
Key Takeaways
- Scaling stalls at governance, not creative capacity; adding tools without redesigning intake, prioritization, approval, and evaluation amplifies existing process breakage rather than fixing throughput 8.
- Treat the schedule as a four-layer operating system where intake briefs, scored priority queues, modular execution with named owners, and sprint retros each produce a visible artifact.
- Approval gates accelerate work by replacing ambiguous late-stage rework with scope, quality, and launch decisions made against written criteria by named reviewers 18.
- A workable cadence runs weekly intake scoring, biweekly approval councils, and monthly evaluation retros, keeping the queue concentrated rather than resetting every few days 7.
- Sort production into modular work that assembles against a shared creative foundation and judgment work that absorbs senior strategist time on voice, positioning, and risk 12.
- Measure at three altitudes—asset, sprint, and portfolio—so production defects, rubric defects, and strategy defects each surface where they can be corrected 9.
- Multi-brand operators federate the loop: shared scoring rubric and portfolio-owned asset library at the center, local intake queues and joint monthly retros at the units 17.
- Scope AI to intake structuring and modular execution, route every AI-assisted module through the same gates as human work, and log production path for retro comparison 1.
Why most scaling attempts stall at the governance layer
Content marketing managers who try to double output usually invest in the wrong layer. They buy a generation tool, hire a freelancer pool, or rebuild the editorial calendar. Throughput rises for a quarter, then plateaus or regresses. The bottleneck was never creative capacity. It was the absence of a repeatable decision structure that could absorb more inputs without losing review discipline.
The pattern shows up in cross-industry data. A 2024 BCG survey of more than 1,000 C-level executives found that 74% of companies struggle to achieve and scale value from AI initiatives, and BCG attributed the gap to organizational, data, and operating-model issues rather than algorithm quality 8. The scope matters: this is a survey of AI adoption broadly, not marketing-specific, but the diagnosis transfers cleanly. When a function adds tools without redesigning how work enters, gets prioritized, and gets approved, the tools amplify whatever process was already in place, including its breakage.
McKinsey's operating-model research points the same direction from a different angle. Organizations that move to next-generation operating models, with clear accountabilities and outcome-based metrics, report up to a fourfold increase in the speed of decision-making and execution 18. The lift comes from governance redesign, not from working harder inside the old structure.
For a content marketing manager running a lean team, the practical reading is straightforward. A marketing implementation schedule that scales is not a fuller calendar. It is a governed production loop with named artifacts at each stage and explicit approval points where work either moves forward or gets rerouted. The rest of this guide builds that loop layer by layer, starting with how demand enters the system.
