibility and explainability flagged as essential in early AI workflow feedback 6.
Reusability: Moderate. The asset library holds approved copy blocks and creative but does not replace a proper DAM for large image and video inventories.
AI role: Draft assistant. Suggestions for post copy and optimal send times are available within the composer.
Headcount impact: Positive for teams publishing across three or more channels. Neutral for single-channel operations.
Honest weakness: Sprout Social handles outbound well but does not reach back into the drafting environment. The rewrite problem shrinks but does not disappear until the CMS and social tool share the same source of truth.
Writer: holding brand voice under AI drafting
Brand voice slips quickly when AI drafting enters the workflow without guardrails. Different AI models or prompts used by various writers lead to inconsistent drafts. Editors then spend more time normalizing tone than fixing structure, negating efficiency gains.
Writer is a generative AI platform built around enforced style rules. Teams upload a voice guide, term list, and prohibited-phrase library. The platform checks every draft—human or AI-generated—against these rules before it leaves the editor. Suggestions surface inline, and violations are flagged before publication. The style guide becomes a runtime constraint rather than an unread PDF. This design aligns with regulatory patterns. The FDA's internal generative AI tool, Elsa, functions as a productivity layer within defined guardrails, not a replacement for review 8. Writer adopts a similar stance: AI accelerates drafting, but the voice model gates acceptable output.
Governance: Strong on voice, moderate on workflow. Style enforcement is primary; multi-step editorial approval depends on integrations with the CMS or project tool.
Reusability: Moderate. Approved snippets, boilerplate, and term definitions are stored centrally and surface during drafting.
AI role: Draft assistant with policy enforcement. It generates copy and audits copy generated by others.
Headcount impact: Positive for teams with multiple writers or vendors. Editors save hours previously spent on tone reconciliation.
Honest weakness: Writer's guardrails are only as effective as the voice model provided. Vague style guides result in vague enforcement, and the platform cannot fix an unwritten editorial standard.
See How Leading Brands Streamline Content Workflows with AI Coordination
Request a tailored walkthrough of unified workflow automation, real-time approvals, and integrated content organization built for complex, high-velocity teams.
Vectoron: the execution layer for approvals across channels
While the previous six tools address specific pipeline stages, Vectoron operates across all of them. It functions as an execution layer that reads live business signals, prioritizes work, drafts recommendations, and routes every item through a human approver before shipping. Content is one of six channels, alongside SEO, PPC, backlinks, social, and call intelligence, with a consistent approval log regardless of the target channel. This approach aligns with federal guidance. The GSA AI Guide frames any AI program's test as enhancing business unit ability and supporting practitioner effectiveness 3. An execution layer that surfaces ranked recommendations without removing editor sign-off satisfies both criteria. The Command Center manages the queue; the human manages the gate.
Governance: Strong. Approval is the default state, not a configurable option. Every recommendation includes the strategic reasoning behind it, addressing reproducibility and explainability, which were highlighted as essential in early AI workflow feedback 6.
Reusability: Moderate to strong. Approved assets carry channel-agnostic metadata, ensuring a blog post, paid ad variant, and social thread share source-of-truth copy rather than requiring parallel rewrites.
AI role: Execution layer, not draft assistant. AI proposes; humans approve; the platform executes and measures.
Headcount impact: Positive. Coordination work between strategy, production, and publishing collapses into one loop.
Honest weakness: Vectoron is designed for teams willing to work through a governed queue. Content managers who prefer ad-hoc drafting in a shared doc may find the approval-first model more rigid than a Notion page.
Scoring the seven side by side
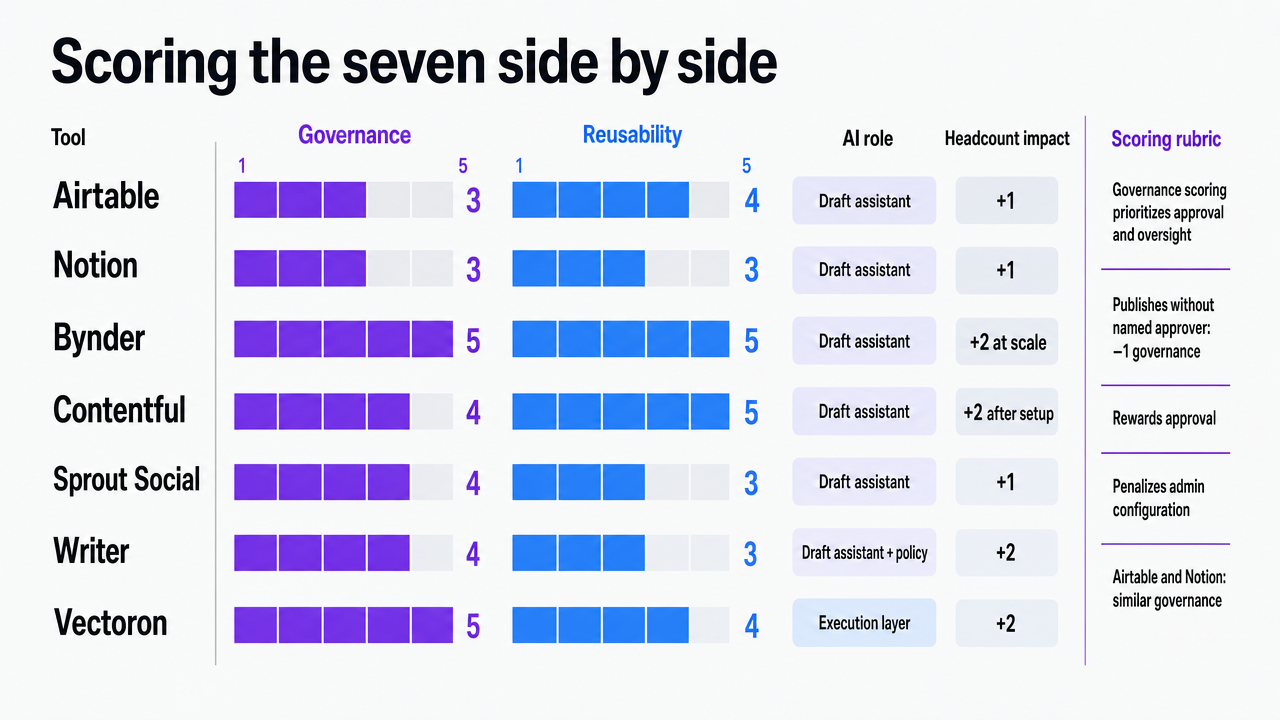
The table below matches each tool to the symptom it addresses. Scores are relative, reflecting performance against the four-part rubric for an in-house team of four to twenty. Governance scoring prioritizes the CMS mandate: AI supports, not substitutes for, human decisions and oversight 2. A platform that publishes without a named approver loses a full point, regardless of drafting speed.
