
Key Takeaways
- Perplexity visibility requires a four-layer measurement stack: versioned prompt sets, citation and brand-mention capture, source verification, and referral correlation against GA4 data.
- Brand-mention frequency and citation share are distinct signals — a brand can be named in prose without its domain being cited, and each gap points to different content fixes.
- Citation reliability cannot be assumed; Perplexity returned 37% of news queries with mis-attribution, syndication, or fabricated URLs 2, so verification state belongs in every client report.
- Manual tracking breaks near fifteen accounts, where vertical context, verification quality, and citation-dense content production 1can no longer scale without a shared system.
Why agency reporting breaks when Perplexity enters the scope
There is no Search Console for Perplexity. No verified property, no impression count, no query report, no click curve. The moment an agency adds Perplexity visibility to a client's scope of work, the reporting stack that took years to standardize across Google, Bing, and social referral data stops producing comparable numbers.
The product itself compounds the problem. Perplexity operates as a live web search answer engine that synthesizes responses with inline citations users can click to verify 3. A neutral product review hosted by NIH/PMC characterizes it as a real-time, citation-backed research tool rather than a conversational interface 13. That means the unit of visibility is not a ranked link, it is a sentence-level citation inside a generated answer that may or may not appear depending on prompt phrasing, model selection, freshness, and which publisher sources the engine pulled that day.
Three reporting assumptions break at once:
- Impressions cannot be measured because the engine does not publish them.
- Position cannot be measured because answers are not ranked lists.
- Click data is partial at best, since referral attribution depends on whether the user clicks the citation chip, and Perplexity's chip behavior produces weaker downstream traffic than other AI platforms.
For a head of SEO running ten to fifty accounts, this creates a methodology gap, not a tooling gap. Buying another dashboard will not solve it. What works is a portable measurement stack — one set of definitions, prompts, and capture rules that can be cloned across clients in different verticals, then wired into the reporting cadence already in place. The next section defines that stack in four layers.
The four-layer tracking stack
Layer 1: Prompt sets as the unit of measurement
The first decision in any Perplexity tracking program is what to measure visibility against. Keywords do not map cleanly to an answer engine. A single client question — say, who the best estate planning attorneys in Phoenix are — can be phrased a dozen ways, and each phrasing pulls different sources into the cited set. The portable unit is not a keyword. It is a prompt set.
A prompt set is a fixed, versioned list of natural-language queries representative of how a client's prospects actually ask. For a behavioral health client, that might be 30 prompts covering condition-based queries, treatment-comparison queries, insurance-coverage queries, and local intent queries. The set is locked at the start of a measurement cycle so week-over-week changes reflect engine behavior, not query drift.
Three rules keep prompt sets useful across a portfolio:
- Prompts must be written in the voice of the prospect, not the agency — Perplexity is tuned for natural research questions 3, and synthetic SEO phrasing produces unrepresentative citation patterns.
- Each prompt is tagged with intent class, funnel stage, and geography so the resulting citation log can be sliced the same way ranking reports are sliced today.
- The set is split between branded prompts (does the client appear when named directly) and unbranded prompts (does the client appear in a category answer where the brand is not mentioned in the prompt). The unbranded ratio is the real visibility signal.
Run the set on a fixed cadence — weekly is the common floor — and log each run with timestamp, model selection, and any account state. Without this discipline, every downstream layer in the stack drifts. With it, the same prompt set can be cloned across thirty clients in under an hour of analyst time per cycle.
Layer 2: Citation capture and brand-mention frequency
Once prompt sets are running, the second layer captures what came back. Two distinct signals matter, and conflating them is the most common reporting error agencies make at this stage.
The first signal is brand-mention frequency: the share of prompts in a set where the client's brand name appears anywhere in the answer text. The second is citation share: the share of prompts where the client's domain (or an owned property like a doctor profile, a help-center article, or a category page) appears in the inline citation chips Perplexity attaches to its answers 3. A brand can be mentioned without being cited, and a domain can be cited without the brand being named in the visible prose. Both states have different content implications.
