
Key Takeaways
- Define the baseline measurement set — citation frequency, share of voice, sentiment, source URLs, and prompt-level visibility — before shortlisting vendors, since anything less produces partial views that fail procurement scrutiny 6.
- Evaluate tools across four layers: data collection transparency, entity resolution controls, ranking signal capture including off-site brand mentions, and recommendation logic visibility, because opaque platforms cannot be defended in client review 9.
- Run a manual prompt diagnostic of ten to twenty queries per client before signing, since 26% of brands have zero AI Overview mentions and the gap determines which vendor category actually fits 4.
- Weigh AI-native diagnostics seriously: automated audits reach 95–98% accuracy versus 60–70% for manual work and process millions of pages in hours, which reshapes portfolio-level margin math 8.
- Model portfolio scaling around prompts per client, refresh frequency, engine coverage, competitor set size, and brand mention scope, because per-prompt and per-domain pricing compounds fast past 15 accounts 7.
- Choose software that emits structured findings into briefs, PR target lists, and reputation workflows, since visibility data that stops at the dashboard forces analysts to retype insights instead of shipping work 2.
Why Client Questions About ChatGPT Broke the Old Reporting Stack
The trigger is almost always the same phone call. A client asks why a competitor keeps surfacing in ChatGPT answers about their category, and the agency's monthly report — built around Ahrefs positions, Search Console impressions, and a Semrush visibility index — has no field that answers the question. Traditional rank tracking measures ten blue links. AI answer engines assemble responses from citations, brand mentions, and structured signals that never resolve to a keyword position 3.
That gap is now a delivery problem, not a curiosity. Analysis of Google AI Overviews across 75,000 brands found that branded web mentions and branded search volume outperform backlinks as visibility predictors, meaning the inputs an agency's stack tracks most carefully are not the inputs deciding whether a client gets cited 4. Meanwhile, generative engines pull from a moving set of sources: reviews, third-party listicles, structured data, and off-site brand references that a keyword tracker was never designed to read 3.
For an agency head of SEO managing 15 to 50 accounts, the operational question is narrower than the industry debate. It is not whether GEO matters. It is which data layer, added to the existing stack, produces client-ready answers about citation frequency, source URLs, sentiment, and prompt-level visibility across ChatGPT, Perplexity, Gemini, and AI Overviews 6. Choosing that layer is a procurement decision with margin implications — cost per client, hours to insight, and how quickly a finding turns into shipped content. The sections that follow treat AI visibility analysis software as a data pipeline feeding production, and lay out the criteria that survive both procurement review and portfolio scale.
What AI Visibility Analysis Software Actually Measures
The Baseline Capability Set: Citations, Sentiment, Source URLs
Before comparing vendors, an agency needs a shared definition of what the category should measure. A generative engine optimization tool tracks citation frequency, share of voice against competitors, brand mention sentiment, source URLs cited by AI engines, and prompt-level visibility across ChatGPT, Perplexity, and Google AI Overviews 6. Anything less than that set is a partial view, and partial views tend to fail procurement questions the second a client asks how a finding was produced.
Each dimension answers a different production question. Citation frequency indicates whether the brand appears at all for a defined prompt set. Share of voice quantifies the competitive gap. Sentiment separates a citation that helps from one that damages positioning. Source URLs identify which third-party pages the model actually pulled from — often reviews, listicles, and industry directories rather than the client's own domain 3. Prompt-level visibility ties the finding to a specific query, which is the only unit that translates to editorial planning.
The right tracking tool monitors brand visibility across AI platforms, analyzes citation quality and sentiment, and uses modern data collection methods to keep results accurate 7. For an agency head evaluating software, the baseline test is straightforward: if any of those five measurement dimensions is missing, the tool is a reporting widget, not a data layer that can feed client work at scale.
Why Off-Site Brand Signals Belong Inside the Tool, Not Beside It
Citation tracking alone will mislead an agency into treating AI visibility as an on-page problem. It rarely is. The Ahrefs study of 75,000 brands measured which factors correlate with appearances in Google AI Overviews and found that branded web mentions correlate at 0.664, while backlinks correlate at only 0.218 4. The measurement was scoped to one engine — Google AI Overviews — and to correlational signals rather than causal proof, but the directional finding reshapes what a visibility tool has to see.
