
Key Takeaways
- Profound suits enterprise agencies needing deep prompt libraries and multi-region segmentation, but pricing rarely fits accounts with thin prompt volumes or small monitoring budgets.
- Similarweb AI shows answer-engine visibility next to organic search share, turning AI presence into a defensible SEO retainer line when categories shift toward generative discovery.
- Semrush GEO tracking layers AI visibility onto existing keyword workflows, offering the lowest-friction entry point but lighter sentiment, citation, and entity-level depth than dedicated tools.
- Brandwatch covers upstream conversation across social, forums, and news with AI-assisted sentiment and anomaly detection, feeding the discourse that models eventually cite back to prospects 11.
- Brand24 delivers accessible real-time mention alerts for reputation protection, but does not measure answer-engine share of voice and should pair with a dedicated AI tracker.
- LLM Pulse focuses narrowly on prompt-set share of voice, sentiment, and citations, with transparent methodology that holds up when defending numbers in client reviews 1.
- Vectoron pairs brand visibility measurement with content, SEO, PPC, and outreach execution inside an approval workflow, fitting agencies rebuilding retainers around AI-powered production.
Why client retainers now depend on measuring answer-engine presence
Client CMOs are already asking a version of the same question in quarterly reviews: why isn't the brand showing up when a prospect asks ChatGPT, Perplexity, or Gemini for a recommendation? Legacy rank trackers cannot answer it. AI-mediated discovery breaks the assumptions behind keyword ranking and last-click attribution, which means agencies reporting on Google positions alone are undercounting a growing share of brand exposure 2.
The stakes are commercial, not academic. Research on brand awareness finds that up to 82% of online consumers prefer to buy from brands they already recognize, a benchmark drawn from digital marketing survey data on consumer preference among familiar versus unfamiliar labels 5. When an AI assistant summarizes a category and names three competitors instead of the client, familiarity erodes at the exact moment purchase intent forms.
Share of voice has already expanded beyond ad spend to cover visibility across search, social, and content, and AI-enabled tracking has pushed that definition further into real-time sentiment and citation analysis 9. Agencies that add answer-engine measurement to the retainer defend existing SEO scope and open a new reporting line clients will pay to see monthly. Agencies that don't will keep explaining why the dashboard looks green while the pipeline softens.
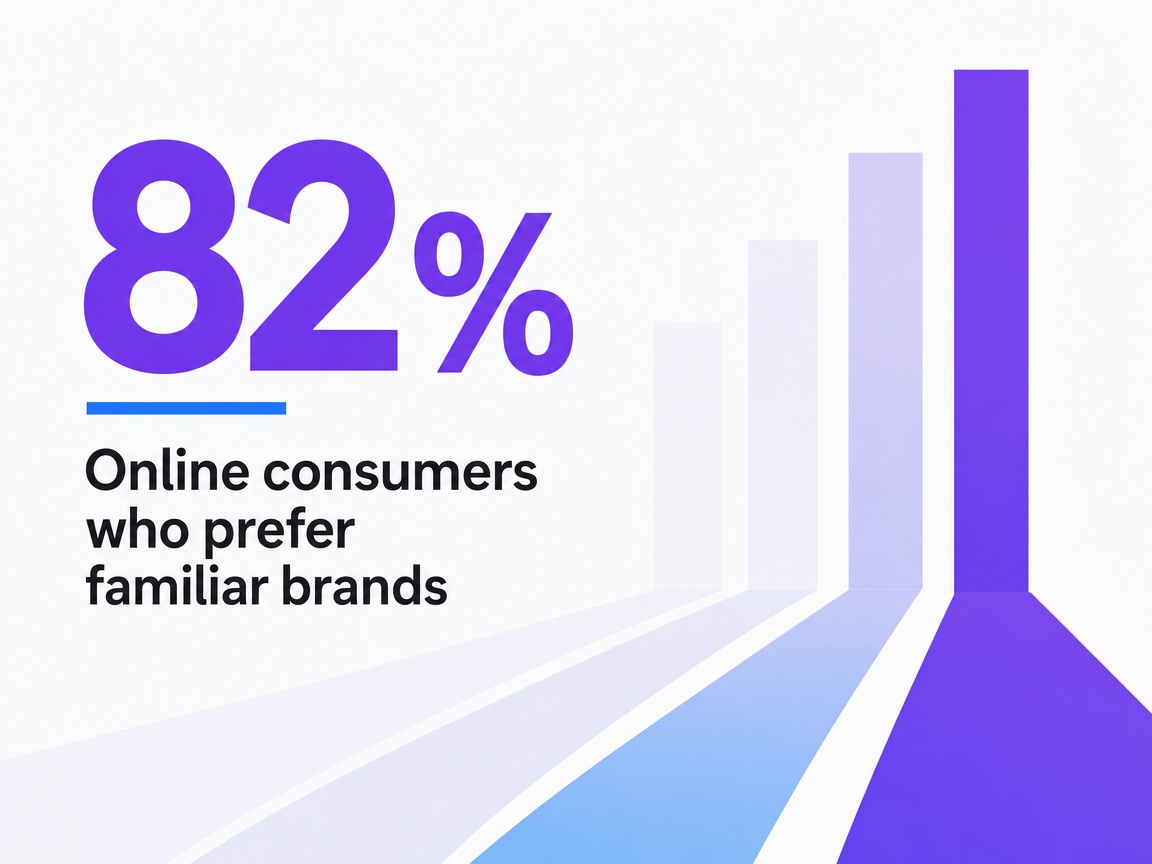 Online consumers who prefer familiar brands
Online consumers who prefer familiar brands
Online consumers who prefer familiar brands
What agencies should actually measure inside AI answer engines
Share of voice, sentiment, and citation rate as the core triangle
