
Key Takeaways
- A digital publishing platform operates as a five-stage supply chain—intake, structured production, distribution, discovery and archive, and measurement—with each stage feeding governed data into the next 2.
- Structured production converts drafts into schema-bound source files so a single record renders across every channel, collapsing parallel format-specific workflows into one governed asset 2.
- AI runs horizontally across all five stages, drafting and reranking repeatable work, while tiered approval routing keeps human sign-off enforceable in regulated verticals 11, 10.
- For multi-location operators, the operating-model decision is whether to keep coordinating stacked tools and agencies or consolidate intake through measurement inside one workflow where judgment work stays in-house 7, 9.
The Content Supply Chain Behind Every Modern Publishing Platform
A digital publishing platform is a governed content supply chain, not a website with a publish button. It moves an idea through five operational stages: intake, structured production, distribution, discovery and archive, and measurement. Each stage has its own queue, its own approval gates, and its own data exhaust that feeds the next round of work.
The scholarly publishing world figured this out first. An XML-through journal workflow takes a copyedited manuscript, converts it to a structured source file, then generates PDF, HTML, and repository deliveries from that single source 2. The same architectural logic now sits inside enterprise content platforms, where a CMS coordinates authoring, governance, and collaboration across distributed teams instead of treating each output as a separate file 7.
What changed recently is the AI layer running horizontally across all five stages. A 2024 analysis of the publishing value chain documents AI integration from content acquisition through marketing and distribution, with traditional intermediaries being disrupted at every stage 11. That horizontal layer is what separates a modern publishing platform from a 2015-era CMS, and it is what makes the operating-model question urgent for in-house teams weighing whether to keep stacking agencies or consolidate execution. The sections that follow walk each stage in order, then examine the AI layer and the economics of consolidation.
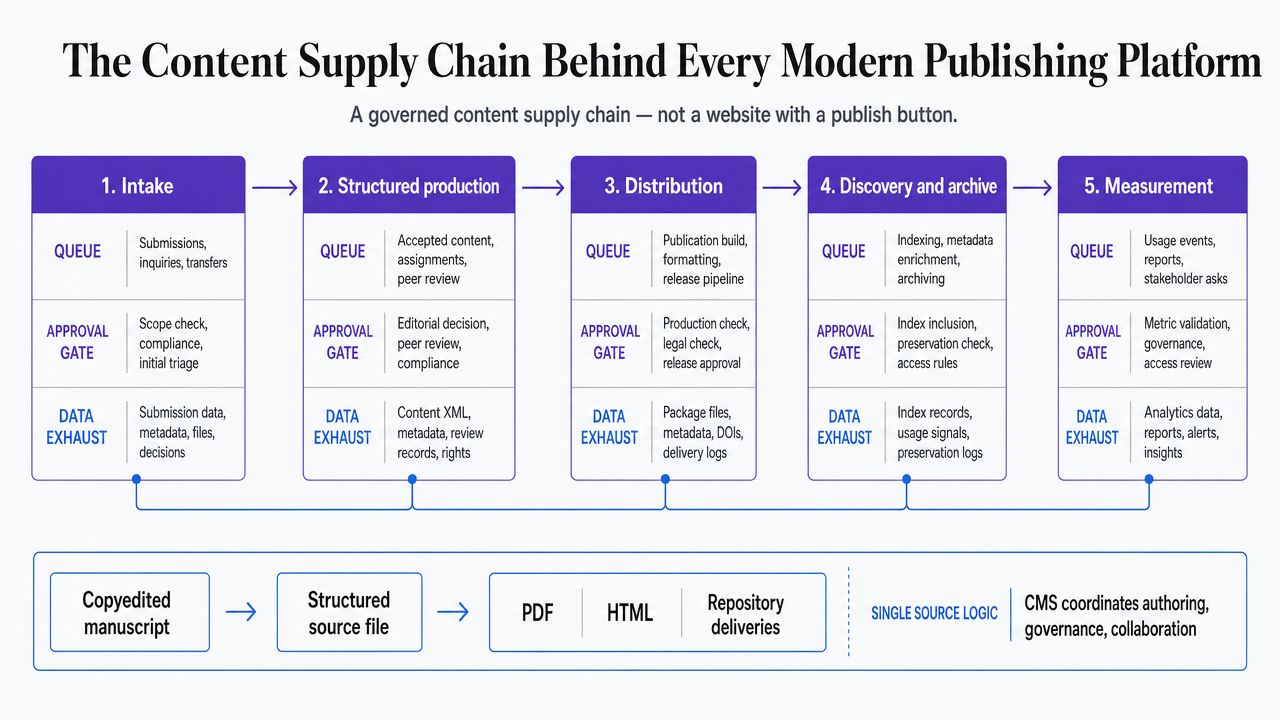 Visualize the five-stage content supply chain that structures the entire article
Visualize the five-stage content supply chain that structures the entire article
Stage One: Intake and the Submission Queue
Intake is where most content operations quietly bleed time. A modern publishing platform treats every brief, draft, asset, and external contribution as a tracked item in a submission queue, with status, owner, deadline, and approval state attached from the moment it enters the system. Scholarly publishing platforms like Open Journal Systems were built around this exact discipline—structured submission, automated routing, and visible status for every manuscript in flight 4.