If off-site brand mentions are the strongest observable signal for at least one major AI surface, then a tool that only reads the client's domain and pulls citation logs from LLMs is watching the wrong side of the equation. The buying criteria shift accordingly. The software has to index unlinked brand mentions, anchor-text patterns, and branded search demand alongside citation output, or an agency ends up correlating what it can see rather than what actually moves visibility 4. Reputation data, review coverage, and third-party editorial mentions become inputs to the visibility dataset, not adjacent research an analyst does by hand 3.
This has direct consequences for tool selection. A dashboard that reports citations without brand mention infrastructure forces the agency to bolt on separate media monitoring, digital PR, and review tracking systems — and then reconcile them manually every reporting cycle. For a 15-to-50-account portfolio, that reconciliation is where margin disappears. The tools worth shortlisting either ingest off-site brand signal data natively or expose an API that lets the agency merge it upstream of client reporting. Anything else pushes the integration work back onto the delivery team, and the client still gets a fragmented answer to the question they actually asked.
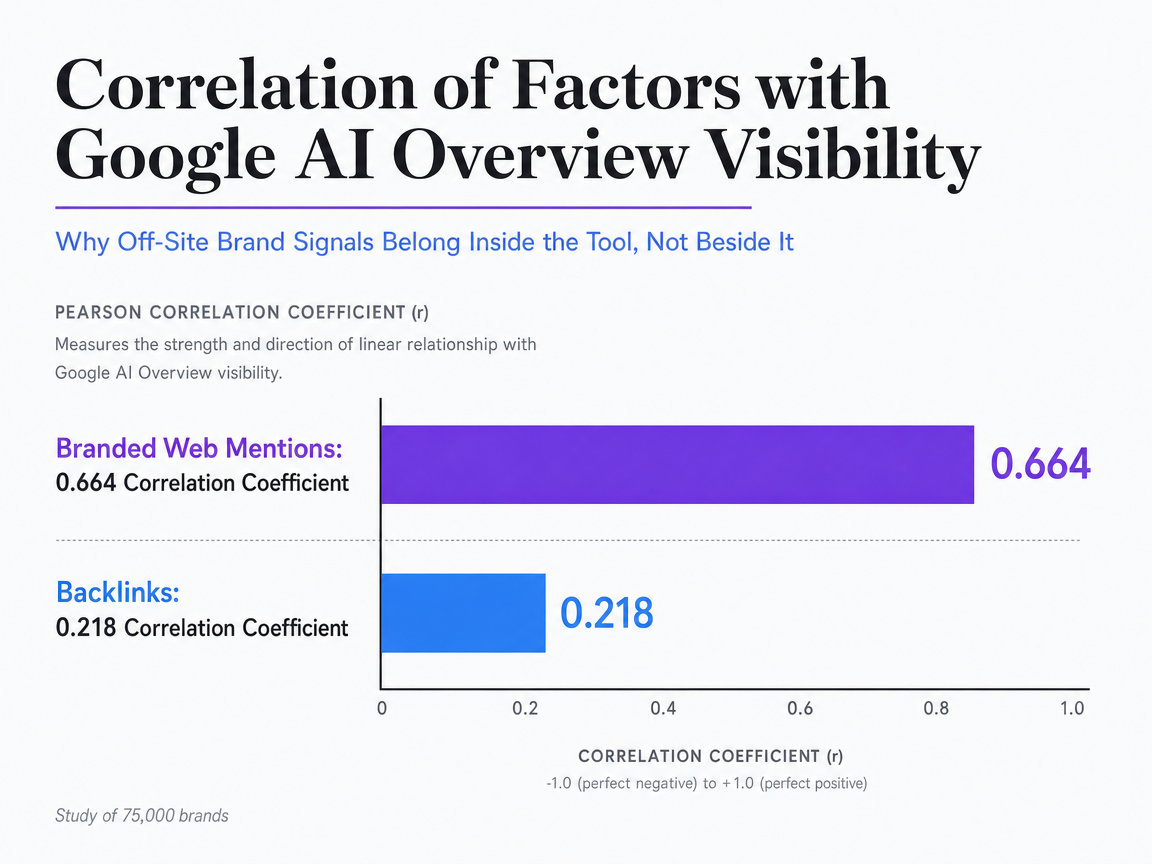 Correlation of Factors with Google AI Overview Visibility
Correlation of Factors with Google AI Overview Visibility
Comparison of Pearson correlation coefficients between various SEO/brand factors and a brand's visibility in Google AI Overviews, based on a study of 75,000 brands.
