
Key Takeaways
- Planning from a keyword row hides what Google has already decided to reward; the SERP slate shows the formats, features, and competitors that determine whether a brief can win.
- Ranking systems weigh hundreds of factors per query 1, 4, and AI Overviews now draw more visual attention than the first organic result 12, shrinking the prize a #1 rank represents.
- Briefs should be built around four archetypes—commercial, AI Overview informational, local pack dominant, and video dominant—each forcing a different format decision before writing begins.
- Run SERP analysis as a two-minute triage pass that tags archetype and reduces the outrank set to two or three URLs, then validate outcomes against Search Console 3.
The planning unit problem: keyword row vs. SERP slate
Most agency planning still starts with a spreadsheet row: keyword, monthly volume, difficulty score, current position. That row treats the query as a target. It tells an analyst nothing about the page Google has already decided to reward, the format that wins the click, or the features sitting above the blue links.
A SERP slate is the alternative planning unit. It is the full results page for a query: the AI Overview if one appears, the paid block, the local pack, the video carousel, the People Also Ask cluster, and the ten organic results with their domains, page types, and content angles. Google itself describes ranking as the work of multiple systems sorting hundreds of billions of pages against a specific query, with relevance shaped by hundreds of factors including location, language, and device 1, 4. A keyword row cannot represent any of that. A SERP slate can.
The practical consequence for an agency head is brief quality. A row tells a writer to cover a topic. A slate tells the writer which competitors to outrank, whether the winning format is a comparison table or a clinical explainer, and whether a feature above the fold is already absorbing the click. The rest of this article argues that the slate, not the row, is the unit of work that scales across client accounts.
What Google's own documentation says about ranking signals keyword tools cannot model
Google describes Search as a three-stage pipeline: crawling, indexing, and serving. The serving step is where ranking happens, and Google states plainly that relevance is determined by hundreds of factors, including location, language, and device 1. None of those inputs live inside a keyword tool's database. A volume number is a national or regional average across an unknown mix of intents, devices, and user contexts. The SERP itself is the only place where those factors collapse into a visible answer.
The ranking systems documentation goes further. Google frames ranking as the output of multiple systems working together to organize the web and decide which results, and which features, to show for a given query 4. That phrasing matters for agency planning. It tells an analyst that the page layout, the presence of an AI Overview, the local pack, the video carousel, and the order of organic results are all products of the same ranking machinery. Treating the ten blue links as the competitive set, when Google's own systems may have already promoted a feature above them, misreads what the algorithm has decided.
The public ranking-results page reinforces the point: Google says its systems sort through hundreds of billions of pages to present the most relevant, useful results for a specific query 5. The operative word is specific. Two keywords with similar volume can produce entirely different SERPs because the ranking systems weigh intent, freshness, and format differently for each. Search Essentials adds the inverse warning: meeting best practices does not guarantee a page will appear or rank 2. Keyword tools cannot model any of this. A SERP slate shows the result.
Search Console validates outcomes, but it cannot describe the competitive set
Search Console is the agency's outcome ledger. Its performance report breaks down impressions, clicks, and average position by query, page, and country, which is enough to confirm whether work is moving the right numbers 3. For a head of SEO running 30 or 60 client accounts, that breakdown is how traffic drops get diagnosed and how rankings get tied back to revenue conversations.
The ledger has a blind spot. Search Console reports the queries a client's pages already surface for. It does not show the domains ranking above them, the page formats winning those positions, the AI Overview that may be intercepting the click, or the local pack that pushed organic results below the fold. A query with falling clicks and stable position usually means the SERP itself changed, not the page. The performance report cannot show that change.
SERP competitor ranking fills the gap. It describes the slate that produced the click numbers Search Console records. Used together, the two answer different questions: Search Console asks whether the work is paying off, and SERP analysis asks what the work needs to look like to keep paying off as the page evolves.
Pinpoint SERP competitors and publish test content
Validate your SERP competitor insights by publishing real, live content during your 7-day trial.
How attention actually moves across a results page
Vertical scanning replaced the Golden Triangle
For years, the planning shorthand was the Golden Triangle: users locked their gaze on the upper-left of the page, the top three organic results captured most attention, and ranking position #1 was the prize that mattered. Eye-tracking research has since dismantled that picture. The Golden Triangle has all but disappeared, and users now scan SERPs vertically, moving down the page in a column rather than fixating on a corner 10.