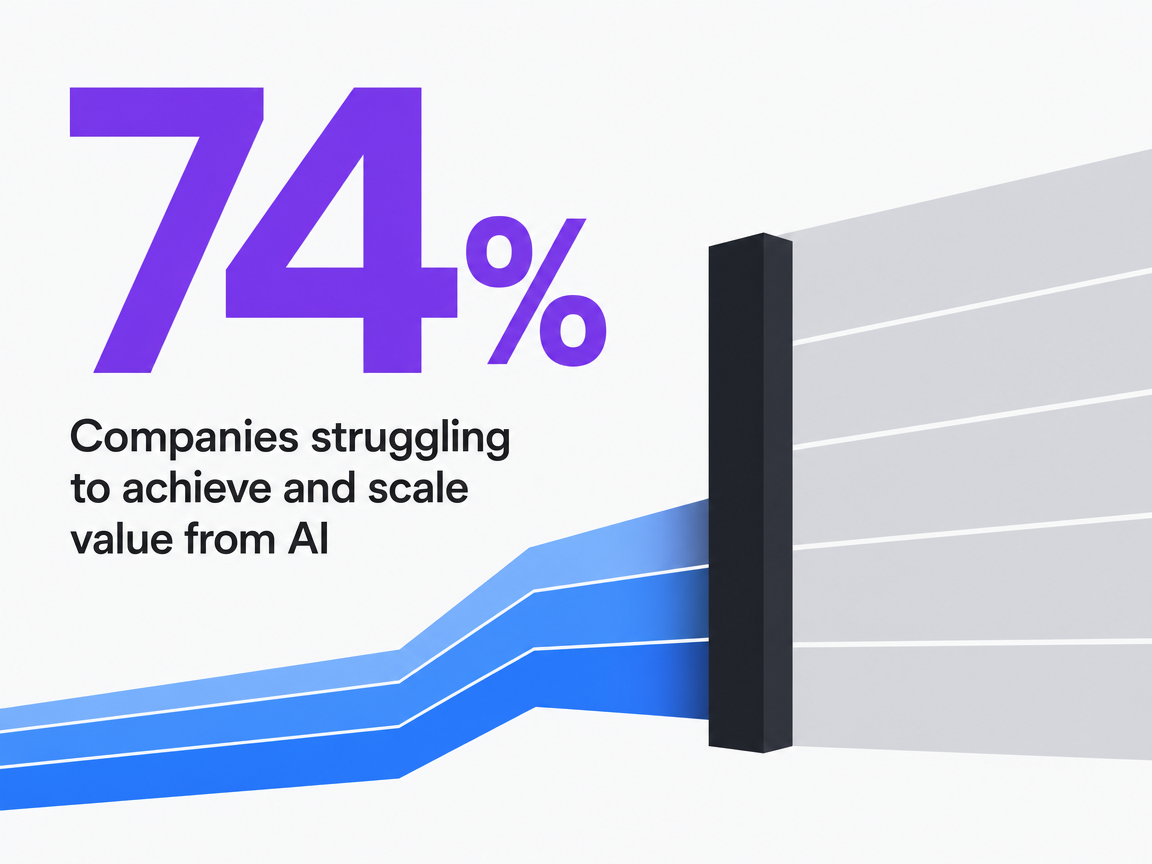 Companies struggling to achieve and scale value from AI
Companies struggling to achieve and scale value from AI
Companies struggling to achieve and scale value from AI
The schedule as a four-layer operating system
Intake: capturing demand without absorbing chaos
Intake is the layer where every request, idea, or signal enters the schedule. On most lean teams, it lives in Slack threads, hallway conversations, and a half-maintained spreadsheet. The result is a queue shaped by whoever asked last, not by what the business needs next.
A working intake layer collects demand through a single artifact: an intake brief with fixed fields. Source of the request, business outcome it serves, target audience, target keyword or distribution channel, supporting data, and requested launch window. The brief is short on purpose. Its job is to force the requester to translate a vague ask into a structured input before it touches production.
The fields matter because they map to what AMA identifies as the baseline elements of an executable action plan: timeline, assigned responsibilities, budget, and performance monitoring 11. A request that cannot fill those fields is not yet a work item. It is a conversation, and it stays in the intake queue until the requester sharpens it.
Live business signals belong in the same intake layer. Qualified call volume, declining keyword rankings, pipeline gaps by segment, and competitor publication patterns should generate intake briefs the same way a stakeholder request does. The point is to give every input the same shape so the next layer, prioritization, can compare them on equal terms.
Prioritization: a scored queue, not a wish list
Prioritization fails when the queue is a list. Lists imply order without explaining why one item ranks above another, which means the order quietly resets every time a louder stakeholder appears. A scored queue replaces opinion with a visible rubric.
The rubric should reflect what actually drives content effectiveness in managerial practice, which researchers describe as a function of context-specific features rather than volume alone 6. For most in-house teams, four scoring dimensions hold up: expected business impact, audience evidence, production effort, and strategic fit with the current quarter's objectives. Each dimension gets a 1-to-5 score, and the composite produces a ranked queue rather than a flat backlog.
Scoring is a decision artifact, not a math exercise. The numbers are useful because they make trade-offs legible. When a stakeholder asks why their request is in week six instead of week two, the queue answers in the same language for every item. BCG's blueprint for AI-powered marketing makes a related point at the workflow level: prioritized use cases beat scattered experiments because they concentrate effort where measurement can compound 7.
The queue should be reviewed weekly, not continuously. Continuous reprioritization is how lean teams burn capacity on triage. A weekly cadence keeps the queue responsive without turning it into a live document that nobody can plan against.