A Four-Layer Evaluation Model for the Buying Decision
Layer One: Data Collection Method and Prompt Methodology Transparency
The first question a procurement review will ask is how the tool gets its data. It matters because different collection methods produce different results for the same brand on the same day, and cross-tool comparability suffers when the mechanics stay hidden 7. Some platforms run live prompts against public interfaces. Others hit provider APIs. A few rely on synthetic tests calibrated against known outputs. Each approach has different latency, cost, and drift characteristics, and each answers the citation question with a slightly different sample of reality.
Prompt methodology is the second half of this layer, and it deserves more scrutiny than most demos allow. AI visibility tools work by conducting mass, systematic prompting on LLMs and analyzing how a brand performs against key queries and competitors 5. That systematic part is where methodology transparency shows up or fails to. An agency should be able to see the prompt library the vendor uses, edit it per client, add category-specific queries, and export the raw prompt-response pairs. Vendors who treat the prompt list as a trade secret are asking the agency to trust an opaque input into every client conversation.
Two questions clarify the layer quickly during a vendor call. First: how is the prompt corpus constructed, refreshed, and localized per client vertical? Second: can the raw responses be exported for internal QA before they reach a client dashboard? A tool that answers both cleanly can be defended in procurement. A tool that answers neither turns every visibility report into a claim the agency cannot substantiate on request 5.
Layer Two: Entity Resolution and Brand Disambiguation
Entity resolution is where most visibility dashboards quietly break. AI systems process entities and sources before deciding whether to recommend a brand, and external tools can only infer that logic rather than observe it directly 9. If the software cannot separate a client's brand from a similarly named competitor, a parent company, or a generic product term, its citation counts are noise dressed as a metric.
The test cases that matter are the ones agencies actually deliver against. A dental group sharing a name with a national supply company. A regional law firm whose surname is also a common category term. A behavioral health brand competing against a widely cited nonprofit with an overlapping name. In each case, the tool has to distinguish citations of the client from citations of the entity that happens to share its label, or the share-of-voice number is wrong from the first report onward.
Two evaluation questions cut through vendor marketing on this layer. Does the platform expose the entity graph or disambiguation rules per client, allowing manual override when the model gets it wrong? And does it track brand variants — legal name, DBA, subsidiary brands, common misspellings — as a single unit or as fragments? Tools that surface these controls make entity resolution auditable. Tools that hide them force the agency to reconcile citation counts by hand, which does not scale past a handful of accounts 9.
Layer Three: Ranking Signal Capture Across Engines
The third layer is about breadth and depth of what the tool actually watches. Engine coverage is the surface variable — ChatGPT, Perplexity, Gemini, Google AI Overviews, and increasingly Copilot and specialized vertical engines 6. Depth is the harder variable: within each engine, does the tool capture citation frequency, share of voice, sentiment, and the source URLs the model pulled from, or only the fact that a citation occurred 6?
The distinction has direct client-reporting consequences. A citation without a source URL leaves the agency unable to answer the follow-up question every client asks — which page or third-party site drove the mention. A citation without sentiment tags means positive coverage and reputational risk get counted identically. Share of voice without a defined competitor set means the number moves for reasons the agency cannot explain.