The reason is layout. Modern results pages stack zones, including knowledge panels, People Also Ask blocks, video carousels, image rows, local packs, and shopping units, between the organic positions an agency cares about. A user looking for a service does not skip past those zones politely on the way to result #3. They read down, decide where the answer lives, and click whatever zone matches their intent first.
That changes what ranking position means for brief planning. Position #2 on a SERP with a People Also Ask cluster wedged between #1 and #2 is not the same property as position #2 on a clean ten-blue-link page. A keyword tool reports the same rank for both. Only a SERP slate shows which zones a user's gaze has to cross to reach the client's listing, and whether anything above the fold is likely to absorb the click first.
Mobile changes which competitors are actually seen
Device context rewrites the competitive set. Google's own large-scale work on mobile search behavior shows that users interact with the mobile interface differently than they do on desktop, which means the slate of competitors an agency should be planning against is not identical across devices 8. A query that surfaces a roomy ten-result page on desktop can collapse, on a phone, into a paid block, a local pack, and a single visible organic result before the user has to scroll.
Paid placements absorb a disproportionate share of that early attention. Google-published eye-tracking data found that on mobile search result pages, 85% of visitors look at the top two AdWords results 9. The scope is narrow and worth stating plainly: this is mobile, and it is paid placements at the top of the page, not a general claim about organic CTR.
For a head of SEO running accounts in legal intake, dental implants, or senior living tours, the planning consequence is direct. If the mobile SERP for a target query is fronted by two paid units and a local pack, the real competitor for organic attention is not the domain ranking at position #3 on desktop. It is whichever listing first appears below the fold a user has to scroll past advertisers to reach.
 Visitors looking at top 2 AdWords results on mobile
Visitors looking at top 2 AdWords results on mobile
Visitors looking at top 2 AdWords results on mobile
AI Overviews are now part of the competitive set
The top of a results page is no longer reliably an organic listing. When an AI Overview appears, it receives more visual attention than the first ranked organic result, according to recent eye-tracking work measuring how users distribute their gaze across SERP zones 12. That finding rearranges what a keyword tool's rank number actually buys an agency. A client sitting at position #1 on a query that triggers an AI Overview is not at the top of the page anymore. The summary is.
The competitive set has expanded to include a zone the client cannot rank in directly. The AI Overview is generated, not crawled into existence as a separate page, and it pulls from sources Google's ranking systems decide to surface alongside the answer 4. Companion research on generative results above traditional listings frames this as a new layer of competition for attention, not a cosmetic SERP change 11. For an agency planning content across legal, dental, or senior living accounts, that means the brief has to answer a different question: not only how to rank, but whether the page is the kind of source an AI Overview cites or summarizes.
The planning consequence is straightforward. Queries that trigger an AI Overview should be flagged during SERP analysis and treated as a separate archetype with their own brief instructions, covered later in the article. Keyword volume on those queries overstates realized organic traffic, because the summary intercepts clicks before users reach the organic list. Volume describes the question being asked. The SERP slate, AI Overview included, describes what users see when they ask it.
Four SERP archetypes and the brief-level decisions each one forces
Commercial SERPs dominated by transactional pages
A commercial SERP is the easiest archetype to misread from a keyword row. Volume looks healthy, difficulty looks workable, and the row hides the fact that the first page is a wall of category and product pages from established retailers or service providers. Google's ranking systems have already decided this query rewards transactional intent, and editorial content has been pushed off the slate 4.
The brief-level decision is format, not topic. If nine of ten results are pricing pages, comparison tables, or service-detail templates, a 2,000-word explainer will not earn position. The page has to match the transactional shape Google is rewarding: visible pricing or pricing logic, structured comparison, clear conversion paths, and the schema the winning pages use.
For a dental DSO targeting "clear aligners cost" or a legal client targeting "workers comp attorney fees," the SERP analysis tells the analyst to brief a money page, not a blog post. The keyword tool would have suggested either. The slate forces the right one.
Informational SERPs with an AI Overview on top
When the AI Overview triggers, the planning math changes. Recent eye-tracking work shows that the summary draws more visual attention than the first ranked organic result 12, which means the keyword's reported volume overstates the organic clicks the winning page will actually capture. A position #1 ranking on this archetype is a smaller prize than the rank number suggests.