Execution: modular assets and named owners
Execution is where most schedules quietly break. Approved work enters production, and the team rebuilds each asset from scratch, briefs a writer in a meeting, edits in a document chain, and ships when the queue clears. Throughput stalls because every asset is a custom project.
A scalable execution layer treats assets as modules. BCG describes this as redesigning creative processes into channel-agnostic, modular components that can be assembled across formats and surfaces 7. For a content team, that means a long-form article generates a structured outline, three social cuts, an email summary, and a sales enablement snippet from one production pass, not five. The modular logic depends on a shared creative foundation, which IPA identifies as a driver of stronger brand and business effects when execution scales across channels 12.
Each module needs a named owner, not a role label. "Editorial" does not own an asset. A person does, and that person is accountable for moving the module from draft to approval-ready inside a fixed window. Forrester's work on marketing resource management describes this coordination layer as the tie that binds planning, budgeting, and workflow management into one operational hub 14.
The execution layer also tracks state. Each module is in one of four states: drafting, in review, approved, or shipped. State changes are logged so the evaluation layer has clean data to work with.
Evaluation: review cycles that feed the next sprint
Evaluation is the layer that turns a production loop into a learning system. Without it, the schedule produces volume but not insight, and the next sprint repeats the same bets with the same blind spots. IPA's guidance on communications planning frames evaluation as the mechanism that drives accountability and enables ongoing optimization of the plan itself 13. WHO's monitoring and evaluation guide, written for digital health but structurally portable, makes the same case: explicit planning, execution, and monitoring steps are what improve the quality of an intervention over time 2.
The artifact at this layer is the sprint retrospective. It captures four things: what shipped, what each module produced against its target metric, what got reworked or killed and why, and which intake assumptions were wrong. The retro feeds back into the prioritization rubric, sharpening the scores on the next cycle.
Evaluation also enforces oversight. NIST's AI Risk Management Framework treats trustworthiness as a property built into operations through measurement and governance checkpoints rather than added after launch 1. The same logic applies to content operations: review gates at intake, prioritization, execution, and evaluation are what keep quality stable when volume rises.
The four artifacts hold the system together. The intake brief defines what enters. The priority queue defines what moves next. The approval log defines what shipped and under whose sign-off. The sprint retro defines what the team learned. When those four are visible and current, the schedule scales without losing review discipline.
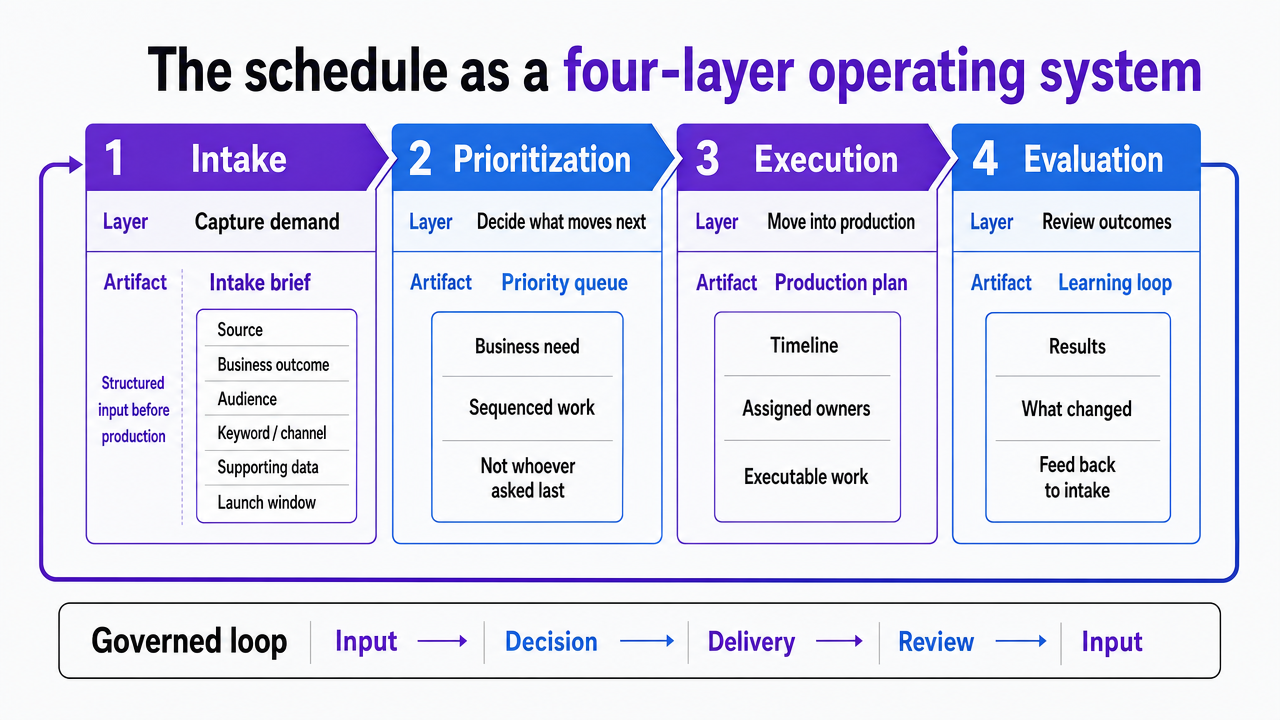 Visualize the four-layer operating system (Intake, Prioritization, Execution, Evaluation) described in the section's subsections, showing the artifact produced at each layer and how they connect into a governed loop
