
Key Takeaways
- Approval latency, not writing speed, is the real cap on content output, so cutting queue time between draft and publish drives far bigger throughput gains than faster drafting.
- Treating publishing as a governed supply chain with six defined stages, single owners, WIP limits, and one unified approval surface replaces scattered Slack-and-email reviews with measurable handoffs.
- AI belongs inside the workflow at intake clustering, brief assembly, drafting, SEO edits, and channel variants, but every AI artifact must pass through the same human approval queue 1.
- A 90-day sequence of measure, consolidate, then insert AI—paired with NIST AI RMF governance mapped onto approval gates—moves teams from tool-stacked to orchestrated operations 9.
Why approval latency, not writing speed, caps content output
Content managers often find that the bottleneck in content production isn't drafting speed, but the time between a draft's completion and its publication. A typical scenario involves a piece waiting days for subject matter expert (SME) review, being reassigned via email, accumulating legal comments in a Google Doc, and then undergoing a brand check before finally being scheduled in the CMS. While writing might take a few hours, the approval process can stretch into weeks.
This issue is rarely addressed by AI drafting tools. McKinsey's analysis of AI-powered workflows cautions against implementing solutions that accelerate one stage while creating new manual steps elsewhere. True gains, they argue, require an end-to-end view of the process, not just point automation 1. Faster drafts merely exacerbate the problem by piling up behind the same slow approval queues.
The operational pattern is clear: brief-to-publish cycle times for most in-house teams range from three to six weeks. The majority of this period is spent in queues, not actively working on the content. Reducing writing time from eight hours to two hours shortens a 30-day cycle by only one day. However, cutting approval latency from 18 days to 4 days can reduce the same cycle to 16 days, effectively doubling quarterly throughput without additional hires.
This article views the publishing workflow as a content supply chain: a structured system with defined stages, work-in-progress limits, and a unified approval process. In this model, writing speed is a secondary factor; approval latency is the primary lever for efficiency.
The content supply chain: a governed operating model
Manufacturing industries addressed similar challenges decades ago by optimizing entire production lines, not just individual components. They established defined handoffs, queue limits, and a single quality gate before shipment. Content operations, however, often lack this structure. Many in-house teams resemble a relay race without a baton: briefs reside in Notion, drafts in Google Docs, comments in Slack, legal reviews in email, and CMS schedules are scattered.
A content supply chain treats publishing as a connected process with explicit stages, owners, and gates. McKinsey's research on AI-powered enterprise workflows emphasizes that significant productivity gains come from redesigning the entire process, not just automating individual steps, as point solutions often shift delays rather than eliminate them 1. This principle applies equally to a 40-asset-per-quarter editorial operation. Stages must be clearly defined, owners assigned, and handoffs consolidated into a single system.
The following subsections detail the six stages every asset moves through from intake to distribution, and the concept of a single approval surface that centralizes disparate review channels. Together, these elements transform a chaotic workflow into a measurable, governed operating model.