Ranking signal capture also has to include what feeds the engines, not just what they emit. Because branded mentions, anchor text, and branded search demand carry stronger correlations with AI Overview visibility than backlinks or organic traffic 4, a tool that ignores off-site brand signals is measuring outputs while missing the strongest observable inputs. The evaluation question is direct: does the platform correlate visibility changes with movements in brand mention volume, review coverage, and branded search demand, or does it stop at citation output? If it stops there, the agency's diagnostic capability stops with it.
Layer Four: Recommendation Logic Visibility
The final layer is the one most demos gloss over. A visibility tool that reports data without explaining its recommendations is a dashboard, not a decision support system. AI systems themselves operate as a layered process, with one internal layer deciding whether to recommend a brand after entities and sources are processed 9. Agency tools have to mirror that transparency, or the recommendations they emit cannot be defended when a client asks why a specific action was proposed.
The practical test is whether the software shows its work. When it suggests adding a client to a specific third-party listicle, does it name the prompts where competitors currently cite that source? When it flags a sentiment decline, does it point to the underlying citations driving the shift? When it prioritizes one content gap over another, does it expose the scoring logic behind the ranking 2?
Recommendation logic visibility matters most when the output has to move through an approval workflow. A finding without traceable reasoning cannot survive review by a client stakeholder or a senior strategist, and the agency ends up rewriting the rationale by hand. Tools that expose the logic feed production directly. Tools that do not create a second job downstream.
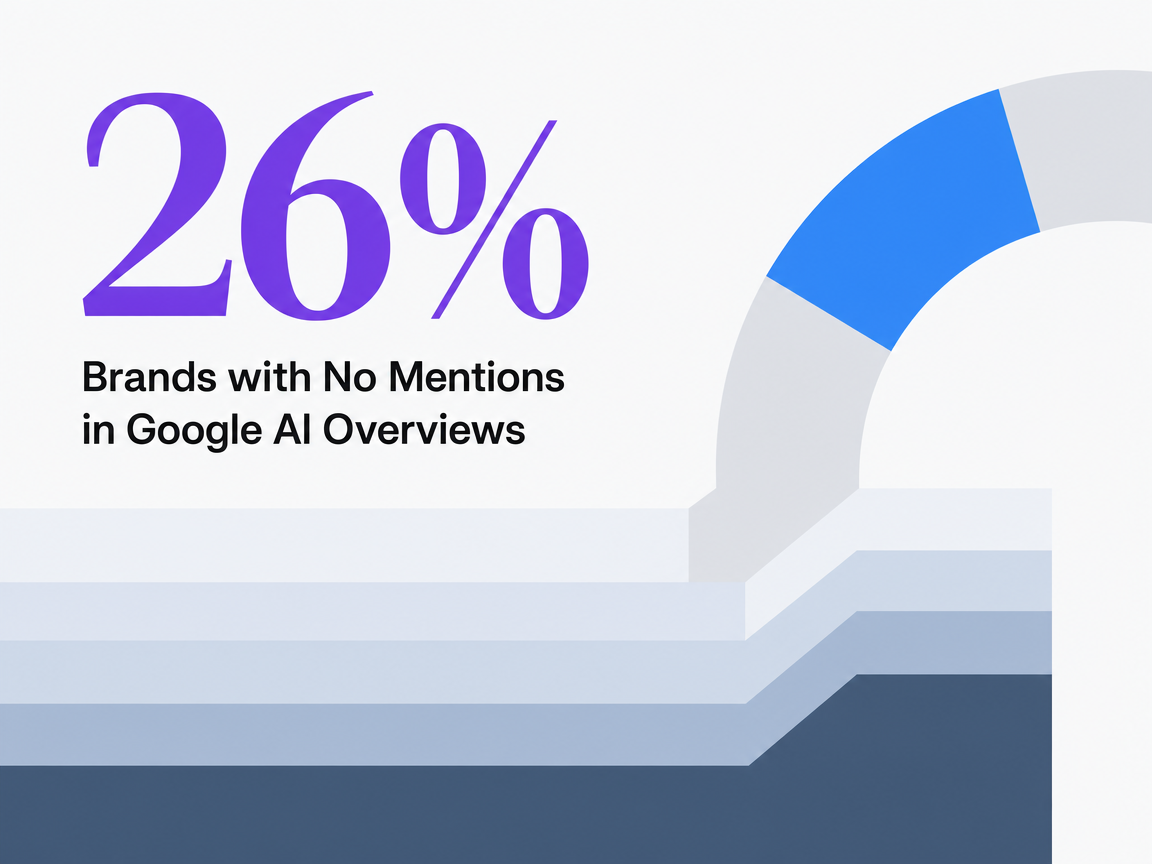 Brands with No Mentions in Google AI Overviews
Brands with No Mentions in Google AI Overviews
Brands with No Mentions in Google AI Overviews
Test AI-driven visibility insights on real campaigns
Validate software impact by running live visibility analysis and publishing actionable content during your free trial.