AI share of voice is the percentage of brand mentions a company receives compared to competitors across AI-generated responses, measured by running a consistent prompt set on a set schedule across platforms like ChatGPT, Perplexity, and Gemini 1. That definition matters because it forces three separate measurements to sit together, not one headline number.
- The first pillar is prompt-set consistency. The same list of category, comparison, and problem-framed prompts has to run on the same cadence, or week-over-week movement means nothing.
- The second pillar is sentiment framing: whether the brand is described as the default choice, one of several options, or a cautionary example.
- The third is citation capture, tracking which source URLs the model links to when it names the brand.
Agencies reporting only mention counts miss the two pillars that predict pipeline. A brand cited in three prompts with strong sentiment and links back to its own domain is winning. A brand mentioned in twenty prompts as a runner-up, with citations pointing to competitor comparison posts, is losing while the dashboard looks healthy 1.
Prompt coverage is a vanity metric without entity trust
Counting prompts the brand appears in is the AI-era equivalent of counting keyword rankings without checking click-through rate. Coverage without context inflates reports and hides the underlying problem.
AI visibility is about favorable perception by AI systems through trust signals, entity footprint, and brand consistency, not just how often a name surfaces in a prompt list 17. A model that recognizes the brand as a distinct entity with a defined category, product line, and verified footprint will cite it in higher-intent responses. A model that treats the brand as a loose string of characters will drop it the moment a prompt is rephrased.
Agencies that lead client conversations with prompt coverage alone set themselves up for the awkward review three months later, when the number climbs but qualified traffic and branded search stay flat. The reporting fix is pairing coverage with sentiment scores and entity-level checks: does the model describe the brand consistently, and does it link the brand to the right products and competitors 17?
Reporting standards agencies should demand before signing a contract
Vendor demos favor screenshots of clean dashboards. The buying decision should favor what those dashboards will look like on the twelfth monthly client review.
Forbes' criteria for AI visibility specialists set a useful bar: transparent dashboards, regular updates, and clear explanations of how AI systems decide what to reference 16. Translated to software procurement, that means three non-negotiables:
- Prompt-set transparency so the agency can audit which queries were run and edit them per client vertical.
- Export access for citations, sentiment scores, and competitor mentions in a format that feeds white-label reports.
- Anomaly alerts driven by machine learning that surface sudden sentiment drops or competitor spikes without waiting for a human to notice 11.