The queue replaces email threads and shared drives with a single record of what is in production. Each item carries metadata at entry: content type, target channel, location or practice area, target keyword, reviewer assignments, and any compliance flags. Enterprise CMS research shows this front-end discipline is where data efficiency and collaboration gains compound, because every downstream step inherits clean inputs instead of reconstructing them 7.
Three intake patterns dominate:
- Internal authors submit drafts through a templated form that enforces required fields.
- External contributors—freelancers, subject-matter experts, agency partners—submit through a gated portal that applies the same schema.
- AI-generated drafts enter the same queue as a distinct submission type, tagged for the additional review their provenance requires.
What separates a publishing platform from a shared folder is what happens automatically at intake: deduplication checks against the existing library, metadata validation, routing to the correct reviewer based on content type or location, and a timestamped audit trail. For a marketing operation managing dozens of practice locations or service lines, the queue is the difference between knowing what is in production and guessing.
Stage Two: Structured Production and the XML Layer
Single-Source Files, Multiple Output Formats
Structured production is the stage where a draft stops being a Word document and becomes a piece of structured data. The platform converts the approved text into a schema-bound source file—JATS XML in scholarly publishing, a component model in headless CMS systems, structured blocks in modern marketing platforms—and every downstream output is generated from that one source.
The scholarly workflow remains the cleanest illustration. An XML-through journal production line takes copyedited manuscripts in JATS XML, runs them through layout and PDF generation, and delivers the same content to repositories and HTML readers without re-keying or reformatting 2. Pagination, cross-linking, citation formatting, and figure placement run as automated steps against the structured source, not as separate manual passes for each output channel 2.
The marketing analog matters because the operational logic is identical. A single structured asset—headline, body components, metadata, schema markup, image references—renders as a long-form page, an email block, a syndicated snippet, an AMP variant, and a feed for a social scheduler. When the source changes, every output regenerates from the same record. When a regulator updates a disclosure requirement or a service line gets renamed, the edit happens once.
This is the production efficiency that separates a publishing platform from a website builder. Format-specific workflows force teams to maintain parallel copies of the same content across channels, which is where version drift, compliance gaps, and lost SEO equity originate. Structured production collapses those parallel tracks into one governed record.
Approval Routing and Editorial Governance
Structured source files only hold their value if every change to them passes through a defined approval path. The platform enforces this through routing rules tied to content type, channel, and risk level. A blog update on a non-regulated topic might require one editor sign-off. A new landing page for a clinical service line routes through legal review, medical review, and brand approval before the publish state unlocks.
Enterprise CMS research frames this as the governance layer that makes data-efficient publishing possible at scale: a CMS
"allows to publish, manage, edit, delete and modify content in a very effective and dynamic way"
precisely because permission and approval logic sit inside the system rather than in email 7. Every action is logged against a user, a timestamp, and a content version.
For an in-house marketing operation, the practical effect is a defensible audit trail. Reviewers see the diff, not the whole document. Approvers sign off on a specific version, and that version is what publishes—not a later draft that quietly drifted past review. Rejections route back to the author with the comment thread attached to the record, not buried in a Slack channel. The governance layer is what makes structured production trustable, and it is the precondition for letting AI handle any portion of the work in the stages that follow.