Visualize the four-layer operating system (Intake, Prioritization, Execution, Evaluation) described in the section's subsections, showing the artifact produced at each layer and how they connect into a governed loop
Why approval gates speed throughput instead of slowing it
The instinct on a lean team is to treat approval as friction. Each gate looks like a queue, and every queue looks like lost velocity. The data points the other direction. McKinsey's operating-model research finds that organizations with clear accountabilities and outcome-based metrics report up to a fourfold gain in decision and execution speed, with the lift coming from where authority is placed, not from removing review 18. Gates do not slow throughput. Ambiguity does.
Ambiguity shows up as rework. A draft circulates through three rounds of comments because no one specified what "approved" means. A campaign launches and gets pulled because legal saw it for the first time on go-live day. A keyword brief gets rewritten twice because the strategy lead and the SEO lead never aligned on intent. Each of those is a hidden gate, opened late and without structure. Explicit gates compress that cost by surfacing the decision earlier, with the right reviewer, against a written standard.
NIST's AI Risk Management Framework formalizes the same principle for AI operations: trustworthiness is built in through measurement and governance checkpoints, not bolted on after the fact 1. Translated to content work, that means the question "is this ready to ship?" gets answered against criteria the team agreed to in advance, not against the reviewer's mood that afternoon.
Three gates carry most of the load.
- A scope gate at intake confirms the brief is complete enough to enter the queue.
- A quality gate after drafting confirms the asset meets the rubric, including brand voice, factual sourcing, and SEO targeting.
- A launch gate before publish confirms the asset clears legal, compliance, and channel-specific requirements.
Each gate has a named decision-maker, a documented checklist, and a service-level window. When those three exist, the team stops debating individual assets and starts debating the rubric, which is where the strategic conversation belongs.
The approval log is the artifact that proves the system is working. It records what shipped, who signed off, and against which criteria. Over a quarter, the log shows whether gates are accelerating or accumulating, and the team adjusts the rubric rather than the people running it.
Test a Scalable Marketing Schedule in One Week
Build and launch a data-driven implementation schedule with real campaigns before making a commitment.
A worked sprint cadence: weekly intake, biweekly approval, monthly evaluation
Abstract layers only hold up when they map to a calendar. A workable cadence for a lean in-house team runs on three nested cycles: weekly intake review, biweekly approval council, and monthly evaluation retro. Each cycle has a fixed time, a named owner, and a defined output.
The weekly intake review takes thirty minutes. The content marketing manager closes the intake queue for the week, scores every new brief against the four-dimension rubric, and publishes the updated priority queue before end of day Friday. Anything that arrives after the cutoff waits seven days. The discipline matters because BCG's blueprint for AI-powered marketing argues that scaling depends on concentrating effort on prioritized use cases rather than running scattered experiments across the workflow 7. A queue that resets every two days cannot concentrate anything.
