
Key Takeaways
- Click metrics are decoupling from AI discovery, so agencies need a defensible mention-tracking workflow to prove visibility on surfaces like Perplexity that lack referrer data 6.
- Distinguish mentions from citations using a fixed taxonomy, then track coverage and share of voice against a constant prompt set to generate portfolio-level KPIs 7.
- Build a versioned prompt library of 40 to 60 questions per client, split roughly 40% consideration, 35% awareness, 25% decision, to mirror the buyer journey 11.
- Run each prompt as a structured capture event recording answer text, citations, sentiment, and source type, since Perplexity outputs shift with model and index updates 8.
- Audit monthly to produce 12 comparable data points per year, balancing volatility against the risk of missing model shifts that move share of voice 8.
- Choose between manual auditing and LLM visibility platforms based on client count, engines monitored, and library size, with most portfolio agencies landing on a hybrid model 9.
- Scale across portfolios through standardization rather than added hours, capping library size and engine count to protect margin as the client roster grows 8.
- Raise mention probability with structured answers, schema, entity consistency, and third-party placements, since answer engines weight outside sources over self-description 2.
Why agency leaders need a defensible mention-tracking workflow
Click-based reporting is losing its grip on the SEO retainer. A Bain consumer survey found that 80% of consumers now rely on zero-click results in at least 40% of their searches, and the firm estimates that AI-first search experiences have already reduced organic web traffic by 15% to 25% for many brands 6. This shift in consumer behavior, particularly across general search, means that sessions and clicks, long-standing metrics in monthly reporting, are decoupling from the discovery surface where buyers now form opinions.
Perplexity operates within this decoupled layer. When a prospect uses Perplexity to compare vendors, summarize a category, or seek recommendations, the client's brand either appears in the answer or it does not. A mention in that answer constitutes the discovery event. Unlike traditional web analytics, there is no referrer string, UTM parameter, or analytics property to track. Agencies that wait for native dashboards from platforms like Perplexity, OpenAI, or Anthropic will be unable to report on this crucial channel.
The effective response is an audit discipline, not merely a tool subscription. A defensible mention-tracking workflow requires three key components: a fixed taxonomy to differentiate a brand mention from a linked citation 7, a prompt library aligned with each client's buyer journey, and a consistent logging cadence to generate share-of-voice data over time. This output becomes a recurring deliverable that agencies can use to justify their retainer, even when traditional traffic metrics decline.
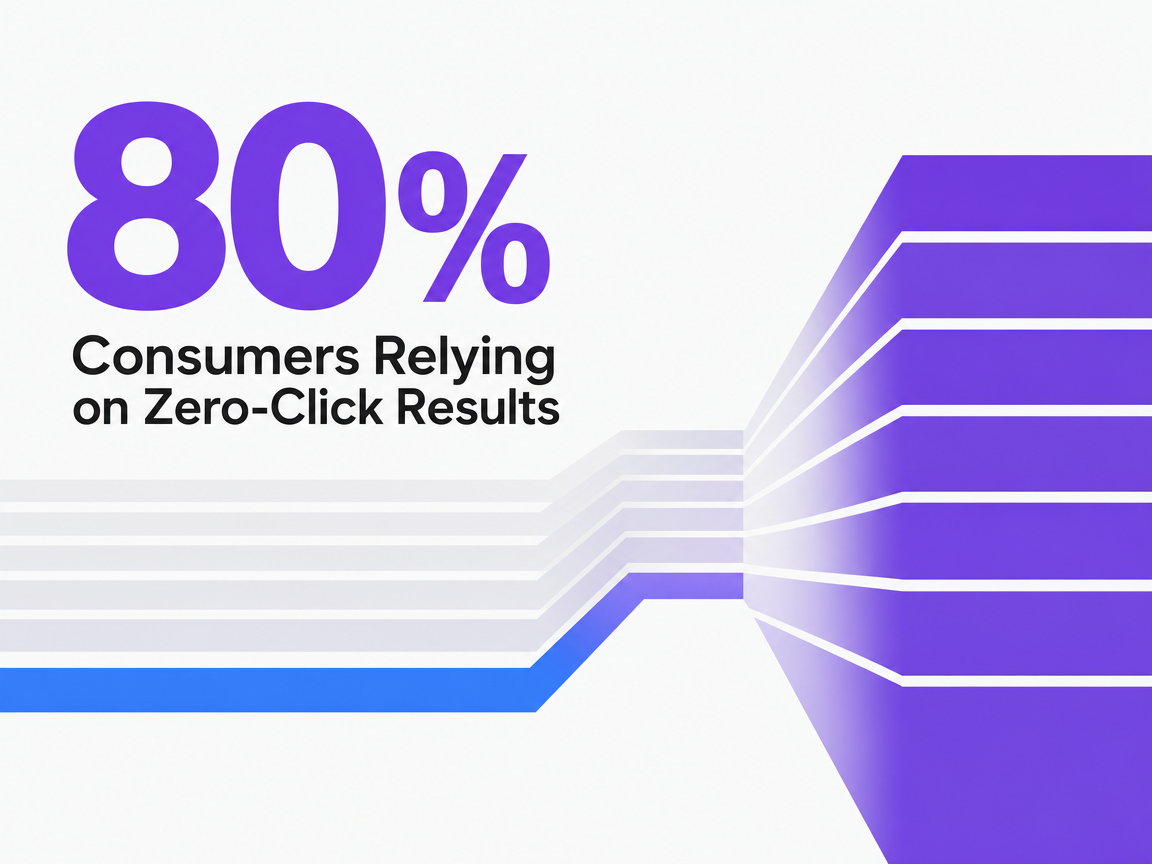 Consumers Relying on Zero-Click Results
Consumers Relying on Zero-Click Results