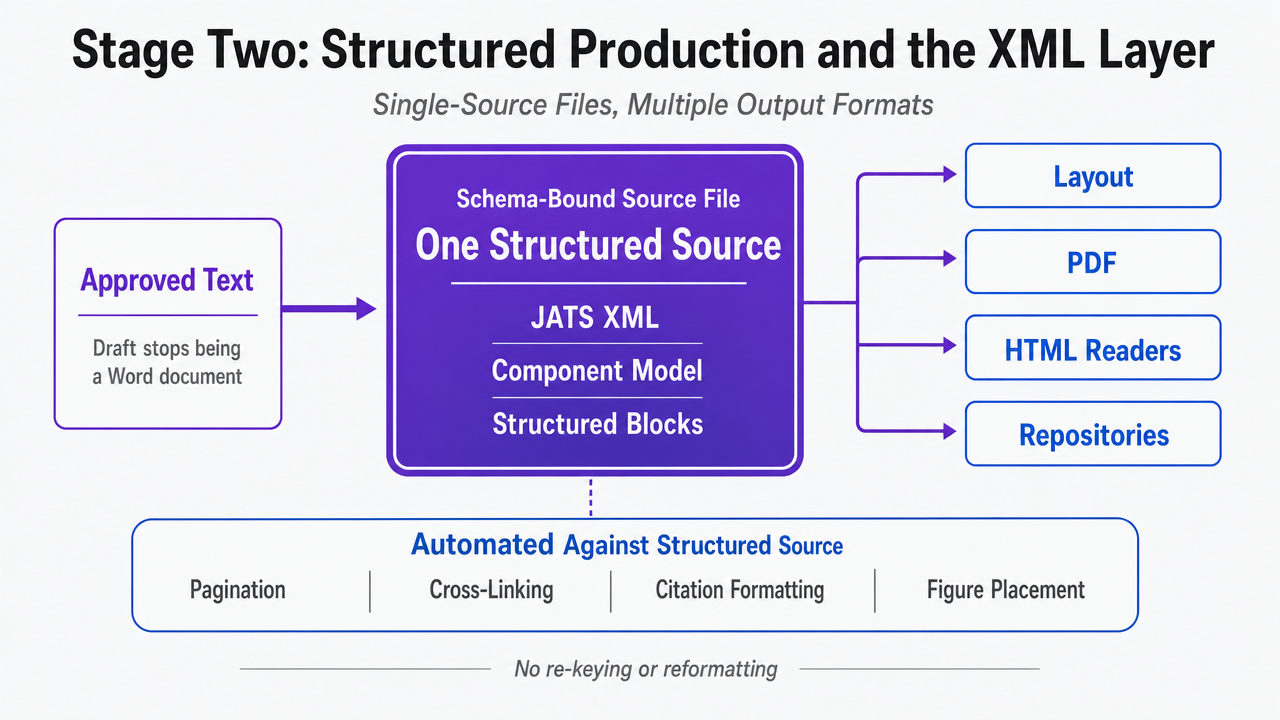 Show how one structured source file renders to multiple output formats
Show how one structured source file renders to multiple output formats
Stage Three: Distribution Across Channels
Once a structured source file exists, distribution stops being a copy-paste exercise and becomes a routing problem. The platform reads the metadata attached to the record—channel targets, audience segment, location, schema type—and pushes the rendered output to each destination on its own schedule. A single approved asset can populate a website page, a syndicated repository, an email module, a feed for a social scheduler, and a structured data block for search engines without any human re-keying the content.
Scholarly publishing has run this pattern for years. An XML-through workflow delivers the same manuscript to journal pages, repositories, and HTML readers from one source, with pagination and linking handled automatically against the structured file 2. The dissemination surface itself has widened: digital platforms now intersect with social media, repositories, and open data to create a broader ecosystem of channels reached from one production record 1.
The marketing implication is that distribution becomes a configuration layer, not a labor layer. AI-driven personalization sits inside this stage, adjusting which variant of a structured asset reaches which segment and on which channel. Peer-reviewed analysis of AI in social marketing finds that personalization and content optimization measurably influence awareness, platform choice, and conversion intent 5. For an in-house team, the practical shift is that channel expansion no longer requires proportional headcount. Adding a new location page, a new service line, or a new syndication partner means adding a routing rule and a metadata tag, not a second production cycle.
Test Digital Publishing at Full Operational Scale
Experience live content publishing workflows and performance measurement with no commitment during your trial period.
Stage Four: Discovery, Metadata, and Archive
Most vendor content skips this stage. That is a mistake. Discovery, metadata, and archive are where a publishing platform either compounds value over time or quietly leaks it. Every asset a team produces has to be findable—by search engines, by internal authors looking for what already exists, and by the platform itself when a structured source needs to be regenerated for a new channel.