Diagnosing the Citation Gap Before Picking a Vendor
A vendor demo is the wrong place to discover a client has no AI presence at all. The Ahrefs analysis of 75,000 brands found that 26% had zero mentions in Google AI Overviews 4. That is not a long-tail visibility problem. It is a category-entry problem, and it changes what the software has to do first.
The diagnostic work happens before a contract is signed. Running a short manual prompt set — ten to twenty queries per client covering category, comparison, and problem-framing prompts — establishes a baseline: does the brand appear at all, does a competitor own the answer, or is the AI citing a third-party source neither party controls 2? That baseline determines what a visibility tool needs to solve. A client with zero citations needs a platform strong at surfacing which third-party sources currently occupy the answer and where the brand could be inserted 2. A client with weak but present citations needs sentiment resolution, share-of-voice math, and source-URL tracking to protect and expand what already exists 6.
The distinction matters for procurement. Tools optimized for competitive visibility monitoring assume the client already appears somewhere. Tools built for citation gap discovery emphasize prompt exploration and source attribution. An agency that skips the diagnostic ends up buying the wrong half of the category and then patching around it for the length of the contract.
The diagnostic also filters the vendor conversation. If a shortlisted platform cannot reproduce the manual prompt findings against the same client within a demo window, its data collection method or entity resolution is not going to hold up under a portfolio load 7. The gap the agency already measured becomes the acceptance test.
Why AI-Native Diagnostics Change the Agency Math
Manual auditing does not survive contact with a 40-account portfolio. Sampling a few pages per client, checking citations by hand, and rebuilding prompt logs each month absorbs analyst hours that never reach production. The comparative data is unambiguous: AI-driven audit tools reach 95–98% accuracy for technical issue detection versus 60–70% for manual audits, and can process millions of pages in hours rather than the days or weeks a sampled manual pass requires 8. That gap is not a marginal efficiency claim. It reshapes what an agency can promise per account without adding headcount.
The finding is scoped to technical SEO auditing, not to every dimension of AI visibility work, and human judgment still governs entity disambiguation edge cases and sentiment nuance. But the underlying mechanic applies directly to visibility analysis: prompt runs, citation parsing, source-URL extraction, and share-of-voice math are pattern-matching tasks that benefit from the same accuracy and throughput profile 8. An analyst who spends four hours per client per month reconciling visibility data is spending 160 hours across a 40-client portfolio. An AI-native pipeline that resolves the same work in a fraction of that time redirects those hours to strategy and shipped content.
The math for tool selection follows. Hours-to-insight and insight-to-execution latency are the operating variables that decide whether a visibility contract is profitable at scale. A tool that produces cleaner data faster is not a nice-to-have — it is what makes the delivery model work when the client count moves past a threshold the manual approach cannot cross 8.
See How Leading Agencies Operationalize AI Visibility Analysis at Scale
Connect with our data specialists to review real-world workflows for integrating AI-powered visibility analysis across multiple client accounts—without increasing platform overhead or manual QA cycles.
If the Portfolio Runs 15 to 50 Clients: Scaling Variables and Pricing Logic
What Changes Between Three Clients and Forty
Scope note: this section addresses agency operators running a client portfolio, not in-house teams managing a single brand. The variables that follow only matter once the same tool has to serve 15 or more accounts under one operational roof.