The biweekly approval council runs for sixty minutes. Scope gate, quality gate, and launch gate decisions for every module in flight are cleared in one sitting, against the written rubric. The council includes the editorial owner, the SEO lead, and whichever subject-matter reviewer the asset requires. Decisions land in the approval log within the hour. Modules that fail a gate return to their owner with specific rework notes, not general feedback.
The monthly evaluation retro takes ninety minutes. The team reviews what shipped, what each module produced against its target metric, which assumptions in the intake briefs were wrong, and which rubric scores predicted poorly. The retro output is a short rubric revision and a list of three to five process adjustments for the next sprint. IPA's evaluation guidance positions this kind of structured review as the mechanism that drives optimization rather than producing reports for their own sake 13.
The contrast with a traditional linear schedule shows up across four dimensions. A linear schedule moves throughput in fits and starts because rework is invisible until launch; a governed loop holds throughput steady because gates catch defects early. Review depth is shallow and late in linear work; it is shallow and frequent in the loop, which costs less per asset. Rework rates run high in linear schedules because feedback arrives after sunk effort; they fall in the loop because the scope gate kills weak briefs before production. Measurement cadence in linear work is quarterly or campaign-based; in the loop, it is monthly and feeds the next intake cycle. The BCG staged-adoption logic, moving from Essentials to Scaling to Leading, depends on exactly this kind of structured feedback to compound output rather than reset it each quarter 7.
The cadence is not the schedule. It is the heartbeat that keeps the four layers synchronized.
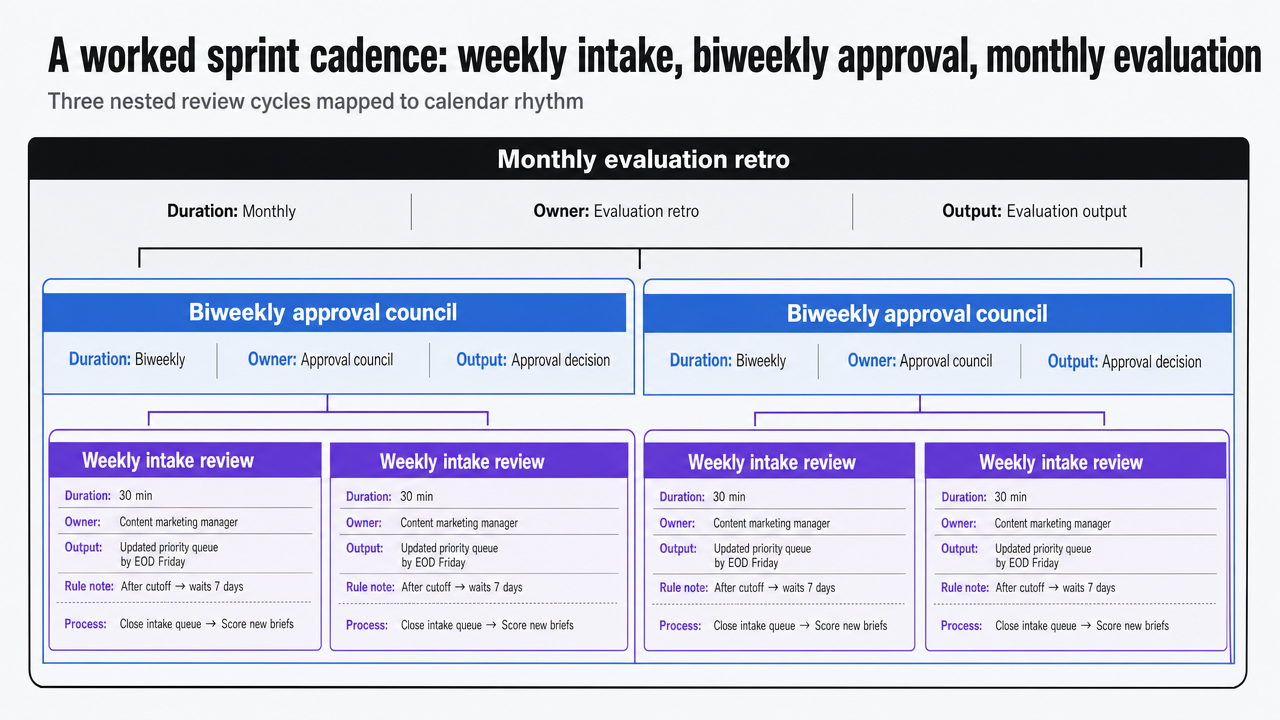 Visualize the three nested review cycles (weekly intake, biweekly approval, monthly evaluation) with their duration, owner, and output, directly mapping to the cadence described in this section
Visualize the three nested review cycles (weekly intake, biweekly approval, monthly evaluation) with their duration, owner, and output, directly mapping to the cadence described in this section
Separating modular work from judgment work as volume grows
Doubling output without adding headcount only works when the team stops treating every asset as a one-off. The practical move is to draw a line through the production catalog and sort each work type into one of two columns: modular work that can be templated, parallelized, and partially automated, or judgment work that requires a human strategist's read on context, voice, or risk.