Digital content management research treats this stage as the structural problem the field exists to solve. A vast amount of content must be collected, organized, and preserved so that the digital content and the information it carries remain available for future use 8. For a marketing operation, that translates into three concrete functions the platform must run continuously.
- The first is the metadata layer. Every record carries structured tags—content type, service line, location, author, review state, schema markup, canonical URL, internal taxonomy—that make the asset retrievable and machine-readable.
- The second is internal discovery. Authors searching for an existing piece on a topic find it through the platform's index rather than rebuilding it from scratch, which is where most duplicate-content problems originate.
- The third is the archive itself: versioned, queryable, and durable across CMS migrations and rebrands.
The scholarly ecosystem has widened this surface considerably. Digital platforms now intersect with social media, repositories, and open data, expanding the channels a single record reaches and the metadata it must support 1. The practical consequence is that the archive stops being a graveyard. It becomes the source library that feeds the AI layer at every other stage—training context for personalization, retrieval for content reuse, and the input for measurement.
Stage Five: Measurement and the Feedback Loop
Measurement is the stage that decides whether the previous four stages compound or stall. A publishing platform that ends at distribution is a one-way conveyor belt. A platform that closes the loop reads behavioral and performance data from every channel and routes it back into the production queue as a ranked input for the next cycle.
The Deloitte framework for AI-driven personalization is explicit about this dependency. Organizations should assess the full content lifecycle—planning, authoring, governance, and measurement—and make personalization measurable through defined journeys and test-and-learn cycles rather than aggregate dashboard views 10. The platform attaches performance data to the structured record itself: organic sessions, rankings, time on page, conversion events, syndication pickups, and channel-specific engagement all tie back to the same content ID that moved through intake and production.
That tie-back is what makes the feedback loop operational instead of decorative. Underperforming pages surface as candidates for refresh in the next submission cycle. High-converting structures get tagged and replicated across locations or service lines. The Ithaka S+R analysis of the current transformation frames this as data-driven decision-making moving from a reporting function to an infrastructure function, embedded in the workflow rather than reviewed quarterly 9.
For an in-house team, the practical output is a production queue that ranks itself. The platform knows which assets are decaying, which are converting, and which gaps in the library map to active demand—and it presents that ranking as the input to the next intake cycle, not as a separate analytics report.
The AI Layer Running Across All Five Stages
Where AI Touches the Value Chain
AI is not a feature bolted onto one stage of a publishing platform. It runs horizontally across all five. A 2024 analysis of the publishing industry documents that AI
"has been integrated into the entire publishing value chain"
and that the traditional chain is
"being disrupted and disintermediated at every stage,"
from content acquisition through development, production, marketing, and distribution 11.
At intake, AI handles classification and routing: tagging incoming drafts by content type, detecting duplicate coverage against the existing library, and flagging items that need legal or medical review based on topic detection. At structured production, it drafts components against the schema, generates metadata, proposes internal links, and runs first-pass copy edits before a human reviewer sees the record. The same study notes that tools like ChatGPT and Grammarly are now embedded directly in editorial workflows rather than used as side utilities 11.
At distribution, AI sits in the personalization layer, selecting which variant of a structured asset reaches which segment on which channel. Peer-reviewed analysis of AI in social marketing finds that AI-powered personalization and content optimization measurably influence customer awareness, engagement, and conversion intent across channels 5. At discovery and archive, AI improves retrieval through semantic search and auto-generated taxonomies. At measurement, it ranks the next production cycle by reading performance data attached to each record.
The practical consequence is that the publishing platform stops being a destination for content and becomes the operating layer that produces, routes, and reranks it.
Governance and Approval Authority in Regulated Verticals
A horizontal AI layer raises an obvious problem for legal, healthcare, behavioral health, dental, and senior living operators: unreviewed model output is a liability, not an efficiency gain. The peer-reviewed literature on AI in regulated settings is explicit. Deploying AI systems surfaces
"critical ethical and regulatory concerns"
around fairness, accountability, transparency, and data protection, and those concerns apply wherever algorithmic output influences quasi-clinical or quasi-legal decisions 6.
The Deloitte framework for AI-driven personalization handles this by defining tiered oversight: low-risk content moves through "safe lanes," while higher-risk material requires explicit human approval before publication 10. A publishing platform built for regulated verticals enforces that tiering at the platform level rather than in a separate review tool. Approval authority is wired into the routing rules from intake. AI can draft, classify, and rerank, but it cannot move a record into a published state without the signed-off version being the one that ships.