Any tool that hides its prompt library, ships a fixed PDF report, or lacks alerting will fail on the second client added to the account. The evaluation questions are simple: what runs, when, and who can see it.
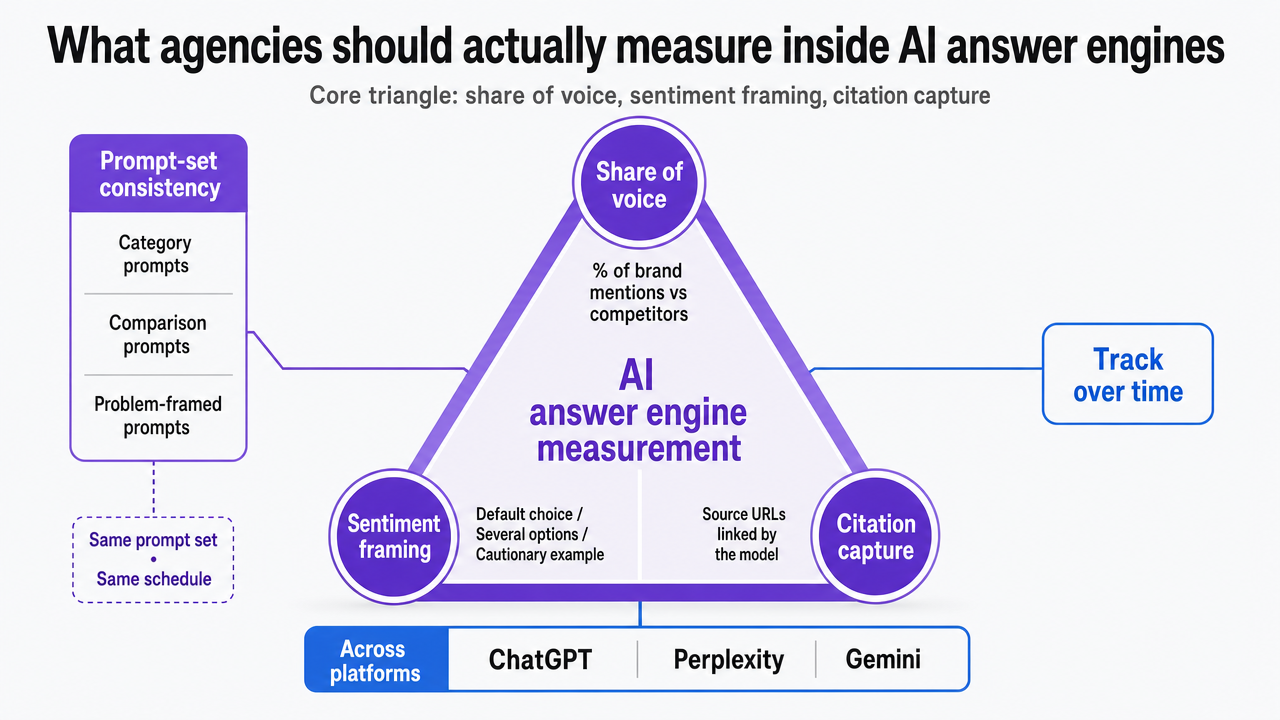 Visualize the three-pillar measurement framework introduced in this section: share of voice, sentiment framing, and citation capture, which the article explicitly frames as the core triangle
Visualize the three-pillar measurement framework introduced in this section: share of voice, sentiment framing, and citation capture, which the article explicitly frames as the core triangle
Three categories the 7 tools fall into
The AI visibility tool market has split into three practical categories, and confusing them is the fastest way to overpay for the wrong capability. Zapier's 2026 roundup groups leading tools by job-to-be-done, separating enterprise all-in-one monitors like Profound from side-by-side SEO and GEO trackers like Similarweb and Semrush that layer answer-engine visibility onto existing keyword workflows 15.
- Dedicated AI answer-engine trackers. These tools run prompt sets against ChatGPT, Perplexity, Gemini, and Google AI Overviews, then report share of voice, sentiment, and citations. Profound, Similarweb AI, Semrush GEO tracking, and LLM Pulse sit here. They answer the question a client CMO actually asks: is the brand named when a buyer prompts an AI assistant in the category?