| Tool | Governance | Reusability | AI role | Headcount impact |
|---|---|---|---|---|
| Airtable | 3 | 4 | Draft assistant | +1 |
| Notion | 3 | 3 | Draft assistant | +1 |
| Bynder | 5 | 5 | Draft assistant | +2 at scale |
| Contentful | 4 | 5 | Draft assistant | +2 after setup |
| Sprout Social | 4 | 3 | Draft assistant | +1 |
| Writer | 4 | 3 | Draft assistant + policy | +2 |
| Vectoron | 5 | 4 | Execution layer | +2 |
This matrix rewards tools that prioritize approval and penalizes those that rely on admin configuration. Airtable and Notion score similarly on governance because they record, rather than enforce, sign-off. Bynder, Writer, and Vectoron score highest as approval logic is a core primitive. The reusability column differentiates repositories from execution surfaces: Bynder and Contentful manage structured inventories, Sprout Social and Writer handle operational snippets, and Vectoron carries channel-agnostic metadata across its six execution channels.
No single tool excels in every column, which underscores the rubric's purpose.
 Translate the scoring table into a visual comparison so readers can scan governance and reusability scores across all seven tools at a glance
Translate the scoring table into a visual comparison so readers can scan governance and reusability scores across all seven tools at a glance
If the operator runs multiple locations
This section addresses content managers operating across multiple locations, such as law firm branches, DSO practices, home services franchises, or senior living communities. At this scale, coordination complexity increases, and the number of tools typically needs to shrink rather than grow.
A common pattern involves one planning tool per region, a shared document environment, a project manager per brand, a corporate-maintained DAM, and a bolted-on legal review tool. Each location adds seats to five surfaces, and each new channel adds another. The Harvard Law School piece on knowledge management highlights the underlying failure: capturing best practices, onboarding new staff, and transferring expertise breaks down when the number of surfaces exceeds the number of people 10.
| Cost driver | Best-of-breed stack | Execution-layer stack |
|---|---|---|
| Planning tool seats | Per user, per location | Per user, unified |
| Doc tool seats | Per user, per location | Included |
| PM tool seats | Per user, per brand | Included |
| DAM seats | Per admin, corporate only | Included |
| Review tool seats | Per approver | Included |
| Channels covered | Content only | Content + SEO + PPC + social + backlinks + calls |
The critical variable is not price per seat, but how many surfaces multiply by the location count.
How to run a 30-day evaluation before switching stacks
Tool switches often fail due to rushed procurement rather than poor products. A 30-day evaluation focused on one real workstream is more effective than a full team-wide pilot. The goal is to determine if the platform absorbs coordination work that the current stack struggles with, not to prove its theoretical functionality.
- Week one: Select a single production track and freeze its scope—one channel, one campaign, three to five pieces. Document the current cycle time from brief to publish and the number of tool surfaces each piece touches. This baseline will be used to measure the new platform's performance.
- Week two: Run the same track within the candidate tool. Route every draft through named approvers, avoiding ad-hoc Slack sign-offs. The NIST AI RMF Playbook advises building trustworthiness into deployment from the start 4, meaning approval gates should be implemented on day one of a pilot.
- Weeks three and four: Measure cycle time, surface count, and rework rate against the baseline. Interview writers and reviewers separately. If the tool does not reduce at least one surface or shorten at least one handoff, the switch may not be cost-effective.
Frequently Asked Questions
References
- 1.AI Risk Management Framework | NIST.
- 2.AI Guidance - CMS.
- 3.AI Guide for Government - IT Modernization Centers of Excellence.
- 4.NIST AI RMF Playbook.
- 5.Manage - AIRC - NIST AI Resource Center.
- 6.Feedback from Uptake on Initial Draft of NIST AI Risk Management Framework.
- 7.1st Draft AI RMF Comments: Microsoft.
- 8.FDA Launches Agency-Wide AI Tool to Optimize Performance for the American People.
- 9.Shapiro Administration Leads the Way in Ethical Use of AI.
- 10.Knowing Is Half the Battle - Harvard Law School Center on the Legal Profession.