The operational shift for an in-house team is that governance stops being a brake on AI and becomes the precondition for using it at all. Every AI action attaches to a user, a timestamp, and a content version. Reviewers see what changed and approve a specific diff. The platform's value is not that AI handles repeatable production work. It is that AI handles repeatable production work inside a system where human approval is enforceable and auditable.
See How Leading Teams Streamline Digital Publishing Across Channels
Connect with an expert to review integrated workflows that reduce manual publishing steps and deliver measurable efficiency gains for enterprise-scale content operations.
Print-Era Workflow Versus Digital-Native Workflow
The shorthand version of digital transformation is that print became pixels. The accurate version is that the second wave is rebuilding the operating model behind the pixels. The Ithaka S+R 2024 analysis is direct on this point: many of the
"structures, workflows, incentives, and outputs that characterized the print era are being revamped"
in the current transformation 9. That sentence has four nouns, and each one names a different layer that has to change before a publishing platform actually behaves like a digital-native system.
Structures shift from a linear assembly line to a shared infrastructure. The print workflow ran in sequence: write, edit, lay out, print, distribute, archive. A digital-native structure runs in parallel against one structured record, with intake, production, distribution, archive, and measurement all reading and writing to the same source. The output is no longer a finished artifact handed downstream. It is a queryable record that every channel renders against.
Workflows shift from format-specific labor to schema-bound automation. A print-era team built the magazine, then built the website version, then built the email version. A digital-native team edits one component and every channel regenerates. The repeatable production work that filled timesheets in the print model is exactly the work AI now drafts, classifies, and routes inside the platform.
Incentives shift from volume of artifacts to performance of records. Print-era incentives rewarded shipping issues on schedule. Digital-native incentives reward assets that rank, convert, and compound—measured against the same content ID through every channel they reach. Outputs shift accordingly. A print-era output is a finished document. A digital-native output is a structured record that keeps producing new outputs as channels, segments, and AI models change.
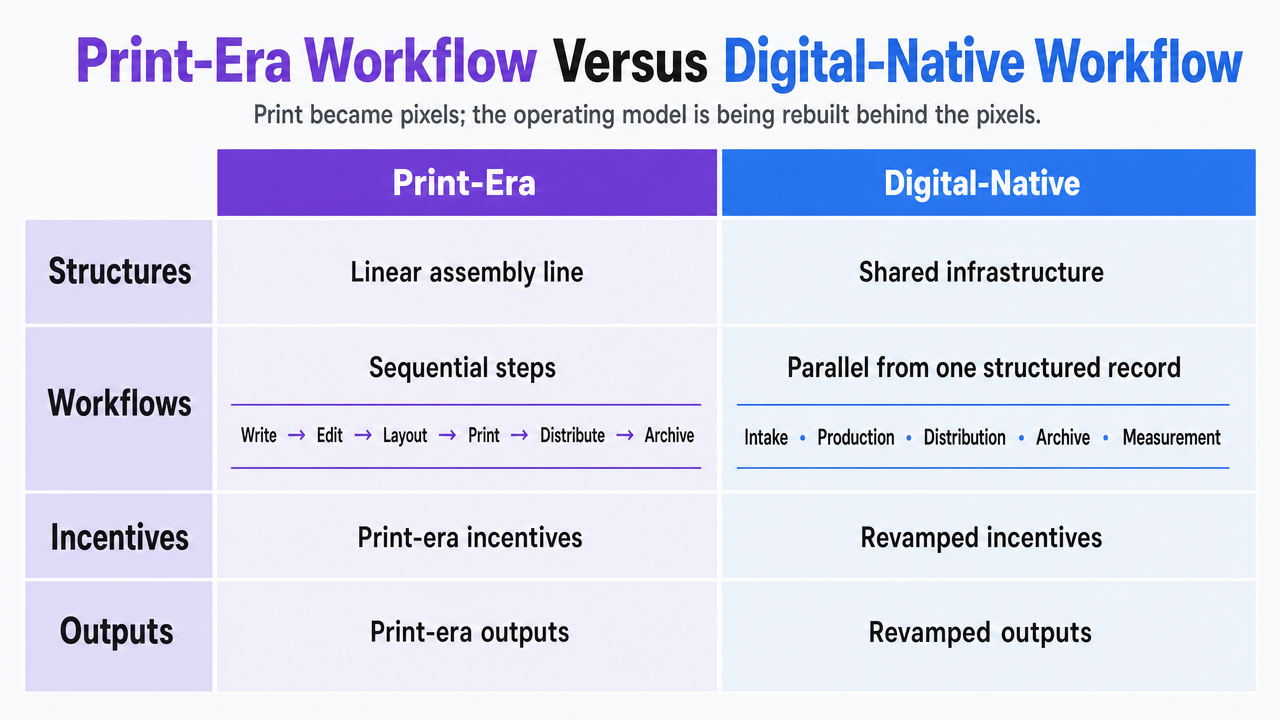 Comparison table contrasting print-era and digital-native operating models across four dimensions cited in the section
Comparison table contrasting print-era and digital-native operating models across four dimensions cited in the section
If You Manage Multiple Locations: Consolidation Economics
A note on audience: the rest of this article applies to any in-house team running a content operation. This section is specifically for VPs at multi-location service businesses—legal groups, behavioral health networks, dental support organizations, home services brands, senior living portfolios, healthcare systems—where the production model is usually a stack of separate tools and agencies, not one platform.