- Expanded social listening. Brandwatch and Brand24 built their businesses on tracking mentions across social, review sites, forums, and news, and have added AI-assisted sentiment and anomaly detection on top 14. They cover the wider brand conversation that shapes what AI models eventually ingest and cite.
- Execution-integrated platforms. These tools measure visibility as part of a broader workflow that also produces content, publishes changes, and tracks the downstream effect on pipeline. Vectoron sits in this tier. The trade-off is scope: less depth on prompt-level analytics, more coverage of what happens after the measurement.
Test AI Brand Visibility Monitoring On Live Campaigns
Evaluate automated brand visibility tracking with your own agency data and real-time performance insights during your trial.
The 7 tools, grouped by the job they do
Profound: enterprise AI answer-engine tracking
Profound is positioned as the all-in-one enterprise option in the current AI visibility tool market, built for teams that need to monitor brand presence across ChatGPT, Perplexity, Gemini, and Google AI Overviews from a single workspace 15. The pitch is depth over breadth: heavy prompt libraries, competitor benchmarking, and answer-engine coverage that goes beyond a bolt-on to an existing SEO product.
For agencies, the practical draw is scale. Profound is built to handle the prompt volume required when a single client operates in multiple categories or geographies, and to segment share of voice by product line or region without the analyst spending an afternoon in spreadsheets. Sentiment scoring and citation tracking sit alongside mention counts, which addresses the three-pillar measurement problem covered earlier in this article.
The trade-off is fit at the low end of the roster. Enterprise-grade tooling tends to price out of retainers where clients pay for six or eight hours of monitoring work per month. Agencies with two or three anchor accounts in competitive verticals get more from Profound than agencies with a long tail of small local clients where prompt volumes stay thin.
Similarweb AI: side-by-side SEO and GEO visibility
Similarweb AI extends the platform's existing traffic and market-intelligence data into generative engine optimization, letting analysts view answer-engine visibility next to organic search share in one interface 15. The value is the join. When a category loses ten points of traditional search visibility and gains six in AI answers, the client conversation shifts from panic to reallocation.
For agency reporting, Similarweb AI answers a specific question well: is the brand cited when a prospect prompts an AI assistant, and how does that map to the domains still winning clicks in classic search? That side-by-side view is what turns AI visibility from a curiosity into a defensible line item in an SEO retainer.
The limitation is prompt-set control. Platforms built on traffic-panel data tend to lean on their own prompt libraries and competitive baselines, which is useful for benchmarking but less flexible when an agency wants to run vertical-specific queries a general-purpose panel would not include. Agencies serving niche verticals like DSO acquisitions or senior living should audit the prompt library before signing.
Semrush GEO tracking: adding AI visibility to an existing SEO stack
Semrush layers GEO tracking onto the keyword and rank data agencies already pull for client reporting, which makes it the lowest-friction entry point for teams that do not want to add another vendor invoice 15. The measurement approach mirrors the traditional rank-tracker model: watch a defined set of prompts across AI answer engines, log presence and position, chart movement over time.
The workflow advantage matters for retainer economics. Analysts already inside the platform for keyword research and site audits can pull AI visibility into the same monthly report without switching context. White-label reporting features carry over to the AI visibility module, which shortens the path from data to client deck.
The ceiling is depth. Agencies that need granular sentiment framing, citation-source tracking, and entity-level trust analysis will find the GEO module lighter than a dedicated tool 17. Semrush GEO fits agencies expanding an SEO retainer to include AI visibility as a defensible add-on, not agencies building a standalone AI visibility service line with its own monthly deliverable.
Brandwatch: consumer and market research with AI-assisted listening
Brandwatch is positioned as the strongest option for consumer and market research inside the social listening category, with complex query building and premium analytics that support deep brand studies 14. It is not an AI answer-engine tracker in the Profound sense. It monitors what people say about a brand across social platforms, forums, news, and review sites, and applies AI to sentiment and anomaly detection on top of that stream.