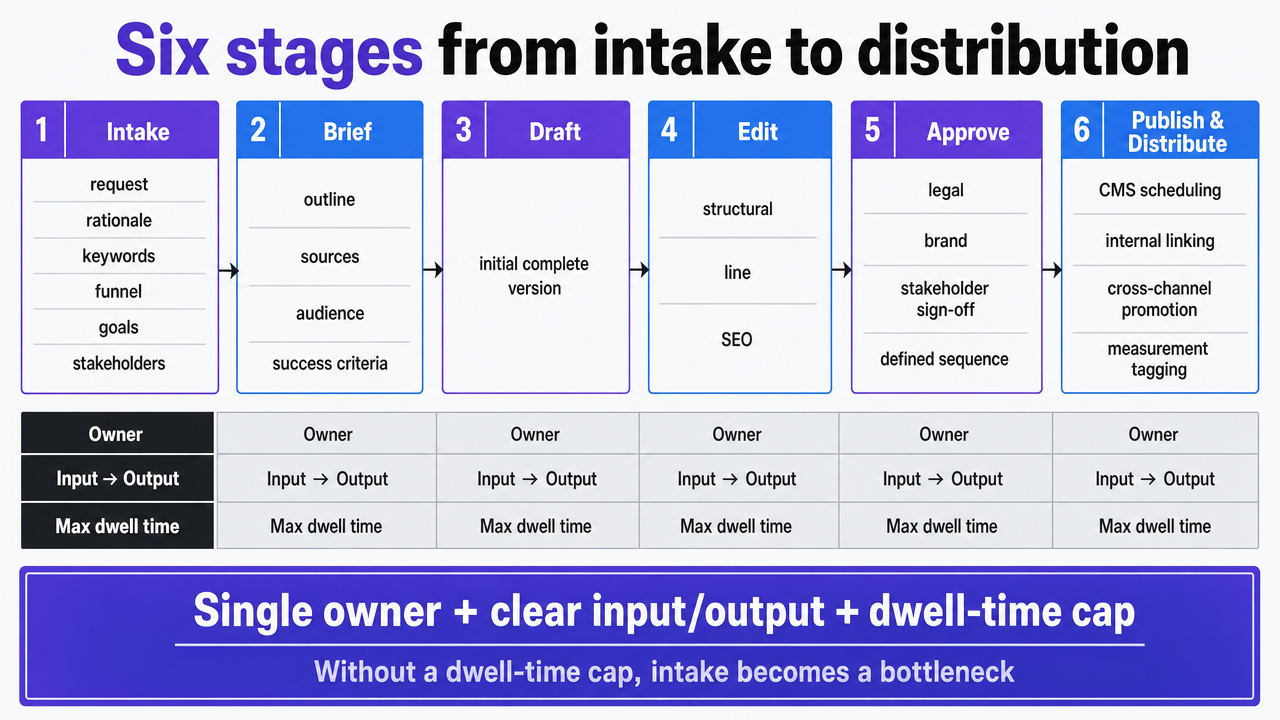
Six stages from intake to distribution
Every published asset progresses through six stages, whether formally recognized or not:
- Intake captures the request and strategic rationale, including target keywords, funnel position, business goals, and stakeholders.
- Brief converts the request into a working specification with an outline, sources, audience, and success criteria.
- Draft produces the initial complete version.
- Edit involves structural, line, and SEO revisions.
- Approve secures legal, brand, and stakeholder sign-off in a defined sequence.
- Publish and Distribute handles CMS scheduling, internal linking, cross-channel promotion, and measurement tagging.
Simply naming these stages is insufficient. The critical step is assigning a single owner, defining clear inputs and outputs, and setting a maximum dwell time for each stage. Without a dwell-time cap, intake becomes an unmanaged backlog. A brief without a defined output remains a fragmented discussion. An approval stage without a defined sequence leads to the prolonged queues observed in many teams.
Research on content marketing performance underscores the importance of explicit stage definitions. A study found that quality, relevance, and channel fit are context-dependent variables requiring deliberate managerial decisions 7. Stages formalize these decisions: the brief stage ensures relevance, the edit stage verifies quality, and the distribute stage plans channel fit. Skipping a stage renders these variables invisible, making them impossible to measure or improve.
 Visualize the six-stage content supply chain described in this section, giving readers a reference diagram for the operating model
Visualize the six-stage content supply chain described in this section, giving readers a reference diagram for the operating model
A single approval surface replaces scattered channels
Scattered approvals are a major source of delay and inefficiency. When SME comments arrive in Slack, legal redlines in Word, brand feedback in video, and final executive approval in email, the content manager becomes a human router. This routing is uncompensated work that scales directly with volume, ultimately limiting throughput.
A single approval surface provides an architectural solution: one queue, one interface, one audit trail. All reviewers access the asset, brief, previous comments, and specific decision requirements in a unified location. Approvals proceed sequentially with defined Service Level Agreements (SLAs), replacing chaotic parallel reviews.