The stack is recognizable:
- A CMS license.
- An SEO platform.
- A social scheduler.
- A content agency on retainer.
- An SEO agency on retainer.
- A PPC agency on retainer.
- Coordination overhead absorbed by in-house FTE hours that never show up on an invoice.
Each line item is defensible in isolation. The cost question is what they total when each location multiplies the work and each handoff adds a briefing cycle.
The enterprise CMS research is direct on the consolidation lever: a CMS
"allows to publish, manage, edit, delete and modify content in a very effective and dynamic way,"
with the data efficiency and collaboration gains compounding as more of the workflow moves inside one system 7. The Deloitte framework reinforces that point at the AI layer—personalization at scale requires a single content lifecycle, not parallel ones glued together at the edges 10.
The directional comparison VPs can run against their own numbers:
| Line Item | Stacked Model | Unified Workflow ||---|---|---|| CMS license | $ per month | included || SEO platform | $ per month | included || Social scheduler | $ per month | included || Content agency retainer | $ per location | replaced by platform execution || SEO agency retainer | $ per month | replaced by platform execution || PPC agency retainer | % of spend | replaced by platform execution || Coordination overhead | FTE hours per week | approval routing inside the platform |
The figures are blanks because every operator's numbers differ. The structural point holds across them: the stacked model charges per tool, per agency, and per location, while the unified workflow charges once and scales the same approval logic across every location record in the platform.
What This Means for the Operating Model
The five-stage supply chain and the horizontal AI layer point to a specific shift in how in-house teams staff and structure content work. The repeatable production labor that used to justify a content agency retainer—drafting variants, formatting outputs, tagging metadata, scheduling distribution—is exactly the work the platform now drafts and routes. The Ithaka S+R analysis frames this as workflows and incentives being rebuilt for a digital-native era, not as faster versions of the print model 9. The labor that survives is the labor that requires judgment: editorial direction, approval authority, regulatory review, and the strategic ranking of what gets produced next.
The practical operating-model question is no longer whether to buy a CMS. It is whether to keep coordinating separate tools and agencies around a website, or to consolidate intake, production, distribution, archive, and measurement inside one governed workflow where AI handles the repeatable work and humans hold the approval gates 10. For VPs running content programs in regulated verticals, Vectoron offers a two-week trial at $599 per month after trial as one way to test that consolidation against the current stack.
Frequently Asked Questions
References
- 1.Scholarly Publishing - Scholarly Communication Library Guide.
- 2.Building an Automated XML-Based Journal Production Workflow.
- 3.Electronic Publishing of Scholarly Communication in the Biomedical Sciences.
- 4.Platforms - Journal Publishing (NYU Libraries Research Guide).
- 5.The Role of Artificial Intelligence in Personalizing Social Media Marketing Strategies and Its Impact on Customer Experience.
- 6.Ethical and regulatory challenges of AI technologies in healthcare.
- 7.Research Paper on Content Management Systems (CMS).
- 8.Chapter 5: Digital Content Management.
- 9.The Second Digital Transformation of Scholarly Publishing.
- 10.AI-driven personalization requires a modern, scalable content platform.
- 11.Artificial intelligence transforming the publishing industry.