Consumers Relying on Zero-Click Results
The taxonomy: mention, citation, coverage, share of voice
What counts as a Perplexity mention versus a citation
A mention and a citation are distinct concepts, and confusing them in client reports can undermine the argument for AI visibility as a retainer-worthy service. A mention is defined as any instance where the brand name appears directly within the AI's answer text, irrespective of whether the answer includes a link 7. The brand is explicitly named, and the user sees that name, marking a direct discovery event without necessarily generating outbound traffic.
A citation, conversely, is a narrower concept: it refers to the linked source that Perplexity attaches to an answer, typically presented as a numbered footnote or sidebar reference pointing to a specific URL. Citations can drive clicks, whereas mentions do not. It's common for the two to diverge: a client's brand might be named in the answer body, while all citations point to third-party publishers, review sites, or competitor comparison pages. The opposite can also occur, where the client's domain is cited as a source, but the brand name itself is absent from the natural-language response a user reads.
For auditing purposes, agencies should log each occurrence with three flags:
- "mentioned" (named in answer text)
- "cited" (linked as a source)
- "both."
A mention without a citation indicates awareness without a clear attribution path 7. A citation without a mention suggests the content is contributing to the answer, but the brand name is being omitted during synthesis. Each scenario points to different content optimization strategies, highlighting the importance of a precise taxonomy before building any reporting framework.
Coverage and share of voice as portfolio-level KPIs
Coverage measures the proportion of prompts in a defined audit set that result in any brand presence, whether a mention, a citation, or both. For example, if an agency runs 50 prompts for a client and the brand appears in 18 of them, the coverage is 36%. This metric provides a straightforward answer to a client's fundamental question: "How often does our name appear when buyers ask questions on Perplexity?"
Share of voice introduces a competitive dimension. Within the same 50-prompt set, the agency logs every named brand across all answers, then calculates the client's appearances as a percentage of the total brand mentions captured. If a client has a 12% share of voice against three competitors at 28%, 22%, and 9%, this provides a clear picture of their market position and areas for improvement. Tracking share of voice month-over-month generates a trendline that can effectively replace declining organic sessions charts in retainer reviews.
Both metrics rely on the prompt set remaining consistent across audit cycles. Altering prompts mid-quarter invalidates the baseline and compromises comparisons. This discipline is more akin to survey methodology than keyword tracking: define the measurement instrument, execute it on a schedule, and report changes against a constant pool of questions.