This approach also makes governance more efficient. McKinsey's workflow guidance specifically warns against AI deployments that accelerate one stage while introducing new manual coordination steps, as this can worsen overall cycle time 1. A single approval surface prevents this failure. When AI generates a draft, human review is a click away within the same system, eliminating context switching. The approval surface transforms the supply chain from a metaphor into a measurable system, providing timestamped positions for every asset, queue depths for reviewers, and accountability for delays.
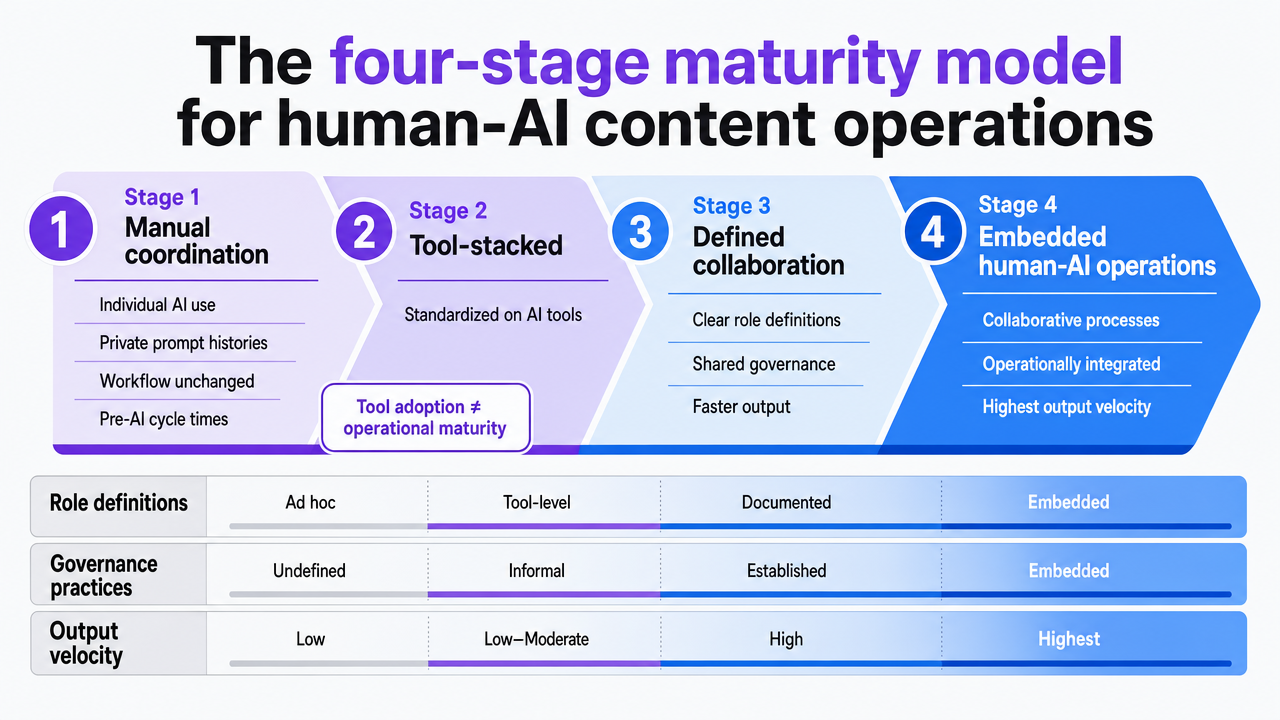
The four-stage maturity model for human-AI content operations
Content managers often lack a framework to assess their operational maturity. The Cal State LA framework for integrating generative AI into marketing workflows outlines four progressive stages of human-AI integration, from ad hoc experimentation to fully embedded collaborative processes 8. Each stage is characterized by different role definitions, governance practices, and output velocity. This model is valuable because it distinguishes between tool adoption and operational maturity; a team can possess numerous premium AI subscriptions yet still operate at stage one.
- Stage one: Manual coordination. Writers use AI assistants individually, prompts are stored in private chat histories, and the overall workflow remains unchanged. Cycle times are comparable to pre-AI teams.