Capture should record, per prompt run:
- The full answer text
- Every citation chip URL
- The position of each chip in the answer
- Whether the client domain appears in citations
- Whether the client brand string appears in prose
- Which competitor brands and domains appear in either field
Competitor capture is non-negotiable — Perplexity's marketing-use-case page positions the tool for exactly this kind of sentiment and source synthesis 8, and the same logic applies in reverse when an agency monitors the client's competitive set.
Storage matters more than tooling choice. A flat citation log with one row per prompt-run-citation triplet lets the same dataset feed weekly client reports, quarterly trend analysis, and the Layer 4 referral correlation step downstream. Agencies that store only screenshots or aggregate counts lose the ability to re-slice the data when a client asks why a competitor's share moved or which prompt classes are driving the change.
Layer 3: Source attribution and the citation reliability problem
The third layer is where most tracking programs quietly fail. A citation chip is a claim by the engine that a specific URL supports a specific sentence in the answer. That claim is not always true.
A Columbia Journalism Review study tested eight AI search tools, including Perplexity and Perplexity Pro, on their ability to identify and cite news sources accurately. Perplexity answered 37% of tested news queries incorrectly, with failure modes spanning wrong source attribution, fabricated URLs, syndicated links pointing to republishers rather than originals, and apparent disregard for publishers' robots.txt preferences 2. The scope matters: the study tested news queries on eight tools, not all Perplexity queries across all verticals. The reliability ceiling for category and commercial queries an agency cares about may be higher or lower. Treat the figure as a planning anchor, not a universal error rate.
The operational consequence is that Layer 3 must verify, not just record. For every citation logged in Layer 2, the workflow needs to confirm three things:
- That the cited URL resolves to a live page
- That the cited page actually contains the claim Perplexity attributed to it
- That the citation points to the canonical source rather than a syndicated or aggregator copy
A neutral product review of Perplexity hosted by NIH/PMC characterizes the tool as real-time and citation-backed 13, which is the design intent — but design intent and field accuracy are not the same measurement.
Verification should be sampled, not exhaustive. A defensible cadence is full verification on every branded-prompt citation and a 20% sample on unbranded-prompt citations. Tag each citation in the log with a verification state: verified, mis-attributed, syndicated, fabricated, or unresolved. The mis-attributed and syndicated counts become a reportable metric in their own right — agencies in regulated verticals (legal, healthcare, financial services) have a duty to flag when an AI engine is misquoting a client's content, and the tracking workflow is the only place that surfaces it.
Source attribution data also feeds back into content strategy. When citations consistently point to a syndicated copy of a client's article rather than the original, the client's canonical signaling needs work. When fabricated URLs appear under a client's brand, that is a brand-safety incident worth a separate alert, not a footnote in a monthly report.
Layer 4: Referral correlation and the crawl-to-refer gap
The fourth layer connects mention data to traffic data, and this is where the stack must defend itself against a common executive question: if the client is being cited more in Perplexity, why isn't organic traffic moving in proportion?
Digiday's 2025 analysis of AI referral traffic found that Perplexity had the lowest crawl-to-refer ratios among major AI platforms in the period covered, meaning the engine crawls publisher and brand content at high volume but sends comparatively little click traffic back 14. The implication for client reporting is structural. Mention frequency and citation share are leading indicators of visibility inside the answer engine, but they cannot be expected to convert to referral sessions at the same rate as Google organic clicks or even ChatGPT citations. Reporting that treats them as equivalent will misread Perplexity as underperforming when it is doing exactly what the platform does.
Layer 4 builds two parallel views:
- The direct referral view: GA4 sessions with perplexity.ai as source, segmented by landing page and matched against the URLs the citation log shows were cited that week.
- The mention-weighted visibility view: citation share and brand-mention frequency tracked independently as upper-funnel exposure metrics, with no expectation that they convert one-to-one.
Both views appear in the client report. Neither replaces the other.
The correlation work itself is straightforward once the citation log from Layer 2 exists. Join the citation URLs to GA4 referral data by date and landing page, then calculate a crawl-to-refer ratio for the client and compare it against the platform-level benchmark. When the client's ratio sits at or below the platform average, the takeaway is that Perplexity is functioning as an awareness surface, not a traffic surface — and the content and channel mix needs to reflect that, not fight it.