At three clients, an analyst can hand-curate a prompt library per account, run refreshes on request, and produce reporting in whatever format the client prefers. At forty, none of that survives. The prompt corpus has to be templated by vertical, versioned per client, and refreshed on a fixed cadence, or the data becomes stale in ways the client notices before the agency does. Multi-domain support stops being a feature and becomes the gating requirement — the tool has to segment citation data, sentiment, and share-of-voice by client without cross-contamination between accounts 7.
Pricing logic shifts along the same axis. Per-domain and per-prompt pricing models scale linearly with the portfolio, which means a tool that looked affordable at three clients can consume the visibility line item at forty 7. The evaluation question is whether pricing is bounded by client count, prompt volume, engine coverage, or refresh frequency — and which of those variables the agency can actually predict twelve months out. White-label reporting, API access, and role-based permissions move from optional to required, because delivery at portfolio scale cannot route through a single analyst's login 5.
A Framework Table for Per-Client Configuration Variables
The variables below are the ones that change per account and drive tool cost, analyst hours, and reporting cadence. The table is a planning skeleton, not a benchmark — agencies plug in their own client-specific values and the resulting configuration determines which vendor tier fits.
| Variable | Range Across Portfolio | What It Drives |
|---|---|---|
| Prompts tracked per client | 20–200+ | Per-prompt pricing, refresh cost, prompt library maintenance hours 5 |
| Engines covered | ChatGPT, Perplexity, Gemini, Google AI Overviews, Copilot | Platform coverage fit, data collection cost per engine 6 |
| Refresh frequency | Daily, weekly, monthly | API call volume, data freshness in client reports 7 |
| Competitor set size | 3–15 per client | Share-of-voice calculation load, entity resolution complexity 9 |
| Reporting cadence | Weekly, monthly, quarterly | White-label output volume, analyst review hours 5 |
| Brand mention tracking scope | Domain-only vs. off-site signals | Whether reputation and PR data feed the visibility dataset 4 |
| Sentiment resolution | Binary, three-tier, nuanced | Analyst QA time, client-facing narrative quality 6 |
Two configuration decisions carry disproportionate weight. Prompts tracked per client compounds with refresh frequency to determine the true per-account cost — a client on 100 prompts refreshed weekly runs a different economic profile than one on 30 prompts refreshed monthly, even at the same headline price. And brand mention tracking scope decides whether the tool feeds a full diagnostic or a partial one, because domain-only tracking will not surface the off-site signals that correlate most strongly with AI Overview presence 4.
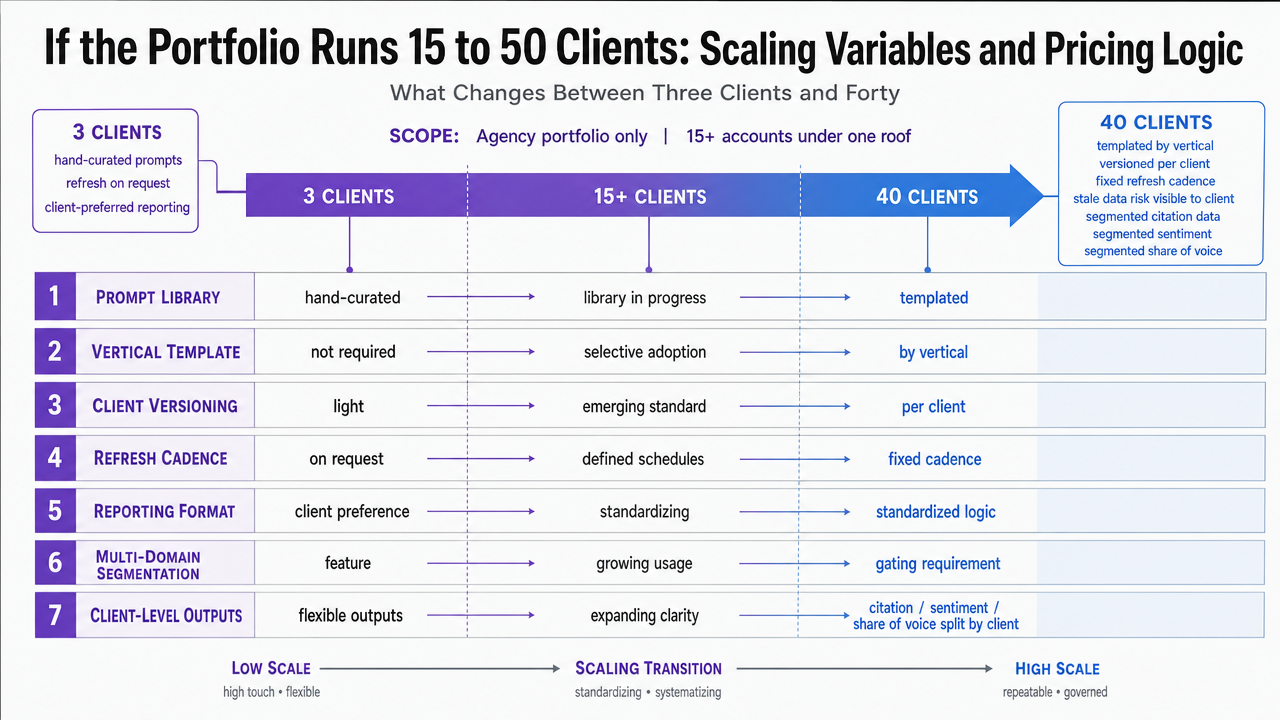 Present the seven per-client configuration variables from the framework table as a scannable visual reference, reinforcing the operational planning skeleton the section provides