- Stage two: Tool-stacked. The team has standardized on AI tools for drafting, SEO research, and editing, but these tools operate alongside the existing workflow rather than being integrated into it. Output may increase modestly, but approval latency remains unchanged because reviews still occur across multiple channels like Slack, email, and Google Docs. The 2024 State of Marketing AI Report, summarized by Harvard Professional and Executive Education, indicates that daily AI use is now routine in marketing, suggesting many in-house operations are at stage two by default 4.
- Stage three: Orchestrated. AI execution is integrated into the supply chain. This includes briefs generated from intake data, drafts produced against those briefs, and SEO passes run before editorial review, all managed within a single queue. Handoffs become system events rather than human reminders.
- Stage four: Governed AI execution. Stage three's orchestration is augmented with explicit approval gates, audit trails, and risk controls at every AI insertion point. Throughput increases because approval latency decreases, and quality is maintained because human judgment focuses on critical decisions rather than being spread thin across routine handoffs.
These stages are not merely descriptive; they predict cycle time. A stage-two team with a 28-day brief-to-publish cycle will not achieve a 10-day cycle by simply adding another AI drafting tool. The improvement requires redesigning the entire workflow.
 Render the Cal State LA-derived four-stage maturity model so readers can self-assess where their operation sits
Render the Cal State LA-derived four-stage maturity model so readers can self-assess where their operation sits
Test a Scalable Content Workflow—Start Publishing Now
Experience hands-on publishing with a workflow built for rapid, high-quality content at scale—no delays or commitments.
Metrics that indicate a healthy content supply chain
Most content operations report on executive-level outputs such as published pieces, organic sessions, or influenced MQLs. While these metrics reflect results, they don't reveal the health of the underlying supply chain. A team might meet quarterly publish targets by overworking editors, indicating an unsustainable operation that will fail under increased volume. Conversely, a team might slightly miss a publish count but have a healthier workflow than the previous quarter.
The crucial metrics for workflow health predict future output. These fall into two categories: lagging indicators, which describe past production, and leading indicators, which signal potential bottlenecks. The first group assesses current performance, while the second indicates scalability. The following subsections define both, offering specific metrics for immediate dashboard implementation.
Throughput, cycle time, first-pass approval, SEO impact
Four lagging metrics measure the supply chain's productivity:
- Throughput: Published assets per editor-week. Editors are typically the constrained resource, so capacity is measured by how much an editor can move from draft to publish, regardless of draft volume.
- Cycle time: The median brief-to-publish duration in calendar days, from intake approval to live URL. Median is preferred over average to avoid distortion from single stalled assets.
- First-pass approval rate: The percentage of assets that clear each approval gate without revision requests. A rate below 60% at any gate suggests a brief problem, not a writing problem.
- SEO impact per published asset: Organic sessions or ranked keywords at day 90, attributed to the URL, not the campaign. Research on content marketing effectiveness highlights that quality and relevance, not just volume, drive performance 7, making per-asset impact a vital dashboard metric alongside throughput.
WIP limits and reject rates as leading indicators
Leading indicators provide early warnings of workflow issues:
- Work-in-progress (WIP) limits: Caps the number of assets allowed in any single stage. For example, a team with a WIP limit of six in the edit stage cannot intake a seventh brief until one clears. This makes bottlenecks visible rather than silently absorbed into an editor's queue.
- Reject rate: The percentage of assets sent back from a downstream stage to an upstream one (e.g., legal sending edits back to draft, brand sending approvals back to edit). A rising reject rate at any handoff indicates that the upstream stage is producing work unusable by the downstream stage, often due to a weak brief or a lack of quality checks at an AI insertion point. McKinsey's workflow guidance identifies this as a central failure mode of AI-accelerated processes: speed without governance pushes defects downstream, where they are more costly to fix 1. WIP and reject rates detect these failures before cycle time metrics reflect them.
Where AI belongs: inside the workflow, not beside it
A common error in AI-assisted publishing is treating AI as merely a faster writer whose output is then fed into the same human queue. McKinsey's analysis of generative AI's economic potential estimates that in marketing, this technology could yield productivity improvements of 5 to 15 percent of total marketing spend 5. This figure, however, represents potential gains across automated content generation, testing, and personalization, not realized cost savings for a single team. To capture any part of this potential, AI must be integrated into specific stages of the supply chain with defined inputs and a clear downstream consumer for its output.