 Incorrectly answered news queries by Perplexity
Incorrectly answered news queries by Perplexity
Incorrectly answered news queries by Perplexity
Track and analyze brand mentions in real time
Monitor and report on Perplexity AI mentions across campaigns without workflow delays or manual effort.
The content lever that feeds the stack
A tracking stack only earns its keep when the agency can also move the numbers it produces. The lever that moves them is the content itself, and the academic record on what works inside generative engines is unusually specific.
The GEO paper from arXiv tested content modifications across multiple generative engines and found that adding citations, quotations from relevant sources, and statistics produced up to a 40% visibility improvement across generative engines overall and up to a 37% lift on Perplexity specifically 1. The study scope is worth naming: researchers tested controlled content variations against generative engines including Perplexity, measuring how often the modified source appeared in cited answers versus a baseline. The result is not a guarantee on any single client page. It is directional evidence that the same formatting choices a careful trade publication already makes — named sources, direct quotes, hard numbers with citations — are the formatting choices that earn Perplexity citations.
What this means operationally is that content production has to be retooled to produce citation density as a default, not as an editorial bonus. A 1,200-word client article with two embedded statistics, three named third-party sources, and a direct quote from a recognized authority is structurally different from the same word count delivered as generalized prose. The first is extractable. Perplexity can lift a sentence, attach a citation chip, and present it as a verifiable claim — which is exactly the product behavior described in the platform's own documentation 3and reinforced by neutral product reviews 13. The second produces nothing the engine can confidently quote.
Three production rules follow from the evidence:
- Every commercial-intent page should carry at least one externally citable statistic with a linked source.
- Every category or comparison page should include at least one direct quote attributed to a named person or organization.
- Every freshness-sensitive topic — pricing, regulation, market data — should carry a visible last-updated date and a refresh cadence the agency can defend.
This is also where portfolio economics start to bite. Producing citation-dense, freshness-tuned content across thirty client accounts in different verticals is not a copywriting problem solved by adding writers. It is a production-system problem, which is the subject of the portfolio economics section below.
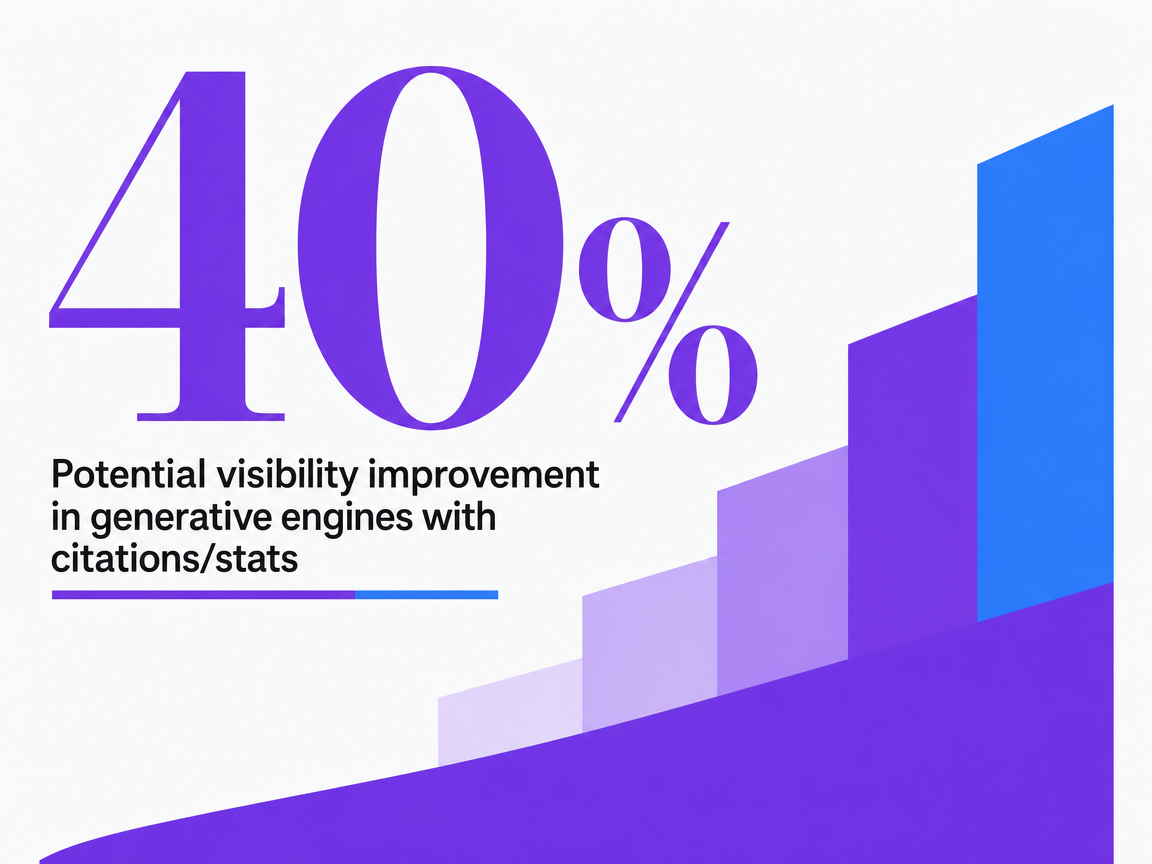 Potential visibility improvement in generative engines with citations/stats
Potential visibility improvement in generative engines with citations/stats
Potential visibility improvement in generative engines with citations/stats
Designing around the publisher ecosystem shift