The brief shifts in two directions at once. First, the page has to be the kind of source the Overview cites or summarizes: tight definitional paragraphs near the top, clear subheaders that match question phrasing, and structured data where the entity supports it. Second, the page has to earn the click after the summary appears, which means it has to promise depth the Overview cannot deliver, like a worked example, a clinician's caveat, a state-by-state breakdown, or a comparison the generated answer skipped.
For senior living queries such as "what is memory care," the brief should assume a portion of demand resolves inside the Overview and plan the page to capture the residual: the families who want a tour, a checklist, or a pricing conversation, not a definition 11.
Local pack dominant SERPs in service verticals
Local pack dominant SERPs reorder the competitive set. Three map listings sit between the top of the page and the first organic result, and on mobile that stack often consumes the entire first viewport before the user has scrolled 8. The competitor that matters is the pack, not the domain ranking at position #2.
The brief-level decision splits the work in two. The organic page still needs to rank, but the larger lever is the Google Business Profile feeding the pack: review velocity, category accuracy, service-area definitions, and primary-photo quality. An analyst briefing a "emergency plumber [city]" page in isolation is solving the wrong half of the SERP.
For agencies running home services or multi-location dental accounts, the SERP slate forces a paired brief: an organic page tuned to the queries the pack does not satisfy (comparison, pricing context, service explainers) and a profile task list tuned to the pack itself. Keyword volume on the head term cannot indicate which half deserves more analyst hours that week.
Video dominant SERPs and visual-first intent
Some queries surface a video carousel above the organic list, and Google's ranking systems have decided the visual format answers the question better than text 5. "How to floss with braces," "what does a memory care unit look like," and "deposition preparation" all skew this way, and a text-only brief on those queries enters the SERP at a structural disadvantage.
The brief-level decision is to produce or commission the video alongside the page, not after it. The text article hosts the asset, transcript, and structured data; the video competes inside the carousel where the user is already looking. Without the visual layer, the page is planning to outrank a format the SERP has already rewarded over text 4.
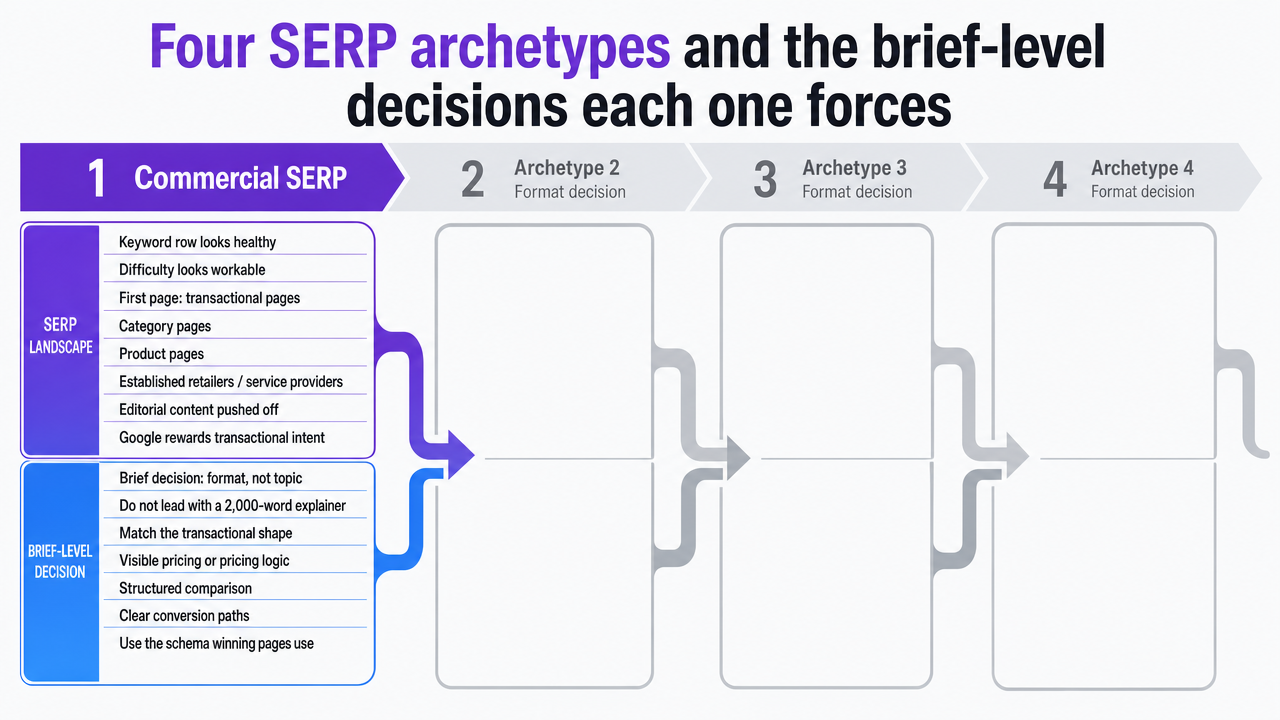 Visualize the four SERP archetypes and the format decision each one forces, directly supporting the section's framework
Visualize the four SERP archetypes and the format decision each one forces, directly supporting the section's framework
See How Precise SERP Competitor Tracking Outperforms Keyword Lists
Request a walkthrough of workflow-driven SERP competitor analytics built for agencies managing complex account portfolios—benchmark against live market leaders, not just keywords.