Five key AI insertion points align with the six stages of the content supply chain:
- Intake: AI can cluster incoming requests against existing content inventory, flagging duplicates or cannibalization risks before a brief is written.
- Brief: AI can assemble outlines, target keywords, competing URLs, and source material into a working specification for editor approval.
- Draft: AI can produce the first complete version based on the approved brief.
- Edit: AI can perform structural and SEO passes before human editors, identifying missing entities, thin sections, and internal linking opportunities as comments.
- Distribute: AI can generate channel variants (email subject lines, social posts, paid ad copy) from the approved canonical asset.
IE Insights documents a similar funnel-wide application of generative AI for ideation, A/B testing, SEO, and personalized outreach as connected workflow steps 2.
Crucially, AI should not be responsible for approving its own output. Every AI-generated artifact must enter the single approval surface and await a human decision. The projected productivity gains only materialize when AI execution and human approval share a unified queue. Integrating AI into a workflow that still relies on Slack for reviews will not reduce cycle time; it will only cause drafts to accumulate faster at the existing bottleneck.
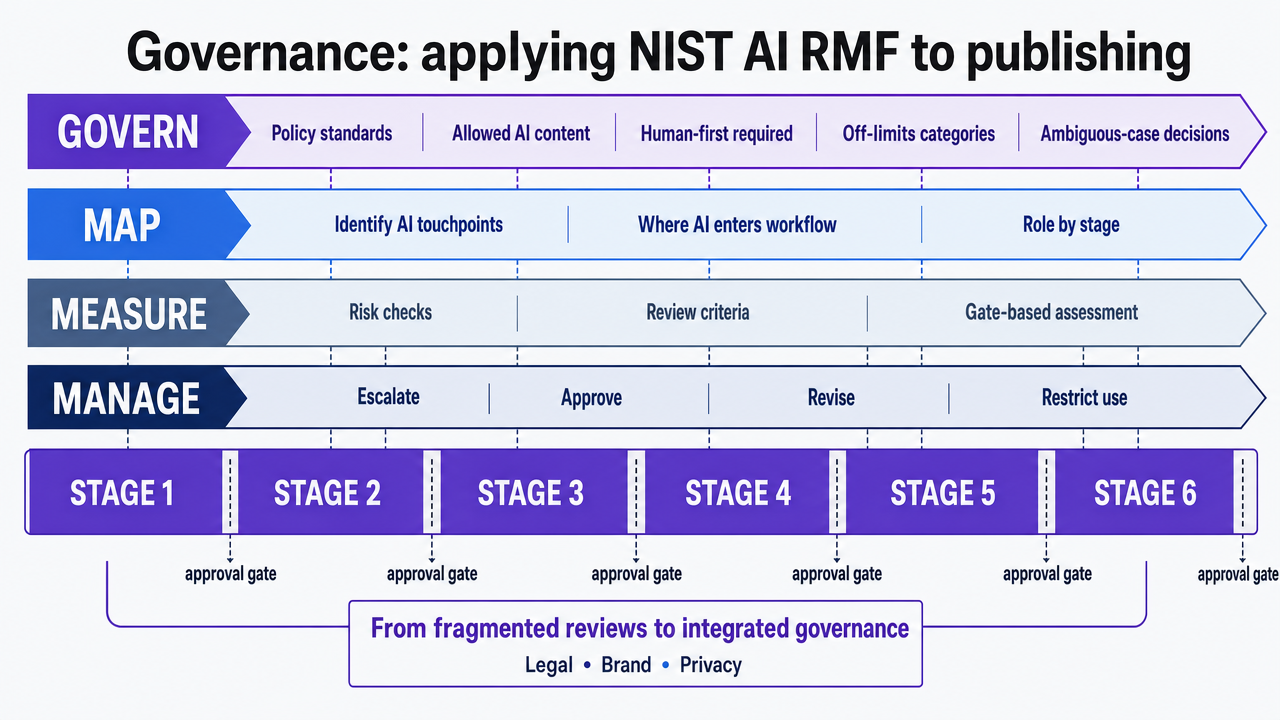
Governance: applying NIST AI RMF to publishing
In AI-assisted publishing, governance is often treated as a separate, fragmented process involving isolated legal, brand, and privacy reviews. This approach becomes unsustainable when AI generates content at every stage of the supply chain. The NIST AI Risk Management Framework (RMF) offers a more effective organizing principle. This voluntary framework, built around four functions—govern, map, measure, and manage—can be directly integrated into the six-stage supply chain 9.