Manually auditing Perplexity for client mentions
Building a prompt library keyed to buyer journey stages
A prompt library is the foundational instrument for all subsequent audit data. If treated casually, it produces unreliable results. However, when treated as a fixed survey instrument aligned with a client's buyer journey, it generates consistent share-of-voice data over time. This library is constructed once per client and then versioned, not repeatedly rewritten.
The library should be structured around three stages of the buyer journey: awareness, consideration, and decision 11. Awareness prompts reflect how a buyer might define a problem before considering specific vendors. For a personal injury law firm in Phoenix, an awareness prompt might be "what should someone do after a rear-end collision in Arizona." Consideration prompts focus on category framing, such as "best personal injury law firms in Phoenix for car accidents" or "how to choose a personal injury attorney." Decision prompts involve direct comparisons and verification, like "is [client firm] a good personal injury attorney" or "reviews of [client firm]."
The distribution of prompts across these stages is important. A practical starting split is approximately 40% consideration, 35% awareness, and 25% decision. Consideration prompts often yield the most competitive share-of-voice data, as this is where brands actively compete for mentions. Awareness prompts assess whether the client's content contributes to category-defining answers. Decision prompts test the brand's resilience in direct comparison queries 8.
The volume of prompts should align with the audit cadence. A library of 40 to 60 prompts per client is suitable for monthly runs without overtaxing the analyst or diluting the signal. Each prompt should have a stable ID, a stage tag, a target intent description, and a date added. Prompts should not be edited mid-quarter; new prompts are appended, not substituted, and are flagged as a separate cohort until they establish a baseline over three audit cycles.
Running the audit: capture, sentiment, source tracing
Effective execution prevents manual audits from becoming inconsistent. Each prompt run must be treated as a structured data-capture event with mandatory fields, rather than a casual screenshot exercise. Perplexity's answers can change due to model updates, indexed sources, and even minor prompt variations, so the capture must be precise at the moment of execution 8.
For each prompt, the analyst records the complete answer text, a list of cited sources with URLs, the date and time, the Perplexity mode used (e.g., default, Pro, or focus filters), and a screenshot of the rendered answer. Capturing the full text is crucial because mention detection is performed against this saved string. Cited sources are logged separately from the answer body to clearly distinguish between mentions and citations according to the established taxonomy.
Sentiment tagging categorizes mentions into three buckets:
- positive (brand recommended or praised)
- neutral (brand named as one option without qualitative framing)
- negative (brand associated with criticism or complaints)
Most mentions for well-managed client accounts will be neutral, serving as the baseline. Negative mentions trigger a separate review workflow, indicating potential issues like review-site contamination or content gaps exploited by competitors.
Source tracing completes the loop. For every citation Perplexity provides, the analyst notes whether the source is the client's own domain, a third-party publisher, a review aggregator, or a competitor-related property. This distribution informs the content team about which off-site assets are contributing to answers and which owned pages are being overlooked, directly guiding future content production decisions 1.
Logging cadence and the monthly audit cycle
The audit should be conducted monthly. A weekly cadence is too volatile for reliable trend analysis, while quarterly audits risk missing significant model updates and indexing shifts that impact share of voice. A monthly rhythm provides 12 comparable data points per year, sufficient to distinguish signal from noise and to justify month-over-month changes in client reports 8.
The audit cycle follows five repeatable steps:
- The analyst executes the full prompt library on Perplexity, capturing answers, citations, and screenshots into a structured log.
- Each captured answer is scored for mentions, citations, or both, with brand and competitor names extracted.
- Sentiment and source-type tags are applied.
- Coverage and share-of-voice metrics are calculated against the fixed prompt set and compared to the previous month's baseline.
- The deltas are incorporated into the client report, with two or three annotated examples explaining notable movements.
Cross-engine parity is a strategic choice, not a methodological requirement. The same prompt library can be run on ChatGPT and Gemini within the same cycle, providing a comparative share-of-voice view across the AI engines buyers actually use 8. While this adds analyst time, it's not a tripling of effort since the prompts and scoring rubric are already established. Agencies that report solely on Perplexity miss the broader cross-engine narrative, which is often what clients seek once they understand the framework.