The relevance to AI visibility is upstream. Large language models train and retrieve on the same public conversations Brandwatch indexes. When a brand's sentiment on Reddit and industry forums shifts, that eventually shapes how AI models describe the category. Machine-learning-driven alerting surfaces those shifts before a human analyst would spot them 11.
For agencies, Brandwatch belongs on the shortlist when a client retainer includes brand health, reputation management, or product-launch monitoring. Pairing it with a dedicated AI answer-engine tracker gives the fuller picture: what people are saying, and how AI models are summarizing it back to prospects.
Brand24: real-time mention monitoring across social and web
Brand24 sits in the same social listening category as Brandwatch but leans toward real-time brand monitoring and alerts rather than deep market research 14. The product is built for teams that need to know within minutes when a mention spikes, a sentiment score drops, or a competitor gets named in an unexpected context.
The agency use case is protective. On accounts where reputation risk sits on the daily task list, Brand24 covers the base-layer monitoring that alerts an account manager before a client's PR team notices. Pricing has historically skewed more accessible than enterprise listening suites, which makes it viable for small-to-mid agencies adding a monitoring line to retainers that could not absorb Brandwatch.
What Brand24 does not do is measure share of voice inside AI answer engines directly. Agencies buying it for that purpose will be disappointed. Buying it as the always-on reputation layer underneath a dedicated AI visibility tracker is the pairing that holds up on a monthly client review.
LLM Pulse: prompt-set share of voice for client reporting
LLM Pulse defines AI share of voice as the percentage of brand mentions a company receives compared to competitors across AI-generated responses, and its product is built around running consistent prompt sets on a set schedule to track that number over time 1. The methodology is transparent, which matters when an agency has to defend the report line by line in a client review.
The product covers the measurement triangle set out earlier: prompt-set consistency, sentiment framing, and citation capture. It also documents practical steps for improving AI share of voice through authoritative content, citation-worthy structure, and full product-capability coverage inside the models 1, which gives agency strategists a next-action list to attach to the monthly report.
The narrower scope is the point. LLM Pulse does not try to be a social listening suite or a full SEO platform. Agencies that want a focused AI share of voice tracker with clean reporting exports for white-label decks get more from a specialist product than from a general-purpose tool with a GEO module bolted on.
Vectoron: execution-integrated brand visibility with approval workflows
Vectoron sits in the third category, execution-integrated platforms, rather than the dedicated AI answer-engine tracker tier. The platform pairs brand intelligence with specialist AI strategists that work across content, SEO, PPC, backlinks, social, and call intelligence inside a single approval workflow. Visibility measurement is one input among several that feed ranked, actionable recommendations for the agency to approve before anything ships.
The workflow difference is what agencies with production overhead care about. A dedicated visibility tracker reports on the gap; an execution-integrated platform reports on the gap and produces the content, on-page changes, and outreach designed to close it, with human sign-off on every step. That fits the emerging framing of AI visibility as favorable perception by AI systems through trust signals, entity footprint, and brand consistency, not just prompt coverage 17.
Vectoron is not the right fit for agencies buying a pure prompt-set tracker with no production layer. It is the fit for agencies rebuilding retainer economics around AI-powered execution and want brand visibility measured in the same governed loop that produces the work.
 Visualize the three-category segmentation of the 7 tools that the article explicitly organizes this section around, helping readers scan tool positioning before reading individual profiles
Visualize the three-category segmentation of the 7 tools that the article explicitly organizes this section around, helping readers scan tool positioning before reading individual profiles
Comparison table: matching tool category to retainer scope
The individual profiles cover what each tool does. The scan below covers which tool fits which retainer, so agency owners can move from reading to shortlisting without re-reading the section 15, 14.