Govern establishes policies defining what AI can produce, what it must avoid, and who makes decisions in ambiguous cases. In publishing, this means a written standard for AI-drafted content types, those requiring human first passes, and categories (e.g., regulated claims, customer testimonials, clinical/legal guidance) entirely off-limits for AI. Map identifies AI's location in the workflow and the risks associated with each insertion point. For example, intake clustering carries cannibalization risk, drafting models carry factual accuracy and brand voice risks, and distribution models carry channel-compliance risks. Each risk must be explicitly named.
Measure attaches evaluation criteria to each insertion point, such as hallucination rates at draft, citation accuracy at edit, or prohibited-claim detection at approval. These are not abstract metrics; they become specific checks that human reviewers sign off on before an asset progresses. Manage closes the loop with documented response actions when a measurement fails—e.g., sending a draft back to the brief stage, revising a model prompt, or temporarily disabling an insertion point until defect rates decrease.
The benefit is that governance ceases to be a separate queue. It becomes an inherent property of the existing approval surface, with every AI-generated artifact carrying a record of which gate it cleared and which reviewer approved it. McKinsey's 2025 global survey notes that organizations scaling AI increasingly pair adoption with formal risk management, though the maturity of these practices varies across functions 6. In publishing, uneven governance quickly manifests: a single off-brand AI claim in a published asset can negate a quarter's throughput gains. Mapping RMF functions onto supply-chain gates helps content managers sustain these gains.
 Show how the four NIST AI RMF functions map onto the publishing supply chain's approval gates, since the section explicitly describes this mapping
Show how the four NIST AI RMF functions map onto the publishing supply chain's approval gates, since the section explicitly describes this mapping
See How Leading Teams Streamline Content Publishing at Scale
Connect with a strategist to review proven, centralized workflows that accelerate content approvals and multi-channel publishing—without adding headcount or losing oversight.
Tooling: one stack decision, not a buyer's guide
The type of tooling is more important than the specific vendor. A robust content supply chain requires four integrated functions, ideally within the same system or tightly connected systems:
- an intake-to-brief layer for capturing requests and generating specifications;
- a draft-and-edit layer where AI generation and human review coexist;
- a single approval surface with audit trails and SLA tracking; and
- a publish-and-measure layer that pushes to the CMS and reports per-asset SEO impact.
The choice between a single platform or multiple integrated ones is a procurement decision; the critical operational question is whether they share a unified queue.
The common failure pattern is predictable: teams adopt a best-in-class drafting tool, a separate SEO platform, a project tracker, and a CMS, then route reviews through Slack because no single tool manages approvals. McKinsey's workflow guidance explicitly states that this configuration often accelerates one stage while introducing new manual coordination steps elsewhere, resulting in unchanged or worse net cycle time 1. The crucial stack decision is which system will own the approval surface; all other tools should integrate into it. Platforms built around a command-center model—including category entrants like Vectoron—are designed for this structure, unifying AI execution and human sign-off within a single queue.
Managing content across multiple locations or brands
While this article primarily addresses single in-house teams managing one brand, this section is for content managers overseeing multiple locations, franchise networks, or a portfolio of brands. The content supply chain logic still applies, but the scale changes.
Portfolio operators face a multiplier effect. A 40-asset quarterly plan for one brand becomes a 200-asset plan across five locations, each with unique service mixes, local SEO targets, and brand-voice variations. The default response—replicating the single-brand workflow per location—replicates the approval-latency problem across the entire network. McKinsey's workflow guidance is particularly relevant here: accelerating one stage per location while introducing new manual coordination steps between locations will not improve the network's overall cycle time 1.