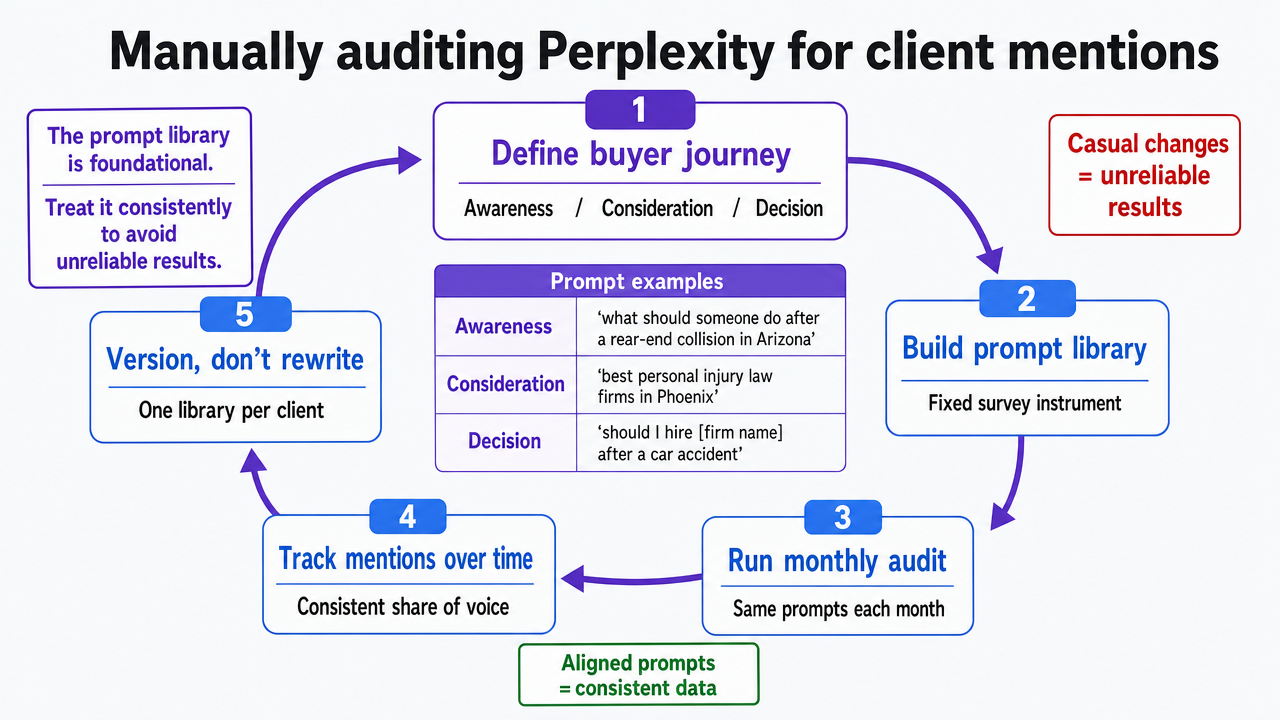 Visualize the five-step monthly audit cycle described in the section, giving readers a clear process reference for executing prompt-based mention tracking
Visualize the five-step monthly audit cycle described in the section, giving readers a clear process reference for executing prompt-based mention tracking
Test real-time AI mention tracking instantly
Validate how your brand is surfaced and referenced in AI-driven search within a live operational environment.
Build versus buy: manual auditing against LLM visibility platforms
A manual workflow becomes unsustainable for more than three or four clients due to the escalating analyst hours. A 50-prompt library, run monthly across two or three engines, including capture, scoring, and source tracing, typically requires four to seven hours per client per cycle 8. This "build" approach generates auditable raw data owned by the agency, but the time commitment grows significantly with an expanding client roster.
The "buy" option involves emerging LLM visibility tools. Platforms like Profound and others automate prompt execution across ChatGPT, Gemini, and Perplexity, extract brand and competitor mentions, and present coverage and share-of-voice metrics via dashboards instead of spreadsheets 9. This category is still nascent, so features, pricing, and the depth of sentiment and source-tracing capabilities vary. Agencies evaluating these tools should test them against their own manual logs for at least one cycle to verify extraction accuracy.