The source pool Perplexity draws from is not static, and a tracking framework built against last quarter's citation distribution will misread the next one. Three product moves in particular reshape what an agency should expect to see in the citation log.
The first is the steady expansion of the publisher program. Perplexity has continued adding licensed publishers to its source ecosystem, including a recent batch of 15 new media partners 4and a major partnership with Gannett that routes a large local-news network into both Perplexity's AI search and the Comet browser 11. For agencies running unbranded prompt sets in geographies Gannett covers, expect local-news domains to take more citation share over time, particularly on commercial-local queries where a client previously held the chip. That is not a content quality verdict on the client — it is an ecosystem reweighting the agency needs to label in reports.
The second is Comet Plus, a $5 subscription delivering premium journalism from launch partners inside the Perplexity environment 5, 12. Premium publisher access concentrated behind a subscription tier can skew which sources the engine treats as authoritative on the topics those publishers cover. Track which client-relevant verticals overlap with Comet Plus partners and watch citation share on those prompt subsets separately.
The third is Perplexity Pages, a native publishing format that turns research into structured content inside Perplexity itself 7. Combined with Deep Research, which conducts dozens of searches and reads hundreds of sources per query 6, the engine is increasingly capable of citing its own native artifacts and synthesizing across far wider source sets than a single answer reveals. The tracking implication is twofold. Native Pages become a candidate publishing channel worth testing for clients with research-heavy content. And Deep Research outputs need their own capture rule in Layer 2, because the citation density per answer is materially higher than standard mode and skews any unweighted average.
Practical step: add a publisher-ecosystem column to the citation log that tags each cited domain as licensed partner, Comet Plus partner, native Perplexity surface, or independent. The agency that knows where its citation share is coming from can defend the report when the mix shifts.
 Map the four publisher-ecosystem source classes the section instructs agencies to tag in their citation log, making the taxonomy scannable
Map the four publisher-ecosystem source classes the section instructs agencies to tag in their citation log, making the taxonomy scannable
See How Leading Agencies Track Brand Mentions in Perplexity AI—At Scale
Request a walkthrough of automated frameworks purpose-built for high-volume mention tracking in Perplexity AI, designed for agencies managing multi-brand portfolios. Learn how to centralize insights for actionable reporting across all clients.
If you manage multiple clients: portfolio economics of tracking
A note on audience scope: this section addresses heads of SEO running a book of accounts, not in-house teams tracking a single brand. The math below only matters at portfolio scale.