The key operating decision is which functions to centralize and which to keep local. Brief generation, SEO research, draft production, and channel variant creation centralize efficiently because they are template-driven and benefit from shared inventory and AI execution. Local SME review, jurisdiction-specific compliance checks, and final brand approval should remain local, as the judgment required cannot be effectively delegated centrally without undermining the purpose of local entities.
A worksheet, rather than a benchmark, is useful here. The table below compares cost-per-published-asset across three operating models using manager-defined variables. The McKinsey 5 to 15 percent productivity range for generative AI in marketing sets the upper bound for the "Governed AI-execution workflow" column, with the same caveat regarding output potential versus realized P&L savings 5.
| Variable | Distributed agency retainers | Centralized in-house team | Governed AI-execution workflow ||---|---|---|---|| Editor hours per asset | n/a (agency-owned) | E hours | E × (0.85 to 0.95) || Freelance or agency rate | R per asset | n/a | n/a || Throughput per editor-week | n/a | T assets | T × (1.05 to 1.15) || Approval latency (days) | High, cross-vendor | Medium, single team | Low, single queue || Per-location variance | High | Low | Low |
Managers should plug in their team's actual E, R, and T values. The governed AI column uses the McKinsey range as a planning assumption. The "variance" row is often underestimated by portfolio operators: distributed agency retainers can lead to inconsistent output quality across locations, as each engagement sets its own quality bar. This is a context-dependent failure, not merely a vendor-selection issue 7. A single approval surface across the entire portfolio significantly reduces this variance.
A 90-day plan to re-engineer the workflow
Re-engineering a publishing operation doesn't require a software migration or a reorganization. It involves a sequenced 90-day plan to rebuild the workflow while keeping it operational. This plan assumes an in-house team of two to five writers, one or two editors, and existing CMS and project tools. It aims to advance the operation from stage two to stage three of the Cal State LA maturity model—orchestrated AI execution within a single approval surface 8.
- Days 1 to 30: Measurement. Instrument the current workflow. Log each asset's intake date, stage transitions, and publish date for one full cycle. Record reject events between stages and the reviewer responsible for each delay. The goal is to establish a baseline cycle time, a baseline first-pass approval rate at each gate, and a map of where queue time accumulates. No process changes should be made yet. McKinsey's workflow guidance emphasizes that point automation without an end-to-end view often shifts bottlenecks rather than removing them, making initial diagnosis crucial 1.
- Days 31 to 60: Consolidation. Select the system that will own the approval surface and route all reviews into it. Define the six stages, assign a single owner per stage, and set WIP limits based on the baseline data from month one. Develop a governance standard: specify which content types can be AI-drafted, which require a human first pass, and which are off-limits, mapping these against the four NIST AI RMF functions 9. Avoid adding new AI insertion points during this phase; the workflow must be governed before it is accelerated.
- Days 61 to 90: Insertion. Introduce AI execution at intake clustering, brief assembly, and channel variant generation first. These points carry the lowest risk and offer the highest potential for latency reduction. Weekly, measure cycle time, first-pass approval, and reject rates against the month-one baseline. A successful re-engineering will show cycle time decreasing while the reject rate remains steady. If the reject rate rises, it indicates that AI output is entering the queue without adequate quality checks, and the insertion point requires a measurement gate before further scaling.
Frequently Asked Questions
References
- 1.Transforming the enterprise through AI-powered workflows.
- 2.Marketing in the Age of Generative AI.
- 3.The state of AI in early 2024: Gen AI adoption spikes and shows no signs of slowing.
- 4.AI Will Shape the Future of Marketing.
- 5.The economic potential of generative AI: The next productivity frontier.
- 6.The State of AI: Global Survey 2025.
- 7.Determinants of content marketing effectiveness: Conceptual framework and empirical validation.
- 8.Integrating Generative AI into Team-Based Marketing Workflows.
- 9.AI Risk Management Framework.
- 10.The state of AI.