The decision is not mutually exclusive. Most agencies managing more than four clients adopt a hybrid approach: tools handle high-volume prompt execution and dashboarding, while analysts maintain control over prompt library design, sentiment review of flagged answers, and the narrative component of client reports. The platform streamlines data capture, but it doesn't replace the human judgment needed to translate coverage deltas into actionable content recommendations.
Three variables determine the optimal balance:
- Client count: manual auditing is viable for fewer than five active accounts.
- Engine count: monitoring Perplexity alone is manageable manually, but adding ChatGPT and Gemini triples the capture effort without necessarily tripling the insights.
- Prompt library size: a 40-prompt library is manageable by hand, but a 150-prompt library for a complex B2B buyer journey is not 8.
Agencies should assess their current portfolio against these variables before committing to a path, to avoid either margin erosion or unjustified tooling expenditure.
If you manage multiple client accounts: scaling the audit across a portfolio
For agency leads managing 8, 12, or 20 client accounts, the challenge shifts from individual audit mechanics to portfolio-level operations. The audit must produce comparable data across all accounts on a consistent cadence without analyst hours increasing proportionally with the client roster.
Standardization, rather than increased effort, is the key lever. Three variables define the operating model: analyst hours per client per month, audit frequency, and the number of engines monitored. Maintaining a prompt library size near 50 per client and limiting the audit to Perplexity plus one other engine keeps monthly capture within a manageable scope. Expanding to three engines or doubling the library size pushes the manual approach beyond its margin limits 8.
| Approach | Analyst hrs / client / mo | Audit frequency | Prompts / client | Engines monitored |
|---|---|---|---|---|
| Fully manual | 4–7 | Monthly | 40–60 | 1–2 |
| Hybrid + LLM visibility tool | 1.5–3 | Monthly or biweekly | 60–100 | 2–3 |
| Integrated platform workflow | under 1.5 | Weekly capture, monthly report | 100+ | 3+ |
The manual baseline is effective for small client rosters but becomes impractical beyond five active accounts 8. Most portfolio agencies adopt a hybrid model: a visibility platform handles prompt execution and data aggregation, while the analyst retains control over library design, sentiment review, and the narrative for client presentations 9. The integrated path combines capture and reporting into a single workflow but requires committing to a specific tool's extraction logic across all accounts.
A critical portfolio question is whether prompt libraries should be templated by vertical or custom-built for each client. Templating, for instance, using one library for all personal injury firms with brand-name tokens swapped, can halve setup time and generate cross-client benchmarks for agency marketing. Custom libraries capture nuanced buyer journeys but sacrifice the comparative data that transforms a portfolio into a proprietary asset.
Quantify Your Brand’s AI Footprint—See Where and How Perplexity Mentions You
Request a walkthrough of actionable mention tracking and AI visibility analytics designed for agencies managing multiple brands. Benchmark your clients’ presence in Perplexity and validate earned visibility with real data.
Content levers that raise mention probability
Structured answers, entity clarity, and schema
Mention frequency in Perplexity is directly influenced by how effectively an answer engine can extract brand-anchored claims from a webpage. The optimization approach is more focused than full-spectrum SEO, emphasizing schema markup to disambiguate entities, answer-ready structures that place key claims prominently, and consistent entity references across owned properties to ensure the model resolves the brand to a single canonical node 1. Pages that obscure answers with lengthy introductions or split definitions across multiple subheadings provide less usable content for the model.
The benefits are measurable, with qualifications. One vendor study indicated that effective GEO implementation correlated with approximately a 40% increase in brand visibility within AI-generated query responses 3. This figure, from internal research, may not generalize across all industries or AI platforms. Agencies citing this in client presentations should emphasize its directional nature as evidence that structured optimization can improve visibility, rather than a precise forecast.