Modular work is the larger column for most in-house teams. Comparison pages built from a standing structure, location pages that swap geographic and service variables against a fixed template, glossary entries, FAQ expansions, and channel cutdowns from a primary asset all share the same property: the creative foundation is decided once, and individual instances are produced against it. IPA's research on creative consistency supports the structural case for this approach, finding that consistent creative foundations, a culture of consistency, and consistent execution drive stronger brand and business effects when output scales across channels 12. The modules do not need to be invented each time. They need to be assembled against a standard.
Judgment work is the smaller, higher-stakes column. Category-defining thought leadership, sensitive product positioning, executive bylines, crisis response, and any asset that sets the rubric for the modules below it belong here. These items absorb senior time on purpose because the cost of getting voice or strategy wrong compounds across every module that inherits from them.
BCG's blueprint frames the same split at the workflow level, recommending that teams redesign creative processes into modular, channel-agnostic assets while concentrating senior judgment on the prioritized use cases that set direction for the rest 7. The schedule reflects the split in two ways. Modular work runs on the biweekly approval council against a checklist rubric. Judgment work routes to a separate review track with the strategy lead, longer review windows, and explicit voice and positioning criteria. Mixing the two on the same queue is what causes lean teams to either over-review modules or under-review the assets that actually move the brand.
Measurement loops that compound across sprints
A schedule that scales does not just measure more often. It measures the same things in the same way, sprint after sprint, so that signal accumulates instead of resetting. Without that discipline, monthly reports become recaps, and the team relearns the same lessons every quarter.
Three measurement layers carry the load.
- The asset layer tracks per-module outcomes against the target set at intake: rankings, qualified sessions, conversion events, or pipeline contribution, depending on the brief.
- The sprint layer aggregates those outcomes by intake source, priority score, and module type, so the team can see which scoring inputs actually predicted business impact.
- The portfolio layer rolls everything into quarterly performance against the strategic objectives that seeded the priority rubric in the first place.
SBA's guidance on marketing planning makes the structural case plainly: comparing marketing costs to revenue and maintaining plans on a regular cycle is what turns activity into ROI evidence 9.
The point of three layers is to keep the feedback honest at each altitude. Asset metrics catch production defects. Sprint metrics catch rubric defects. Portfolio metrics catch strategy defects. Mixing them, which is the default failure mode on lean teams, produces dashboards that show everything and explain nothing.
WHO's monitoring and evaluation guidance, while written for digital health, codifies the same logic content teams need: planning, execution, and monitoring have to be explicit and step-wise for evaluation to improve quality over time 2. Translated to a content schedule, that means each layer has a named owner, a fixed cadence, and a written definition of what counts as a positive result. Ambiguous metrics generate ambiguous conclusions.
Compounding shows up when retro findings change the next intake. If sprint data shows that briefs from sales-call signals outperform briefs from competitor monitoring, the scoring rubric weights the audience-evidence dimension accordingly. If a module type consistently misses its conversion target, the rubric flags it for redesign before more instances enter production. The schedule learns. That is the difference between a team running ten sprints in a year and a team running one sprint ten times.