Manual Perplexity tracking is deceptively cheap at one client. An analyst writes a 30-prompt set, runs it weekly, copies the answers and citation chips into a sheet, verifies a handful of attributions, and joins the result to GA4 referral data. The whole loop fits inside three to four hours per client per month. At five accounts, that is a part-time slice of one analyst's calendar. The work feels artisanal in a good way.
The economics turn at roughly fifteen accounts. Prompt sets multiply, vertical-specific citation verification compounds, the publisher-partner column added in the previous section needs maintenance as Perplexity keeps expanding its source ecosystem 4, 11, and Deep Research outputs — which read hundreds of sources per query 6— produce citation logs that are an order of magnitude denser than standard mode. The same four-hour loop becomes six or seven, and the agency is now spending the equivalent of a full analyst headcount on tracking alone, before any content production or strategy work.
By thirty accounts, manual tracking is no longer an analyst problem. It is a staffing problem. Three structural constraints kick in at once:
- Verification quality degrades because no one analyst can hold context across thirty verticals.
- Reporting cadence slips because the citation log falls behind the weekly run schedule.
- The content lever — the citation-dense production work that earned a 37% visibility lift in the GEO study 1— cannot be fed at the rate the tracking stack now demands.
The variables to model in a portfolio plan are straightforward: hours per client per cycle, prompts per client per week, citation verification sample rate, and the cycle frequency itself. Hold the first three constant and the labor line grows linearly with client count. Hold client count constant and labor still grows as Perplexity's source ecosystem widens and Deep Research adoption raises citation density per answer.
The implication for an agency head is not that tracking should be cut. It is that tracking and the content production feeding it have to share a system. Productized content workflows that generate citation-dense, freshness-tuned pages on a defensible cadence — and log their own outputs into the same citation-tracking schema — are the only configuration that holds margin past fifteen accounts. Vectoron is built around that configuration: strategist-driven content production wired to the same approval and measurement loop the tracking stack already runs in.
Wiring the stack into existing client reporting
The tracking stack only matters if account leads and clients actually see it. The goal at this stage is integration, not invention — slotting Perplexity data into the reporting cadence already in place rather than launching a separate AI visibility deck no one reads after month two.
Three placements carry most of the value:
- Weekly internal scorecard: citation share and brand-mention frequency from the Layer 2 log sit next to ranking and impression deltas as a separate visibility column, not blended into a composite score.
- Monthly client report: the Layer 4 dual view does the work — direct perplexity.ai referral sessions appear in the traffic section, while citation share and mention frequency appear in a labeled awareness section with the crawl-to-refer benchmark from Digiday's 2025 analysis as context 14.
- Quarterly business review: the publisher-ecosystem tag from Layer 2 explains shifts in source mix — useful when a competitor's chip share rises because a Gannett-partnered local paper started getting cited 11, not because the client's content slipped.
Two operational rules keep the integration honest. Verification state from Layer 3 must appear on any citation surfaced to the client; an unverified or syndicated chip cannot be reported as a clean win. And the prompt set version used in each cycle goes in the report footer, so changes to the set are visible rather than hidden inside the methodology.
Frequently Asked Questions
References
- 1.[PDF] GEO: Generative Engine Optimization - arXiv.
- 2.AI Search Has a Citation Problem - Columbia Journalism Review.
- 3.Getting Started with Perplexity - Perplexity.
- 4.Perplexity Expands Publisher Program with 15 New Media Partners - Perplexity.
- 5.Introducing Comet Plus - Perplexity.
- 6.Introducing Perplexity Deep Research - Perplexity.
- 7.Introducing Perplexity Pages - Perplexity.
- 8.Perplexity for Marketing - Perplexity.
- 9.Perplexity Enterprise for Advertising - Perplexity.
- 10.Why we're experimenting with advertising - Perplexity.
- 11.Welcoming Gannett to the Perplexity Publisher Program - Perplexity.
- 12.Announcing Comet Plus Launch Partners - Perplexity.
- 13.PRODUCT REVIEW / ÉVALUATION DE PRODUIT - PMC - NIH.
- 14.In Graphic Detail: The state of AI referral traffic in 2025 - Digiday.