| Tool | Primary job | Pricing model | Multi-client fit | Reporting output |
|---|---|---|---|---|
| Profound | AI answer-engine tracking | Enterprise, custom | Limited for small accounts | Dashboard, API |
| Similarweb AI | SEO + GEO side by side | Per-workspace, custom | Yes | Dashboard, export |
| Semrush GEO | AI visibility inside SEO stack | Per-seat tier add-on | Yes | Dashboard, white-label |
| Brandwatch | Consumer and market research listening | Enterprise, custom | Yes | Dashboard, API |
| Brand24 | Real-time mention monitoring | Per-brand tier | Yes | Dashboard, alerts |
| LLM Pulse | Prompt-set share of voice | Contact vendor | Yes | Dashboard, export |
| Vectoron | Execution-integrated visibility | Per-workspace | Yes | Command Center, approval logs |
Read the table by column, not by row. The primary job column separates the three categories introduced earlier; the multi-client fit column flags where seat and workspace pricing start to bite on retainer margin.
See How Leading Agencies Automate Brand Visibility Audits with AI
Request a live walkthrough of automated brand monitoring workflows proven to reduce reporting hours and ensure consistent brand presence across every channel.
If an agency manages a multi-client portfolio, the economics change
Scope shift: the sections above evaluated tools from a single-brand measurement lens. The question changes when an agency runs fifteen or forty client accounts on the same platform, because seat pricing, workspace limits, and prompt-volume caps stop being line items and start dictating which tools are viable at portfolio scale.
- Per-seat pricing punishes agencies with rotating analyst teams. Every new hire adds an invoice line, and turnover creates dormant seats that finance eventually flags.
- Per-brand tiers are cleaner for small agency portfolios but scale linearly, which erodes margin as the roster grows past ten accounts.
- Per-workspace pricing tends to be the friendliest structure for retainer economics, since one contract covers the full client book and analyst headcount can flex without triggering renewals 15.
Two other variables decide whether the tool survives a real client review cycle. White-label export is the first: a report that carries the agency's brand and travels cleanly into a monthly deck saves hours per client and protects the agency's positioning as the source of insight 16. Anomaly alerts driven by machine learning are the second, because a portfolio of thirty accounts cannot be watched manually, and vendors are already building automatic detection of outliers users did not predefine 11.
How to pilot one of these tools inside a live retainer
The lowest-risk way to add AI visibility to a retainer is a 60-day pilot inside a single client account, scoped tightly enough that neither side has to renegotiate the master agreement to run it. Pick one anchor client where branded search is already tracked, competitor set is defined, and the CMO has raised the AI question at least once.
- Week one is prompt-set construction. Build 40 to 60 prompts covering category, comparison, and problem-framed queries, then lock the list so week-over-week movement is comparable 1.
- Week two runs the baseline across ChatGPT, Perplexity, Gemini, and Google AI Overviews, capturing share of voice, sentiment framing, and citation sources as three separate columns rather than one blended score.
- Weeks three through eight add a monthly report line to the existing deck. The report should sit next to branded search and share of search, not replace them, since AI visibility reads as a leading indicator inside a broader brand measurement stack 3.
If the client renews the line at day 60, the pilot converts. If they don't, the agency keeps the prompt library and the workflow, and rolls both into the next new-business pitch.
Frequently Asked Questions
References
- 1.Share of Voice: definition, measurement and benchmarks - LLM Pulse.
- 2.AI Is Breaking Brand Visibility and Marketing Measurement.
- 3.How to Measure the Impact of Brand Marketing.
- 4.Brand Awareness Metrics: Drive Growth and Engagement.
- 5.How To Measure Brand Awareness In Digital Marketing.
- 6.How to Measure Brand Awareness.
- 7.How Companies Use AI Social Listening to Spot Trends and Boost Engagement.
- 8.Tools for social listening and brand monitoring.
- 9.Is AI Share of Voice The Next Big Brand Strategy?.
- 10.2025: The State of Generative AI in the Enterprise.
- 11.Social Listening Platforms Aim To Serve All User Types.
- 12.AI Will Shape the Future of Marketing.
- 13.How To Use Brand Monitoring In Your Market Research.
- 14.13 Best Social Media Listening Tools for 2026 (And How to Choose).
- 15.The 8 best AI visibility tools in 2026.
- 16.How To Identify The Best AI Visibility Agency For Your Brand.
- 17.Best AI Visibility Agencies: 2026 Rankings & Guide.