A workflow for converting SERP analysis into briefs without doubling analyst hours
The objection most agency leads raise to SERP-first planning is time. A keyword row takes seconds to triage. Pulling a full slate, reading the competitors, and identifying features above the fold sounds like a research project an analyst cannot afford to run on 300 target queries per client. The workflow below treats SERP analysis as a triage pass, not a deep dive, and pushes depth only where the slate justifies it.
- Archetype tagging. An analyst opens the live SERP for each priority query and records four data points: dominant page format in the top five organic results (money page, explainer, listicle, video, forum), presence of an AI Overview, presence of a local pack, and presence of a video carousel. That tag set takes under two minutes per query and produces the archetype classification the brief will inherit. Google's ranking systems decide which features to show per query 4, so this tag is the closest an analyst gets to reading the algorithm's verdict.
- Competitor reduction. Inside each SERP, only two or three of the ten organic listings are real competitors for the client's domain authority, format, and intent match. The brief inherits those two or three URLs as the outrank set, not all ten. Search Console then confirms whether the page is moving against that reduced set over time 3.
- Brief generation against the tag plus the outrank set. The writer receives the archetype, the format Google is rewarding, the AI Overview flag if present, and the specific URLs to beat. Volume and difficulty remain on the row as context, not as the planning input. The slate is.
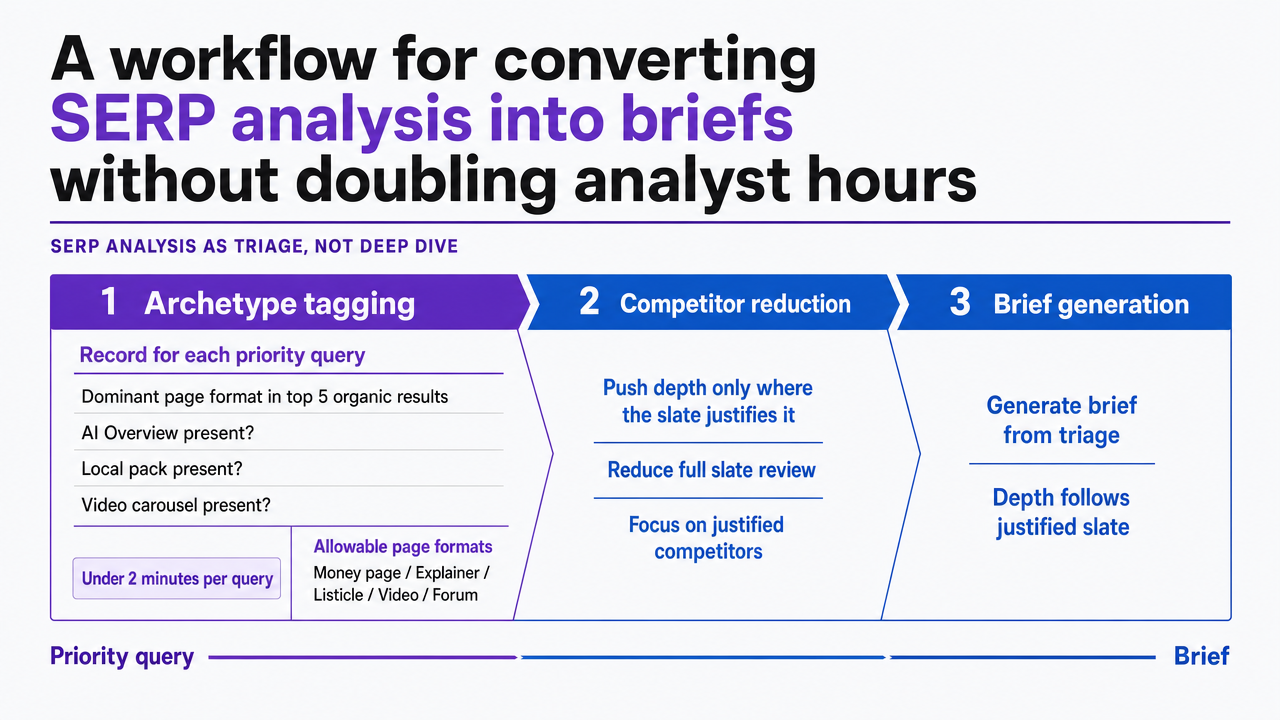 Visualize the three-step triage workflow described in the section: archetype tagging, competitor reduction, brief generation
Visualize the three-step triage workflow described in the section: archetype tagging, competitor reduction, brief generation
If you manage multiple client accounts: the analyst-hours math
A note on scope before this section develops: the rest of the article applies to any team running SERP-first planning. This part is written for agency leads operating a portfolio, where the constraint is analyst hours per account rather than data access or tooling budget.