See How Leading Teams Orchestrate Scalable Marketing Schedules
Get a personalized walkthrough of centralized workflows that reduce production bottlenecks, improve cross-channel coordination, and maintain brand control—without expanding your team.
If you manage multiple brand units or regional teams
The audience shifts here. Content marketing managers running a single in-house team can skip ahead; this section is for operators coordinating two or more brand units, regional teams, or franchise-style marketing groups against a shared backlog.
The four-layer loop holds, but the artifacts have to be federated. Each unit runs its own intake queue against a shared scoring rubric, so local context enters production without local opinion overriding portfolio priorities. The approval log lives at the portfolio level so cross-unit duplication and voice drift surface in the same week they occur, not the quarter after. McKinsey's research on marketing operating models in multi-brand environments argues for exactly this split: cross-functional collaboration and portfolio management at the center, with capability building distributed to the units that own execution 17.
Two governance rules keep the federation honest.
- The modular asset library is portfolio-owned; units assemble against it rather than rebuilding it. IPA's findings on consistent creative foundations apply with more force when channel count multiplies across regions 12.
- The monthly evaluation retro is run jointly, with each unit reporting against the same three measurement layers so portfolio trade-offs are visible in one view.
Where AI assistance fits inside a governed schedule
AI belongs inside the schedule the same way any other production input does: scoped to a layer, accountable to a gate, and measured against a rubric. The mistake on most lean teams is to drop generation tools into the execution layer without changing intake, prioritization, or evaluation. Output rises briefly, review load rises permanently, and the team ends up editing more than it ships.
The cleaner placement maps AI to specific layers. At intake, AI is useful for structuring signals into draft briefs from sales call transcripts, ranking shifts, or competitor publication patterns. At execution, it accelerates modular work: outline generation against a standing template, channel cutdowns from a primary asset, and first-pass drafts of glossary or FAQ modules. McKinsey's survey of generative AI adoption identifies content production, personalization, and time allocation as the marketing functions most reshaped by the technology 15. Harvard's executive education commentary adds that AI tools reduce time on repetitive tasks across content, email, social, and CRM workflows 16. Both point to the same operational read: AI compresses production time on modular work, not judgment work.
The governance layer is where AI assistance either compounds or breaks the schedule. NIST's AI Risk Management Framework treats trustworthiness as a property built through measurement and oversight checkpoints rather than added post-launch 1. The same logic applies here. Every AI-assisted module passes through the same scope, quality, and launch gates as human-produced work, against the same rubric. The approval log records which assets used AI assistance so the evaluation retro can compare rework rates and outcome metrics by production path.
BCG's blueprint for AI-powered marketing makes the staged case for this discipline. Teams progress from Essentials to Scaling to Leading by concentrating AI on prioritized use cases inside redesigned workflows, not by spreading it across every task at once 7. Approval-first orchestration platforms like Vectoron are one expression of that pattern: AI proposes, a human approves, and the schedule absorbs the throughput gain without losing the review structure that made the gain durable.
Frequently Asked Questions
References
- 1.AI Risk Management Framework | NIST.
- 2.Monitoring and evaluating digital health interventions.
- 3.Global strategy on digital health 2020-2025.
- 4.The value relevance of digital marketing capabilities to firm performance.
- 5.The changing role of marketing: transformed propositions ....
- 6.Determinants of content marketing effectiveness: Conceptual ... - PMC.
- 7.The Blueprint for AI-Powered Marketing.
- 8.AI Adoption in 2024: 74% of Companies Struggle to Achieve and Scale Value.
- 9.Marketing and sales | U.S. Small Business Administration.
- 10.Advertising, Promotions, and Marketing Managers.
- 11.Develop a Winning Marketing Strategy: Step-by-Step Guide.
- 12.How creative consistency strengthens brands and business effects.
- 13.Why evaluation is a key component to communications planning.
- 14.Marketing Resource Management: A Tie That Binds Marketing.
- 15.The state of AI in 2023: Generative AI's breakout year.
- 16.AI Will Shape the Future of Marketing.
- 17.Connecting for growth: A makeover for your marketing operating model.
- 18.A new operating model for a new world.