Present the seven per-client configuration variables from the framework table as a scannable visual reference, reinforcing the operational planning skeleton the section provides
Integrating Visibility Data Into the Production Pipeline
Visibility data that stops at the dashboard is a reporting artifact. The point of the exercise is to move findings into shipped work — new pages, updated entities, digital PR placements, review campaigns, and paid search adjustments that respond to what the citation data actually shows. That translation is where most agencies stall, and it is where the tool choice matters most.
The integration question is straightforward: does the platform emit findings in a format that a production workflow can consume without a rewrite? Prompt-level visibility gaps should map to briefs. Source-URL analysis should feed digital PR target lists and third-party listicle outreach 2. Sentiment shifts should trigger reputation work before they harden into a citation pattern 3. Share-of-voice deltas against a defined competitor set should route into content prioritization, not sit in a monthly PDF. When the tool exports structured findings — via API, webhook, or scheduled data feed — production planning happens against real signals. When it only exports charts, an analyst spends the week retyping findings into briefs.
Traditional SEO and paid search sit on the same pipeline. SEM performance metrics still track how paid search complements organic and brand discovery 11, and PPC testing remains a live source of query intent that informs both prompt libraries and content targets 10. A visibility layer that ignores those inputs produces a partial diagnosis. One that ingests them alongside citation data feeds a single production queue instead of three.
The agencies moving fastest are the ones treating AI visibility analysis as an input to an approval-based production system — where recommendations carry their reasoning, decisions route through human review, and approved work ships across content, SEO, PPC, and reputation channels without a second handoff. Platforms like Vectoron are built for that loop. The tool selection question, at the end, is whether the visibility software chosen can feed it.
Frequently Asked Questions
References
- 1.What a Single Program Page Reveals About Your AI Search Visibility.
- 2.500M AI Searches Later: How To Actually Improve AI Search Visibility & Citations.
- 3.AI Search Visibility Beyond Rankings.
- 4.An Analysis of AI Overview Brand Visibility Factors (75K Brands).
- 5.14 best tools to track brand visibility in AI search.
- 6.Best GEO Tools Guide: AI Search Visibility Platforms in 2026.
- 7.Top Tools for Tracking AI Visibility.
- 8.AI SEO Audit Tools vs Manual Audits: Which Is Better?.
- 9.How AI Visibility Works: The 4 Layers Behind Every AI Citation.
- 10.Enhance Online Visibility: SEO & PPC Tactics.
- 11.The Importance of Search Engine Marketing in Digital Marketing.