The portfolio math is what makes or breaks a methodology change. A head of SEO running 30 client accounts with an average of 200 priority queries each is governing 6,000 planning decisions per cycle. Cutting two minutes per decision saves 200 hours. Adding two minutes costs the same. That is the budget any new workflow has to fit inside, and it is why keyword-row planning persists despite producing weaker briefs.
The triage pass described earlier holds up under that math because it caps the per-query cost. The variables a lead can hold their team to are explicit: accounts managed, priority queries per account, minutes per query in the archetype tag pass, and minutes per brief on the queries that pass triage into deep analysis. The table below uses those variables as inputs, not benchmarks. Each agency fills them in from its own utilization data.
| Input | Keyword-row planning | SERP-slate planning |
|---|---|---|
| Triage minutes per query | Volume + KD scan (~30 sec) | Archetype tag pass (~2 min) |
| Queries advanced to full brief | All priority queries | Reduced set after archetype + outrank filter |
| Brief inputs | Topic, volume, KD | Archetype, format, 2–3 outrank URLs, feature flags |
| Revision cycles per brief | Higher (intent misreads surface late) | Lower (format decided before writing) |
The honest read is that SERP-slate planning costs more minutes at triage and recovers them at the brief and revision stages, because the writer is no longer guessing at format. Whether the trade nets positive for a given agency depends on how often its current keyword-row briefs get sent back. Search Console can answer that question per account by showing which published pages stalled against the competitive set they were meant to outrank 3.
Where competitor-ranked planning fits inside an approval-first execution model
SERP-slate planning produces sharper briefs, but briefs still have to ship. The gap most agencies fight is between the analyst who tagged the archetype and the writer, the editor, and the client approver who each touch the page before it goes live. Every handoff is a chance for the format decision Google rewarded to get edited back into a generic explainer.
The fix is workflow, not more analysis. The archetype tag, the outrank URLs, and the AI Overview flag have to travel with the brief through every approval gate, so the writer sees the same competitive verdict the analyst read off the SERP, and the client approver sees why the page looks the way it does. Google's ranking systems decide which formats win per query 4; the production chain has to carry that decision intact.
Approval-first AI execution platforms, including Vectoron, are built to hold that chain together: the SERP read, the brief, the draft, and the publish step sit in one governed loop with human sign-off at each gate.
Frequently Asked Questions
References
- 1.In-Depth Guide to How Google Search Works | Documentation.
- 2.Google Search Essentials (formerly Webmaster Guidelines).
- 3.How To Use Search Console | Documentation.
- 4.A Guide to Google Search Ranking Systems | Documentation.
- 5.How Does Google Determine Ranking Results - Google Search.
- 6.Eyetracking in Online Search.
- 7.Eye-Tracking Analysis of User Behavior in WWW Search.
- 8.A Large Scale Study of Wireless Search Behavior: Google Mobile Search.
- 9.Eye Tracking Study.
- 10.Eye-Tracking Study: How Users View Google Search Result Pages.
- 11.An Eye Tracking Study: Are AI Overviews Changing Search Behavior?.
- 12.An Eye Tracking Study: Are AI Overviews Changing Search Behavior?.