Practical content edits can be prioritized across four key levers within a monthly production cycle:
- Placing direct answers in the first sentence of relevant sections
- Applying FAQ and HowTo schema to question-and-answer blocks where the audit shows competitors winning
- Ensuring entity consistency across the homepage, about page, and structured profiles
- Embedding numeric claims and statistics in prose
GEO frameworks prioritize fluency, statistics, citations, and quotations as attributes most associated with inclusion in AI responses 3. Each lever is testable: the prior month's audit log identifies prompts where the brand is absent, guiding targeted production efforts rather than broad site rewrites.
Off-site authority: why third-party citations move AI answers
Owned content is necessary but insufficient for optimal AI visibility. Forrester research, as summarized in industry coverage, highlights that most major answer engines, excluding Google, prioritize third-party information about a brand over the brand's self-description when generating responses 2. Perplexity operates within this paradigm. A client's domain, even if perfectly optimized with schema and entity consistency, may still lose share of voice to a competitor mentioned in authoritative industry publications, review aggregators, or category roundups beyond the brand's direct control.
This implies that digital PR and third-party placements are not merely supplementary activities but essential inputs for AI visibility 1. Off-site mentions in publications deemed authoritative by the model serve a dual purpose: they accumulate citations that Perplexity uses as sources, and they strengthen the entity associations that help the brand name survive synthesis into the answer text.
The audit log reveals which off-site properties are already contributing to answers. Source tracing from monthly captures generates a ranked list of domains Perplexity actually cites for the client's target prompts. This list then becomes the priority queue for outreach, contributed content, and review-site optimization, replacing generic backlink building with a targeted focus on properties the answer engine has demonstrated it trusts.
Turning the audit into a client-facing deliverable
Raw audit data alone is insufficient for a retainer review. A compelling client deliverable condenses the monthly log into a four-part report:
- A coverage and share-of-voice scorecard
- A competitive movement narrative
- An annotated answer gallery
- A content priority queue linked to the next production cycle
The scorecard is paramount. It features two key metrics: coverage percentage across the fixed prompt set and share of voice against named competitors, each presented with comparisons to the prior month and the trailing six-month average. The trendline is more significant than a single-month figure, as agencies sell trajectory, not snapshots. Sentiment distribution, broken down into positive, neutral, and negative mentions, supports these headline numbers 8.
The narrative section explains the changes. If share of voice increased from 12% to 17% for the same prompt set, the report identifies which prompts changed status, which competitors lost ground, and which content deployed in the prior month likely contributed. If a competitor gained ground, the report names the third-party sources Perplexity began citing for that competitor and recommends specific off-site placements to counter those properties 2.
The annotated gallery showcases two to four actual Perplexity answers, with brand mentions and citation patterns highlighted directly on the screenshot. This visual proof is crucial for clients who haven't seen their brand appear in an AI answer, making the metrics tangible rather than abstract.
The report concludes with a priority queue: three to five content actions directly tied to specific audit findings. Examples include restructuring a page for entity clarity, adding schema to an FAQ block, pursuing a third-party placement, or publishing a competitor comparison 1. Each action includes an owner, a target ship date, and the prompts it is expected to influence in the next audit cycle. This final column transforms the report from a measurement artifact into a billable production roadmap.
 Potential Brand Visibility Increase from GEO
Potential Brand Visibility Increase from GEO
Potential Brand Visibility Increase from GEO
Frequently Asked Questions
References
- 1.Brand Visibility in AI Search Engines: 9 Strategies.
- 2.Media in the Age of AI: Boosting Brand Visibility in AI Search.
- 3.Understanding the new hidden growth lever – AI answer engines.
- 4.Zero‑Click Searches in 2025: Winning in AI Search.
- 5.What is Zero-Click Search? AI stole your traffic.
- 6.Goodbye Clicks, Hello AI: Zero-Click Search Redefines Marketing.
- 7.AI Visibility 101 and Best Practices for Brands.
- 8.Checking Brand Mentions in AI Search.
- 9.How to Improve Your Brand Visibility in AI Search Engines.
- 10.AI Search Enhances LLM Brand Visibility – Optimize Now.
- 11.AI Search + Zero-Click Results.
- 12.Zero-Click Search and AI Overviews: How to Adapt in 2026.